A Practitioner’s Guide to Multi-turn Agentic Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2510.01132v1
-
作者: Prithviraj Ammanabrolu; Ruiyi Wang
-
发布机构: NVIDIA; University of California
TL;DR
本文通过将多轮智能体强化学习(multi-turn agentic reinforcement learning)的设计空间分解为环境、奖励和策略三大支柱,系统性地进行了实证研究,并最终提炼出一套用于训练大型语言模型(LLM)智能体的实用方法配方。
关键定义
本文主要沿用并适配了现有的强化学习概念,将其应用于多轮智能体场景,核心在于其问题形式化方式:
-
分部分可观察马尔可夫决策过程 (Partially Observable Markov Decision Process, POMDP):本文将多轮智能体任务构建为一个POMDP问题,由元组 $(\mathcal{S},\mathcal{A},\mathcal{T},\mathcal{R},\Omega,\mathcal{O},\gamma)$ 定义。其中,智能体在每个时间步 $t$ 根据历史轨迹 $h_t$ 采取一个动作 $a_t$,接收到一个部分观察 $o_t$(真实状态 $s_t$ 的文本描述)和一个标量奖励 $r_t$,目标是最大化期望折扣奖励总和。
-
多轮动作与奖励分配 (Multi-turn Action and Reward Assignment):与传统RL不同,这里的动作 $a_t$ 是一个由模型生成的自然语言指令(即一个 token 序列),直到遇到结束符 \(<eos>\) (end-of-sequence) 才被环境执行。本文的核心设计之一是将该轮的奖励 $r_t$ 仅分配给 \(<eos>\) 这个 token,而动作序列中的其他 token 奖励为0。这种机制在不改变环境奖励结构的前提下,为基于 token 的策略梯度计算提供了明确的信号。
相关工作
当前,将强化学习应用于大型语言模型(LLM)的研究主要集中在单轮(single-turn)任务上,例如 Proximal Policy Optimization (PPO)、RLOO等方法已被广泛优化。然而,将这些方法直接应用于多轮智能体场景是十分困难的,主要原因在于:
- 奖励与动作解耦:在多轮互动环境中,奖励通常是在一系列动作之后才出现(稀疏奖励),这打破了单轮RL方法所依赖的“单个动作-即时奖励”的紧密耦合关系。
- 缺乏标准化:现有的多轮RL实现方法五花八门,有些将工具辅助的单次查询视为多轮,有些依赖基于模型的假设,还有些在奖励分配上采用简单均分等策略。这种碎片化导致了不同研究之间的结果难以比较,也模糊了真正的多轮学习与伪多轮学习的界限。
本文旨在解决这一现状,即 如何有效地通过多轮强化学习训练大型语言模型(LLM)智能体?。通过对RL三大核心支柱——环境、策略和奖励——进行系统性分析,本文试图为在各种交互式文本环境中训练LLM智能体提供一个标准化的、可复现的实践指南。
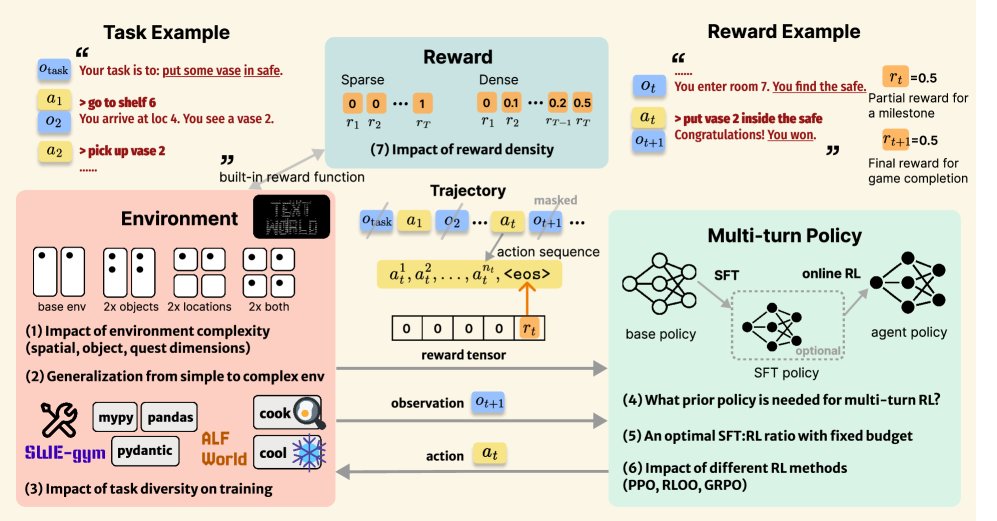
本文方法
本文的核心贡献不是提出一个全新的算法,而是构建了一个系统性的分析框架和一套经过实证检验的训练配方。该框架将多轮智能体RL的设计分解为环境、策略和奖励三个相互关联的支柱,并通过实验揭示了在不同支柱下的最佳实践。
问题形式化
本文将多轮智能体任务形式化为一个POMDP问题。在每个时间步 $t$,LLM智能体的策略 $\pi_{\theta}$ 基于历史轨迹 $h_t=(u,s_0,a_0,s_1,a_1,\cdots,s_t)$ 来生成一个动作序列 $a_t$。这个动作本身是一个自然语言序列 $(a_t^1, a_t^2, …, a_t^{n_t}, a_t^{eos})$。
一个具体流程示例如下: LLM接收到的输入遵循一个聊天模板: ``\(<|im_start|>user Your task is: {任务提示}. state: {状态0} your action:<|im_end|> <|im_start|>assistant {动作0}<|im_end|> ... <|im_start|>user state: {状态t} your action:<|im_end|> <|im_start|>assistant\)`$$ 模型 $\pi_{\theta}$ 生成动作 $a_t$。环境接收到完整的动作后,执行状态转换并计算奖励 $(s_{t+1}, r_t) = \text{env}(s_t, a_t)$。
创新点
本文方法的核心创新在于其系统性的多轮问题建模与信用分配机制,而非单一算法的改进。
-
明确的逐轮(Turn-level)信用分配:本文提出,将每轮互动产生的奖励 $r_t$ 明确地赋给该轮动作序列的结束符 \(<eos>\)。即,对于动作 $a_t$ 中的每个 token $a_t^i$,其奖励为:
\[r_t^i=\begin{cases}r_t&\text{if }a_t^i=\texttt{<eos>}\\ 0&\text{otherwise}\end{cases}\]这种设计将稀疏的轮次奖励巧妙地转化为 token 级别的稀疏信号,使得PPO等基于优势函数的算法可以通过价值网络自举(bootstrapping)将信用分配给动作序列中的其他 token。
-
token级别的优势函数计算:基于上述奖励分配,本文为PPO等算法设计了 token 级别的优势函数估计。首先计算每个 token 的TD误差 $\delta_t^i = r_t^i + \gamma V(h_t^{i+1}) - V(h_t^i)$,然后使用广义优势估计 (Generalized Advantage Estimation, GAE) 计算每个 token 的优势值 $\hat{A}_t^i = \sum_{l=0}^{L-i}(\gamma\lambda)^l\delta_t^{i+l}$。最终PPO的裁剪代理物镜函数为:
\[\mathcal{L}^{CLIP}(\theta)=\mathbb{E}_{\tau\sim\pi_{\theta}}\left[\sum_{t=0}^{T}\sum_{i=1}^{n_t+1}\min\left(r_t^i(\theta)\hat{A}_t^i,\text{clip}(r_t^i(\theta),1-\epsilon,1+\epsilon)\hat{A}_t^i\right)\right]\]其中 $r_t^i(\theta)$ 是新旧策略下 token $a_t^i$ 的概率比。
优点
- 通用性和标准化:该方法为多轮智能体RL提供了一个清晰、标准化的流程,可应用于多种交互式环境(如文本冒险、软件工程),结束了以往研究中方法混乱、结果难以比较的局面。
- 有效利用现有算法:通过巧妙的奖励分配和优势函数计算,该框架使得PPO这类成熟的单轮RL算法能够有效应用于多轮场景,而无需对算法本身进行伤筋动骨的修改。
- 兼顾理论与实践:本文不仅提出了形式化的建模方法,还通过大量实验对环境、策略、奖励三大支柱的设计选择进行了深入分析,最终形成了一套可操作的“配方”,对学术研究和工业实践都具有很高的指导价值。
实验结论
本文在TextWorld、ALFWorld和SWE-Gym三个基准上进行了大量实验,验证了其提出的训练配方的有效性。
环境 (Environment)
- 环境复杂度:智能体的性能随着环境复杂度(空间、物体数量)的增加而下降。值得注意的是,物体复杂度的增加比空间复杂度带来的挑战更大。同时,更大的模型(如7B vs 1.5B)能更好地应对复杂环境。
- 泛化能力:在简单环境中训练的智能体,在更复杂的环境中表现出良好的泛化能力。例如,在空间复杂度较高的环境中训练的模型,在物体和空间复杂度都很高的环境中也取得了显著的性能提升。这证明了多轮RL学会了可复用的技能。
- 任务多样性:多任务训练能显著提升智能体的性能和泛化能力。即使是在 seemingly unrelated 的任务上训练,也能帮助智能体在单一专有任务上取得比单任务训练更好的表现,这表明智能体学会了更通用的解决问题的策略。
策略 (Policy)
- 先验知识与RL的结合:使用少量高质量的专家示例进行监督微调(Supervised Fine-tuning, SFT)可以作为优秀的模型先验,显著加速RL训练过程,并大幅减少对在线RL数据的需求。
- SFT与RL的最佳配比:在固定成本预算下,存在一个最佳的SFT与RL数据配比。纯SFT在领域内表现优异但泛化能力差,而结合少量SFT和大量RL训练(如$$SFT:RL=60:400`的配置)能在任务准确性和泛化能力之间取得最佳平衡。
- 算法选择:有偏的启发式算法(如PPO)和无偏的策略梯度算法(如RLOO)都能在本文的框架下取得稳定学习效果,证明了性能提升主要来源于本文提出的多轮问题形式化,而非特定算法的“技巧”。总体而言,PPO在复杂任务上表现通常优于RLOO。
奖励 (Reward)
- 奖励密度:与稀疏的最终任务奖励相比,稠密的中间步骤奖励能显著加速多轮RL训练。
- 奖励与算法的相互作用:稠密奖励的效果高度依赖于所选择的RL算法。PPO能很好地利用稠密奖励信号,而RLOO虽然也能受益,但提升幅度较小。然而,在面对稠密奖励时,RLOO表现出比PPO更高的训练稳定性。
最终结论:本文的实证研究表明,通过对环境、策略和奖励进行协同设计,可以有效地训练LLM进行多轮智能体任务。本文提出的训练配方在文本推理、具身推理和软件工程等多种任务中均被证实有效,为未来多轮智能体RL的研究与实践提供了坚实的指南。