A Multi-Agent Framework for Stateful Inference-Time Search
-
ArXiv URL: http://arxiv.org/abs/2510.07147v1
-
作者: Arshika Lalan; Rajat Ghosh; Debojyoti Dutta
-
发布机构: Carnegie Mellon University; Nutanix
TL;DR
本文提出了 \(MA<binary data, 2 bytes>S\),一个无需训练的多智能体框架,它通过结合持久化推理时状态、对抗性变异和进化式搜索,显著提升了单元测试中边缘案例 (edge cases) 的生成能力和代码覆盖率。
关键定义
- 有状态的推理时搜索 (Stateful Inference-Time Search): 与传统的无状态(stateless)推理相反,该方法在推理过程中跨多个步骤持久化地维护和更新中间状态(如已生成的测试用例、覆盖率分数、奖励历史等),从而实现更深层次、更连贯的探索和推理。
- 多智能体框架 (Multi-Agent Framework): 将复杂的任务分解给一组专门的智能体协同完成。在本文中,该框架包含五个核心智能体:
- 控制器 (Controller): 协调所有智能体,维护跨阶段的持久化状态,并决定搜索何时终止。
- 行动者 (Actor): 负责根据当前状态和源代码,生成候选的边缘案例。
- 对抗者 (Adversary): 通过对源代码进行变异(mutation),生成用于评估测试用例鲁棒性的“靶子”,从而引导搜索发现更深层次的缺陷。
- 评论家 (Critic): 评估行动者生成的边缘案例,并根据覆盖率、变异分数和异常发现情况计算出一个综合奖励分数。
- 执行者 (Executor): 提供一个安全的沙箱环境(sandboxed environment),用于执行代码和测试,并返回覆盖率等客观反馈。
- 对抗性引导的 Actor-Critic (Adversarially Guided Actor-Critic, AGAC): 一种在推理时使用的搜索机制。行动者提出方案(边缘案例),评论家根据对抗者(代码变异)提供的挑战性环境对方案进行打分。此过程不涉及模型参数的梯度更新,而是通过奖励信号来指导进化式搜索。
- 进化式保留 (Evolutionary Preservation): 一种搜索策略,通过在迭代过程中保留和传递高质量的候选解(精英),来确保解的多样性并避免陷入局部最优。
相关工作
当前,基于大型语言模型(LLM)的代码生成和测试自动化取得了显著进展。然而,现有方法仍面临诸多瓶颈:
- 无状态推理的局限: 大多数LLM的推理是无状态的,每次调用都丢弃中间思考过程。这在需要深度、多步推理的任务(如程序综合、复杂问题求解)中表现不佳,因为它们难以处理长程逻辑依赖和进行有效的探索。
- 现有框架的不足: 虽然出现了一些多智能体协作框架(如 \(AI Co-scientist\)),但它们通常缺乏持久化状态和结构化的奖励信号。而一些基于搜索的方法(如进化算法)虽然能探索组合行为,但又未能有效地整合对抗性评估或跨代维护状态。
- 适应性与覆盖率问题: 许多测试生成器采用前馈方式或依赖微调,难以动态适应未见过的代码库,并且生成的测试用例在覆盖率和鲁棒性方面常常不足。
本文旨在解决这些问题,提出一个无需训练的框架,它通过统一多智能体推理、对抗性评估和带持久化状态的进化式搜索,来系统性地生成高质量、高覆盖率的边缘案例,从而动态适应新代码并发现深层缺陷。
本文方法
本文的核心思想是,生成语法正确的单元测试相对容易,但识别出具有足够覆盖率和鲁棒性的边缘案例则需要结构化的探索、记忆和对抗性验证。为此,本文设计了一个名为 \(MA<binary data, 2 bytes>S\) (Multi-Agent framework for Stateful inference-time search) 的框架。
总体架构
\(MA<binary data, 2 bytes>S\) 将单元测试生成分解为两个阶段:首先通过一个有状态的多智能体进化式搜索过程生成边缘案例,然后将这些高质量的边缘案例转换为最终的单元测试文件。其核心是边缘案例的生成过程,由控制器协调四个智能体(Actor, Executor, Adversary, Critic)在 N 个阶段中迭代进行。
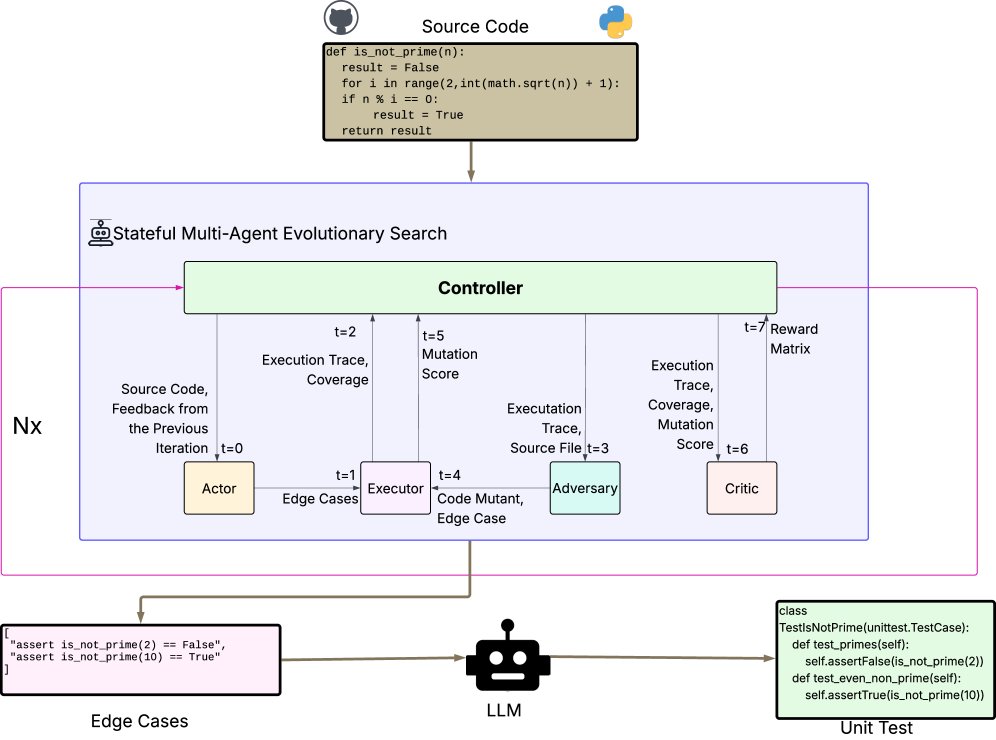
上图展示了 \(MA<binary data, 2 bytes>S\) 的整体架构。蓝色框内是核心的进化式搜索循环,品红色线条突出显示了贯穿 N 个阶段的持久化状态流。
智能体角色与工作流程
该框架是一个在推理时运行的对抗性引导 Actor-Critic(AGAC)系统,无需梯度学习。
-
状态 (State): 在每个阶段 \(n\) 开始前,控制器维护一个持久化的状态 \(S_{n-1}\),它包含了之前所有阶段的历史信息:
\[S_{n-1}=\Big(\zeta_{1:n-1},\mu_{1:n-1},\kappa_{1:n-1},c_{1:n-1},R_{1:n-1}\Big)\]其中 \(ζ\) 是边缘案例序列,\(μ\) 是变异分数,\(κ\) 是覆盖率,\(c\) 是异常信号,\(R\) 是奖励历史。
- 行动者 (Actor): 在第 \(n\) 阶段,行动者 \(A_n\) 负责生成一组候选边缘案例 \(ζ_n\)。
- 在初始阶段(\(n=1\)),由于没有历史状态,行动者通过基于规则的启发式方法(如边界值分析)进行冷启动 (cold-start)。
-
在后续阶段(\(n>1\)),行动者通过 LLM 的上下文学习 (in-context learning) 生成,其提示 (prompt) 中包含了历史状态 \(S_{n-1}\) 和源代码 \(f\):
\[\zeta_{n}=\mathcal{A}(f,S_{n-1})\]
-
对抗者 (Adversary): 对抗者 \(D_n\) 对源代码 \(f\) 生成一组变体(mutants)\({f'_{n,j}}\)。然后,它评估行动者生成的边缘案例 \(ζ_n\) 是否能“杀死”(即识别出)这些变体。最终计算出一个变异分数 \(μ_n\),作为测试鲁棒性的信号。
\[\mu_{n}=\frac{\text{Number of mutants killed by }\zeta_{n}}{\text{Total number of generated mutants}}\] -
评论家 (Critic): 评论家 \(C_n\) 将覆盖率 \(κ_n\)、变异分数 \(μ_n\) 和异常发现信号 \(c_n\) 融合成一个标量奖励 \(R_n\)。奖励函数设计如下:
\[R_{n}^{\text{unnormalized}}(\kappa_{n},\mu_{n},c_{n})=[\alpha\cdot c_{n}+\beta(\kappa_{n}+\max(0,(\kappa_{n}-\theta)\cdot 0.5))]\times\gamma\cdot\mu_{n}\]其中 \(α, β, γ, θ\) 是超参数。该函数鼓励发现异常、奖励超过特定阈值 \(θ\) 的高覆盖率,并确保测试用例必须具备鲁棒性(高 \(μ_n\))才能获得高分。
-
执行者 (Executor): 在一个隔离的 Docker 环境中运行所有测试,为评论家和对抗者提供可靠的覆盖率和执行结果反馈,同时保证系统安全。
-
控制器 (Controller): 负责整个流程的编排。它更新持久化状态 \(S_n\),并在每次迭代后检查是否满足终止条件,例如总奖励达到阈值 \(τ\) 或奖励在最近 \(p\) 次迭代中趋于平稳(变化小于 \(δ\))。
\[\sum_{i}R_{i}\geq\tau\;\;\text{or}\;\;\max_{i\in[n-p+1,\,n]}R_{i}\;-\;\min_{i\in[n-p+1,\,n]}R_{i}\leq\delta\]
核心创新
该框架的智能性并非来自模型训练,而是源于其推理时的结构化协作:
- 持久化非马尔可夫状态: 控制器维护的结构化历史状态,使行动者(LLM)能够基于丰富的上下文进行推理。这相当于一种无需梯度更新的、在推理时进行的轻量级策略调整。
- 对抗性引导与评估: 对抗者的代码变异和评论家的综合奖励设计,有效“锚定”了行动者的输出,迫使其超越表面语法正确性,去探索真正有价值的边缘案例。
- 进化式精英保留: 框架保留了历史上表现最好的边缘案例群体,避免了单路径推理的脆弱性,从而在不进行专门训练的情况下提升了鲁棒性。
实验结论
实验设置
- 模型: 使用了 Llama、Gemma 和 GPT 三个系列的 LLM。
- 数据集:
- HumanEval: 一个包含164个Python编程问题的标准代码生成基准。
- TestGenEvalMini: 一个从真实世界代码库中精选出的包含48个任务的单元测试生成基准。相比于其完整版 TestGenEvalLite,它在保持了相似代码复杂度的同时,优化了执行效率,适合快速实验。
| 指标 | TestGenEvalLite (160个任务, 11个库) | TestGenEvalMini (48个任务, 6个库) |
|---|---|---|
| 代码行数 | $906.57\pm 821.67$, 中位数 = 584 | $575.79\pm 600.78$, 中位数 = 425 |
| 函数数量 | $46.27\pm 53.80$, 中位数 = 31 | $33.81\pm 37.38$, 中位数 = 28 |
| 分支数量 | $79.87\pm 84.46$, 中位数 = 52 | $60.06\pm 70.57$, 中位数 = 40 |
- 基线 (Baselines): 零样本 (zero-shot)、一样本 (one-shot)、三样本 (three-shot) 的上下文学习 (ICL),并分别对比了带与不带思维链 (Chain-of-Thought, CoT) 的版本。
- 评估指标: 行覆盖率、分支覆盖率、函数覆盖率以及变异分数。
关键结果
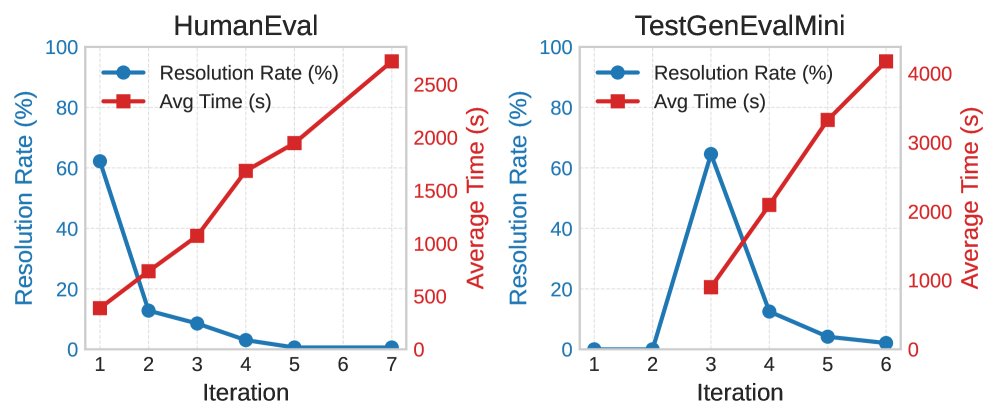
- HumanEval 上的表现: 在这个相对简单的基准上,\(MA<binary data, 2 bytes>S\) 的表现与各基线相当。这被视为一个“健全性检查” (sanity check),因为约62%的问题在第一轮冷启动时就被解决了,显示了框架在简单任务上的高效性,同时也说明需要更复杂的基准来体现其优势。
| HumanEval (Llama 70B) | 行覆盖率 | 分支覆盖率 | 函数覆盖率 |
|---|---|---|---|
| SUT (\(MA<binary data, 2 bytes>S\)) | 90.01% | 89.76% | 91.51% |
| Zero Shot LLM | 82.77% | 81.92% | 85.36% |
| Zero Shot LLM with CoT | 86.90% | 86.73% | 87.5% |
| One Shot LLM with CoT | 87.21% | 87.04% | 88.41% |
| Three Shot LLM | 89.94% | 89.87% | 90.09% |
| Three Shot LLM with CoT | 88.18% | 88.13% | 89.33% |
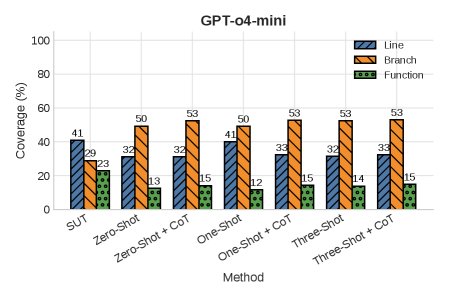
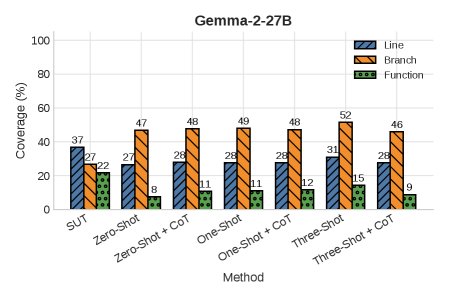
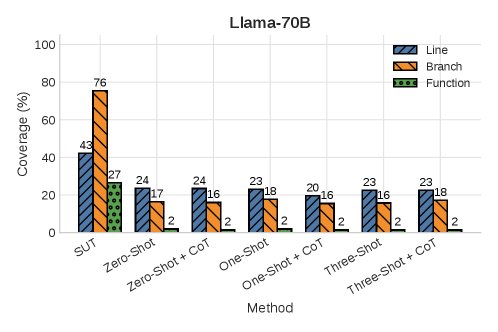
- TestGenEvalMini 上的表现: 在这个更复杂的基准上,\(MA<binary data, 2 bytes>S\) 的优势凸显。
- 在使用 \(Llama 70B\) 模型时,\(MA<binary data, 2 bytes>S\) 在所有覆盖率指标上都显著优于所有基线方法。
- 对于 \(gpt-o4-mini\) 和 \(Gemma-2-27B\) 模型, \(MA<binary data, 2 bytes>S\) 在行覆盖率和函数覆盖率上仍保持领先,但在分支覆盖率上略逊于基线。作者推测这可能是因为搜索过程更偏向于发现能引发异常的测试用例,而这些用例可能只深入探索单一的控制流路径。
- 值得注意的是,少样本学习 (few-shot) 基线中,使用CoT与否几乎没有差异,这反衬出仅靠提示工程难以实现深度推理,需要本文提出的有状态机制。
-
效率与收敛分析: \(MA<binary data, 2 bytes>S\) 在简单任务(HumanEval)上能快速收敛(多数在1轮内完成),而在复杂任务(TestGenEvalMini)上则需要更多迭代次数和更长运行时间来达到高覆盖率,展示了其在效率和效果之间权衡并扩展到复杂任务的能力。
总结
实验结果表明,本文提出的有状态多智能体进化框架在单元测试生成任务上,尤其是在发现高覆盖率的边缘案例方面,显著优于传统的无状态提示方法。这证明了在推理时进行多智能体协同是一种有效的、无需训练即可提升 LLM 推理深度和可靠性的策略。
尽管如此,该框架也存在局限性,如在复杂任务上推理成本较高、运行时间较长。未来的工作将致力于优化执行效率、开发更智能的终止条件,并将其推广到更大规模的工业级代码库中进行验证。