A Survey of Inductive Reasoning for Large Language Models
-
ArXiv URL: http://arxiv.org/abs/2510.10182v1
-
作者: Biqing Qi; Liang He; Siyu Yan; Qipeng Guo; Qin Chen; Yinqi Zhang; Jie Zhou; Xiaoming Shi; Yaoting Wang; Wei Zhang; 等14人
-
发布机构: East China Normal University; Fudan University; Shanghai AI Laboratory; Shanghai Innovation Institute; Xi’an Jiaotong University
TL;DR
- 本文是首篇针对大语言模型(LLMs)归纳推理能力的全面综述,系统性地梳理了增强方法、评测基准和理论分析,为该领域的研究奠定了基础。
背景
本节介绍归纳推理的相关概念、应用场景及其重要性。
概念
-
大语言模型 (Large Language Models, LLMs):自 Transformer 架构成为主流以来,预训练语言模型(PLMs)迅速发展。从2022年 ChatGPT-3.5 问世开始,拥有海量参数和独特训练方法的 LLMs 时代正式来临,它们显著提升了 NLP 任务的性能,并深刻影响了日常生活。
-
归纳推理 (Inductive Reasoning):归纳推理是一种从具体实例或观察中推导出一般性规则和结论的思维过程,其特点是从特殊到一般,且结论不唯一,具有一定的概率性。这种推理模式与人类认知过程高度一致,是知识泛化和学习的基础。
归纳推理的应用
归纳推理的核心思想是归纳偏置 (inductive bias),即模型在面对未见过的项目时所依赖的一组假设或先验条件。
- NLP下游任务:归纳推理被广泛用于提升NLP任务性能,例如:通过学习归纳偏置、构建思维链(CoT)或总结规则来增强模型的可解释性和性能。其应用涵盖句法与语义分析、信息抽取、对话系统、问答及多模态任务。
- 真实世界场景:
- 金融预测与风险管理:通过从历史时序数据中学习复杂的非线性模式,对未来金融结果进行预测。
- 自动驾驶:解决缺乏足够训练数据的罕见、安全关键场景的处理问题。
- 对话式医疗与诊断:通过从症状模式中泛化,模仿临床医生问诊和诊断的过程。
归纳推理的重要性
归纳推理是知识发现和泛化的基础方法,其重要性体现在:
- 知识泛化:能够从具体案例中推导出普适性结论,覆盖更广泛的应用场景,符合人类的学习过程。
- 适应不确定性:在复杂和不确定的场景中,归纳推理能产生多种可能的合理解释,而非单一的确定性答案,具有更强的适应性。
增强方法
本文将增强 LLMs 归纳能力的方法分为三大类:后训练、测试时扩展和数据增强。
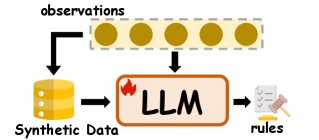
 归纳推理的后训练方法示意图
归纳推理的后训练方法示意图
后训练
后训练指在模型预训练之后,通过监督微调 (Supervised Finetuning, SFT) 或强化学习 (Reinforcement Learning, RL) 等算法来提升模型的归纳推理能力。
- 合成数据:为解决自然数据难以获取或组织的局限,研究者常人工构建数据来训练模型。例如,LingR 构建“语言学规则指令集”;ItD 利用 LLMs 的演绎能力生成数据以优化归纳能力;CodeSeq 构建训练集让 LLM 推理数列通项公式。
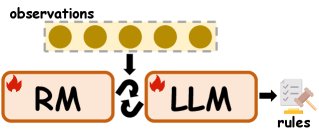
- IRL风格的优化:传统奖励模型 (Reward Models, RMs) 难以监督答案不唯一的归纳任务。因此,逆强化学习 (Inverse RL, IRL) 成为一种有潜力的替代方案,它能从反馈中推断潜在的奖励函数。在 LLMs 的 RLHF 流程中,通过设计合适的奖励模型可以增强其归纳能力。例如,Prompt-OIRL 利用历史经验训练奖励模型,提升模型的归纳探索能力。
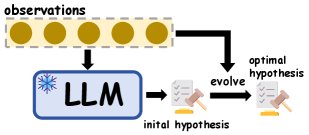 归纳推理的测试时扩展方法示意图
归纳推理的测试时扩展方法示意图
测试时扩展
测试时扩展是一种在推理阶段使用的、基于假设的方法,它通过提示 (prompting) 冻结的 LLMs 来形成归纳推理流程,无需重新训练模型。
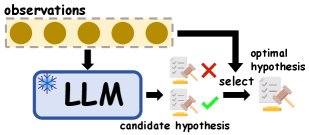
- 假设选择:让 LLM 生成多个候选假设,然后从中筛选出能够覆盖所有观察实例的假设。例如,Hypothesis Search 通过 LLM 或少量人工过滤来筛选抽象假设;Mixture of Concepts (MoC) 首先识别语义不冗余的概念,再基于概念生成假设,以减少语义冗余。
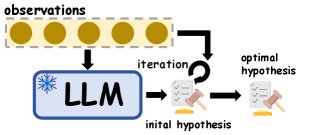
- 假设迭代:对候选假设进行迭代优化,直到它能满足所有观察实例。例如,Qiu et al. (2024) 提出三步迭代式假设修正方法,模拟人类的归纳过程;SSR 通过执行反馈来迭代优化规则。
- 假设演化:通过生成、筛选和组合多个假设来扩展、多样化或演化假设空间,以形成能捕捉更复杂模式的最终假设。例如,IncSchema 通过分阶段查询 LLM 来逐步归纳通用模式;PRIMO 引入渐进式多阶段开放规则归纳方法,以推导多跳规则。
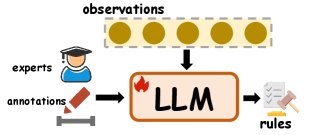

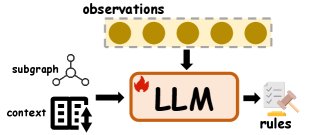 归纳推理的数据增强方法示意图
归纳推理的数据增强方法示意图
数据增强
数据增强指通过为模型输入补充额外的知识或结构化信号(如外部事实、检索文档等)来增强其推理能力。
- 人工干预:在归纳推理过程中融入专家知识或人工标注信息。例如,Zhang et al. (2023a) 利用 GPT-3 生成候选模式,再通过人工干预提升其质量。
- 外部知识:包含来自网络、文档、其他语料库或 LLM 自身参数中的知识。例如,LLEGO 将 LLM 的语义先验知识融入遗传编程;也可以直接提示强大的 LLM 为当前任务生成归纳思维链、归纳步骤或归纳规则作为辅助信息。
- 结构化信号:利用子图或上下文信息(如相邻的隐藏状态或嵌入)为 LLM 提供局部隐式信号,帮助其学习归纳偏置。例如,Li et al. (2023b) 检索最近邻嵌入作为上下文示例;REST 部署规则诱导的子图来捕捉局部语义模式。
评测
本节介绍用于 LLM 归纳推理的现有基准、评测方法和相应指标。
基准
研究界构建了多样化的基准来评测 LLMs 的归纳推理能力。这些基准的核心任务要求模型观察少量输入样例(观察输入),推断底层模式,并输出最终规则(归纳目标)。如下表所示,这些基准的数据对象涵盖了从数字、字符串等基础结构到网格、逻辑公式等复杂形式。
| 原子对象 | 基准名称与引用 | 输入形式 | 归纳目标 | 测试样本数 |
|---|---|---|---|---|
| entity | SCAN (Lake et al., 2019) | text | command | ~10k |
| grid | ARC* (Chollet, 2019) | grid transformation | grid transformation rules | ~1k |
| list | List Func.* (Rule, 2020) | list transformation examples | list processing functions | ~1k |
| code | PROGES (Alet et al., 2021) | I/O examples | program | ~1k |
| string | SyGuS (Odena et al., 2021) | I/O examples | string transformation program | ~1k |
| entity | ACRE (Zhang et al., 2021a) | text description | concept rules | ~1k |
| symbol | ILP (Glanois et al., 2022) | logical facts | logical rules | ~10k |
| text | Instruc. (Honovich et al., 2022) | I/O text pairs | instructions | ~1k |
| number | Arith.* (Wu et al., 2024) | arithmetic sequences | arithmetic rules | ~1k |
| symbol | Le/Ho. (Liu et al., 2024b) | geometric patterns | logical formulas | ~1k |
| structure | NutFrame (Guo et al., 2024) | text | schema | ~1k |
| fact | DEER (Yang et al., 2024) | factual text | abstract rules | ~1k |
| puzzle | RULEARN (He et al., 2025) | I/O examples | game rules | ~1k |
| word | Crypto.* (Li et al., 2025a) | word puzzles | decryption rules | ~1k |
| symbol | GeoILP (Chen et al., 2025c) | geometric figures/facts | geometric theorems | ~1k |
| string | In.Bench (Hua et al., 2025) | multi-type examples | rules | ~1k |
| number | CodeSeq (Chen et al., 2025a) | number sequences | general term formula | ~1k |
注:\(*\) 表示数据以类比推理的形式呈现。\(~\) 表示近似值。表格部分信息根据原文及上下文补充。
其中,ARC、List Functions 等基准侧重于算法或规则学习;ILP、GeoILP 等更强调逻辑概念和符号规则的归纳;而 CodeSeq 则涉及更高级的数列通项计算。
评测方法
传统评测策略
大多数基准直接评估 LLM 生成的答案与标准答案的一致性,采用 ACC、精确匹配 (Exact Match)、成功率等传统指标。例如,SCAN 评估生成输出是否与参考答案完全匹配。
基于沙箱的评测
考虑到所有归纳任务的内在机制都是从具体观察中推断通用规则,本文提出了一个统一的评测方法:沙箱单元测试 (sandbox unit test)。
该方法将 LLM 生成的归纳规则封装为代码、工具或提供给“LLM作为裁判”的提示,然后在受控的沙箱环境中,用每个观察实例作为测试用例,验证其是否符合该规则。
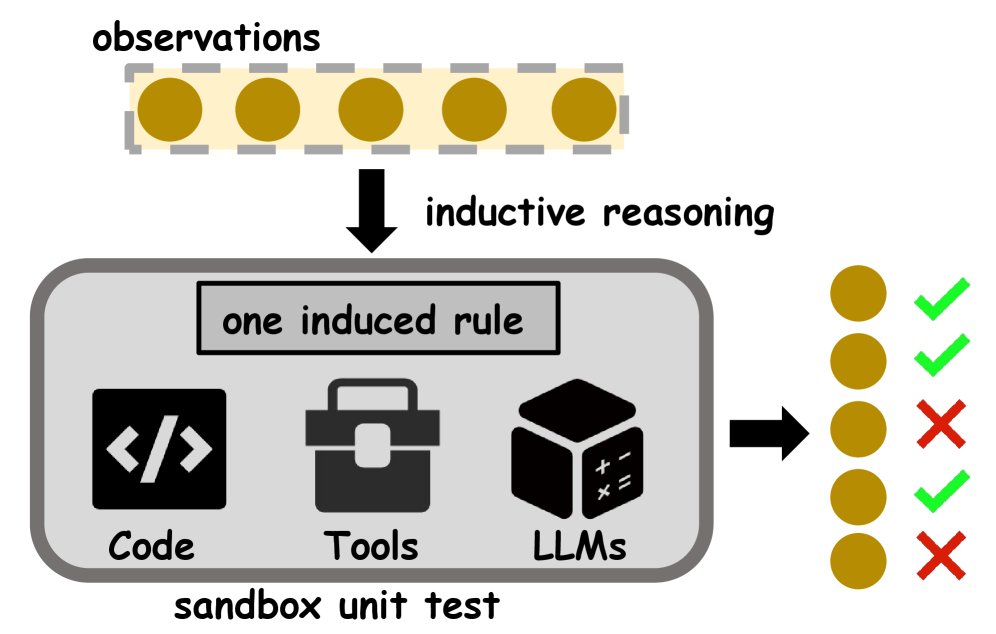 LLM归纳推理的沙箱单元测试示意图
LLM归纳推理的沙箱单元测试示意图
基于此,本文提出了一个更细粒度的指标:观察覆盖率 (Observation Coverage, OC),定义为通过单元测试的观察实例占总观察实例的比例。相比于任务级别的整体 ACC,OC 提供了观察实例级别的监督信号,能更精确地反映模型答案的完备性,并为后续的规则修正和假设探索提供更有信息量的反馈。
分析
本节介绍了一些对 LLMs 归纳推理和归纳偏置进行理论分析的探索性工作。
-
归纳能力源于归纳头 (induction heads) 研究表明,LLMs 强大的上下文学习 (in-context learning, ICL) 或样例模仿能力源于归纳头。归纳头是一种注意力头,它执行“匹配-复制”操作,识别并复制上下文中的相关 Token。实际上,归纳头是在上下文中对一个抽象的归纳过程进行元学习。
-
模型参数、架构和数据共同塑造归纳偏置 模型参数、架构和训练数据是形成归纳偏置的关键。研究发现,任务相似性在混合训练中至关重要。此外,数据增强(即使是噪声数据)和选择最小范数 (minimum norm) 也能影响模型的归纳泛化。
-
归纳即简单 (Induction means simplicity) 早期研究表明,复杂的模型架构和数据实际上可能阻碍归纳泛化,而正则化对于高阶模型形成归纳偏置可能是有害的。简单性对于归纳推理至关重要。寻找简单的归纳偏置、使用简单纯粹的语料库,往往是成功归纳推理的基础。
总结
本文首次对大语言模型的归纳推理进行了全面综述。文章将增强方法归纳为后训练、测试时扩展和数据增强三类,并总结了现有的评测基准,提出了一种基于沙箱的统一评测方法及观察覆盖率指标。此外,本文还分析了归纳能力的来源及影响因素,为未来的研究提供了坚实的理论基础和实践指导。