$π_0$: A Vision-Language-Action Flow Model for General Robot Control
-
ArXiv URL: http://arxiv.org/abs/2410.24164v3
-
作者: Karol Hausman; Liyiming Ke; Tim Jones; Quan Vuong; Kevin Black; Chelsea Finn; Michael Equi; L. X. Shi; Haohuan Wang; Anna Walling; 等14人
-
发布机构: Physical Intelligence
TL;DR
本文提出了一个名为 $π_0$ 的通用机器人控制模型,它通过将预训练的视觉语言模型(VLM)与一个新颖的、基于流匹配(Flow Matching)的“动作专家”(Action Expert)相结合,来生成高频、连续的机器人动作序列,从而在大量不同的机器人平台上实现了前所未有的灵巧操作能力。
关键定义
- $π_0$: 本文提出的视觉-语言-动作流模型(Vision-Language-Action Flow Model)的名称。它是一个通用的机器人策略,旨在作为一个“机器人基础模型”,能够控制多种类型的机器人执行复杂、灵巧的任务。
- 流匹配 (Flow Matching): 一种生成式建模技术,是扩散模型(Diffusion model)的一种变体。本文创新地将其用于生成连续的、高维的机器人\(动作序列\)(action chunk)。与将动作离散化为 token 的方法不同,流匹配通过学习一个向量场来将简单的噪声分布平滑地转换为目标动作分布,特别适合需要高精度和高频率控制的灵巧任务。
- 动作专家 (Action Expert): $π_0$ 模型架构中的一个关键创新。它是在 VLM 主干网络之外的一组独立的 Transformer 权重(约3亿参数)。当处理机器人相关的输入(如本体感知状态)和输出(动作)时,会调用这组专用权重。这种设计类似于一个双专家混合模型(Mixture of Experts),可以更有效地处理机器人特有的数据,从而提升性能。
- 视觉-语言-动作模型 (Vision-Language-Action Model, VLA): 一类将预训练的视觉语言模型(VLM)扩展到机器人控制领域的模型。这类模型不仅理解图像和文本,还能生成机器人动作。$π_0$ 是一个新颖的VLA模型,其核心区别在于使用流匹配而非自回归离散化来生成动作。
- 预训练/后训练配方 (Pre-training/Post-training Recipe): 本文提出的机器人模型训练框架,模仿了大规模语言模型的训练策略。
- 预训练: 在一个巨大且极度多样化的数据集(包括多种机器人、任务和数据质量)上训练一个基础模型,使其具备广泛的通用物理能力和泛化性。
- 后训练 (精调): 在一个规模更小、质量更高的特定任务数据集上对基础模型进行精调,以使其在目标下游任务上达到高效、流畅和鲁棒的专家级性能。
相关工作
当前,大规模机器人学习领域的研究现状主要围绕视觉-语言-动作(VLA)模型展开,这些模型通过微调预训练的 VLM 来实现机器人控制。然而,现有方法存在显著瓶颈:
- 动作表示的局限性: 大多数 VLA 模型(如 OpenVLA)采用自回归离散化方式生成动作,将连续动作模仿文本 token 来处理。这种方法难以应对需要高频(例如50Hz)、高精度控制的灵巧操作任务。
- 泛化与数据利用: 虽然已有大规模机器人数据集(如 OXE),但现有模型在跨机器人平台(cross-embodiment)、跨任务的泛化能力上仍受限,尤其是在面对比简单物体拾取更复杂的灵巧任务时。
- 任务复杂度的天花板: 先前的研究虽然展示了一些灵巧行为(如系鞋带),但大多局限于较短时间范围。对于长达数十分钟、结合了物理灵巧性和复杂决策的组合任务(如折叠衣物、整理餐桌),端到端学习方法尚未取得突破。
本文旨在解决上述问题,其核心目标是:创建一个通用的、可扩展的机器人基础模型框架,该框架不仅能有效利用多源异构数据进行跨平台控制,还能通过新颖的动作表示方法,实现以往方法难以企及的、长时程的复杂灵巧操作。
本文方法
本文提出的 $π_0$ 是一个集成了多种先进思想的机器人控制框架,其核心是模型架构与训练配方的结合。 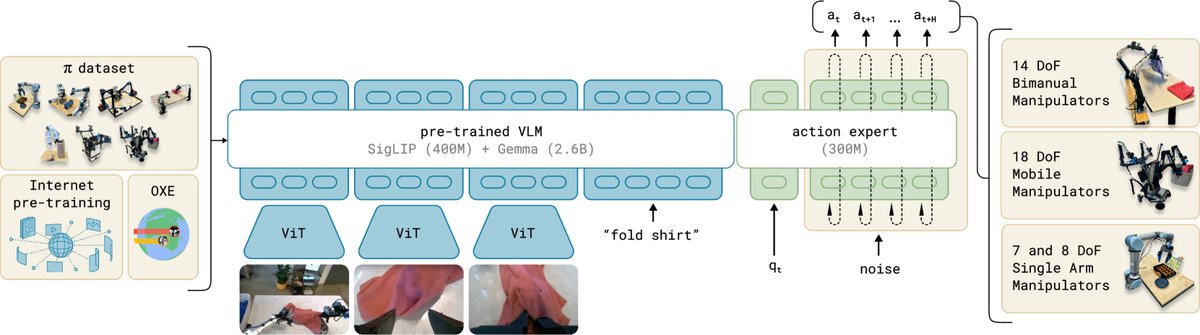
核心架构:VLM + 流匹配 + 动作专家
$π_0$ 模型建立在一个预训练的视觉语言模型(本文使用 PaliGemma-3B)之上,以继承其丰富的语义知识和推理能力。其架构主要包含以下几个部分:
-
输入与主干网络: 模型接收多模态输入,包括多个摄像头图像($\mathbf{I}^{i}_{t}$)、语言指令($\ell_t$)和机器人本体感知状态(如关节角度 $\mathbf{q}_t$)。图像和状态通过各自的编码器被映射到与语言 token 相同的嵌入空间,然后输入到 Transformer 主干网络中。
- 动作生成:条件流匹配: 这是 $π_0$ 的核心创新。它不使用自回归方式逐个生成离散动作,而是采用条件流匹配(Conditional Flow Matching)技术来一次性生成一整个连续的\(动作序列\)(action chunk)$\mathbf{A}_t = [\mathbf{a}_t, …, \mathbf{a}_{t+H-1}]$(本文实验中 $H=50$)。
-
训练: 训练目标是学习一个向量场 $\mathbf{v}_{\theta}$,该向量场可以将高斯噪声分布 $\mathcal{N}(\mathbf{0},\mathbf{I})$ 转化为以当前观测 $\mathbf{o}_t$ 为条件的真实动作分布 $p(\mathbf{A}_t \mid \mathbf{o}_t)$。损失函数定义为:
\[L^{\tau}(\theta) = \mathbb{E}_{p(\mathbf{A}_{t} \mid \mathbf{o}_{t}),q(\mathbf{A}_{t}^{\tau} \mid \mathbf{A}_{t})} \mid \mid \mathbf{v}_{\theta}(\mathbf{A}_{t}^{\tau},\mathbf{o}_{t})-\mathbf{u}(\mathbf{A}_{t}^{\tau} \mid \mathbf{A}_{t}) \mid \mid ^{2}\]其中,$\tau \in [0,1]$ 是流匹配的时间步,$\mathbf{A}_{t}^{\tau}$ 是从真实动作 $\mathbf{A}_t$ 插值到噪声 $\epsilon$ 的中间状态。
-
推理: 从一个随机噪声 $\mathbf{A}_{t}^{0}\sim\mathcal{N}(\mathbf{0},\mathbf{I})$ 开始,通过欧拉积分法,利用学习到的向量场 $\mathbf{v}_\theta$ 进行多步(本文使用10步)迭代,最终生成确定性的动作序列:
\[\mathbf{A}_{t}^{\tau+\delta}=\mathbf{A}_{t}^{\tau}+\delta\mathbf{v}_{\theta}(\mathbf{A}_{t}^{\tau},\mathbf{o}_{t})\] -
优点: 这种方法能够对复杂的连续动作分布进行建模,具有高精度和多模态能力,非常适合需要高频控制的灵巧任务。
-
- 动作专家 (Action Expert): 为了更好地融合机器人特有的信息,本文引入了“动作专家”设计。这是一个拥有独立权重(约3亿参数)的模块,专门用于处理与机器人本体状态和动作相关的 token。而通用的图像和文本 token 则由预训练的VLM权重处理。这种设计类似于专家混合(MoE)机制,让模型不同部分专注于不同类型的信息,实验证明可以提升性能。
训练配方:预训练与后训练
本文强调,仅有先进的架构是不够的,正确的训练“配方”至关重要。
- 预训练 (Pre-training):
- 目标: 训练一个具有广泛通用物理技能的基础模型。
- 数据: 使用一个庞大且异构的数据集混合体。包括:
- 内部采集的约1万小时灵巧操作数据,覆盖7种机器人配置(包括单臂、双臂、移动操作平台)和68类复杂任务。
- 公开的大规模数据集,如 OXE、Bridge v2 和 DROID。
- 方法: 采用跨实体(cross-embodiment)训练,通过对不同机器人的状态和动作向量进行零填充,使单一模型能够处理所有平台。数据被加权采样以平衡不同任务的贡献。
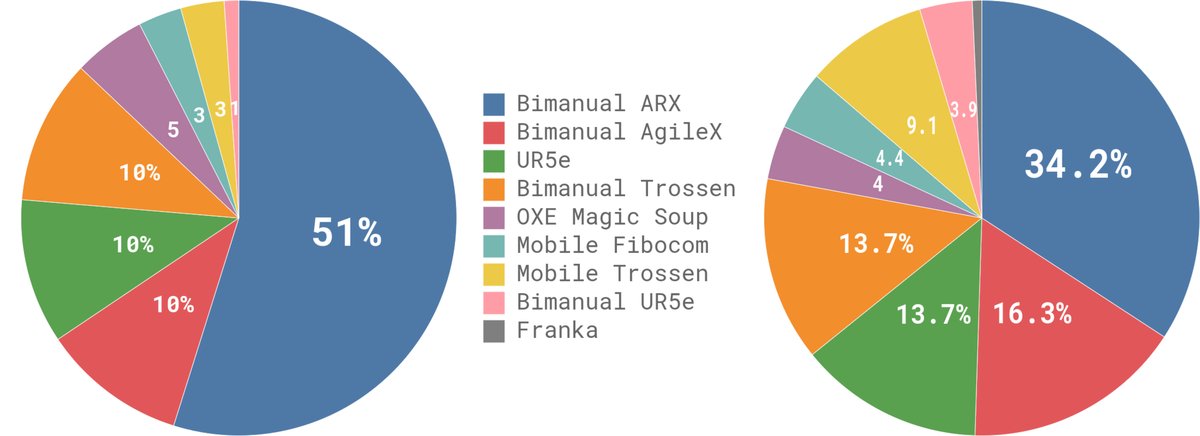
图4: 数据集概览。左图显示了不同数据集按步数计算的相对大小,右图显示了它们在预训练混合数据中的权重。 
图5: 实验中使用的机器人平台,包括单/双臂机械臂以及移动操作平台。$π\_0$ 在所有这些平台上进行联合训练。 - 后训练/精调 (Post-training/Fine-tuning):
- 目标: 将通用基础模型适配到特定的下游任务,以实现专家级的性能。
- 数据: 使用规模更小但质量更高的、为特定任务精心收集的数据(例如,洗衣任务需要100小时以上数据,而简单任务仅需5小时)。
- 理念: 预训练数据(质量较低但多样性高)教会模型如何从错误中恢复和处理各种意外情况;而后训练数据(质量高但场景单一)教会模型如何高效、流畅地完成任务。二者结合,使模型既稳健又高效。
高层规划
对于需要长期策略和语义推理的复杂任务(如整理餐桌),本文框架可以与一个高层VLM规划器结合。高层VLM负责将总任务(“整理餐桌”)分解为一系列简短的子任务指令(“拿起餐巾纸”),然后由 $π_0$ 模型执行这些指令。
实验结论
本文通过一系列实验,系统地验证了 $π_0$ 模型及其训练框架的有效性。
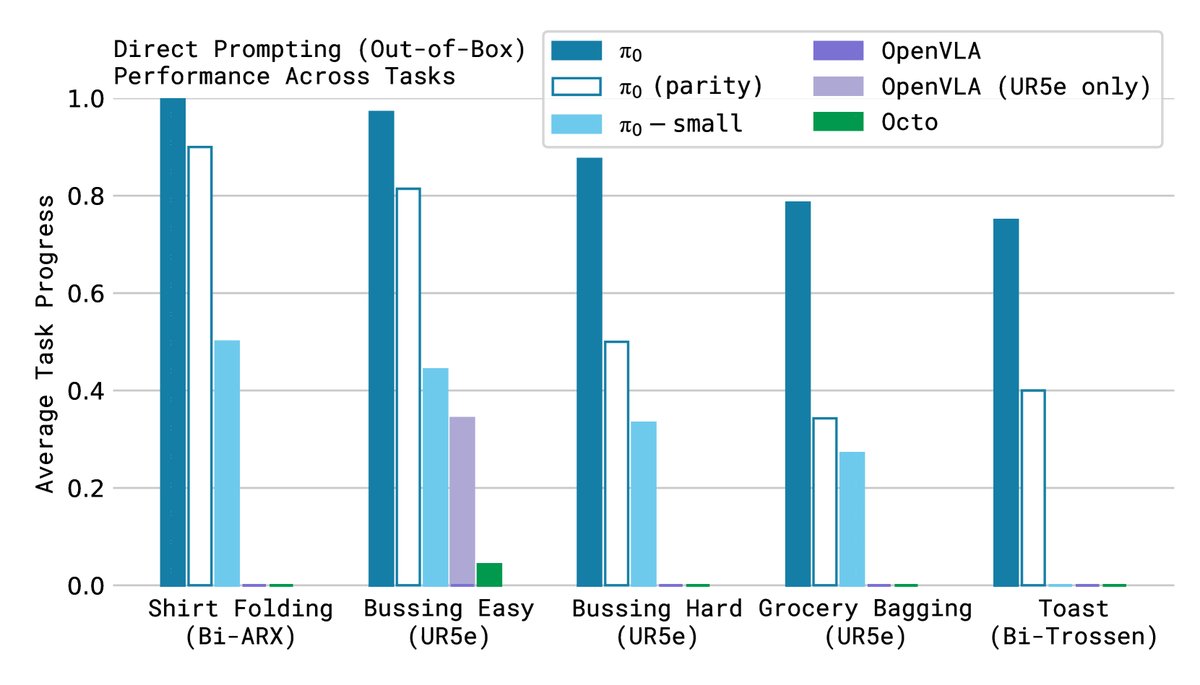
基础模型(预训练后)开箱即用评估
- 任务: 在5个预训练数据中出现的任务上直接评估预训练好的 $π_0$ 基础模型,包括折叠T恤、整理餐桌(难/易)、装购物袋、从烤面包机中取出吐司。
- 比较对象: OpenVLA(7B VLA模型)、Octo(93M 扩散模型)以及一个无VLM预训练的小型版本 $π_0$-small。
- 结论: 如下图所示,$π_0$ 的性能远超所有基线模型。即使是只训练了相当计算量的“parity”版本,也同样优于其他模型。这证明了 $π_0$ 架构(VLM+流匹配)在通用任务上的强大能力,以及VLM预训练带来的巨大优势。而传统自回归 VLA 模型 OpenVLA 在这些需要高频控制的任务上表现不佳。

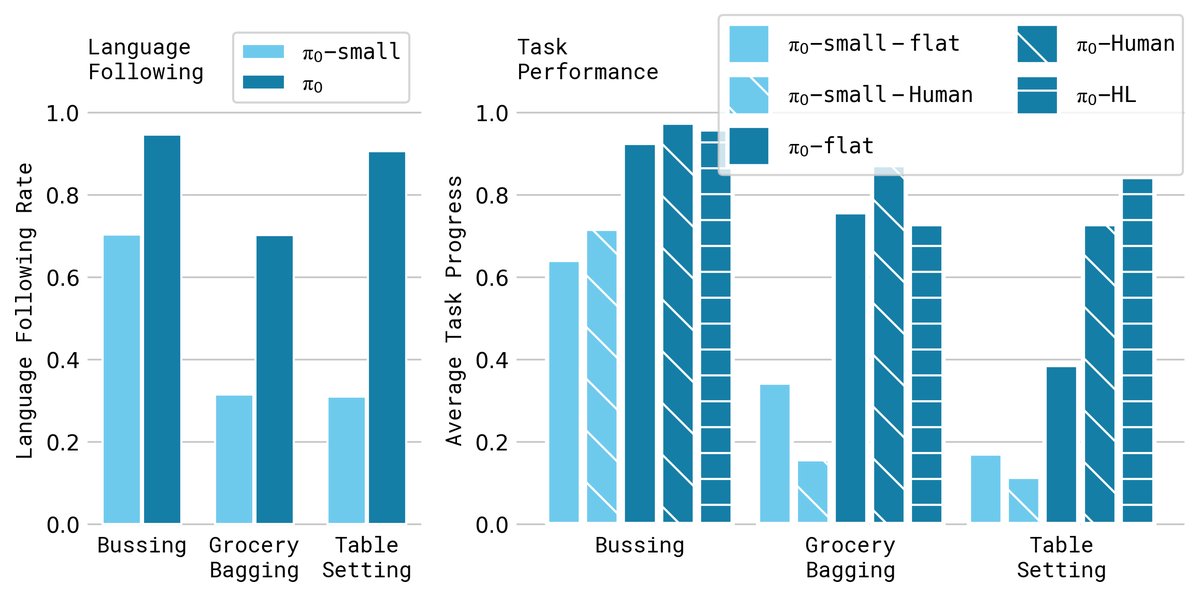
语言指令跟随能力评估
- 任务: 在整理餐桌、布置餐桌和装购物袋三个需要理解并执行一系列语言指令的任务上进行评估。
- 设置: 对比了仅接收高级任务指令(-flat)、接收人类专家子任务指令(-human)和接收高层VLM子任务指令(-HL)三种情况。同时对比了 $π_0$ 和无VLM的 $π_0$-small。
- 结论: 如下图所示,$π_0$ 的语言跟随准确率显著高于 $π_0$-small,证明了大型VLM骨干的价值。这种语言能力直接转化为任务性能的提升,特别是在有高层VLM或人类指导时,模型能够更自主、更高效地完成复杂任务。

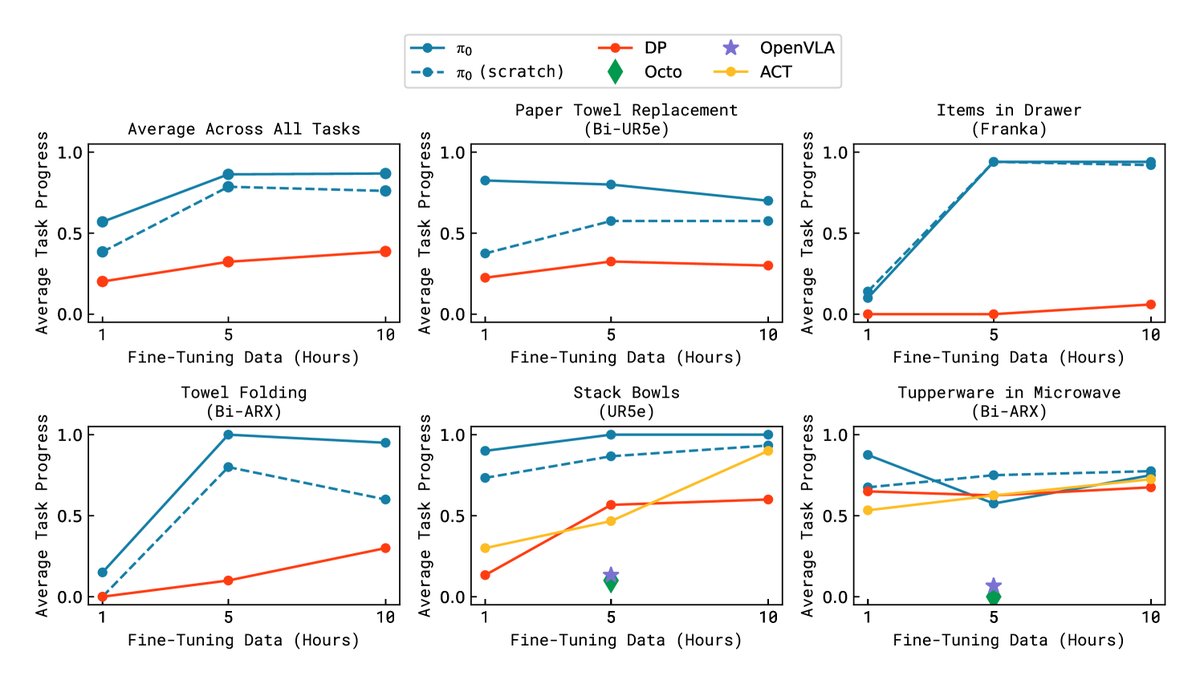
学习新灵巧任务的能力(精调)
- 任务: 评估模型在全新任务上的学习能力,这些任务与预训练数据有不同程度的差异,如堆叠碗、在微波炉中放东西、更换纸巾卷等。
- 设置: 使用不同数量的精调数据来训练模型,并与从头训练的 $π_0$、以及其他为灵巧操作设计的方法(如ACT、Diffusion Policy)进行比较。
- 结论: 如下图所示,通过预训练的 $π_0$ 模型在精调时,比从头开始训练的模型学习效率更高、性能更好。即使只有少量新任务的数据,预训练模型也能快速适应并取得不错的成功率,这证明了本文提出的预训练配方在提升模型样本效率和泛化能力方面的巨大价值。

复杂长时程任务
本文还展示了将 $π_0$ 应用于极其复杂的长时程任务,如折叠衣物和整理餐桌,这些任务耗时5到20分钟,结合了移动操作和灵巧的双手协调。虽然量化结果部分在原文中未完整提供,但其成功演示表明,$π_0$ 框架将机器人端到端学习的能力边界推向了新的高度,实现了前所未有的任务复杂度和执行时长。
