A Multiobjective Reinforcement Learning Framework for Microgrid Energy Management
-
ArXiv URL: http://arxiv.org/abs/2307.08692v2
-
作者: Tri Dao
-
发布机构: Cornell University
TL;DR
本文提出了一个结合多目标进化算法与强化学习的新颖框架,用于解决微电网 (Microgrid, MG) 能源管理中的多目标优化问题,实现了在处理成本、排放和热能浪费等冲突目标时的性能提升和策略可解释性。
关键定义
本文提出或沿用了以下对理解其核心方法至关重要的概念:
- 多目标强化学习框架 (Multi-Objective Reinforcement Learning, MORL, Framework): 本文的核心创新,是一个将多目标进化算法(具体为 Borg MOEA)与强化学习相结合的特定框架。在此框架中,进化算法负责优化强化学习智能体中策略网络的参数,以探索和发现多组代表不同权衡的帕累托最优策略。
- 参数化策略 (Parametric Policy): 指使用一个带有参数 $\theta$ 的函数(本文中为人工神经网络 ANN)来近似决策策略,即 $\pi_{\theta}$。该策略直接将可观测的状态信息映射到行动上,从而减少了需要学习的参数数量,并使策略能够泛化到未见过的状态。
- 状态变量分解 (State Variable Decomposition): 本文将系统的状态 $S_t$ 分解为三个部分:可观测的外部信息 $W_t$(如天气预报、日前电价)、不可观测的变量 $H_t$(如实时负荷、可再生能源出力)和前一时刻的可观测行动 $Y_t$。智能体仅基于可观测部分 $W_t$ 和 $Y_t$ 做出决策。
- 时变敏感性分析 (Time-Varying Sensitivity Analysis, TVSA): 一种用于解释已训练策略的分析技术。它通过方差分解来量化在每个时间点上,智能体的决策变化在多大程度上是由不同的输入信息(如温度、电价)引起的,从而揭示了策略对外部信息的动态依赖关系。
相关工作
微电网的能源管理通常被建模为马尔可夫决策过程 (Markov Decision Process, MDP),传统上使用动态规划 (Dynamic Programming, DP) 求解。然而,DP方法受困于“维度灾难”,且需要精确的系统模型(状态转移概率),这在复杂的能源系统中难以获得。
为了克服这些问题,强化学习 (Reinforcement Learning, RL) 作为一种无模型 (model-free) 的方法被广泛应用。但现有RL研究大多集中于单一目标(如成本最小化),这无法充分代表不同利益相关方在多个冲突目标(如环境影响、运行可靠性)上的诉求。
处理多目标问题的常用方法是加权求和法,它将多目标转化为单目标。这种方法的弊端在于难以发现所有帕累托最优解,尤其是在非凸问题中,并且需要预先设定权重,可能忽略更优的权衡方案。
本文旨在解决的核心问题是:如何在不依赖精确系统模型的情况下,有效处理微电网能源管理中存在的多个、相互冲突的、非线性的随机控制目标,并为决策者提供一组多样化的、显式表示目标间权衡的帕re托最优控制策略。
本文方法
本文提出了一个新颖的无模型多目标强化学习 (MORL) 框架,用于优化含热电联产 (Combined Heat and Power, CHP) 的微电网能源调度问题。该框架的核心是将多目标进化算法 (MOEA) 与基于人工神经网络 (ANN) 的参数化策略相结合,直接在策略空间中进行搜索,以识别出一组帕累托最优的控制策略。
框架概述
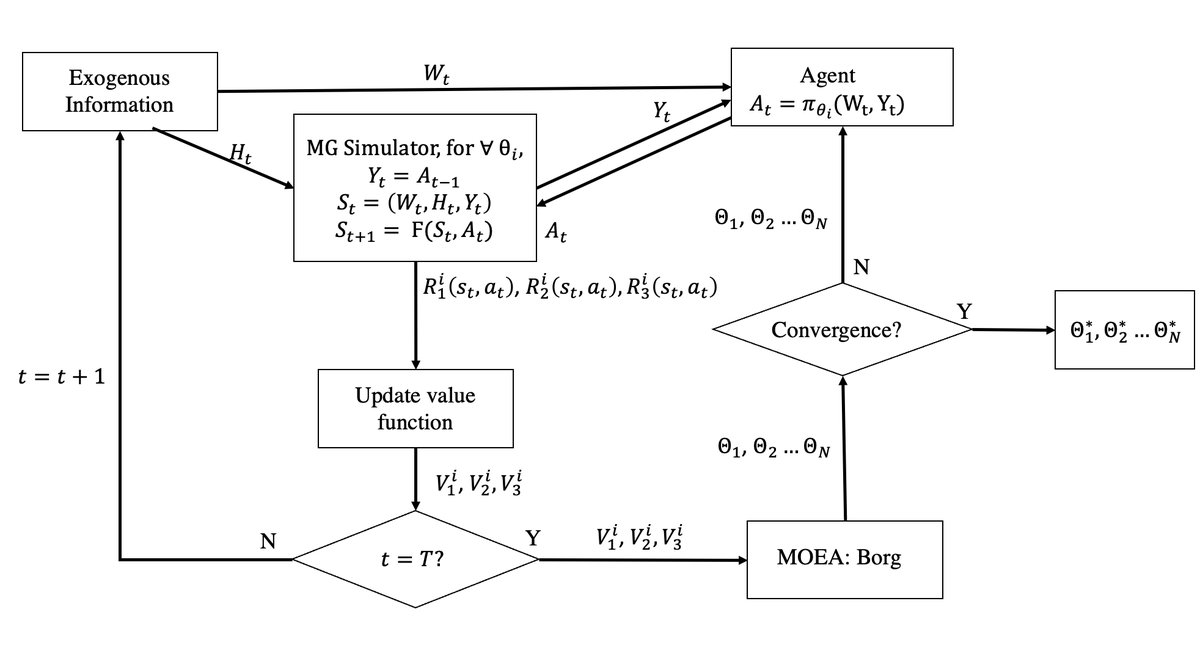
整个框架如图3所示,形成一个闭环优化过程:
- 策略优化: Borg MOEA 作为外部优化器,负责生成并迭代一组人工神经网络 (ANN) 的参数 $\theta$。每一个 $\theta$ 都定义了一个完整的控制策略。
- 环境交互: 对于每一个策略 $\pi_{\theta}$,智能体在微电网模拟器中与环境进行交互。在每个时间步 $t$,智能体根据可观测状态 $(W_t, Y_t)$ 做出决策 $A_t$。
- 性能评估: 模拟器根据决策 $A_t$ 和系统中的不确定性因素 $H_t$ 来更新系统状态,并计算出对应三个目标(成本、排放、热能浪费)的即时奖励 ($R_1, R_2, R_3$)。
- 反馈: 在一个完整的模拟周期(例如一天)和多个随机场景结束后,计算每个策略 $\pi_{\theta}$ 在三个目标上的累积期望回报 $(V_1, V_2, V_3)$。这个多维度的性能向量将作为反馈提供给 Borg MOEA。
- 进化: Borg MOEA 根据所有策略的性能反馈,使用其进化算子(如交叉、变异)生成新一代更优的策略参数,并重复此过程,直到找到一组近似的帕累托最优策略集。
智能体设计与策略近似
本文方法的创新点在于其智能体的设计,特别是策略的表示方式。
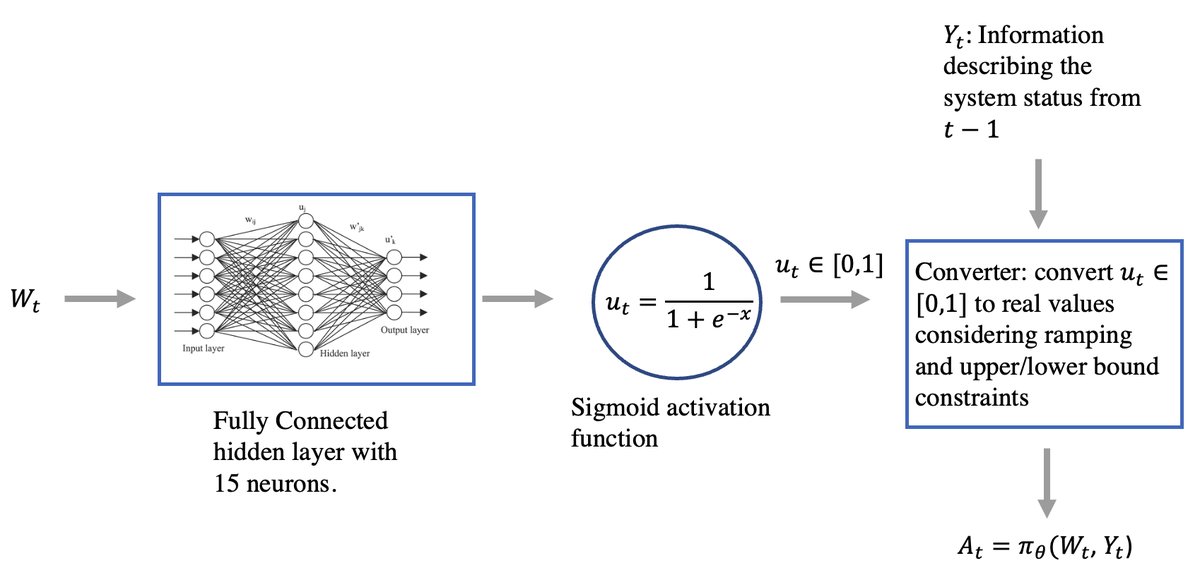
- 策略近似: 智能体的策略 $\pi_{\theta}$ 被一个多输入多输出的 ANN (如图2) 所参数化。
- 输入: ANN 的输入是可观测的外部信息 $W_t$(如温度、风速、日前电价等)和上一时刻的动作 $Y_t$。
- 架构: 采用一个包含15个神经元的单隐藏层全连接网络,激活函数为 Sigmoid。
- 输出: ANN 输出归一化的控制信号 $u_t \in [0,1]$,这些信号随后根据设备的物理约束(如爬坡速率、功率限制)被转换为实际的控制动作 $A_t$(如CHP的发电和产热功率)。这种共享隐藏层的架构使得不同设备的控制决策能够相互协调。
优化算法与可解释性
-
Borg MOEA 的作用: 与传统的基于梯度的策略搜索不同,本文采用 Borg MOEA。该算法善于处理高维、非线性的复杂问题,并通过自适应算子和 $\epsilon$-支配等技术来避免陷入局部最优,能够有效地在策略参数空间中搜索,以发现几何形状复杂的帕累托前沿。
-
策略可解释性: 为了打开ANN这个“黑箱”,本文引入了时变敏感性分析 (TVSA)。通过对已训练好的策略函数(即ANN)进行分析,可以量化各个外部信息输入(如温度、电价)在不同时刻对决策输出的贡献度。该方法的数学表达式如下:
这个分析使得运行人员能够理解策略在一天中不同时段是依据何种信息做出关键决策的,增强了对AI决策的信任和理解。
实验结论
本文将所提出的 MORL 框架应用于康奈尔大学微电网 (CU-MG) 的实际案例中,该微电网是一个复杂的热电联产系统。实验数据涵盖了冬夏两季,并分别进行了训练和测试。
目标权衡分析
- 性能超越现状: 实验结果表明,通过 MORL 框架找到的所有帕累托最优策略在成本、排放和热能浪费三个目标上均优于当前的实际运行策略(见图4和图5中的红叉)。
- 揭示非线性权衡: 框架成功地揭示了三个目标之间复杂的非线性与非凸权衡关系。如图4和图5所示,在达到帕累托最优后,降低排放必然导致成本增加,反之亦然。这为决策者提供了丰富的选择空间,以根据不同优先级进行决策。
- 显著的改进潜力: 以一个“低排放折衷”策略为例(见下表),与当前运行策略相比,该策略在不牺牲成本的情况下,冬季和夏季的排放量可分别减少20%和25%,同时热能浪费也显著降低。这表明仅利用现有的天气和价格信息,就能大幅提升运营效益。
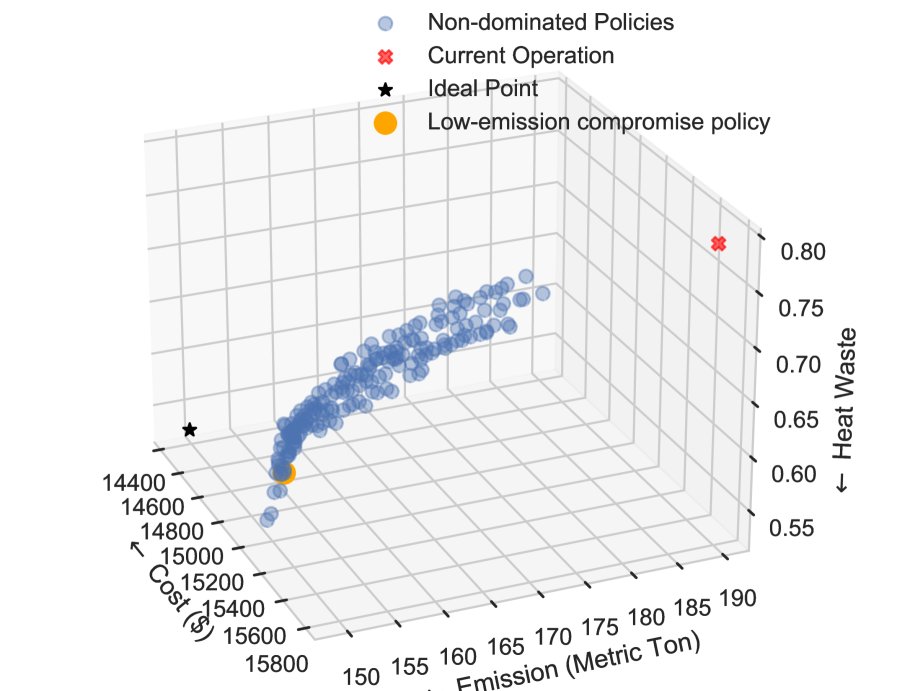
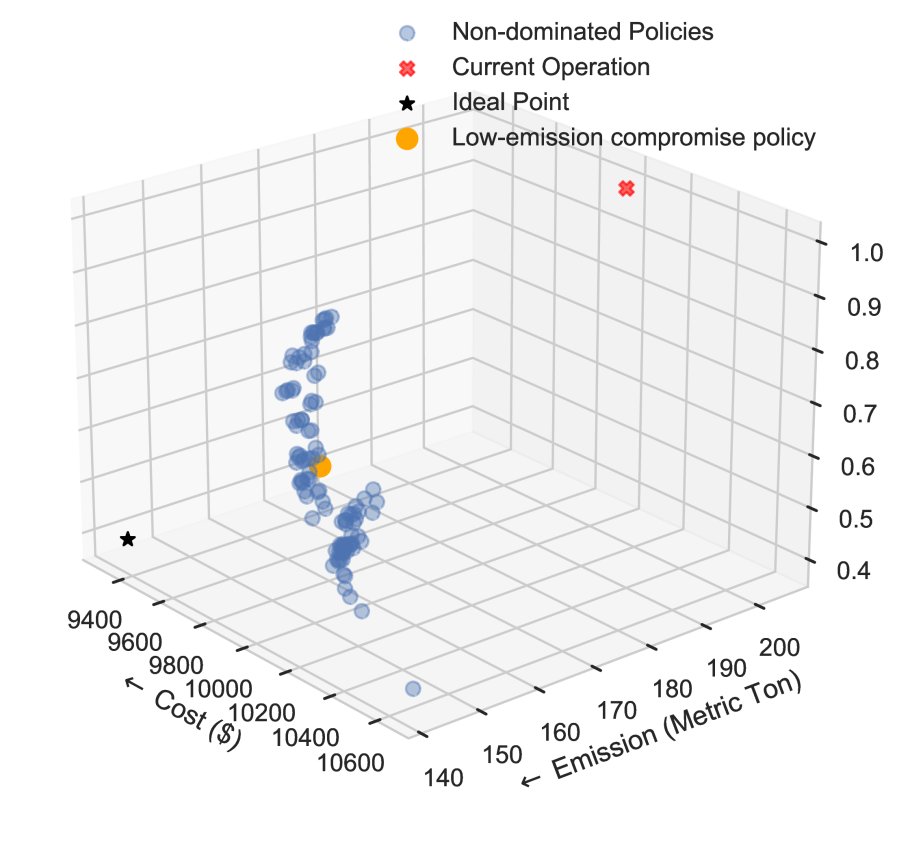
表 I: 代表性策略与当前运行策略的比较
| 季节 | 策略 | 成本 ($/天) | 排放 (公吨/天) | 热能浪费 |
|---|---|---|---|---|
| 冬季 | 当前运行 | 15,784 | 189.79 | 0.7878 |
| 代表性策略 | 15,201 | 151.36 | 0.5756 | |
| 夏季 | 当前运行 | 10,025 | 205.26 | 0.9923 |
| 代表性策略 | 9,902 | 154.83 | 0.6083 |
策略行为分析
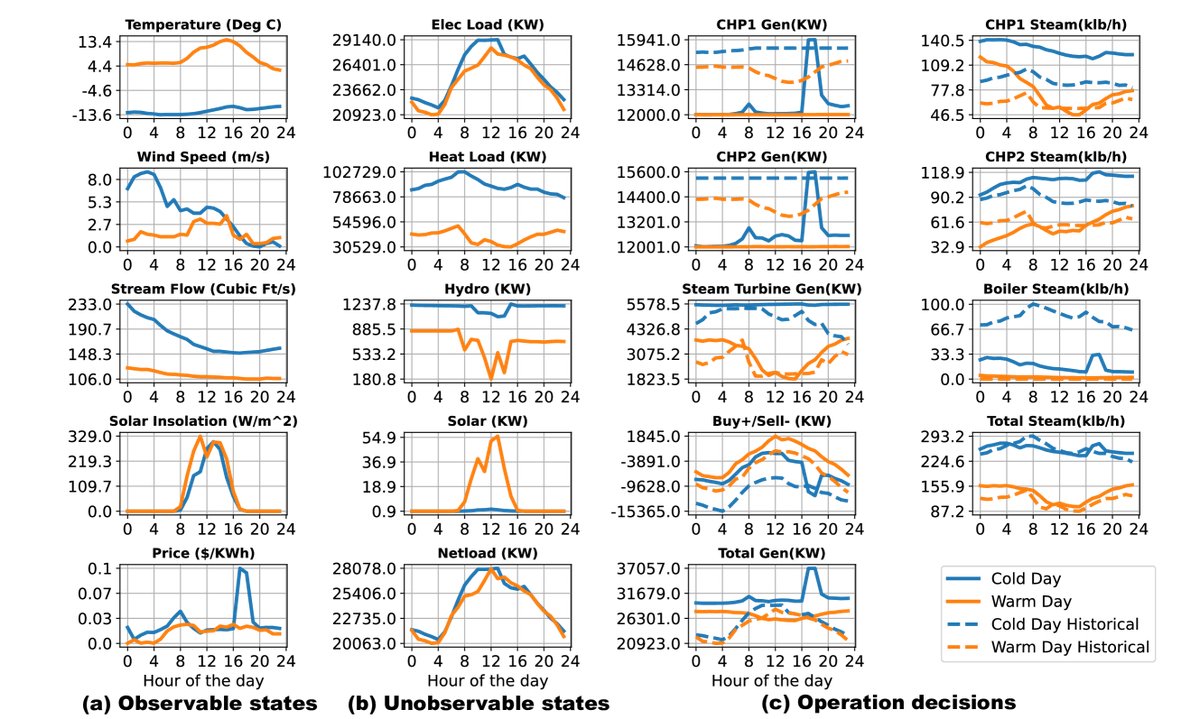
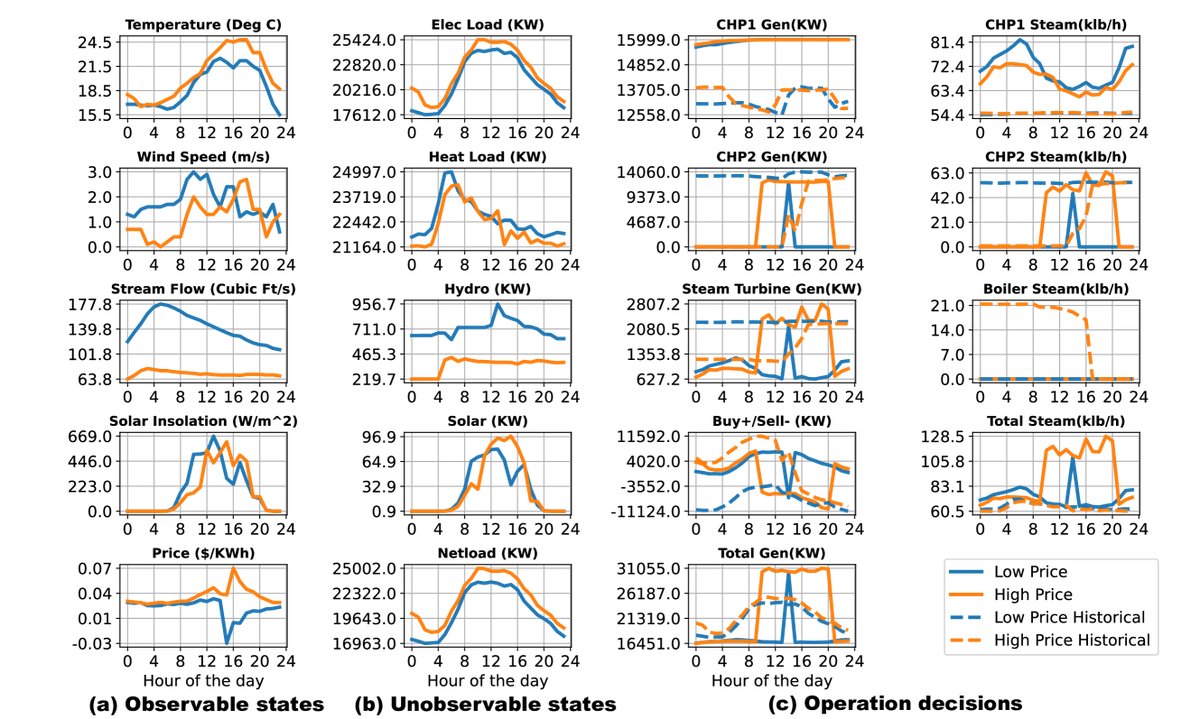
通过分析代表性策略在具体某几天的逐时行为,可以观察到以下特点:
- 自适应性: 策略能根据可观测的外部信息(如温度、电价)动态调整行为。例如,在冬季寒冷天气,CHP发电量会跟随电价峰值波动;但在温暖天气,即使电价高,CHP也保持最低出力以避免浪费。
- 协同性: 策略在多个发电设备之间表现出协同作业。例如,在热负荷较低时,一个CHP机组会减少产热,而另一个增加,以精确满足需求,这得益于ANN的共享信息架构。
- 效率提升: 策略学会了优先使用效率更高的设备(如用CHP替代锅炉产热),并能有效利用价格信号进行套利,例如在负电价时避免向电网售电,而在价格高峰时增加售电以弥补其他时段的成本。
最终结论
本文提出的MORL框架是解决复杂微电网多目标能源管理问题的有效工具。它不仅能够在不确定性下找到一系列优于现状的帕累托最优策略,还能通过TVSA等技术提供可解释的洞见,揭示策略如何利用外部信息进行自适应和协同决策,为实际电网运营商提供了兼顾多个目标并理解其间权衡的强大决策支持。