A Survey of Reinforcement Learning for Large Reasoning Models
-
ArXiv URL: http://arxiv.org/abs/2509.08827v1
-
作者: Ning Ding; Xiang Xu; Biqing Qi; Xiaoye Qu; Shang Qu; Zhiyuan Ma; Kaiyan Zhang; Yihao Liu; Junqi Gao; Huayu Chen; 等37人
-
发布机构: Harbin Institute of Technology; Huazhong University of Science and Technology; Peking University; Shanghai AI Laboratory; Shanghai Jiao Tong University; Tsinghua University; University College London; University of Science and Technology of China; University of Washington
对用于大型推理模型的强化学习的综述
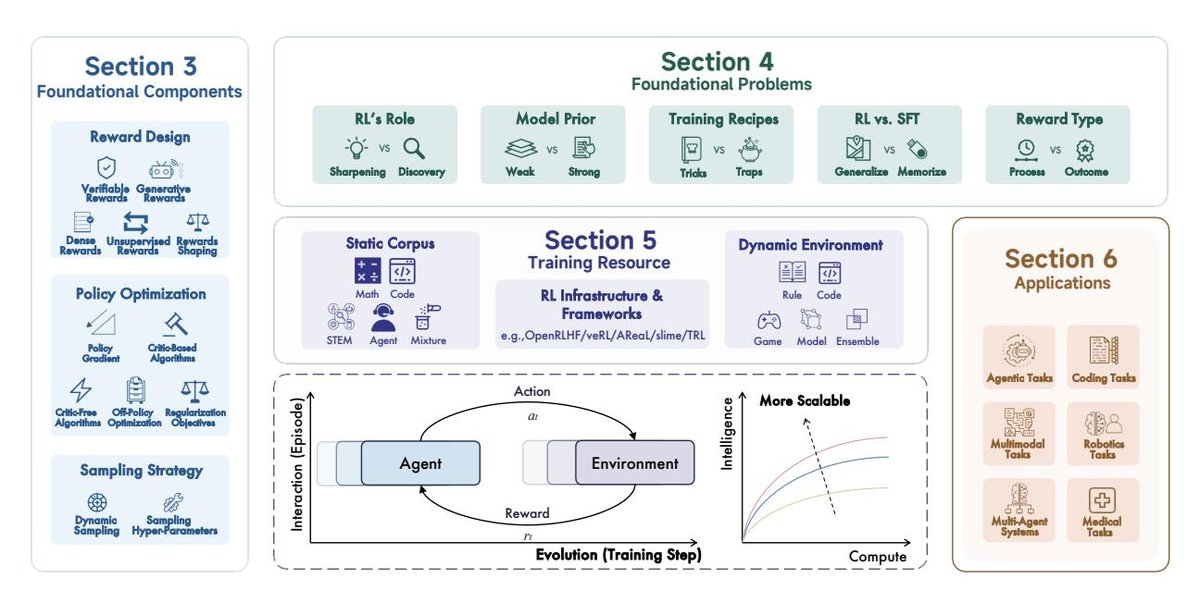
| 图 1 | 本综述概览。本文介绍了用于大型推理模型的强化学习的基础组件,以及开放性问题、训练资源和应用。本综述的核心是关注语言智能体与环境在长期演化过程中的大规模交互。 |
1. 引言
强化学习 (Reinforcement Learning, RL) 已多次证明,通过狭义且明确的奖励信号,可以驱动智能体在复杂任务中达到超人水平。诸如 AlphaGo 和 AlphaZero 等里程碑式的系统,完全通过自我对弈和奖励反馈进行学习,在围棋、象棋、将棋和战略游戏中超越了世界冠军,确立了 RL 作为解决高阶问题的一种实用且有前景的技术。
在大型语言模型 (Large Language Models, LLMs) 时代,RL 最初作为人类对齐的训练后策略而声名鹊起。诸如从人类反馈中强化学习 (Reinforcement Learning from Human Feedback, RLHF) 和直接偏好优化 (Direct Preference Optimization, DPO) 等广泛采用的方法,通过微调预训练模型来遵循指令并反映人类偏好,显著提升了模型的有益性、诚实性和无害性(3H)。
近期出现了一个新趋势:将 RL 用于大型推理模型 (Large Reasoning Models, LRMs),其目标不仅是行为对齐,更是激励推理本身。两个最新的里程碑(即 OpenAI 的 o1 和 DeepSeek-R1)表明,使用可验证奖励的强化学习 (Reinforcement Learning with Verifiable Rewards, RLVR) 来训练 LLM,例如数学题的答案正确性或代码的单元测试通过率,可以使模型执行包括规划、反思和自我纠正在内的长式推理。这种动态引入了一条与预训练中的数据和参数扩展相辅相成的能力提升路径,同时利用了奖励最大化目标和可靠的自动可检查奖励。
与此同时,为 LRMs 进一步扩展 RL 带来了新的制约,不仅涉及计算资源,还涉及算法设计、训练数据和基础设施。如何以及在何处扩展用于 LRMs 的 RL 以实现高水平智能并创造现实世界价值,仍是悬而未决的问题。因此,本文认为,现在是时候回顾这一领域的发展,并探索提升 RL 可扩展性以迈向通用人工智能 (Artificial SuperIntelligence, ASI) 的策略。
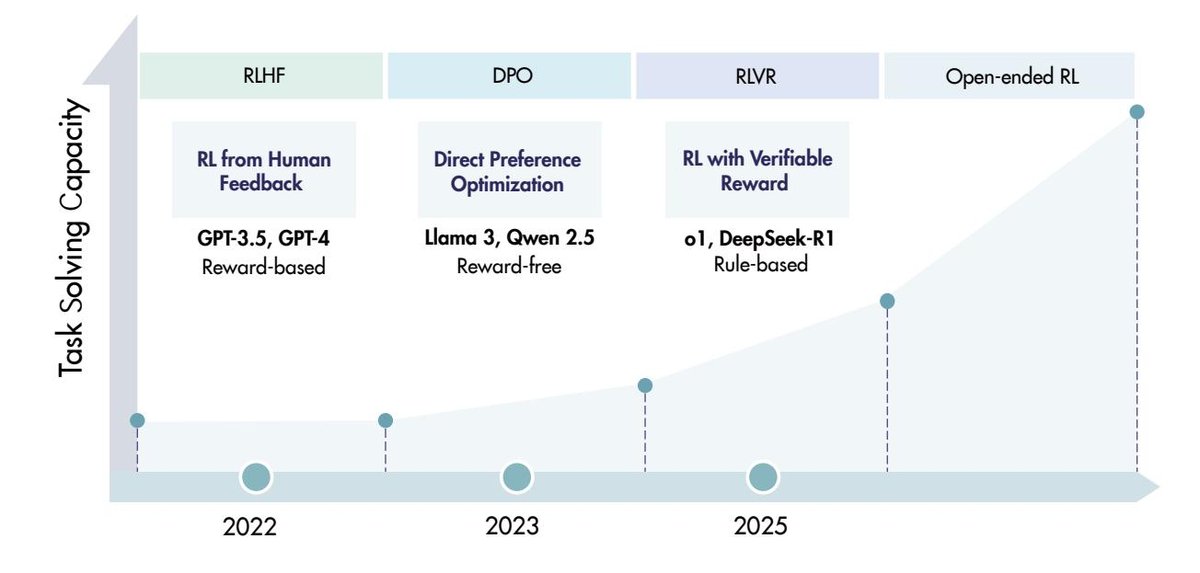
| 图 2 | 近年来,RLHF 和 DPO 已成为人类对齐的两种主流 RL 方法。相比之下,RLVR 代表了用于 LRMs 的 RL 的一个新兴趋势,它显著增强了模型解决复杂任务的能力。LLM 的 RL 下一阶段扩展仍然是一个开放问题,而开放式 RL 则是一个特别具有挑战性和前景的方向。 |
综上所述,本综述回顾了近期关于 RL 用于 LRMs 的工作,具体如下:
- 介绍了在 LRMs 背景下 RL 建模的初步定义,并概述了自 OpenAI o1 发布以来前沿推理模型的发展。
- 回顾了关于 RL for LRMs 基础组件的最新文献,包括奖励设计、策略优化和采样策略。
- 讨论了 RL for LRMs 中基础性且仍存争议的问题,如 RL 的角色、RL 与监督微调 (SFT) 的对比等。
- 考察了 RL 的训练资源,包括静态语料库、动态环境和训练基础设施。
- 回顾了 RL 在广泛任务中的应用,如编码、智能体任务、多模态任务等。
- 最后,讨论了语言模型 RL 的未来方向。
2. 预备知识
2.1. 背景
本节介绍了 RL 的基本组件,并描述了如何将语言模型配置为 RL 框架中的智能体。如图 3 所示,RL 为序贯决策提供了一个通用框架,其中智能体通过采取行动与环境交互,以最大化累积奖励。
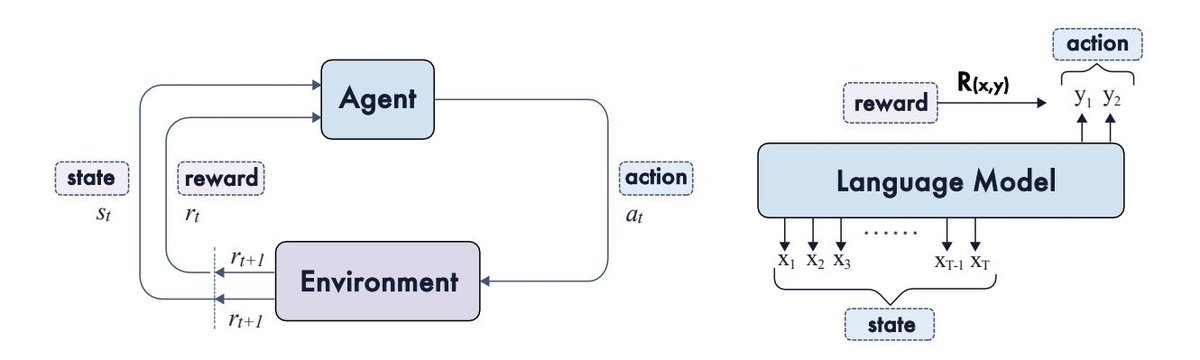
| 图 3 | RL 的基本组件和作为智能体的语言模型(LM)。智能体选择动作,而环境在每个回合提供状态和奖励。在 LM 的上下文中,生成的 Token 被视为动作,与上下文连接形成状态。奖励通常在整个响应的层级上分配。 |
在经典 RL 中,问题通常被表述为马尔可夫决策过程 (Markov Decision Process, MDP),由一个元组 $(\mathcal{S}, \mathcal{A}, P, R, \gamma)$ 定义。主要组件包括:状态空间 $\mathcal{S}$、动作空间 $\mathcal{A}$、转移动态 $P$,奖励函数 $R$ 以及折扣因子 $\gamma \in [0, 1]$。在将 RL 应用于语言模型时,这些概念可以自然地映射到语言领域:
- 提示/任务 (Prompt/Task $x$): 对应初始状态或环境上下文,从数据分布 $\mathcal{D}$ 中抽取。
- 策略 (Policy $\pi_{\theta}$): 代表语言模型,它为响应提示生成一个 Token 序列 $y = (y_1, …, y_T)$。
- 状态 (State $s_t$): 定义为提示与到目前为止已生成的序列的组合,即 $s_t = (x, y_{1:t-1})$。
- 动作 (Action $a_t$): 在步骤 $t$ 从词汇表 $V$ 中选择的 Token,即 $a_t=y_t$。
- 转移动态 (Transition Dynamics P): 在 LLM 上下文中通常是确定性的,因为 $s_{t+1} = [s_t, a_t]$。
- 奖励 (Reward $R(x, y)$ or $r_t$): 通常在序列结束时分配(序列级奖励),表示为 $R(x, y)$,但也可以分解为 Token 级的过程监督奖励。
- 回报 (Return $G_0$): 整个轨迹上累积的(可选折扣的)奖励。对于序列级反馈,它简化为单个标量 $R(x, y)$。
在这种设定下,学习目标是最大化数据分布 $\mathcal{D}$ 上的期望奖励:
\[\max_{\theta} \mathcal{J}(\theta) := \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_{\theta}(x)} [R(x, y)]\]实践中,通常会通过对学习到的策略施加相对于参考策略 $\pi_{\text{ref}}$ 的正则化(通常是 KL 散度约束)来稳定训练并保持语言质量。
2.2. 前沿模型
本节概述了使用类 RL 方法训练的最先进的大型推理模型,大致按时间顺序分为三个主要方向:大型推理模型、智能体式大型推理模型和多模态大型推理模型。
过去一年中,RL 逐步扩展了推理模型及其应用的前沿。OpenAI 的 o1 系列确立了扩展训练时 RL 和测试时计算以增强推理能力的有效性。DeepSeek 的 R1 是首个在基准测试中与 o1 表现相匹配的开源模型。此后,专有模型如 Claude-3.7-Sonnet、Gemini 2.0/2.5、Seed-Thinking 1.5 和 o3 系列相继发布。近期,OpenAI 推出了其首个开源推理模型 gpt-oss-120b 和其最强系统 GPT-5。并行的开源工作也持续扩展,如 Qwen3 系列、Skywork-OR1、Minimax-M1、Llama-Nemotron-Ultra 等。
模型推理能力的提升也扩展了其在编码和智能体场景中的应用。Claude 系列在智能体编码任务上表现领先,Kimi K2、GLM4.5 和 DeepSeek-V3.1 也都强调了工具使用和智能体任务。
多模态是推理模型广泛应用的关键组成部分。大多数前沿专有模型(如 GPT-5、o3、Claude、Gemini)都是原生多模态的。开源方面,Kimi 1.5、QVQ、Skywork R1V2、InternVL 系列(InternVL3, InternVL3.5)、Intern-S1、Step3 和 GLM-4.5V 等模型也在多模态推理方面取得了显著进展,它们通过不同的方法(如混合 RL、级联 RL 框架、混合奖励设计)来平衡推理能力和通用能力,或专注于特定领域(如科学推理)。
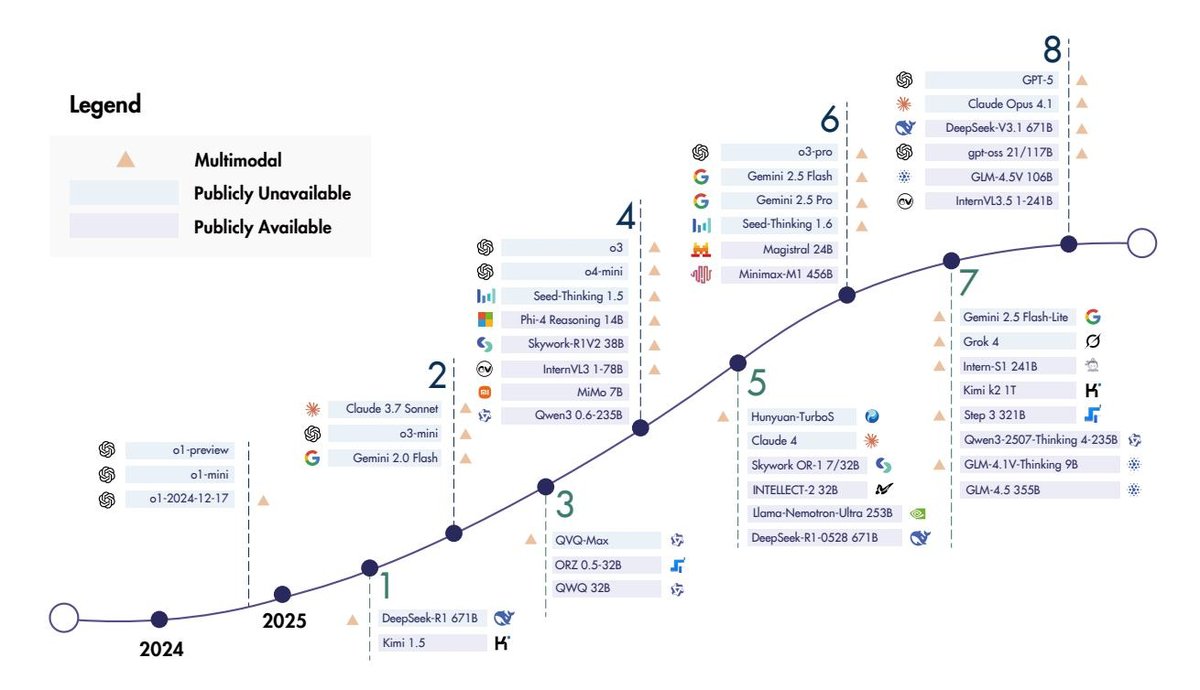
| 图 4 | 使用 RL 训练的代表性开源和闭源推理模型的时间线,包括语言模型、多模态模型和智能体模型。 |
下表详细列出了代表性的开源模型信息。
| 日期 | 模型 | 组织 | 架构 | 参数 | 算法 | 模态 | 链接 |
|---|---|---|---|---|---|---|---|
| 2025.01 | DeepSeek-R1 | DeepSeek | MoE/MLA | 671B | GRPO | 文本 | § |
| 2025.03 | ORZ | StepAI | Dense | 0.5-32B | PPO | 文本 | § |
| 2025.03 | QwQ | Alibaba Qwen | Dense | 32B | - | 文本 | § |
| 2025.04 | Phi-4 Reasoning | Microsoft | Dense | 14B | GRPO | 文本 | § |
| 2025.04 | Skywork-R1V2 | Skywork | Dense | 38B | MPO/GRPO | T/I | § |
| 2025.04 | InternVL3 | Shanghai AI Lab | Dense | 1-78B | MPO | T/I/V | § |
| 2025.04 | MiMo | Xiaomi | Dense | 7B | GRPO | 文本 | § |
| 2025.04 | Qwen3 | Alibaba Qwen | MoE/Dense | 0.6-235B | GRPO | 文本 | § |
| 2025.05 | Llama-Nemotron-Ultra | NVIDIA | Dense | 253B | GRPO | 文本 | § |
| 2025.05 | INTELLECT-2 | Intellect AI | Dense | 32B | GRPO | 文本 | |
| 2025.05 | Hunyuan-TurboS | Tencent | Hybrid MoE | 560B | GRPO | 文本 | § |
| 2025.05 | Skywork OR-1 | Skywork | Dense | 7B/32B | GRPO | 文本 | § |
| 2025.05 | DeepSeek-R1-0528 | DeepSeek | MoE/MLA | 671B | GRPO | 文本 | § |
| 2025.06 | Magistral | Mistral AI | Dense | 24B | GRPO | 文本 | |
| 2025.06 | Minimax-M1 | Minimax | Hybrid MoE | 456B | CISPO | 文本 | § |
| 2025.07 | Intern-S1 | Shanghai AI Lab | MoE | 241B | GRPO | T/I/V | § |
| 2025.07 | Kimi K2 | Kimi | MoE | 1T | OPMD | 文本 | § |
| 2025.07 | Step 3 | Step AI | MoE | 321B | - | T/I/V | § |
| 2025.07 | Qwen3-2507 | Alibaba Qwen | MoE/Dense | 4-235B | GSPO | 文本 | § |
| 2025.07 | GLM-4.1V-Thinking | Zhipu AI | Dense | 9B | GRPO | T/I/V | § |
| 2025.07 | GLM-4.5 | Zhipu AI | MoE | 355B | GRPO | 文本 | § |
| 2025.07 | Skywork-R1V3 | Skywork | Dense | 38B | GRPO | T/I | § |
| 2025.08 | gpt-oss | OpenAI | MoE | 117B/21B | - | 文本 | § |
| 2025.08 | Seed-OSS | Bytedance Seed | Dense | 36B | - | 文本 | § |
| 2025.08 | GLM-4.5V | Zhipu AI | MoE | 106B | GRPO | T/I/V | § |
| 2025.08 | InternVL3.5 | Shanghai AI Lab | MoE/Dense | 1-241B | MPO/GSPO | T/I/V | § |
| 2025.09 | ERNIE-4.5-Thinking | Baidu | MoE | 21B-A3B | - | 文本 |
注:OPMD 表示 Online Policy Mirror Descent;MPO 表示 Mixed Preference Optimization;CISPO 表示 Clipped IS weight Policy Optimization。T, I, V 分别表示文本、图像和视频模态。
2.3. 相关综述
本节比较了近期与 RL 和 LLM 相关的综述。一些综述主要关注 RL 本身,但未明确涉及其在 LLM 上的应用。其他综述则侧重于 LLM 及其新兴能力,如长链思维推理和自适应行为,其中 RL 常被视为支持这些进步的关键方法之一。
与以往的综述不同,本文将 RL 置于中心位置,系统性地综合了其在 LLM 训练生命周期中的作用,包括奖励设计、策略优化和采样策略。本文旨在为扩展 LRMs 中的强化学习以迈向 ASI(通用人工智能),尤其是在长期交互和演化方面,指明新的方向。
3. 基础组件
本节回顾了用于 LRMs 的 RL 的基础组件,包括奖励设计(§ 3.1)、策略优化算法(§ 3.2)和采样策略(§ 3.3)。下图展示了这些基础组件的分类体系。
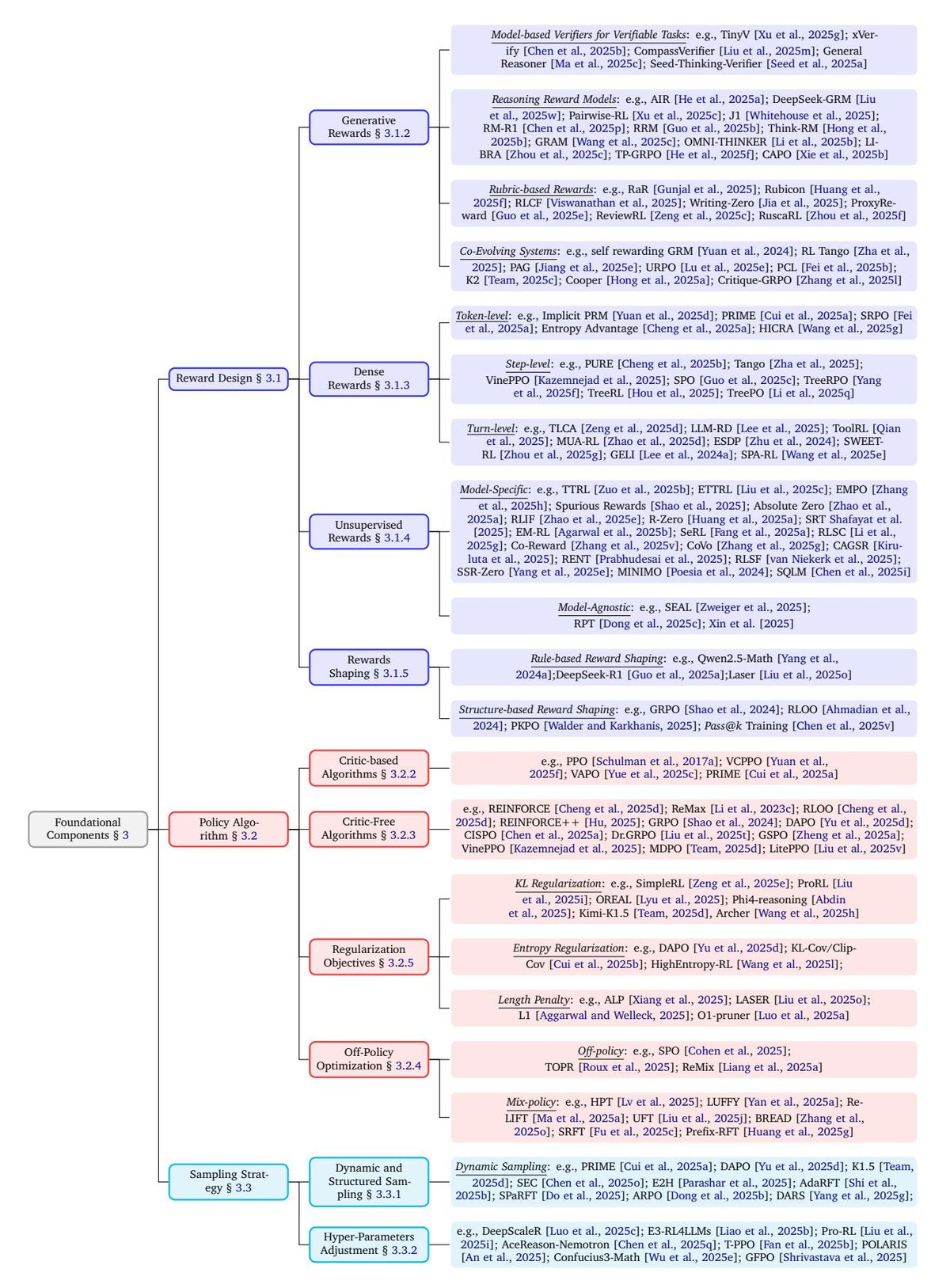

3.1. 奖励设计
本节全面考察了用于 LRMs 的 RL 中的奖励设计。本文从可验证奖励开始,这是自然的起点,并在此方向上取得了显著进展。接着,本文探讨了生成式奖励,即利用模型自身来验证或直接生成奖励信号。之后,本文分析了旨在提供更密集反馈信号的方法。此外,本文还讨论了无监督奖励,它直接由模型估算而非依赖外部真实标签。最后,本文分析了奖励塑造策略,即组合或转换不同奖励信号以促进学习。
3.1.1. 可验证奖励
核心要点
- 基于规则的奖励通过利用准确性和格式检查,为 RL 提供了可扩展且可靠的训练信号,尤其在数学和代码任务中。
- 验证者定律 (Verifier’s law) 指出,具有清晰和自动验证方法的任务能够实现高效的 RL 优化,而主观性任务仍然充满挑战。
基于规则的奖励 (Rule-based Rewards)。奖励是 RL 的训练信号,决定了优化方向。最近,基于规则的可验证奖励已主导性地用于大规模 RL 中训练 LRMs。这种奖励通过鼓励更长、更具反思性的思维链来可靠地增强数学和编码推理能力。这一范式在 Tülu 3 中被形式化为 RLVR,它用程序化验证器(如答案检查器或单元测试)取代了学习的奖励模型。
- 准确性奖励 (Accuracy rewards): 对于具有确定性结果的任务(如数学),策略必须在指定的分隔符内生成最终解。自动检查器会将其与真实答案进行比较。对于编码任务,单元测试或编译器提供通过/失败信号。
- 格式奖励 (Format rewards): 这些奖励施加结构性约束,要求模型将其私有思维链置于 \(<think>\) 和 \(</think>\) 之间,并将最终答案输出在单独的字段中。
基于规则的验证器 (Rule-based Verifier)。基于规则的奖励通常源自基于规则的验证器,这些验证器依赖大量手动编写的等价规则来判断预测答案是否与真实答案匹配。目前,广泛使用的数学验证器主要基于 Python 库 Math-Verify 和 SymPy 构建。
实践中,数学问题解决和代码生成等任务“难于解决但易于验证”,满足了高效 RL 优化的主要标准。相比之下,缺乏快速或客观验证的任务(如开放式问答)对于基于结果的 RL 仍然具有挑战性。验证者定律指出,训练 AI 系统执行一项任务的难易程度与该任务可被验证的程度成正比。
3.1.2. 生成式奖励
核心要点
- 生成式奖励模型 (Generative Reward Models, GenRMs) 通过提供细致的、基于文本的反馈,将 RL 扩展到主观、不可验证的领域,克服了基于规则系统的局限性。
- 一个主要趋势是训练奖励模型在判断前进行推理,通常使用结构化准则来指导评估,或在统一的 RL 循环中与策略模型共同演进。
虽然基于规则的奖励为可验证任务提供了可靠信号,但其适用性有限。为了弥补这一差距,GenRMs 已成为一种强大的替代方案。GenRMs 利用 LRM 的生成能力来产生结构化的批评、理由和偏好,从而提供更具解释性和细致的奖励信号。这解决了两大挑战:提高了难以解析的可验证任务的验证鲁棒性,并使 RL 能够应用于主观、不可验证的领域。
用于可验证任务的基于模型的验证器。为了解决基于规则的系统因格式不匹配而产生的误报问题,研究人员使用“基于规范的 GenRMs”作为灵活的、基于模型的验证器。这些模型被训练来语义上评估模型输出与参考答案的等价性。
用于不可验证任务的生成式奖励。GenRMs 的另一个核心应用是“基于评估的 GenRMs”,它使得 RL 能够用于“验证者定律”不成立的任务。这一范式已从使用强大的 LLM 作为零样本评估器发展到复杂的、共同演进的系统。主要设计原则包括:
- 推理奖励模型(学会思考): 训练奖励模型在做出判断前明确地进行推理。例如,先生成自然语言的批评,然后用它来预测一个标量奖励。
- 基于准则的奖励(结构化主观性): 采用结构化的评估准则(rubrics)来锚定主观任务的评估。LLM 使用或遵循一个原则清单来指导其评估,产生细粒度、多方面的奖励。
- 共同演进系统(统一策略与奖励): 最先进的范式是动态系统,其中生成器和验证器共同进步。
- 自我奖励: 单个模型生成自己的训练信号,交替扮演策略和验证器的角色。
- 协同优化: 策略和一个独立的奖励模型被同时训练,以增强鲁棒性并减轻奖励作弊(reward hacking)。
这种从静态评判者到动态、共同演进系统的演变,证明了生成式奖励对于将 RL 扩展到通用 LRMs 所针对的全部任务范围是不可或缺的。
3.1.3. 密集奖励
核心要点
- 密集奖励(例如,过程奖励模型)提供了细粒度的信用分配,并提高了 RL 中的训练效率和优化稳定性。
- 由于难以定义密集奖励或使用验证器,对于开放域文本生成等任务,扩展仍然具有挑战性。
在经典 RL 任务(如游戏和机器人操作)中,密集奖励 (Dense rewards) 在(几乎)每个决策步骤都提供频繁反馈。这种奖励塑造缩短了信用分配的周期,通常能提高样本效率和优化稳定性,但它也…