A Survey of Large Language Models
-
ArXiv URL: http://arxiv.org/abs/2303.18223v16
-
作者: Ji-rong Wen; Yifan Li; Z. Chen; J. Nie; Xiaolei Wang; Wayne Xin Zhao; Beichen Zhang; Xinyu Tang; Zican Dong; Kun Zhou; 等12人
-
发布机构: Renmin University of China; Université de Montréal
A Survey of Large Language Models
1 引言
语言是人类表达和交流的突出能力。让机器掌握类似人类的语言理解和沟通能力,一直是人工智能(AI)领域长久以来的研究挑战。语言建模 (Language modeling, LM) 是推动机器语言智能发展的主要方法之一。它旨在对词序列的生成概率进行建模,以预测未来(或缺失)的 token。
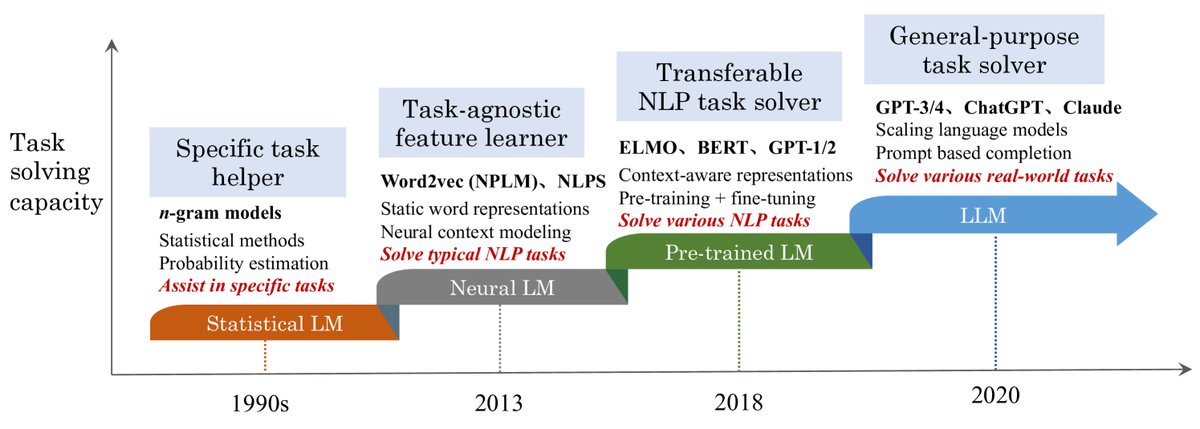
语言建模的发展大致可分为四个主要阶段,这四个阶段也体现了其解决任务能力的演进:
-
统计语言模型 (Statistical Language Models, SLM):SLM 基于 20 世纪 90 年代兴起的统计学习方法,核心思想是利用马尔可夫假设(例如,基于最近的上下文预测下一个词),如 n-gram 模型。然而,它们面临“维度灾难”问题,难以准确估计高阶语言模型。
-
神经语言模型 (Neural Language Models, NLM):NLM 使用神经网络(如 MLP、RNN)来刻画词序列的概率。其标志性贡献是引入了词的分布式表示 (distributed representation),并开启了使用语言模型进行表示学习(而不仅仅是词序建模)的先河,催生了 word2vec 等重要工作。
-
预训练语言模型 (Pre-trained Language Models, PLM):以 ELMo 和 BERT 为代表,PLM 通过在大型无标签语料库上对 Transformer 等架构进行预训练,学习上下文感知的词表示。这确立了“预训练-微调 (pre-training and fine-tuning)”的学习范式,极大地提升了各项自然语言处理(NLP)任务的性能。
-
大语言模型 (Large Language Models, LLM):研究发现,扩大 PLM 的规模(模型大小或数据大小)通常能提升模型在下游任务上的能力,这遵循所谓的“缩放法则 (scaling law)”。当模型参数规模超过某一水平时,这些放大的语言模型不仅性能显著提升,还表现出小模型(如 BERT)所不具备的特殊能力,即“涌现能力 (emergent abilities)”,例如上下文学习 (in-context learning)。最近,以 ChatGPT 为代表的 LLM 应用引起了社会的广泛关注。
 (a) 查询=”Language Model”
(a) 查询=”Language Model”
 (b) 查询=”Large Language Model”
(b) 查询=”Large Language Model”
从“语言建模”到“任务解决”,是理解语言模型发展史的关键。LLM 的发展正对整个 AI 社区产生重要影响,并可能革新我们开发和使用 AI 算法的方式。
本文认为 LLM 与 PLM 存在三个主要区别:
- 涌现能力:LLM 展现出小模型所没有的惊人能力,这是其在复杂任务上表现出色的关键。
- 新范式:LLM 改变了 AI 算法的开发和使用方式。用户主要通过提示接口 (prompting interface) 与 LLM 交互,需要理解其工作原理并相应地格式化任务。
- 研产结合:LLM 的发展模糊了研究与工程的界限,其训练需要大规模数据处理和分布式并行训练的丰富实践经验。
尽管 LLM 取得了巨大进展,但其底层原理仍有待探索,面临三大挑战:
- 涌现能力的来源:LLM 为何会产生涌现能力,其背后的关键因素是什么,这仍然是一个谜。
- 训练成本高昂:巨大的计算资源需求使得重复、消融性的研究变得非常昂贵,许多训练细节也未公开,阻碍了学术界的研究。
- 对齐挑战:LLM 可能会生成有毒、虚假或有害的内容,如何使其与人类的价值观或偏好对齐,是一个严峻的挑战。
2 概述
本节概述了 LLM 的背景知识,并总结了 GPT 系列模型的技术演进。
2.1 LLM 背景知识
通常,大语言模型(LLM)指包含数千亿(或更多)参数的 Transformer 语言模型,它们在海量文本数据上进行训练。LLM 展现出强大的自然语言理解和通过文本生成解决复杂任务的能力。
缩放法则 (Scaling Laws)
LLM 建立在 Transformer 架构之上,并通过显著增加模型大小、数据大小和总计算量来提升性能。缩放法则旨在量化地描述这种规模效应。
-
KM 缩放法则:由 OpenAI 团队于 2020 年提出,该法则建立了模型性能(以交叉熵损失 $L$ 衡量)与模型大小 ($N$)、数据集大小 ($D$) 和训练计算量 ($C$) 之间的幂律关系:
\[L(N) = \left(\frac{N_c}{N}\right)^{\alpha_N}\] \[L(D) = \left(\frac{D_c}{D}\right)^{\alpha_D}\] \[L(C) = \left(\frac{C_c}{C}\right)^{\alpha_C}\]其中,$N_c, D_c, C_c, \alpha_N, \alpha_D, \alpha_C$ 是通过拟合得到的常数。该法则表明,在其他因素不受瓶颈限制的情况下,模型性能与这三个因素有很强的依赖关系。
-
Chinchilla 缩放法则:由 Google DeepMind 团队提出,它为计算最优的 LLM 训练提供了另一种形式的缩放法则。通过在更大范围的模型和数据规模上进行实验,他们拟合出如下公式:
\[L(N, D) = E + \frac{A}{N^{\alpha}} + \frac{B}{D^{\beta}}\]在计算量约束 $C \approx 6ND$ 下,他们推导出最优的模型大小和数据大小应按如下比例分配:
\[N_{opt}(C) = G\left(\frac{C}{6}\right)^{a}, \quad D_{opt}(C) = G^{-1}\left(\frac{C}{6}\right)^{b}\]其中 $a=\frac{\alpha}{\alpha+\beta}$,$b=\frac{\beta}{\alpha+\beta}$。与 KM 法则倾向于更多地增加模型大小不同,Chinchilla 法则表明,模型大小和数据大小应该按大致相等的比例增加。
关于缩放法则的讨论:
- 可预测的缩放 (Predictable Scaling):缩放法则使得我们可以基于小模型的性能来可靠地预测大模型的性能。这有助于在资源有限的情况下,通过训练代理小模型来寻找最优训练策略,并能在训练大型模型时及早发现性能异常。
- 任务级别的可预测性:虽然语言模型损失的降低通常意味着下游任务性能的提升,但这种关系并非绝对。有时会出现“逆缩放 (inverse scaling)”现象,即模型越大,在某些任务上表现越差。此外,一些能力(如上下文学习)是无法通过缩放法则预测的,它们只有在模型规模达到一定程度时才会出现。
LLM 的涌现能力
涌现能力被定义为“小模型中不存在、但在大模型中出现的能力”,这是 LLM 与以往 PLM 最显著的区别之一。这些能力通常在模型规模达到某个临界点时,性能会突然显著高于随机水平,类似于物理学中的“相变 (phase transition)”现象。
三种典型的涌 ઉ 能力:
-
上下文学习 (In-context learning, ICL):由 GPT-3 首次正式提出。LLM 可以在不进行额外训练或梯度更新的情况下,仅通过自然语言指令和几个任务示例,就能为新的测试实例生成预期的输出。例如,175B 的 GPT-3 展现出强大的 ICL 能力,而 GPT-2 则不具备。
-
指令遵循 (Instruction following):通过在多种以自然语言描述的任务(即指令)上进行微调(称为指令调优),LLM 能够很好地泛化到未见过但同样以指令形式描述的新任务上。实验表明,当模型规模达到 68B 时,经过指令调优的 LaMDA-PT 开始显著优于未调优版本。
-
逐步推理 (Step-by-step reasoning):小模型难以解决需要多步推理的复杂任务(如数学应用题)。而通过思维链 (Chain-of-Thought, CoT) 提示策略,LLM 能够生成中间推理步骤,并最终导出正确答案。研究表明,当模型规模超过 60B 时,CoT 提示开始带来显著收益,在超过 100B 时优势更加明显。
LLM 的关键技术
LLM 的成功归功于一系列关键技术的进步。
-
扩展 (Scaling):如前所述,扩大模型/数据规模和计算投入是提升模型能力的核心。Chinchilla 等模型展示了在固定计算预算下,通过优化数据和模型规模的配比可以获得更优的性能。同时,预训练数据的质量至关重要。
-
训练 (Training):训练 LLM 极具挑战性。通常需要结合多种并行策略的分布式训练算法。DeepSpeed 和 Megatron-LM 等优化框架为此提供了支持。此外,混合精度训练、训练重启等优化技巧对于保证训练稳定性和模型性能也十分重要。
-
能力激发 (Ability eliciting):预训练后的 LLM 拥有潜在的通用任务解决能力,但需要通过特定的技术来“激发”。例如,通过精心设计的任务指令或 CoT 等上下文学习策略,可以引导模型展现出推理等高级能力。指令调优是提升模型泛化能力的另一种有效方式。
-
对齐调优 (Alignment tuning):为了防止 LLM 生成有害内容,需要将其与人类价值观(如“有帮助的”、“诚实的”、“无害的”)对齐。InstructGPT 提出了基于人类反馈的强化学习 (Reinforcement Learning with Human Feedback, RLHF) 技术,通过将人类纳入训练循环,有效引导模型遵循预期指令。ChatGPT 正是基于类似技术开发的。
-
工具操纵 (Tools manipulation):LLM 本质上是文本生成器,不擅长精确计算或获取实时信息。通过赋予 LLM 使用外部工具的能力(如计算器、搜索引擎),可以弥补其内在缺陷。ChatGPT 的插件机制正是这一思想的体现,极大地扩展了 LLM 的能力边界。
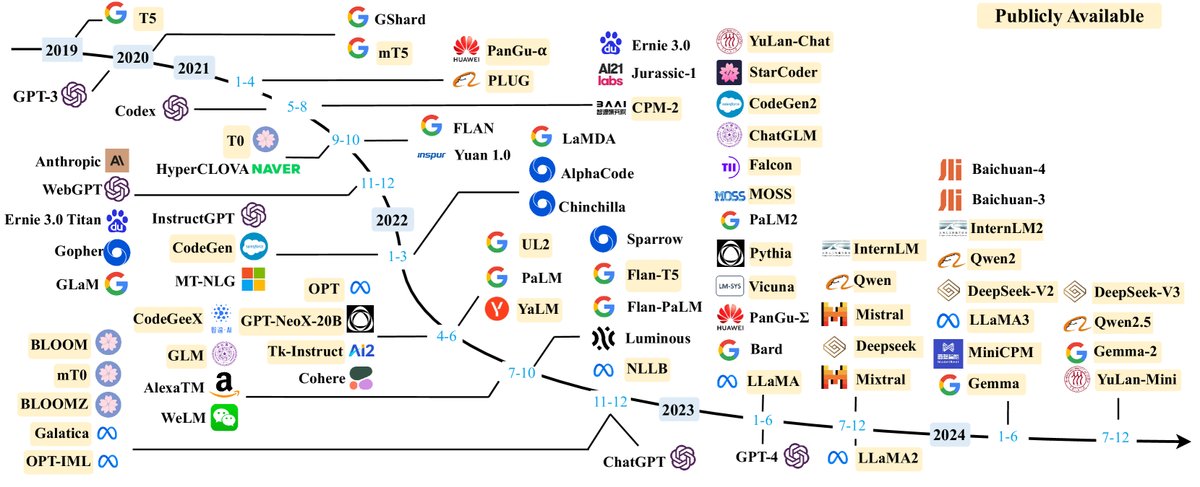
下表总结了近年来发布的一些主要 LLM 的统计信息。
TABLE I: 近年来大语言模型(本文中指规模大于10B)的统计数据,包括能力评估、预训练数据规模(token 数量或存储大小)和硬件资源成本。本表仅包含已发布技术细节论文的LLM。 “发布时间”指相应论文正式发布的日期。”公开可用”指模型检查点可公开访问,”闭源”则相反。 “适配”指模型是否经过后续微调:IT代表指令调优,RLHF代表基于人类反馈的强化学习。 “评估”指模型是否在其原始论文中评估了相应能力:ICL代表上下文学习,CoT代表思维链。”*“表示可公开获得的最大版本。
| 模型 | 发布时间 | 大小 (B) | 基础模型 | 适配 | 预训练数据规模 | 最新数据时间戳 | 硬件 (GPUs / TPUs) | 训练时间 | 评估 | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IT | RLHF | ICL | CoT | |||||||||
| 公开可用 | T5 [82] | 2019-10 | 11 | - | - | - | 1T tokens | 2019-04 | 1024 TPU v3 | - | $\checkmark$ | - |
| mT5 [83] | 2020-10 | 13 | - | - | - | 1T tokens | - | - | - | $\checkmark$ | - | |
| PanGu-$\alpha$ [84] | 2021-04 | 13* | - | - | - | 1.1TB | - | 2048 Ascend 910 | - | $\checkmark$ | - | |
| CPM-2 [85] | 2021-06 | 198 | - | - | - | 2.6TB | - | - | - | - | - | |
| T0 [28] | 2021-10 | 11 | T5 | $\checkmark$ | - | - | - | 512 TPU v3 | 27 h | $\checkmark$ | - | |
| CodeGen [86] | 2022-03 | 16 | - | - | - | 577B tokens | - | - | - | $\checkmark$ | - | |
| GPT-NeoX-20B [87] | 2022-04 | 20 | - | - | - | 825GB | - | 96 40G A100 | - | $\checkmark$ | - | |
| Tk-Instruct [88] | 2022-04 | 11 | T5 | $\checkmark$ | - | - | - | 256 TPU v3 | 4 h | $\checkmark$ | - | |
| UL2 [89] | 2022-05 | 20 | - | - | - | 1T tokens | 2019-04 | 512 TPU v4 | - | $\checkmark$ | $\checkmark$ | |
| OPT [90] | 2022-05 | 175 | - | - | - | 180B tokens | - | 992 80G A100 | - | $\checkmark$ | - | |
| NLLB [91] | 2022-07 | 54.5 | - | - | - | - | - | - | - | $\checkmark$ | - | |
| CodeGeeX [92] | 2022-09 | 13 | - | - | - | 850B tokens | - | 1536 Ascend 910 | 60 d | $\checkmark$ | - | |
| GLM [93] | 2022-10 | 130 | - | - | - | 400B tokens | - | 768 40G A100 | 60 d | $\checkmark$ | - | |
| Flan-T5 [69] | 2022-10 | 11 | T5 | $\checkmark$ | - | - | - | - | - | $\checkmark$ | $\checkmark$ | |
| BLOOM [78] | 2022-11 | 176 | - | - | - | 366B tokens | - | 384 80G A100 | 105 d | $\checkmark$ | - | |
| mT0 [94] | 2022-11 | 13 | mT5 | $\checkmark$ | - | - | - | - | - | $\checkmark$ | - | |
| Galactica [35] | 2022-11 | 120 | - | - | - | 106B tokens | - | - | - | $\checkmark$ | $\checkmark$ | |
| BLOOMZ [94] | 2022-11 | 176 | BLOOM | $\checkmark$ | - | - | - | - | - | $\checkmark$ | - | |
| OPT-IML [95] | 2022-12 | 175 | OPT | $\checkmark$ | - | - | - | 128 40G A100 | - | $\checkmark$ | $\checkmark$ | |
| LLaMA [57] | 2023-02 | 65 | - | - | - | 1.4T tokens | - | 2048 80G A100 | 21 d | $\checkmark$ | - | |
| Pythia [96] | 2023-04 | 12 | - | - | - | 300B tokens | - | 256 40G A100 | - | $\checkmark$ | - | |
| CodeGen2 [97] | 2023-05 | 16 | - | - | - | 400B tokens | - | - | - | $\checkmark$ | - | |
| StarCoder [98] | 2023-05 | 15.5 | - | - | - | 1T tokens | - | 512 40G A100 | - | $\checkmark$ | $\checkmark$ | |
| LLaMA2 [99] | 2023-07 | 70 | - | $\checkmark$ | $\checkmark$ | 2T tokens | - | 2000 80G A100 | - | $\checkmark$ | - | |
| Baichuan2 [100] | 2023-09 | 13 | - | $\checkmark$ | $\checkmark$ | 2.6T tokens | - | 1024 A800 | - | $\checkmark$ | - | |
| QWEN [101] | 2023-09 | 14 | - | $\checkmark$ | $\checkmark$ | 3T tokens | - | - | - | $\checkmark$ | - | |
| FLM [102] | 2023-09 | 101 | - | $\checkmark$ | - | 311B tokens | - | 192 A800 | 22 d | $\checkmark$ | - | |
| Skywork [103] | 2023-10 | 13 | - | - | - | 3.2T tokens | - | 512 80G A800 | - | $\checkmark$ | - | |
| 闭源 | GPT-3 [55] | 2020-05 | 175 | - | - | - | 300B tokens | - | - | - | $\checkmark$ | - |
| GShard [104] | 2020-06 | 600 | - | - | - | 1T tokens | - | 2048 TPU v3 | 4 d | - | - | |
| Codex [105] | 2021-07 | 12 | GPT-3 | - | - | 100B tokens | 2020-05 | - | - | $\checkmark$ | - | |
| ERNIE 3.0 [106] | 2021-07 | 10 | - | - | - | 375B tokens | - | 384 V100 | - | $\checkmark$ | - | |
| Jurassic-1 [107] | 2021-08 | 178 | - | - | - | 300B tokens | - | 800 GPU | - | $\checkmark$ | - | |
| HyperCLOVA [108] | 2021-09 | 82 | - | - | - | 300B tokens | - | 1024 A100 | 13.4 d | $\checkmark$ | - | |
| FLAN [67] | 2021-09 | 137 | LaMDA-PT | $\checkmark$ | - | - | - | 128 TPU v3 | 60 h | $\checkmark$ | - | |
| Yuan 1.0 [109] | 2021-10 | 245 | - | - | - | 180B tokens | - | 2128 GPU | - | $\checkmark$ | - | |
| Anthropic [110] | 2021-12 | 52 | - | - | - | 400B tokens | - | - | - | $\checkmark$ | - | |
| WebGPT [81] | 2021-12 | 175 | GPT-3 | - | $\checkmark$ | - | - | - | - | $\checkmark$ | - | |
| Gopher [64] | 2021-12 | 280 | - | - | - | 300B tokens | - | 4096 TPU v3 | 920 h | $\checkmark$ | - | |
| ERNIE 3.0 Titan [111] | 2021-12 | 260 | - | - | - | - | - | - | - | $\checkmark$ | - | |
| GLaM [112] | 2021-12 | 1200 | - | - | - | 280B tokens | - | 1024 TPU v4 | 574 h | $\checkmark$ | - | |
| LaMDA [68] | 2022-01 | 137 | - | - | - | 768B tokens | - | 1024 TPU v3 | 57.7 d | - | - | |
| MT-NLG [113] | 2022-01 | 530 | - | - | - | 270B tokens | - | 4480 80G A100 | - | $\checkmark$ | - | |
| AlphaCode [114] | 2022-02 | 41 | - | - | - | 967B tokens | 2021-07 | - | - | - | - | |
| InstructGPT [66] | 2022-03 | 175 | GPT-3 | $\checkmark$ | $\checkmark$ | - | - | - | - | $\checkmark$ | - | |
| Chinchilla [34] | 2022-03 | 70 | - | - | - | 1.4T tokens | - | - | - | $\checkmark$ | - | |
| PaLM [56] | 2022-04 | 540 | - | - | - | 780B tokens | - | 6144 TPU v4 | - | $\checkmark$ | $\checkmark$ | |
| AlexaTM [115] | 2022-08 | 20 | - | - | - | 1.3T tokens | - | 128 A100 | 120 d | $\checkmark$ | $\checkmark$ | |
| Sparrow [116] | 2022-09 | 70 | - | - | $\checkmark$ | - | - | 64 TPU v3 | - | $\checkmark$ | - | |
| WeLM [117] | 2022-09 | 10 | - | - | - | 300B tokens | - | 128 A100 40G | 24 d | $\checkmark$ | - | |
| U-PaLM [118] | 2022-10 | 540 | PaLM | - | - | - | - | 512 TPU v4 | 5 d | $\checkmark$ | $\checkmark$ | |
| Flan-PaLM [69] | 2022-10 | 540 | PaLM | $\checkmark$ | - | - | - | 512 TPU v4 | 37 h | $\checkmark$ | $\checkmark$ | |
| Flan-U-PaLM [69] | 2022-10 | 540 | U-PaLM | $\checkmark$ | - | - | - | - | - | $\checkmark$ | $\checkmark$ | |
| GPT-4 [46] | 2023-03 | - | - | $\checkmark$ | $\checkmark$ | - | - | - | - | $\checkmark$ | $\checkmark$ | |
| PanGu-$\Sigma$ [119] | 2023-03 | 1085 | PanGu-$\alpha$ | - | - | 329B tokens | - | 512 Ascend 910 | 100 d | $\checkmark$ | - | |
| PaLM2 [120] | 2023-05 | 16 | - | $\checkmark$ | - | 100B tokens | - | - | - | $\checkmark$ | $\checkmark$ |
2.2 GPT 系列模型的技术演进
ChatGPT 的巨大成功激发了社区对 GPT 系列模型的浓厚兴趣。GPT 模型的基本原理是通过语言建模任务,将世界知识压缩到一个仅包含解码器 (decoder-only) 的 Transformer 模型中,使其能够恢复或记忆世界知识的语义,从而成为一个通用的任务解决器。其成功的两个关键点是:(I) 训练能够准确预测下一个词的 decoder-only Transformer 语言模型,以及 (II) 扩大语言模型的规模。
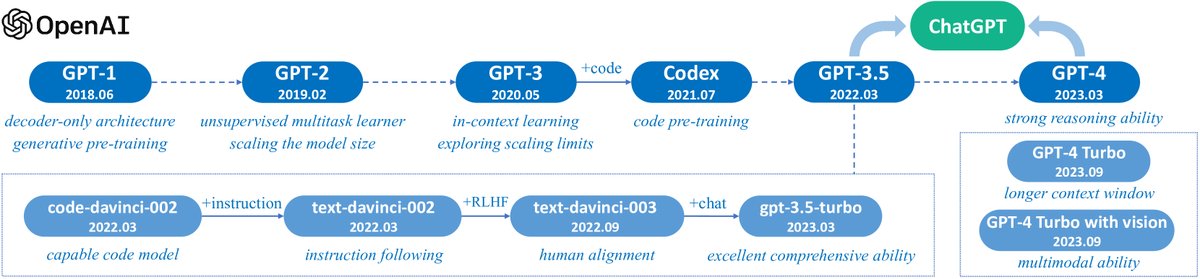
OpenAI 在 LLM 上的研究大致可分为以下几个阶段:
早期探索 根据 OpenAI 联合创始人 Ilya Sutskever 的访谈,OpenAI 早期就已探索用语言模型来构建智能系统,当时尝试的是循环神经网络(RNN)。随着 Transformer 的出现,OpenAI 开发了最初的两代 GPT 模型:GPT-1 和 GPT-2,它们为后续更强大的 GPT-3 和 GPT-4 奠定了基础。
- GPT-1:2017 年 Google 推出 Transformer 模型后,OpenAI 团队迅速将其应用于语言建模工作。他们在 2018 年发布了第一个 GPT 模型,即 GPT-1,并创造了 GPT 这个缩写词,代表该模型。