A Novel Combined Data-Driven Approach for Electricity Theft Detection
-
ArXiv URL: http://arxiv.org/abs/2411.06649v1
-
作者: Kedi Zheng; Yi Wang; C. Kang; Q. Xia; Qixin Chen
-
发布机构: Tsinghua University
TL;DR
本文提出了一种结合最大信息系数(MIC)和快速搜索密度峰值聚类(CFSFDP)的数据驱动方法,以无监督的方式,仅需少量额外信息(区域总电表数据),即可高效、准确地检测出形态各异的电力盗窃行为。
关键定义
- 非技术性损失 (Non-technical loss, NTL):指由计量篡改、窃电等非技术原因造成的电网供售电量差额。本文中,NTL通过区域总电表读数减去该区域内所有用户智能电表读数之和来计算,是检测窃电行为的关键信号。
- 最大信息系数 (Maximum Information Coefficient, MIC):一种用于衡量两个变量之间关联强度的统计方法。它不仅能捕捉线性关系,还能有效发现复杂的非线性关系。本文用MIC来度量区域NTL与单个用户用电曲线之间的关联性。
- 快速搜索与发现密度峰值的聚类 (Clustering by fast search and find of density peaks, CFSFDP):一种基于密度的无监督聚类算法。它通过计算每个数据点的局部密度(\(ρ\))和与更高密度点的最小距离(\(δ\))来识别簇中心和异常点。本文用它来识别用电形状异常的用户。
- 异常度 (Degree of abnormality, \(ζ_p\)):本文基于CFSFDP提出的一个度量指标,定义为 $\zeta_{p}=\frac{\delta_{p}}{\rho_{p}+1}$。异常点的特征是局部密度\(ρ\)小,而距离\(δ\)大,因此\(ζ_p\)值较高的用户负载曲线被视为形状异常。
相关工作
电力盗窃检测方法主要分为三类:基于人工智能(AI)的方法、基于状态(state-based)的方法和基于博弈论的方法。
- 研究现状与瓶颈:
- AI分类方法:如支持向量机(SVM)、神经网络等,虽然精度高,但严重依赖难以获取的、已标记的窃电行为数据集。
- AI聚类方法:作为无监督方法,不需标签,但难以检测那些用电曲线形状看起来“正常”的窃电行为(例如,按比例减少用电量)。
- 基于状态的方法:通过分析电网的物理状态(电压、电流等)与用户电表数据之间的不一致性来发现窃电。这类方法精度较高,但通常需要详细的电网拓扑结构和额外的测量设备,部署成本高,难以普及。
- 本文待解决问题:现有方法要么需要难以获得的先验知识(如标签、系统拓扑),要么检测精度有限,无法覆盖所有窃电类型。本文旨在开发一个通用框架,它:
- 无需标签:采用无监督学习。
- 信息需求最小:仅需用户用电曲线和区域总电表数据,适用性广。
- 检测范围广:能同时应对改变用电模式(形状异常)和保持模式(仅量值改变)的多种窃电类型。
- 准确率高:结合不同方法的优势,提升整体检测性能。
本文方法
本文提出一个结合了两种互补数据挖掘技术的组合检测框架,分别从“幅度-相关性”和“形状-相似性”两个维度量化用户的窃电嫌疑。
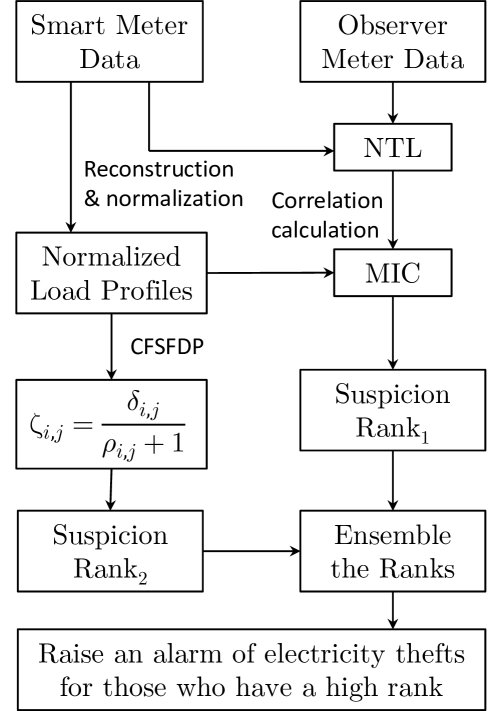 图:MIC-CFSFDP组合检测框架
图:MIC-CFSFDP组合检测框架
创新点
该框架的创新在于将两种先进技术进行优势互补:
- 基于MIC的相关性检测:用于发现那些用电曲线形状正常、但用电量与区域NTL存在强相关性的窃电行为。
- 基于CFSFDP的异常检测:用于发现那些用电曲线形状被篡改得非常规、无规律的窃电行为。
通过结合两种方法的排序结果,该框架能够覆盖更多样的窃电手段,从而提高检测的准确性和鲁棒性。
基于最大信息系数(MIC)的相关性检测
该方法基于一个核心假设:窃电用户的用电行为与区域的非技术性损失(NTL)存在关联。
-
计算NTL:在一个安装了安全观察电表的区域内,NTL可以通过观察电表的总读数 $E_t$ 减去该区域所有用户智能电表读数 $\tilde{x}_{i,t}$ 的总和来计算:
\[e_{t}=E_{t}-\sum_{i\in\mathcal{A}}\tilde{x}_{i,t}\]理论上,这个NTL $e_t$ 主要由窃电用户的窃电量构成。
-
关联性假设:如果一个窃电用户 $i$ 篡改后的电量 $\tilde{x}_{i,t}$ 与其真实用电量 $x_{i,t}$ 仍保持一定关系(如按比例减少),那么其窃电量 $(x_{i,t}-\tilde{x}_{i,t})$ 也会与 $\tilde{x}_{i,t}$ 相关。因此,区域总NTL序列 e 与窃电用户 $i$ 的用电序列 $\tilde{\textbf{x}}_{i}$ 之间的相关性会显著高于正常用户:
\[Corr(\textbf{e},\tilde{\textbf{x}}_{i})\Big{ \mid }_{i\in\mathcal{F}} > Corr(\textbf{e},\tilde{\textbf{x}}_{i})\Big{ \mid }_{i\in\mathcal{B}}\]其中 $\mathcal{F}$ 是窃电用户集合,$\mathcal{B}$ 是正常用户集合。
-
采用MIC:传统的皮尔逊相关系数(PCC)只能检测线性关系。而窃电行为可能更复杂,因此本文采用MIC作为相关性度量 $Corr(\cdot, \cdot)$,因为它能有效捕捉线性和非线性关联。MIC值越高,表明该用户是窃电用户的嫌疑越大。
基于CFSFDP的无监督异常检测
对于某些窃电类型(如随机降低用电量),其篡改后的用电曲线与原始曲线关联性弱,导致MIC方法失效。但这类行为往往会产生形状异常的负载曲线,使其成为数据分布中的“异常点”。
- CFSFDP原理:该算法为每个数据点(这里指每日的负载曲线)计算两个关键指标:
- 局部密度 $\rho_{p}$:点 $p$ 周围邻居点的数量。
- 相对距离 $\delta_{p}$:点 $p$ 与比它密度更高的点中最近那一个的距离。
-
识别异常点:异常点通常远离数据密集的区域,表现为低密度 $\rho_{p}$ 和高距离 $\delta_{p}$。
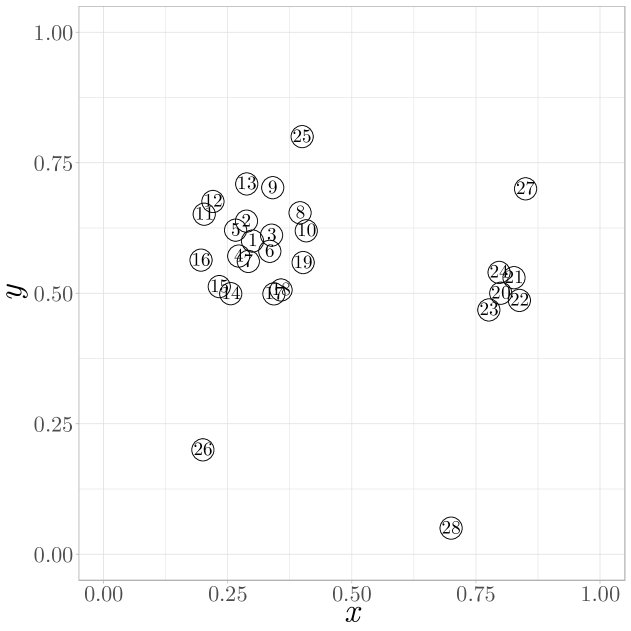 图:数据点分布示例,#26~28为异常点
图:数据点分布示例,#26~28为异常点 图:示例数据点的(ρ, δ)散点图
图:示例数据点的(ρ, δ)散点图 -
计算异常度:本文定义了一个“异常度”指标 $\zeta_{p}$ 来量化每个负载曲线的异常程度:
\[\zeta_{p}=\frac{\delta_{p}}{\rho_{p}+1}\]$\zeta_{p}$ 值越高的用户,其用电曲线形状越可疑。
组合检测框架
该框架将上述两种方法的结果进行融合,得出最终的嫌疑排名。
- 数据预处理:将每个用户每天的负载曲线进行归一化,以专注于形状特征。
- 计算嫌疑度:
- 对每个用户每天的归一化曲线,分别计算其与当天NTL的MIC值。
- 在所有日负载曲线数据集中,计算每条曲线的CFSFDP异常度 $\zeta$ 值。
- 对每个用户,将其多天的MIC值(或$\zeta$值)通过k-means聚类(k=2)分为“正常”和“可疑”两组,取“可疑”组的均值作为该用户的最终MIC嫌疑度(或CFSFDP嫌疑度)。
-
融合排名:根据两种嫌疑度分别对所有用户进行排名,得到 $Rank_1$ (来自MIC) 和 $Rank_2$ (来自CFSFDP)。然后使用算术平均或几何平均来合并这两个排名,得到最终的综合排名:
\[\begin{split} &Rank_{\text{Arith}}=\frac{Rank_{1}+Rank_{2}}{2}\\ \text{or } &Rank_{\text{Geo}}=\sqrt{Rank_{1}\times Rank_{2}} \end{split}\]
综合排名高的用户被认为是重点怀疑对象。
实验结论
实验在包含5000多用户的爱尔兰智能电表数据集上进行,模拟了6种不同的虚假数据注入(FDI)类型来代表窃电行为。
 图:6种FDI窃电类型示例
图:6种FDI窃电类型示例
| 类型 | 修改方式 |
|---|---|
| FDI1 | $\tilde{x}_{t}\leftarrow\alpha x_{t}$ (按比例减少) |
| FDI2 | $\tilde{x}_{t}\leftarrow\min(x_t, \gamma)$ (削峰) |
| FDI3 | $\tilde{x}_{t}\leftarrow\max(x_t - \gamma, 0)$ (整体降低) |
| FDI4 | $\tilde{x}_{t}\leftarrow f(t)\cdot x_{t}$ (某时段清零) |
| FDI5 | $\tilde{x}_{t}\leftarrow\alpha_{t}x_{t}$ (随机比例减少) |
| FDI6 | $\tilde{x}_{t}\leftarrow\alpha_{t}\bar{\textbf{x}}$ (随机常数) |
表:六种FDI(虚假数据注入)类型定义
- 方法优势验证:
- MIC 在检测 FDI1(按比例窃电)时表现出色(AUC达92.7%),因为这种方式保留了很强的相关性。而聚类方法对此几乎无效。
- CFSFDP 在检测 FDI5 和 FDI6(随机篡改,形状异常)时表现优异(AUC分别达86.0%和97.9%),而相关性方法对此效果很差。
- 组合方法 (Arith/Geo) 综合了两者的优点,在所有单一FDI类型上都保持了良好或优异的性能。尤其在混合了所有窃电类型的MIX场景(更贴近现实)中,组合方法的AUC(81.6%)和MAP@20(83.1%)显著优于任何单一方法,分别提升了约10%和20%。
| 类型 | AUC(%) | MAP@20(%) | ||||
|---|---|---|---|---|---|---|
| MIC | CFSFDP | Arith | MIC | CFSFDP | Arith | |
| FDI1 | 92.7 | 49.5 | 76.6 | 90.6 | 20.2 | 69.6 |
| FDI2 | 70.3 | 55.7 | 72.5 | 69.5 | 34.3 | 51.5 |
| FDI3 | 67.2 | 68.3 | 78.7 | 59.4 | 39.6 | 66.8 |
| FDI4 | 86.1 | 85.3 | 96.0 | 80.4 | 35.4 | 97.5 |
| FDI5 | 59.9 | 86.0 | 85.1 | 53.3 | 32.3 | 81.0 |
| FDI6 | 38.6 | 97.9 | 81.2 | 7.8 | 57.4 | 73.1 |
| MIX | 66.2 | 74.8 | 81.6 | 69.3 | 52.6 | 83.1 |
表:不同方法在各类FDI上的性能对比(节选)
- 稳定性与敏感性:
- 组合方法不仅提升了检测精度,还降低了结果的波动性(标准差更小),表现更稳定。
- 在不同窃电用户比例和不同区域用户规模下进行的敏感性分析表明,组合方法始终保持着稳健和优越的性能。
- 最终结论:本文提出的MIC与CFSFDP组合框架,通过互补地利用相关性分析和异常形状检测,成功地构建了一个高效、稳定且适应性强的电力盗窃检测系统。它在各种模拟窃电场景下均表现出卓越的性能,证明了其在实际应用中的巨大潜力。