A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity
-
ArXiv URL: http://arxiv.org/abs/2302.04023v4
-
作者: Yan Xu; Dan Su; Pascale Fung; Willy Chung; Tiezheng Yu; Yejin Bang; Nayeon Lee; Quyet V. Do; Holy Lovenia; Ziwei Ji; 等3人
-
发布机构: Centre for Artificial Intelligence Research; The Hong Kong University of Science and Technology
TL;DR
本文提出了一个全面的评估框架,对ChatGPT在多任务、多语言、多模态、推理、幻觉和交互性方面进行了系统的量化评估,揭示了其在多数零样本任务上的卓越表现,同时也指出了其在低资源语言、复杂推理和事实性方面的显著局限。
关键定义
本文主要沿用现有概念,但为评估框架明确了以下关键分类和定义:
- 语言资源类别 (Language Resource Categories):根据语言在 CommonCrawl 数据集中的占比,将语言分为四类,用于评估多语言能力:
- 高资源语言 (High-Resource Language, HRL):占比 $\geq 1\%$。
- 中等资源语言 (Medium-Resource Language, MRL):占比 $\geq 0.01\%$。
- 低资源语言 (Low-Resource Language, LRL):占比 $\geq 0.0001\%$。
- 极低资源语言 (Extremely Low-Resource Language, X-LRL):占比 $< 0.0001\%$。
- 推理能力分类 (Reasoning Categories):为细致评估模型的思维能力,将推理划分为多个子类别,包括逻辑推理(演绎、归纳、溯因)、非文本语义推理(数学、时序、空间)、常识推理、因果推理、多跳推理和类比推理。
- 代码作为中间媒介 (Code as Intermediate Medium):一种评估纯文本模型多模态能力的方法。通过提示ChatGPT生成可渲染的代码(如SVG),将文本描述转化为视觉图像,从而间接测试其视觉理解和生成能力。
- 幻觉 (Hallucination):沿用通用定义,指模型生成不基于源文本或不符合事实的信息。本文特别关注两种类型:内在幻觉 (intrinsic hallucination)(与源内容矛盾)和外在幻觉 (extrinsic hallucination)(无法从源内容验证,可能是事实或非事实)。
相关工作
尽管ChatGPT广受欢迎,并展现出强大的能力,但其真实的性能边界和具体局限性在论文发表初期(2023年2月)并不清晰,大多依赖于零散的坊间案例。当时,OpenAI并未发布其官方基准测试结果,而现有的大型语言模型 (Large Language Model, LLM) 已知存在幻觉、在低资源语言上表现不佳、推理能力欠缺等问题。
因此,本文旨在解决缺乏对ChatGPT进行系统性、量化、第三方评估这一问题。研究者们提出了一套全面的评估框架,使用公开可用的标准测试集,旨在为学术界和普通用户提供一个关于ChatGPT在各项任务中能做什么、不能做什么的清晰画像。
本文方法
本文的核心是一种覆盖多维度能力的综合评估框架。通过在23个公开数据集上进行实验,系统性地探究了ChatGPT的能力边界。
多任务、多语言、多模态评估
多任务能力
本文评估了ChatGPT在8大类NLP任务上的零样本 (zero-shot) 性能,包括摘要、机器翻译、情感分析、问答、任务导向对话等,并与领域内最先进的 (SOTA) 微调模型和零样本模型进行比较。
| 任务 | 数据集 | 指标 | 微调SOTA | 零样本SOTA | ChatGPT |
|---|---|---|---|---|---|
| 摘要 | CNN/DM | ROUGE-1 | 44.47 | 35.27 | 35.29 |
| SAMSum | ROUGE-1 | 47.28 | - | 35.29 | |
| 机器翻译 (XXX→Eng) | FLoRes-200 (HRL) | ChrF++ | 63.5 | - | 58.64 |
| FLoRes-200 (LRL) | ChrF++ | 54.9 | - | 27.75 | |
| 机器翻译 (Eng→XXX) | FLoRes-200 (HRL) | ChrF++ | 54.4 | - | 51.12 |
| FLoRes-200 (LRL) | ChrF++ | 41.9 | - | 21.57 | |
| 情感分析 | NusaX - Eng | Macro F1 | 92.6 | 61.5 | 83.24 |
| NusaX - Ind | Macro F1 | 91.6 | 59.3 | 82.13 | |
| NusaX - Jav | Macro F1 | 84.2 | 55.7 | 79.64 | |
| NusaX - Bug | Macro F1 | 70.0 | 55.9 | 55.84 | |
| 问答 | bAbI task (15—16) | Accuracy | 100—100 | - | 93.3—66.7 |
| EntailmentBank | Accuracy | 86.5 | 78.58 | 93.3 | |
| CLUTRR | Accuracy | 95.0 | 28.6 | 43.3 | |
| StepGame (k=9—k=1) | Accuracy | 48.4—98.7 | - | 23.3—63.3 | |
| Pep-3k | AUC | 67.0 | - | 93.3 | |
| 错误信息检测 | COVID-Social | Accuracy | 77.7 | 50.0 | 73.3 |
| COVID-Scientific | Accuracy | 74.7 | 71.1 | 92.0 | |
| 任务导向对话 | MultiWOZ2.2 | JGA | 60.6 | 46.7 | 24.4 |
| MultiWOZ2.2 | BLEU | 19.1 | - | 5.65 | |
| MultiWOZ2.2 | 信息率 | 95.7 | - | 71.1 | |
| 开放域知识对话 | OpenDialKG | BLEU—ROUGE-L | 20.8—40.0 | 3.1—29.5 | 4.1—18.6 |
| OpenDialKG | FeQA | 48.0 | 23.0 | 15.0 |
发现:
- 多任务泛化性强:在13个有零样本SOTA记录的数据集中,ChatGPT在9个上表现更优。在4个任务上甚至超过了为特定任务完全微调的模型。
- 对话任务表现不佳:在任务导向对话和知识驱动的开放域对话中,ChatGPT的性能远低于微调模型。它难以在多轮对话中维持信念状态,且倾向于在提供知识范围之外产生幻觉。
多语言能力
本文从语言理解和语言生成两个维度评估ChatGPT的多语言能力。
- 语言理解:通过情感分析 (SA) 和语言识别 (LID) 任务进行测试。
| 语言 | 类别 | 情感分析准确率 | 语言识别准确率 |
|---|---|---|---|
| 英语 | HRL | 84% | 100% |
| 印尼语 | MRL | 80% | 100% |
| 爪哇语 | LRL | 78% | 0% |
| 布吉语 | X-LRL | 56% | 12% |
结果显示,ChatGPT的性能与语言资源量强相关,尤其在极低资源语言(如布吉语)上表现急剧下降。有趣的是,它能理解爪哇语的情感,却无法识别出该语言。
- 语言生成:通过机器翻译任务进行评估。
| 语言 | 类别 | XXX→Eng 正确数 | Eng→XXX 正确数 |
|---|---|---|---|
| 中文 | HRL | 24/30 | 14/30 |
| 法语 | HRL | 29/30 | 25/30 |
| 印尼语 | MRL | 28/30 | 19/30 |
| 韩语 | MRL | 22/30 | 12/30 |
| 爪哇语 | LRL | 7/30 | 6/30 |
| 巽他语 | LRL | 9/30 | 0/30 |
结果表明,ChatGPT在翻译到英语(理解)方面优于从英语翻译到其他语言(生成),尤其是在处理非拉丁脚本语言(如中文、韩语)和低资源语言时,生成能力是其主要瓶颈。
多模态能力
由于ChatGPT是纯文本模型,本文设计了一个创新的“画国旗”任务来评估其多模态潜力。该方法利用代码(SVG格式)作为文本和视觉之间的桥梁。
流程:
- 要求ChatGPT用文字描述一个指定国家的国旗。
- 要求它根据自己的描述生成该国旗的SVG代码。
- 如果生成的图像有误,通过多轮对话要求其修正。
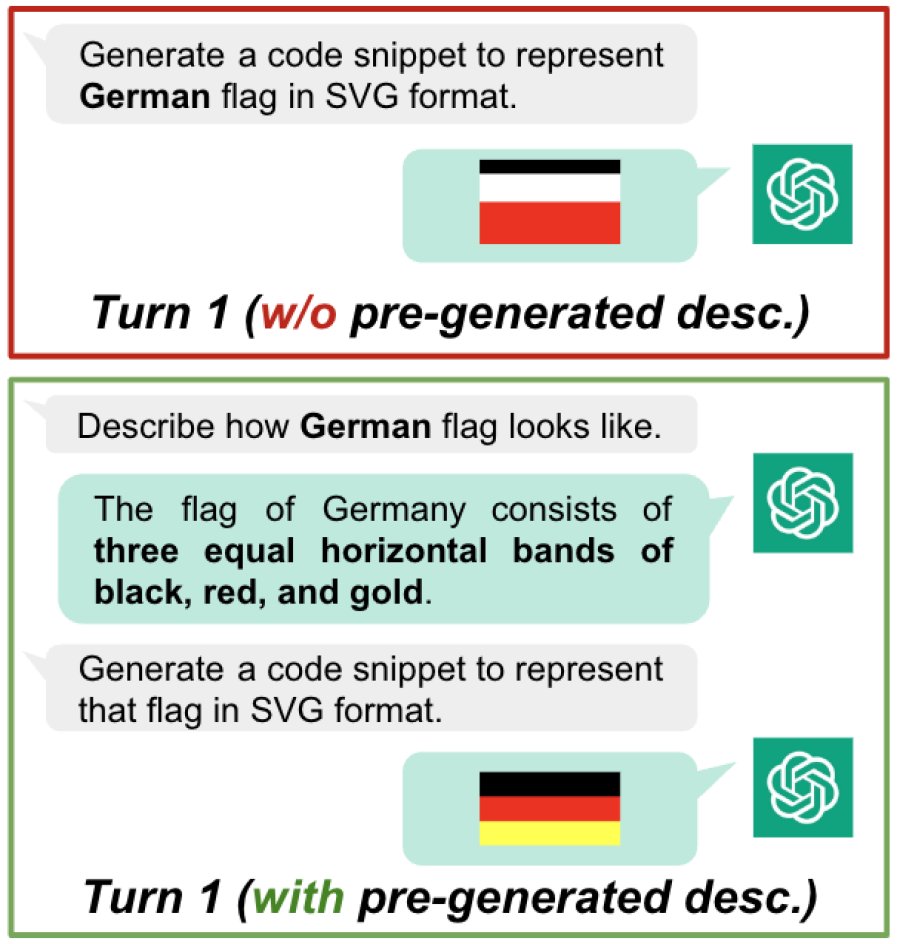
发现:
- 自我描述有助于生成:先生成文本描述再进行代码生成(一种“思维链”),能显著提高图像质量。
- 初级插画师水平:ChatGPT能画出基本轮廓,但在处理复杂形状(如加拿大国旗的枫叶)和精确尺寸方面表现不佳。最常见的错误类型是形状/尺寸错误(68%)。
推理能力评估
本文对ChatGPT的10种不同类型的推理能力进行了细粒度评估。
| 类别 | 测试集 | 结果 |
|---|---|---|
| 演绎推理 | EntailmentBank | 28/30 |
| bAbI (task 15) | 28/30 (原始: 19/30) | |
| 归纳推理 | CLUTRR | 13/30 |
| bAbI (task 16) | 20/30 (原始: 0/30) | |
| 溯因推理 | αNLI | 26/30 |
| 数学推理 | Math | 13/30 |
| 时序推理 | Timedial | 26/30 |
| 空间推理 | SpartQA (困难—基础) | 8/32 — 20/32 |
| StepGame (困难—基础) | 7/30 — 19/30 | |
| StepGame (方位) | 17/20 | |
| StepGame (对角) | 11/20 | |
| StepGame (时钟) | 5/20 | |
| 常识推理 | CommonsenseQA | 27/30 |
| PIQA | 25/30 | |
| Pep-3k (困难) | 28/30 | |
| 因果推理 | E-Care | 24/30 |
| 多跳推理 | hotpotQA | 8/30 |
| 类比推理 | Letter string analogy | 30/30 |
主要发现:
- 逻辑推理不均衡:演绎推理能力较强,而归纳推理能力较弱,有时需要显式提示才能进行有效归纳,被称为“懒惰的推理者”。
- 非文本推理能力弱:在数学推理和空间推理上表现差,尤其难以理解时钟方向和对角线关系。
- 常识推理强大:得益于其庞大的参数化知识,ChatGPT在常识推理任务上表现出色。
- 复杂推理是短板:与其它LLM相似,在需要多步推理(Multi-hop)的任务上表现糟糕。
事实性与幻觉评估
- 事实性:在科学内容的错误信息检测 (COVID-Scientific) 上准确率高达92%,但在社会性内容 (COVID-Social) 上准确率较低 (73.33%),且常拒绝回答。在旨在诱导模型模仿人类谬误的TruthfulQA测试集上,ChatGPT有35.38%的回答是不真实的。
- 幻觉:ChatGPT同样存在幻觉问题,主要表现为外在幻觉,即生成无法从源信息中验证的内容。内在幻觉则相对较少。
交互性评估
本文探索了利用ChatGPT的对话接口通过多轮交互提升任务性能的潜力。
- 摘要:通过第二轮“请把摘要写得更短”的指令,摘要长度被有效控制,ROUGE-1得分提升了约8%。
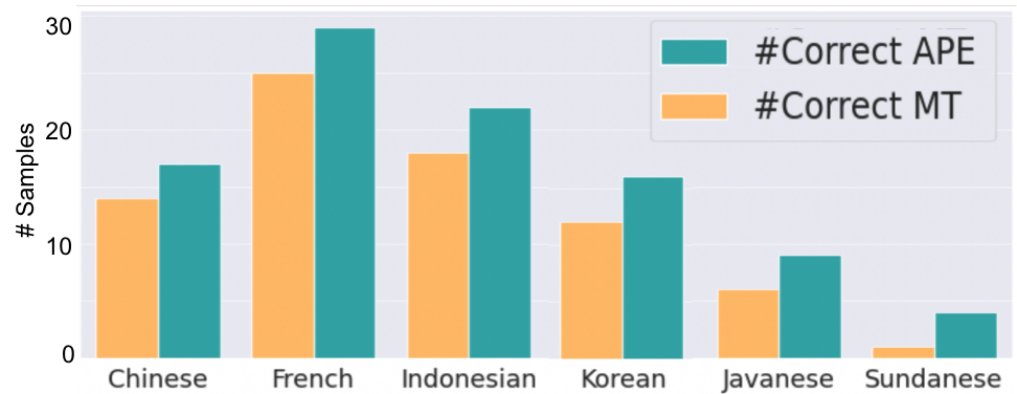
- 机器翻译:在第一轮翻译后,通过后续交互进行自动后期编辑 (Automatic Post-Editing),可以修正部分或全部翻译错误,尤其在低资源语言上效果显著。
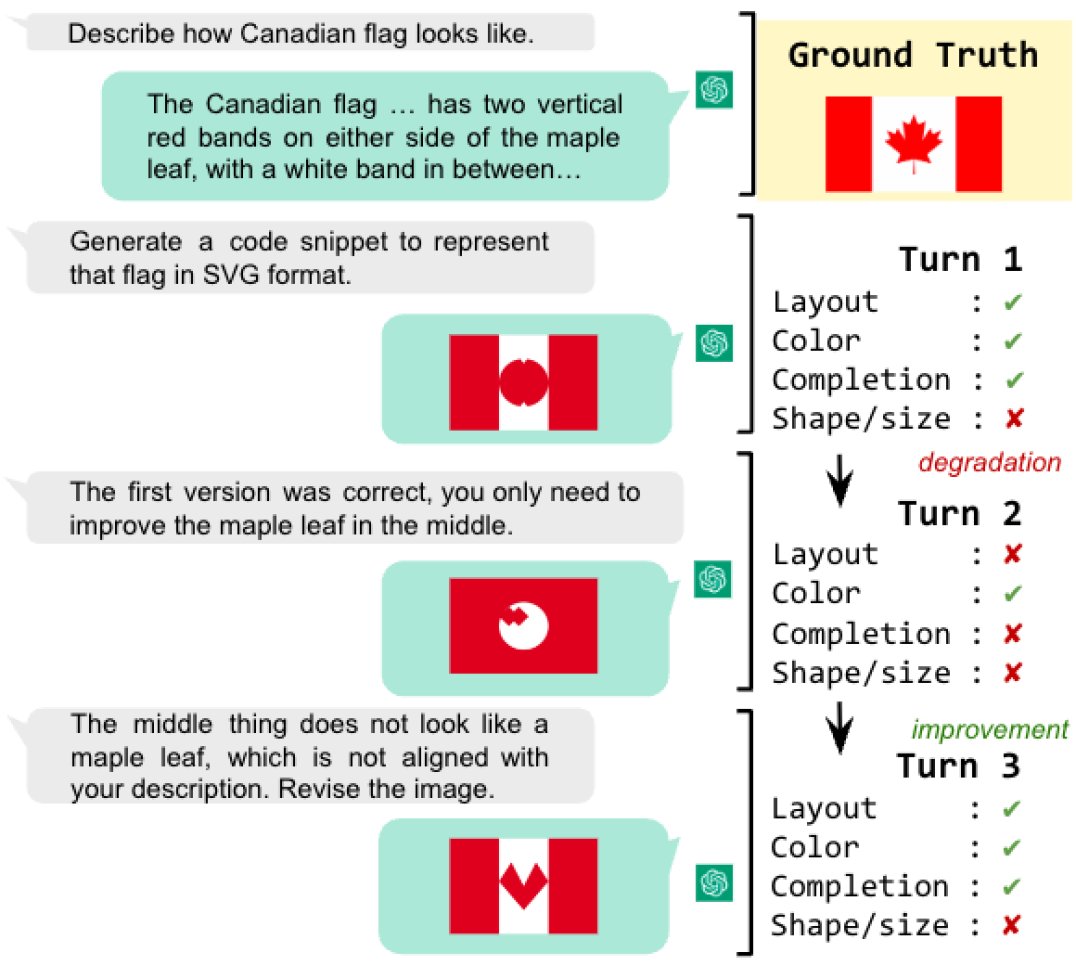
- 多模态生成:在画国旗任务中,通过多轮反馈修正,图像质量逐步提升。例如,加拿大国旗的绘制经过三轮交互,从仅颜色正确逐步修正到布局和组件都正确(尽管枫叶形状仍不完美)。
对GPT-4的评估
本文的更新版本补充了对GPT-4的评估,发现:
- 多任务能力:与ChatGPT相当。
- 多语言能力:在极低资源语言的识别和机器翻译方面优于ChatGPT。
- 推理能力:常识推理能力与ChatGPT接近,但在归纳、数学、多跳、时序和空间推理方面均有显著提升。
实验结论
本文通过一个全面的评估框架,对ChatGPT的能力进行了深入的量化分析,得出了以下核心结论:
- 优势:
- 强大的零样本学习器:在广泛的NLP任务中,其零样本性能优于之前的SOTA LLM,在某些任务上甚至能与完全微调的模型相媲美。
- 有效的交互能力:其多轮对话交互功能是一种强大的“即时提示工程”,可通过用户反馈显著提升摘要、翻译和图像生成等任务的最终效果。
- 丰富的常识知识:在常识推理基准上表现出色。
- 劣势与局限:
- 多语言能力不均衡:对高、中资源语言处理能力较强,但在低资源和极低资源语言上能力严重不足,尤其是在生成非拉丁脚本语言方面。
- 推理能力不可靠:是一个“懒惰的推理者”,在归纳、数学、空间和多跳等需要复杂、非文本或多步逻辑的推理任务上表现不佳,整体平均准确率仅为63.41%。
- 存在幻觉问题:与其它LLM一样,ChatGPT会产生幻觉,特别是生成无法从给定信息中验证的“外在幻觉”,这对其作为可靠信息源构成了挑战。
- 总体结论:ChatGPT是一个功能强大的多面手,但其能力并非均衡。它在利用已有知识进行语言任务上表现出色,但并非一个可靠的“思考者”。未来的研究需要致力于提升其复杂推理的鲁棒性、解决多语言的包容性问题,并开发更有效的机制来缓解幻觉。