A Survey of Data Agents: Emerging Paradigm or Overstated Hype?
-
ArXiv URL: http://arxiv.org/abs/2510.23587v1
-
作者: Wei Zhou; Liangwei Wang; Xinyu Liu; Yuyu Luo; Yu Li; Shimin Di; Guoliang Li; Ji Sun; Xuanhe Zhou; Yizhang Zhu; 等23人
-
发布机构: Beijing Institute of Technology; DeepWisdom; Huawei; Renmin University of China; Shanghai Jiao Tong University; Southeast University; The Hong Kong University of Science and Technology; Tsinghua University
引言
随着大型语言模型 (Large Language Models, LLMs) 的兴起,一种新的范式——数据智能体 (Data Agents)——应运而生。数据智能体被定义为一个综合性的、由LLM驱动的架构,它能自主协调数据与AI生态系统,以处理复杂的数据相关任务。
然而,“数据智能体”这一术语目前存在严重的术语模糊性,将简单的查询响应系统与复杂的自治架构混为一谈。这种模糊性导致了用户期望错配、责任归属不清以及行业发展障碍等一系列问题。
为解决这些挑战,本文借鉴了汽车工程学会 (SAE) 为自动驾驶制定的J3016标准,首次提出了一个针对数据智能体的系统性分层分类体系。该体系为理解数据智能体的现状、指导未来发展以及建立清晰的问责制度提供了坚实的框架。
关键定义
本文的核心是提出了一个全新的数据智能体分类体系,并沿用和明确了以下关键定义:
-
数据智能体 (Data Agent): 一个综合性的、由LLM驱动的架构,它通过协调“数据+AI”生态系统,自主执行从数据管理、数据准备到数据分析的广泛任务。其过程可抽象表示为:
\[\mathcal{A}:(\mathcal{T},\mathcal{D},\mathcal{E},\mathcal{M})\rightarrow\mathcal{O}\]其中,智能体 \($\mathcal{A}\)$ 在环境 \($\mathcal{E}\)$(如数据库、代码解释器)中,利用LLM \($\mathcal{M}\)$ 对原始数据 \($\mathcal{D}\)$ 进行操作,以完成数据任务 \($\mathcal{T}\)$ 并生成输出 \($\mathcal{O}\)$。
-
数据智能体与通用LLM智能体的区别: 与处理定义明确、信息完备任务的通用智能体不同,数据智能体必须在庞大、异构、动态且充满噪声的数据湖中工作。这要求它们具备特殊能力,如:对数据环境的感知、交互式探索、对专业数据工具的稳健调用,以及处理数据不一致、可伸缩性限制等问题的自适应解决能力。
L0-L5 数据智能体分层分类体系
为了解决术语模糊带来的挑战,本文提出了一个从L0到L5的六级分层分类体系,以数据智能体的自主性程度作为核心划分标准。该体系的核心思想是描绘了在数据任务中,控制权和责任从人类逐步转移到智能体的过程。
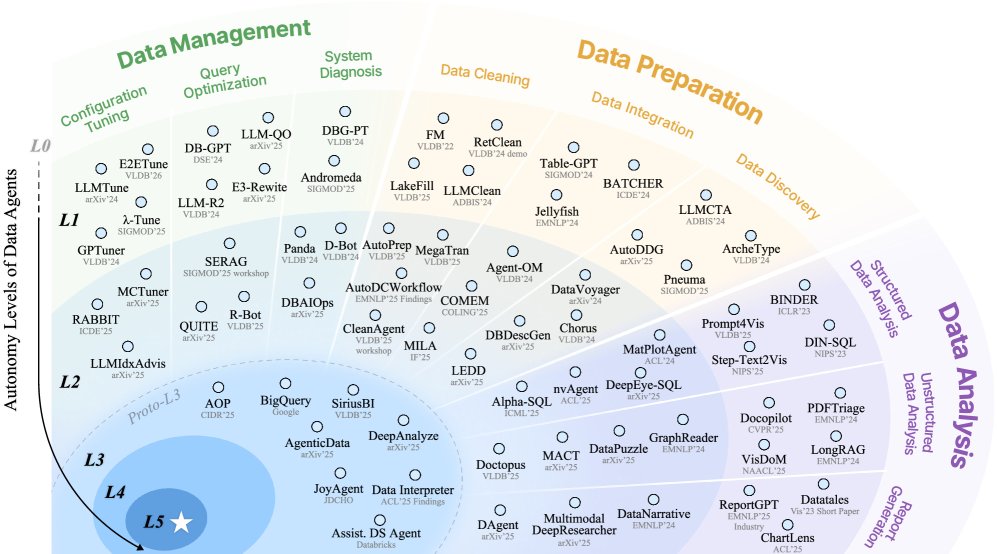
分类体系
- L0 (无自动化): 所有数据任务完全由人类手动完成,没有智能体参与。
- L1 (辅助智能): 智能体作为初步的辅助工具,在无状态的“提示-响应”模式下运行,为人类提供代码片段或建议。人类仍主导整个工作流,并对结果负全责。
- L2 (部分自动化): 智能体能够感知和交互环境(如连接数据源、执行代码),具备记忆和工具调用能力,可以在人类编排的流程中自主执行特定的程序。人类负责整个工作流的宏观管理。
- L3 (有条件自主): 智能体能够自主编排和优化端到端的数据处理流水线,以处理多样化和综合性的复杂任务。人类的角色转变为监督者,任务主导权和主要责任转移给智能体。这是从程序执行者到多功能主导者的革命性飞跃。
- L4 (高度自主): 智能体达到高度可靠,无需人类监督。它们能主动通过持续监控数据湖来发现值得研究的问题,并自主执行任务。人类完全放权,成为旁观者。
- L5 (完全自主): 智能体不仅能应用现有方法,还能创造新颖的解决方案和开创性的范式,推动数据科学领域的前沿发展,此时不再需要任何形式的人类干预。
演进飞跃
从一个级别到下一个级别的跃升代表了智能体能力和范式的关键转变。
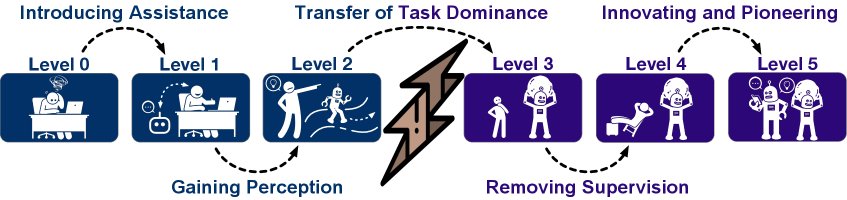
- L0 → L1 (引入辅助): 从纯手动到引入智能助手,人类从独立工作者变为助手的使用者。
- L1 → L2 (环境感知与交互): 从无状态响应到有状态的程序执行。智能体首次获得与数据环境和代码环境交互的能力,但仍局限于人类定义的流程。
- L2 → L3 (自主编排): 革命性的飞跃。智能体从执行固定程序转变为自主设计和编排完整的、端到端的任务流水线,主导权和责任发生根本性转移。
- L3 → L4 (主动发现): 从被动接受任务到主动发现问题。智能体能够自主识别有价值的任务并执行,实现从有监督到无监督的转变。
- L4 → L5 (生成式创新): 从应用知识到创造知识。智能体能够发明全新的方法论,实现真正的科学创新。
L0/L1 数据智能体:从独立实践到辅助智能
该部分回顾了从无智能体参与的L0阶段,到初步引入智能辅助的L1阶段的演变。
L0: 手动数据实践
在L0阶段,不存在数据智能体。所有数据管理、准备和分析任务完全由人类专家手动执行。例如,数据库管理员根据经验手动调优数据库参数,数据分析师手动编写SQL和清洗脚本。
形式上,人类 \($\mathcal{H}\)$ 负责整个流程,包括流程编排 \($\pi\_{\mathcal{H}}\)$ 和执行 \($\epsilon\_{\mathcal{H}}\)$,而智能体 \($\mathcal{A}\)$ 不参与:
\[\begin{align*} \mathcal{H} &: \pi_{\mathcal{H}}(\mathcal{T},\mathcal{D},\mathcal{E})\rightarrow P; \quad \epsilon_{\mathcal{H}}(P,\mathcal{D},\mathcal{E})\rightarrow\mathcal{O} \\ \mathcal{A} &: \emptyset \end{align*}\]这种模式劳动强度大、耗时长,且对专业技能要求高。
L1: 辅助智能
L1数据智能体是早期的LLM助手,它们以“提示-响应”的方式工作,为人类提供建议或生成代码片段。它们是无状态的,无法感知或与环境交互。
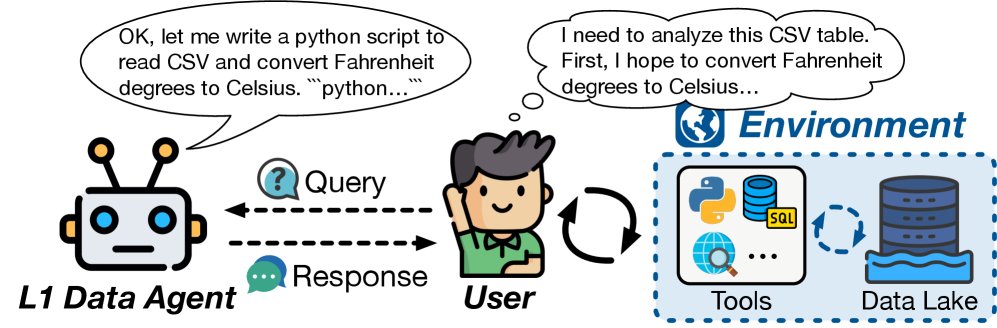
在L1阶段,人类依然负责整个工作流的编排和执行,但可以利用智能体 \($\mathcal{A}\)$ 对查询 \(q\) 的响应 \(r\) 来辅助完成任务。
\[\begin{align*} \mathcal{H} &: \pi_{\mathcal{H}}(\mathcal{T},\mathcal{D},\mathcal{E})\rightarrow P; \quad \epsilon_{\mathcal{H}}(P,\mathcal{D},\mathcal{E},r)\rightarrow\mathcal{O} \\ \mathcal{A} &: (q,\mathcal{M})\rightarrow r \end{align*}\]用户需要自行集成、执行和验证智能体生成的代码,并根据环境反馈进行调整。尽管L1智能体提升了效率,但其交互是孤立和一次性的。
L1 数据智能体在数据管理中的应用
数据管理旨在确保数据库系统的高效可靠运行。L1智能体在此领域主要应用于以下任务:
- 配置调优 (Configuration Tuning): 识别有效的系统设置,如数据库旋钮参数和索引。
- 查询优化 (Query Optimization): 通过逻辑重写等方式改进SQL查询。
(注:原文后续章节内容缺失)
| 智能体 | 技术 | 数据复杂度 | 任务 | 会议/期刊 |
|---|---|---|---|---|
| 配置调优 | ||||
| CBTune | ICL | 单一、结构化 | 数据库旋钮调优 | SIGMOD’23 |
| TuneMate | ICL | 单一、结构化 | 数据库旋钮调优 | CoRR’24 |
| DB-GPT | SFT+RAG | 单一、结构化 | 数据库旋钮调优 | TODS’24 |
| Index-GPT | ICL | 单一、结构化 | 索引建议 | VLDB’24 |
| 查询优化 | ||||
| SQL-PALM | ICL | 单一、结构化 | 查询重写 | CoRR’23 |
| LERO | ICL | 单一、结构化 | 查询重写 | CoRR’23 |
| Text2SQL-GPT | SFT | 单一、结构化 | 查询重写 | CoRR’24 |
| 系统诊断 | ||||
| DIAG-GPT | ICL | 单一、结构化 | 根本原因分析 | VLDB’24 |
| Sherlock | ICL | 单一、结构化 | 根本原因分析 | CIDR’24 |
未来方向与展望
尽管原文内容不完整,但其引言和大纲明确指出了未来的研究方向,主要集中在实现更高级别的自主性上:
-
迈向L3及更高等级: 当前研究的瓶颈在于从L2向L3的跨越,即从执行预设程序到实现自主的流水线编排。未来的工作需要解决智能体在策略推理、任务分解和跨数据生命周期权衡方面的不足。
-
实现L4的主动性和无监督性: L4级别的关键挑战在于赋予智能体“主动性”,使其能够自主发现数据湖中有价值的问题,而不仅仅是被动地响应人类指令。这需要智能体具备持续监控和探索复杂数据生态系统的能力。
-
展望L5的生成式能力: L5是数据智能体的最终愿景,即成为能够进行范式创新的“人工数据科学家”。这不仅需要模型具备强大的推理能力,更需要在知识创造和方法论革新方面取得突破。
总结
本文是一篇关于数据智能体的综述,其核心贡献是首次提出了一个受自动驾驶SAE J3016标准启发的、从L0到L5的系统性分层分类体系。该体系通过明确各级别智能体的自主性边界和人机责任划分,为解决当前领域内术语混乱、用户期望错配和责任归属不清等问题提供了清晰的框架。论文围绕此分类体系,结构化地梳理了现有研究,并指出了实现更高级别自主智能体(特别是从L2到L3的跨越)所面临的关键技术挑战和未来的研究方向,为该领域的健康发展规划了路线图。