A Survey of AI Scientists: Surveying the automatic Scientists and Research
-
ArXiv URL: http://arxiv.org/abs/2510.23045v2
-
作者: Pan Zhou; Guiyao Tie; Lichao Sun
-
发布机构: Huazhong University of Science and Technology; Lehigh University
TL;DR
本文首次对新兴的 AI 科学家 (AI Scientist) 领域进行了系统性综述,提出了一个统一的六阶段科学工作流框架,并基于此框架梳理了从 2022 年到 2025 年的关键研究,揭示了该领域从基础模块化、闭环集成到追求可扩展性、影响力与人机协作的清晰三阶段演进脉络。
引言
近年来,一个名为“AI 科学家”的新范式在人工智能与科学哲学的交叉领域迅速崛起。它与早期的“AI for Science”不同,后者主要利用机器学习加速数据分析等离散任务,而 AI 科学家的目标是实现端到端的自主发现 (end-to-end autonomous discovery)。这些系统旨在模拟甚至完全执行人类研究者的角色——从提出新颖假说、设计并执行实验,到解读结果并生成可发表的成果。
这一愿景的实现得益于大型语言模型 (Large Language Models, LLMs) 复杂的推理能力、多智能体 (Multi-Agent) 协同技术的进步以及自动化实验室系统的成熟。这些技术共同推动了研究模式从“自动化”(AI 辅助预定义步骤)向“自主化”(AI 智能体自行设计、验证并执行科研工作流)的根本转变。
尽管自 2024 年以来相关研究呈指数级增长,但现有工作大多聚焦于特定领域(如化学、生物)或单一能力(如假说生成、文献综述),呈现出碎片化的状态。目前尚无研究提供一个统一的分类法,将科学任务、AI 能力、智能体系统和评估协议联系起来。
为此,本文旨在整合这些分散的研究线索,为该领域建立一个连贯的基础。本文的核心贡献在于:
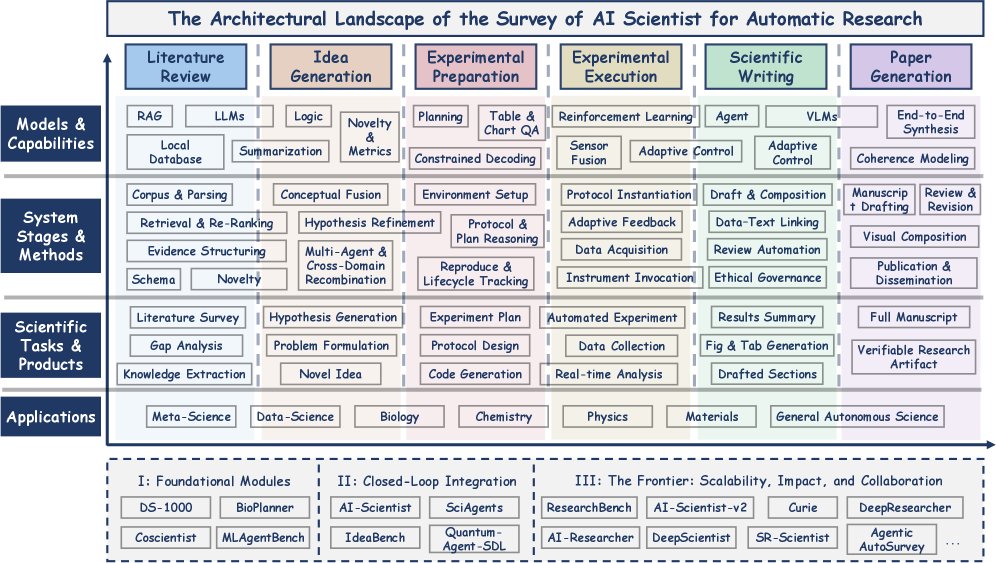
- 提出首个六阶段科学工作流框架:将科学流程解构为文献回顾、创意生成、实验准备、实验执行、科学写作和论文生成六个阶段,为领域研究提供了统一的分类与分析词汇。
- 全面梳理系统与基准:系统性地将 2022 年至 2025 年的数十篇开创性工作映射到该六阶段框架中,提供了一张可视化领域能力和演进全景的矩阵图。
- 揭示三阶段历史演进:清晰地阐述了该领域从“基础模块”(2022-2023)、到“闭环集成”(2024)、再到当前“可扩展性、影响力与协作”前沿(2025)的发展轨迹。
本文的组织结构如下:首先建立六阶段分类体系并概述历史演进;然后深入探讨每个阶段的方法论;接着综述通用及特定领域的应用系统;最后讨论开放挑战与未来方向。
背景与分类体系
本章通过引入一个研究类别分类法并追溯 AI 科学家系统的历史演进,为本次综述建立了概念框架。首先将端到端的科学流程分解为六个独特的方法论阶段,然后将 2022 年至 2025 年的代表性系统和基准与这些阶段对齐,并最终将这些发现整合成一个三阶段的历史发展叙事。
下表根据论文中的贡献,对代表性系统在六个方法论阶段的覆盖范围进行了重建和扩展。\(●\) 表示该系统明确覆盖了对应的方法论阶段。
| 系统/基准 | 文献回顾 | 创意生成 | 实验准备 | 实验执行 | 科学写作 | 论文生成 | 备注 |
|---|---|---|---|---|---|---|---|
| The AI Scientist v1/v2 [15, 6] | ● | ● | ● | ● | ● | ● | 首个端到端全流程自主系统 |
| DeepScientist [34] | ● | ● | ● | ● | ● | ● | 追求科学影响力的端到端系统 |
| AI-Researcher [46] | ● | ● | ● | ● | ● | ● | 端到端全流程自主系统 |
| DeepResearcher [35] | ● | ● | ● | ● | 侧重可扩展性与真实环境交互 | ||
| freephdlabor [36] | ● | ● | ● | 强调人机深度协作的框架 | |||
| Coscientist [38] | ● | ● | 结合物理实验室执行 | ||||
| LitLLM [27] | ● | 专注于文献综述与引用生成 | |||||
| SciAgents [41] | ● | 专注于创意生成 | |||||
| HypER [26] | ● | ● | 专注于文献回顾与假说验证 | ||||
| DS-1000 [37] | ● | ● | 数据科学代码准备与执行基准 | ||||
| MLAgentBench [40] | ● | ● | 机器学习智能体能力基准 | ||||
| ResearchBench [23] | ● | 科学写作与结果呈现基准 | |||||
| IdeaBench [24, 42] | ● | 创意/假说生成能力基准 |
分类体系
2022 年至 2025 年的 AI 科学家研究可被系统地解构为六个核心方法论阶段 (six core methodological stages)。这些阶段共同构成了一个端到端的闭环流程,将非结构化知识转化为可验证的科学产出。
- 文献回顾 (Literature Review):此阶段将非结构化的科学文献转化为机器可解释的知识。它涵盖了从大规模信息检索到综合研究空白等技术。其目标是为后续任务提供坚实的知识基础。
- 创意生成 (Idea Generation):在已构建的知识基础上,此阶段自动化地发现假说和构思问题。它利用 LLM 的创造性和推理能力来提出新颖且合理的研究方向。
- 实验准备 (Experimental Preparation):这个关键的中间阶段将抽象的假说转化为可执行的计划。它包括定义变量、选择数据集、生成分析代码和设计实验方案等任务。
- 实验执行 (Experimental Execution):此阶段涉及运行真实或模拟的实验。它强调智能体与工具交互、控制机器人设备以及根据实时反馈调整计划的能力。
- 科学写作 (Scientific Writing):此阶段专注于科学发现的交流,将结构化的结果转化为连贯、有引证支持的叙述。能力范围从章节感知型摘要到数据到文本的综合。
- 论文生成 (Paper Generation):作为科学工作流的顶峰,此阶段综合所有先前阶段的成果,生成一篇完整的、可供发表的稿件。这是最先进的全自主系统的标志性能力。
历史演进
AI 科学家研究在 2022 年至 2025 年的演进揭示了一条清晰的轨迹:从分立的任务模块逐步走向自我反思和可验证的端到端系统。本文识别出三个主要的发展阶段。
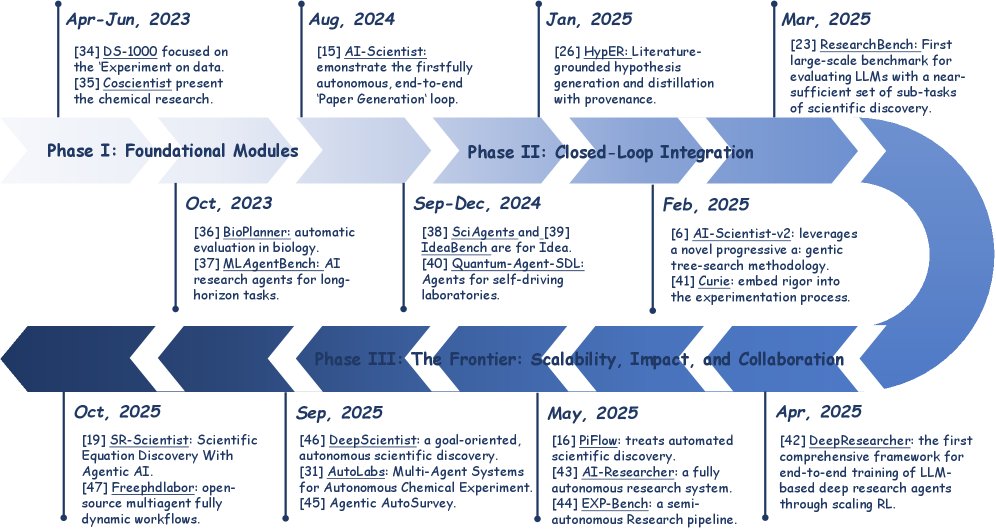
阶段 I: 基础模块 (2022–2023)
该初始阶段的特点是开发和评测那些针对科学流程中离散阶段的组件。早期的工作如 DS-1000 专注于数据科学代码的“实验准备”和“执行”阶段。同时,像 Coscientist 这样的系统展示了在物理实验室中进行闭环“执行”的可行性。
阶段 II: 闭环集成 (2024)
2024 年标志着一个关键转折点,研究焦点从模块化组件转向将多个阶段整合成连续的工作流。该阶段的里程碑是 The AI Scientist v1,它首次成功演示了完全自主的端到端“论文生成”循环,将先前分散的阶段统一到一个单一、连贯的流程中。
阶段 III: 前沿:可扩展性、影响力与协作 (2025–至今)
最近的阶段由三个并行且前沿的研究方向定义:
- 可扩展性与鲁棒性:以 DeepResearcher 为代表,通过在真实网络环境中进行强化学习来训练智能体,使其能处理嘈杂信息并随时间改进。
- 科学影响力与渐进式发现:以 DeepScientist 为代表,这是一个为实现目标导向、长周期的研究而设计的里程碑式系统,其明确目标是在前沿科学任务上超越人类现有水平。
- 深度人机协作:以 freephdlabor 等框架为代表,将研究过程设计为持续的、交互式的伙伴关系,人类研究员可以引导、定制和协作一个个性化的多智能体团队。
AI 科学家系统的方法论集成
本章系统分析了构成现代 AI 科学家系统的方法论组件。基于前述的分类体系,端到端的研究工作流被组织为六个顺序阶段,共同构成一个自主科学发现的闭环流程。
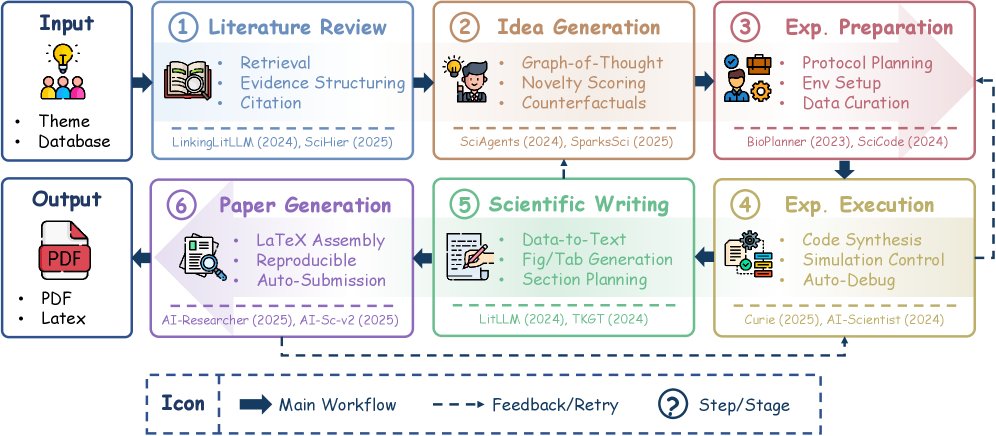
文献回顾
文献回顾是 AI 科学家系统的基础认知层。其目标是将海量的非结构化科学文献转化为结构化的、来源可追溯的知识表示,以支持后续的推理和假说生成。与通用摘要不同,科学文献回顾对溯源意识 (provenance-awareness)、逻辑一致性 (logical consistency) 和知识缺口识别 (knowledge-gap identification) 有着严格要求。
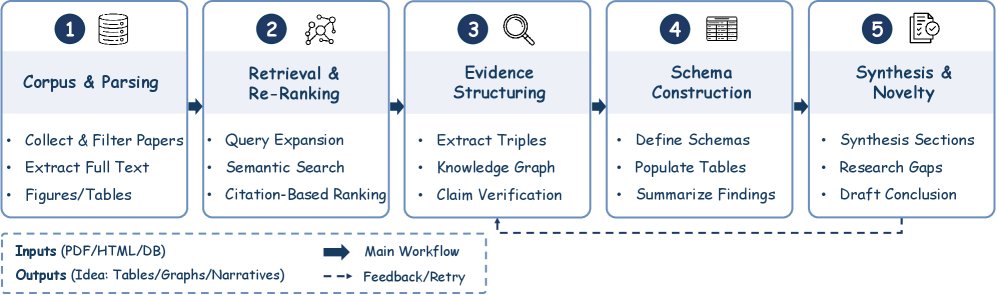
为了确保方法论的严谨性,文献回顾过程可以被形式化为一个五阶段的流水线:
-
语料库构建与规范化 (Corpus Construction and Normalization):此阶段从异构的科学文档(如 arXiv, PubMed)中构建一个结构化的、可查询的基础。核心方法包括版面感知解析 (layout-aware parsing)、文档格式转换和引文图谱重建。S2ORC 和 GROBID 等工具在此领域发挥了基础性作用。
-
检索与重排序 (Retrieval and Re-ranking):系统检索并排序与特定研究问题相关的文本段落。工作流通常采用混合检索(词法+语义)、交叉编码器重排序 (cross-encoder re-ranking) 和章节感知加权等技术。如 PaperQA 等系统已通过集成检索增强生成 (Retrieval-Augmented Generation, RAG) 实现了超人的综述能力。
-
证据结构化 (Evidence Structuring):此阶段将检索到的文本证据转化为机器可解释的结构,如信息抽取 (Information Extraction, IE) 得到的元组、知识图谱 (Knowledge Graph, KG) 和用于系统推理的表格。
-
模式归纳 (Schema Induction):系统自动发现用于跨多篇论文进行比较的有意义的维度(例如,“模型架构”、“数据集”),并形成一个全面的综述表。ArxivDIGESTables 系统完整实现了这一流水线。
-
基于根据的叙述合成 (Grounded Narrative Synthesis):最后阶段将结构化证据合成为连贯的、引用可靠的叙述,同时量化发现的新颖性。LitLLM 等系统实现了可靠的、基于引用的草稿撰写流程,而 SCIMON 则专注于通过迭代优化来激发灵感的多样性和新颖性。
创意生成
在文献综述之后,创意生成 (Idea Generation) 阶段是 AI 科学家流程的创造性核心。它旨在将前一阶段产生的结构化知识和文献嵌入转化为具体的、可测试的假说和新颖的研究方向。这项任务需要模拟推理 (analogical reasoning)、创造性综合 (creative synthesis) 和认知验证 (epistemic validation) 的融合。
该过程被形式化为一个四阶段的方法论框架:
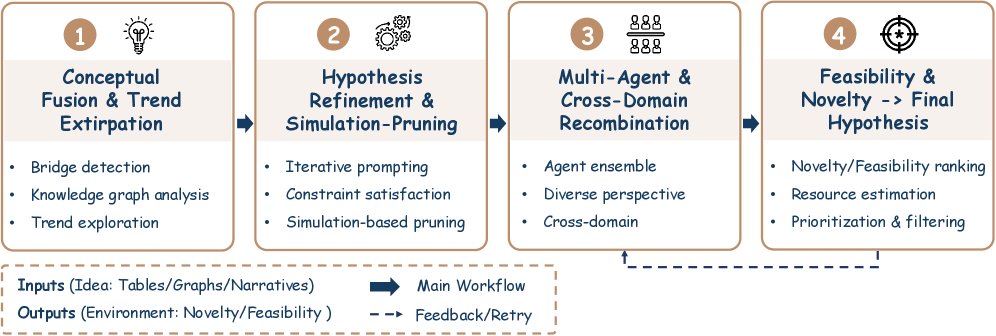
-
概念融合与趋势外推 (Conceptual Fusion and Trend Extrapolation):此初始阶段致力于在异构的科学语料库中发现潜在联系,并识别新兴的研究轨迹。方法论通常利用密集检索和嵌入聚类来映射不同研究前沿之间的概念关系。例如,MOOSE-Chem 利用化学知识图谱重新发现了未知的分子关系。
-
知识精炼与验证 (Knowledge Refinement and Validation):一旦生成了初步的假说语料库,此阶段会进行严格的精炼和筛选,以确保其逻辑连贯性、事实一致性和经验可行性。HypER 等系统引入了来源感知的因果验证机制。
-
多智能体协作头脑风暴 (Multi-Agent Collaborative Brainstorming):受人类科学辩论的启发,该阶段采用多智能体模拟来进行思想的迭代和对抗性测试。智能体被分配不同角色(如生成者、批评者、综合者),通过辩论来增强假说的鲁棒性和新颖性。
-
假设评分与排序 (Hypothesis Scoring and Prioritization):最后,系统根据多个标准对精炼后的假说进行评分和排序,包括新颖性、影响力、可行性和可证伪性。IdeaBench 等基准为此提供了标准化的评估协议。