A Comprehensive Survey on Benchmarks and Solutions in Software Engineering of LLM-Empowered Agentic System
-
ArXiv URL: http://arxiv.org/abs/2510.09721v1
-
作者: Siu-Ming Yiu; Zhijiang Guo; Kwok-Yan Lam; Han Yu; Dong Huang; Suizhi Huang; Mei Li; Pietro Lio
-
发布机构: Alborg University; Nanyang Technological University; The Hong Kong University of Science and Technology; The University of Cambridge; The University of Hong Kong
好的,我将遵循您的指示,撰写一份关于该论文的报告。
第一步:判断类型
这是一篇 [综述] 论文。论文的标题、摘要和内容结构(如提出分类体系、回顾不同方法、总结研究现状)都明确表明其旨在对特定领域进行全面总结和分析,而非提出一个全新的原创方法。
第二步:撰写报告
引言
软件工程 (Software Engineering) 旨在通过系统化的方法、工具和实践,开发高质量、可靠且可维护的软件系统。传统方法如基于规则和模板的系统,在应对复杂编程场景时显得力不从心。近年来,研究重心已转向基于学习的方法,特别是大型语言模型 (Large Language Models, LLMs)。
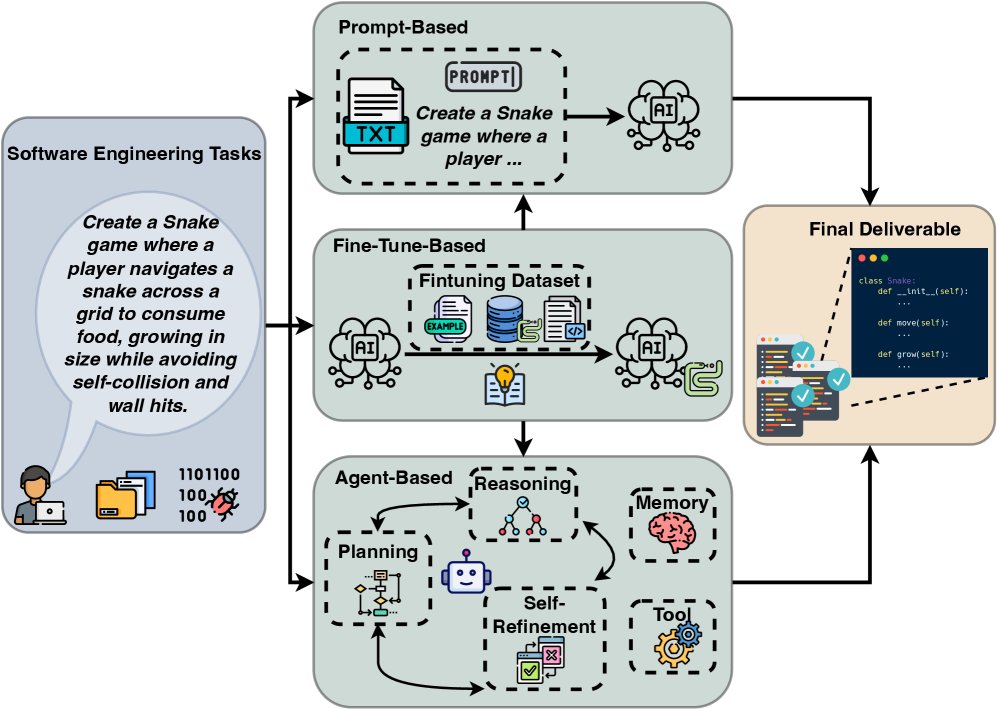
LLM的出现从根本上改变了软件工程的面貌。如下图所示,现代基于LLM的软件工程流程始于多样化的软件工程任务,采用三种主要方法框架:
- 基于提示 (Prompt-Based):通过精心设计的指令直接查询LLM。
- 基于微调 (Fine-Tune-Based):通过监督学习使模型适应特定领域。
- 基于智能体 (Agent-Based):集成规划、推理、记忆和工具使用的复杂系统。
尽管该领域发展迅速,但现有综述存在局限性。如下表所示,它们或只关注单一任务(如程序修复或代码生成),或未能全面覆盖从提示工程到智能体系统的演进,最关键的是,它们普遍缺乏对基准 (Benchmarks) 和解决方案 (Solutions) 之间联系的分析,这阻碍了对不同方法系统性的评估和比较。
相关软件工程综述的比较 (PR-程序修复, CG-代码生成, SE-软件工程)
| 参考文献 | 任务(PR) | 任务(CG) | 无基准 | 分类体系 | 提示 | 智能体组件 | 智能体架构 | 解决方案-基准联系 |
|---|---|---|---|---|---|---|---|---|
| [9] | ✓ | ✓ | × | × | ||||
| [10] | ✓ | ✓ | ✓ | × | ||||
| [11] | ✓ | ✓ | ✓ | × | ||||
| [12] | ✓ | ✓ | ✓ | × | ||||
| [13] | ✓ | ✓ | ✓ | × | ||||
| [14] | ✓ | ✓ | × | ✓ | ✓ | × | ||
| 本文 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
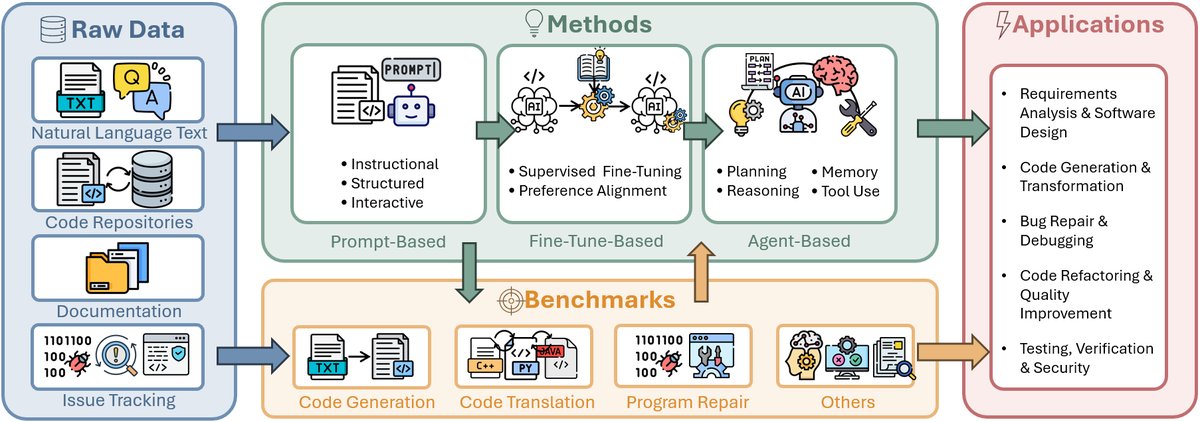
本文旨在填补这些空白,通过提供一个统一的分类体系和流程图,全面连接解决方案与评估基准,为研究人员提供理解、评估和推进LLM赋能的软件工程系统的基础资源。
关键软件工程任务定义
本文关注软件工程中的几个关键基准任务,具体如下:
- 代码生成 (Code Generation)
- 代码翻译 (Code Translation)
- 程序修复 (Program Repair)
分类体系
为了系统地梳理该领域的研究,本文提出了一个核心的分类体系 (Taxonomy),从解决方案 (Solutions) 和基准 (Benchmarks) 两个维度对现有工作进行组织。

- 解决方案维度:根据所采用的核心技术,将方法分为三类:
- 基于提示的解决方案 (Prompt-Based Solutions):这是与LLM交互最直接的方式,包括指令式、结构化和交互式提示。
- 基于微调的解决方案 (Fine-Tune-Based Solutions):通过监督微调 (SFT) 或基于强化学习 (RL)/无RL的偏好对齐来提升模型性能。
- 基于智能体的解决方案 (Agent-Based Solutions):集成任务分解与规划、推理与自我改进、记忆机制和工具使用,以实现更高层次的自动化和协作。
- 基准维度:根据目标软件工程任务,将基准分为四类:
- 代码生成 (Code Generation)
- 代码翻译 (Code Translation)
- 程序修复 (Program Repair)
- 其他任务 (Other Tasks):如代码推理、测试生成、代码重构等。
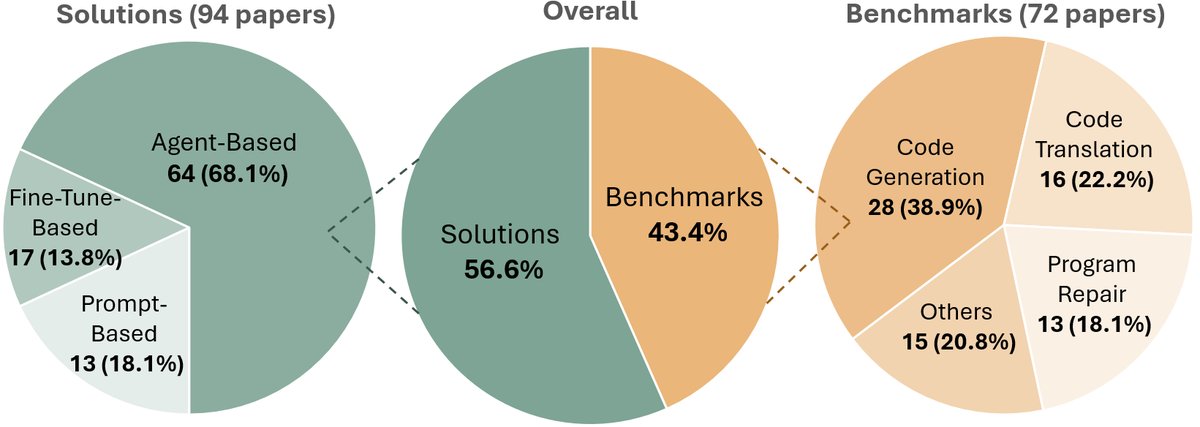
如下图所示,本文回顾了140多篇论文,并根据该分类体系进行了归类。该框架清晰地展示了从简单的提示方法到复杂的智能体系统的范式演进,并将各种评估基准与其实际应用场景对应起来。
LLM赋能的解决方案
LLM推动了软件工程自动化的范式转变。本节按照自主性递增的顺序回顾了新兴方法论:基于提示的解决方案依赖人类指令,基于微调的解决方案使模型适应软件工程领域,而基于智能体的解决方案是能够自主规划、行动和学习的系统。
基于提示的解决方案
基于提示的方法通过在单个输入(即“提示”)中提供上下文和指令来引导模型行为,而无需修改其内部参数。其效果高度依赖于提示工程。

指令式提示 (Instructional)
指令式提示是最常见的交互方式,用户提供自然语言的任务描述。研究发现,指令的精确性和可验证性至关重要。例如,将测试驱动开发 (Test-Driven Development, TDD) 作为提示范式,即同时向LLM提供单元测试和自然语言描述,可以显著提高生成代码的正确率。相比之下,仅依赖输入/输出 (I/O) 示例的迭代式代码生成效果较差。此外,思维链 (Chain-of-Thought, CoT) 等技术也被用于优化提示结构,例如先生成代码再生成推理过程会更有效。
结构化提示 (Structured)
为了克服自然语言的模糊性,结构化提示将输入的格式变得更规范、机器可解析。例如,使用图(如代码元素间的“关系图”)来表示代码库的依赖关系,可以约束LLM的生成范围,确保修复方案的一致性。另一个例子是分层生成代码仓库,首先生成目录、依赖等“仓库草图”,然后是文件结构,最后才是具体实现,保证了架构的连贯性。即使对于长上下文模型,输入的结构(如代码片段的顺序)也对性能有显著影响。
交互式提示 (Interactive)
交互式提示将静态提示扩展为用户与LLM之间的多轮对话,允许对解决方案进行渐进式优化。系统可以提出澄清性问题以消除歧义,用户则可以提供迭代反馈。例如,\(Clarigen\)框架能识别用户请求中的模糊之处并发起澄清对话。\(ChatDBG\)则将LLM与调试器结合,使其成为一个对话伙伴,允许开发者提出“为什么这个变量是空的?”这类高层次问题。然而,当反馈形式不明确时(如仅提供新的I/O示例),交互的有效性可能会降低。
基于微调的解决方案
微调 (Fine-tuning) 是在提示工程之外,使通用LLM专门化于软件工程的关键步骤。它通过在特定领域的代码示例数据集上训练模型来调整其参数。

监督微调 (SFT)
监督微调 (Supervised Fine-Tuning, SFT) 是模型专业化的基石。一个重要趋势是从静态代码快照转向面向过程的数据 (process-oriented data)。例如,\(SWE-GPT\)在模拟软件改进过程(包括仓库理解、故障定位和补丁生成)的数据上进行微调。同样,\(D3\)数据集将代码生成视为一系列文件差异 (diffs) 的序列,训练模型进行迭代式修改。
以数据为中心的SFT(关注数据质量和规模)非常有效。\(SWE-Dev\)通过从GitHub问题中生成大量“从失败到通过”的测试用例,并收集智能体轨迹用于SFT,使得小模型也能追赶大模型的性能。在数据稀疏的形式化验证领域,\(PoPilot\)通过合成数据生成过程,教会模型复杂的证明导向编程推理。
偏好对齐:基于强化学习 (RL-based)
基于强化学习 (Reinforcement Learning, RL) 的对齐方法能够根据复杂的、不可微分的奖励信号(如通过测试套件的代码正确性)来优化LLM。奖励函数的设计是核心。\(ReST-MCTS*\)使用过程奖励模型 (PRM) 来指导蒙特卡洛树搜索 (MCTS),生成高质量的推理轨迹。\(SEAlign\)则利用MCTS评估行动轨迹并识别影响成功的“关键行动”,再通过偏好优化对模型进行微调。\(Outcome Refining Process Supervision (ORPS)\)在推理时根据执行反馈(正确性、运行时、内存使用)和LLM的自我批判动态生成奖励信号,使智能体能够自主学习更优的实现策略。
偏好对齐:无强化学习 (RL-free)
无RL的偏好对齐技术,如直接偏好优化 (Direct Preference Optimization, DPO),可以直接根据“选择的”和“拒绝的”响应对模型进行优化,避免了RL的复杂性和不稳定性。\(SelfCodeAlign\)流程通过自举方式创建偏好数据集:基础模型为编码任务生成多个响应,然后生成测试用例验证这些响应,只有通过验证的“指令-响应”对才被用于构建偏好数据集。\(Localized Preference Optimization (LPO)\)则在教授LLM安全编码时,仅对安全和不安全代码版本之间存在差异的token应用偏好损失,实现了更精确的优化。
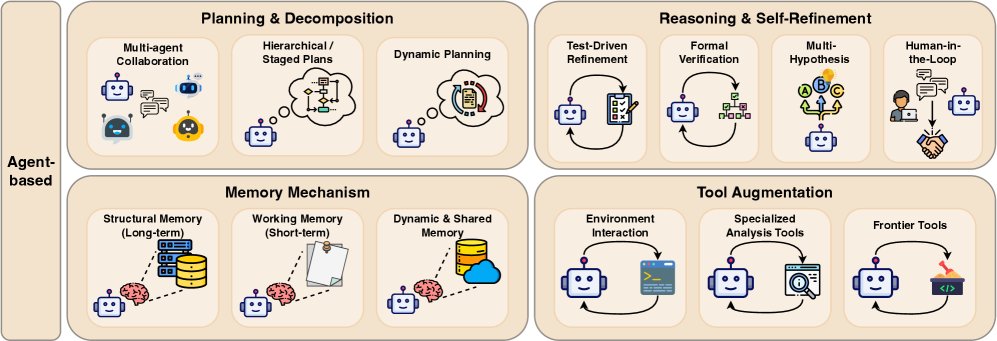
基于智能体的解决方案
基于智能体 (Agent-based) 的系统是LLM驱动软件工程的前沿,将范式从单次生成转变为自主的、多步骤的问题解决。一个“智能体”是能够感知环境、创建和分解计划、利用外部工具并从反馈中学习以实现高层目标的系统。这种方法模仿了人类软件开发的迭代和交互过程。
(原文此处中断)
未来方向
基于对当前领域的系统性分析,本文识别了关键的研究差距并提出了具体的未来方向:
- 多智能体协作框架 (Multi-agent collaboration frameworks):为复杂的软件项目设计协作策略,允许多个智能体共同完成任务。
- 自进化代码生成系统 (Self-evolving code generation systems):构建具备持续学习能力的系统,使其能够随着时间推移自我改进。
- 跨领域知识迁移机制 (Cross-domain knowledge transfer mechanisms):研究如何将一个领域学到的知识和技能有效迁移到另一个软件工程领域。
- 形式化验证与LLM方法的集成 (Integration of formal verification with LLM-based methods):结合形式化方法的严谨性和LLM的灵活性,以生成更可靠、更安全的软件。
这些方向为研究人员提供了超越当前局限、开发下一代软件工程系统的清晰路径。