A Survey on Agentic Multimodal Large Language Models
-
ArXiv URL: http://arxiv.org/abs/2510.10991v1
-
作者: Guanbin Li; Dacheng Tao; Yongcheng Jing; Bo Fang; Ruifei Zhang; Huanjin Yao; Jingyi Zhang; Yibo Wang; Shunyu Liu; Jiaxing Huang
-
发布机构: Chinese University of Hong Kong, Shenzhen; City University of Hong Kong; Communication University of China; Nanyang Technological University; Shenzhen Research Institute of Big Data; Sun Yat-sen University
关于Agentic多模态大语言模型的综述
本文是对Agentic多模态大语言模型(Agentic Multimodal Large Language Models, Agentic MLLMs)领域的综合性回顾。随着AI从传统的静态、被动系统向动态、主动、可泛化的智能体(Agent)范式转变,Agentic MLLMs应运而生。本文旨在系统性地梳理这一新兴领域,为其奠定概念基础,并与传统的基于MLLM的智能体进行区分。
本文提出了一个组织Agentic MLLMs的概念框架,该框架围绕三个基本维度构建:
- 内部智能 (Internal Intelligence):模型作为系统的指挥官,通过推理、反思和记忆等能力实现精确的长期规划。
- 外部工具调用 (External Tool Invocation):模型主动使用各种外部工具,将其解决问题的能力扩展到固有知识之外。
- 环境交互 (Environment Interaction):将模型置于虚拟或物理环境中,使其能够在动态的真实世界场景中采取行动、调整策略并维持目标导向的行为。
本综述的组织结构如上图所示。后续章节将详细探讨Agentic MLLM与传统MLLM智能体的区别,阐述其基础概念、技术方法、训练与评估资源、下游应用,并展望未来的研究方向。
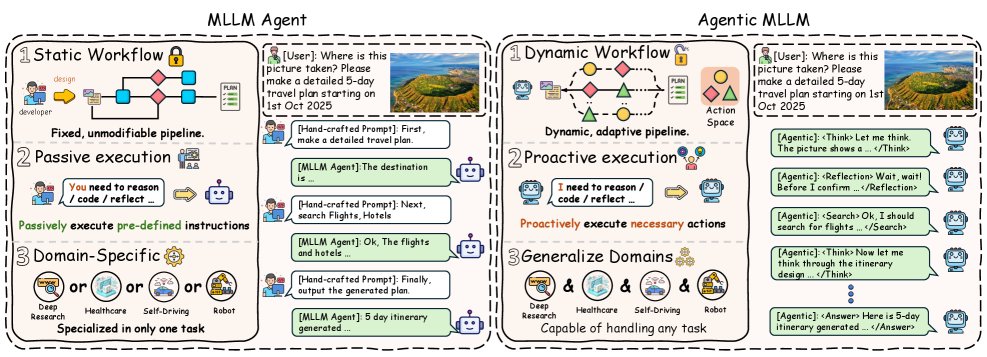
MLLM智能体 vs. Agentic MLLM
本节将正式阐述Agentic MLLM与传统MLLM智能体之间的关键区别,重点强调Agentic MLLM在动态工作流、主动行动执行和跨领域泛化方面的能力。
传统MLLM智能体
传统的MLLM智能体通常由开发者精心设计和实现的静态工作流所定义,遵循“分而治之”的原则。在这种模式下,一个复杂任务被分解成一系列子任务,形成类似流程图的结构。MLLM在每个阶段通过精心设计的提示(prompt)被赋予不同角色,并按顺序执行指令,其中间输出被传递给下一阶段,最终以模块化的方式产生完整解决方案。其过程可形式化为:
\[\text{Agent}_{\text{MLLM}}=f_{T}\circ f_{T-1}\circ\cdots\circ f_{1}(x_{1})\] \[f_{i}(x_{i})=\text{MLLM}(p_{i},x_{i}),~x_{i+1}=f_{i}(x_{i}).\]其中,$p_i$ 是阶段 $i$ 的人工提示,$f_i$ 是MLLM在该提示下的响应,$x_{i+1}$ 是从前一阶段传递过来的顺序多模态输入。
总的来说,传统MLLM智能体将MLLM定位为一个能够通过系统化分解来完成复杂目标的任务执行者。然而,其设计受限于一个静态和固定的工作流,导致其规划是静态的、行动是被动的,并且应用局限于特定领域,这阻碍了其适应性和泛化能力。
Agentic MLLM
相比之下,Agentic MLLM将任务解决视为一个自主决策过程。模型根据环境状态和上下文特征,在每一步独立选择行动。与传统MLLM智能体相比,Agentic MLLM主要有以下三个根本区别。
动态工作流
传统MLLM智能体依赖于开发者预先设计的、不可修改的静态流程。而Agentic MLLM能够根据不断变化的状态动态选择合适的策略,实现自适应的问题解决过程,摆脱了固定的执行模式。这种动态工作流及其状态转换可以表示为:
\[s_{t+1} = \delta(s_{t}, a_{t}),\]其中 $s_t$ 表示当前状态,$a_t$ 是MLLM选择的行动,$\delta$ 代表状态转换函数。
主动行动执行
传统MLLM智能体根据预设指令被动地执行动作。而Agentic MLLM采用主动模式,在每一步都基于当前状态自主选择行动。这种转变使模型从简单地“遵循指令”变为主动思考“下一步该采取什么行动”,从而显著提升了其上下文感知决策能力。该过程可表达为:
\[a_{t}\sim\pi(a\mid s_{t}),\]其中 $a_t$ 表示在当前状态 $s_t$ 下,根据策略 $\pi$ 选择的行动。
跨领域泛化
传统MLLM智能体要求开发者为每个特定任务设计定制化的流程和提示,使其高度领域相关,难以泛化到新场景。相反,Agentic MLLM能够通过自适应地规划和执行所需行动来适应不断变化的环境。这种灵活性使其能够在多样化的情境中运作,并有效解决跨领域的任务。这种泛化能力可以通过最大化期望累积奖励的策略优化目标来形式化:
\[\pi^{*} = \arg\max_{\pi} \mathbb{E}_{(x)\sim\mathcal{D}}\Big[\sum_{t=0}^{T}\gamma^{t} r(s_{t},a_{t};x)\Big],\]其中 $\mathcal{D}$ 代表任务和环境的分布,$s_t$ 和 $a_t$ 分别是 $t$ 时刻的状态和行动,$r(\cdot)$ 是驱动跨领域泛化的奖励函数,$\gamma$ 是控制短期与长期奖励相对重要性的折扣因子。
总而言之,Agentic MLLM将任务解决过程重构为一个面向行动的马尔可夫决策过程。它们被建模为与行动空间和环境互动的自适应策略,而非依赖于静态的手工流程。这种形式化凸显了它们自主规划、行动和跨任务、跨领域泛化的能力。
\[\text{Agentic}_{\text{MLLM}} = \pi^{*}(x,\mathcal{A},\mathcal{E}),\]其中 $x$ 是输入,$\mathcal{A}$ 是行动空间,$\mathcal{E}$ 是环境。$\pi^*$ 代表了在不同状态、行动和环境动态中进行自适应决策的最优策略。
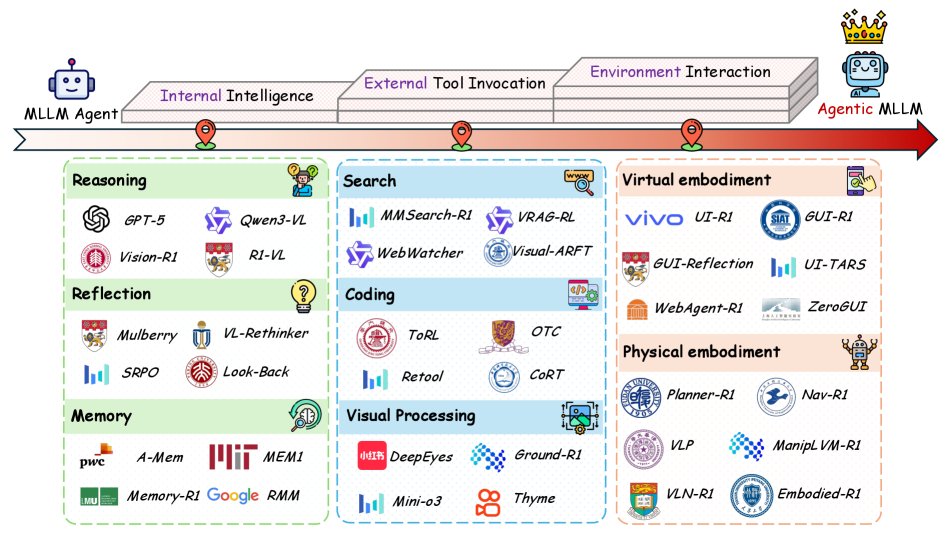
Agentic MLLM的基础概念
本节介绍Agentic MLLM的先验知识,涵盖:(1) 作为智能体系统基础的基础MLLM;(2) 定义行动如何被指定和执行的行动空间;(3) 旨在扩展通用智能体知识的持续预训练;(4) 为强化学习提供冷启动的监督微调;(5) 通过探索和反馈激励智能体行为的强化学习;(6) 从过程或结果层面评估模型的评估方法。
基础MLLM
早期的基础MLLM已经证明了联合处理和对齐图像与文本的能力,在视觉问答、光学字符识别(OCR)等多种视觉理解任务上表现出色。从架构上看,基础MLLM可分为密集模型 (Dense Models) 和 混合专家模型 (Mixture-of-Experts, MoE)。随着Agentic MLLM的发展,MoE架构因其能更好地支持自适应推理和动态工具调用而日益受到关注。
密集模型: 这是MLLM的经典架构,其中所有参数在每次输入时都会被激活。其前向计算过程为:
\[h^{(l+1)}=f\big(W^{(l)}h^{(l)}+b^{(l)}\big)\] \[f(h)=\sigma\big(W_{2}\,\sigma(W_{1}h+b_{1})+b_{2}\big)\]其中 $h^{(l)}$ 是第 $l$ 层的输入,$W^{(l)}$ 和 $b^{(l)}$ 是权重和偏置。这种设计简单直观,易于优化和部署。早期的LLaVA、Flamingo等开源模型奠定了基础,近期的Qwen2.5-VL、MiniCPM-V 4.5等工作进一步提升了密集模型的性能。
混合专家模型 (MoE): 为了在不增加过多计算成本的情况下扩展模型容量,许多基础MLLM采用MoE架构。该架构通过一个可训练的门控网络,为每个输入Token动态选择一小部分“专家”进行激活,从而实现稀疏计算。这使得模型能够扩展到数万亿参数,同时保持较低的计算开销。其前向计算可表示为:
\[h^{(l+1)}=\sum_{i=1}^{K}g_{i}(x)\,f_{i}(h^{(l)})\] \[f_{i}(h)=\sigma\big(W_{2,i}\,\sigma(W_{1,i}h+b_{1,i})+b_{2,i}\big)\] \[g_{i}(x)=\frac{\exp(w_{i}^{\top}x)}{\sum_{j=1}^{K}\exp(w_{j}^{\top}x)}\]其中 $f_i(\cdot)$ 是第 $i$ 个专家网络,$g_i(x)$ 是分配权重的门控函数。MoE架构使一个大模型如同多个专业模型的集合,能更好地支持不同层次的推理和多样的智能体行为。近期的Deepseek-VL2、GLM-4.5V、GPT-oss等模型均采用了MoE架构以增强其在复杂任务上的表现。
Agentic 行动空间
Agentic MLLM利用自然语言作为交互媒介,将行动空间(Action Space)的定义根植于语言形式,从而实现了对推理、反思、工具调用、环境交互等多种动作的灵活和可解释的指定与执行。目前主要有两种方法将不同行动嵌入到MLLM中:
- 特殊Token定义法:使用不同的特殊Token,如 \(<tool_name>\) 和 \(</tool_name>\),来界定特定操作。
- 统一格式调用法:采用一个通用的调用Token,内部使用类似JSON的结构来指定要调用的工具,例如 \(<tool_code>{"tool_name": "...", "tool_input": "..."}</tool_code>\)。
在每个状态下,Agentic MLLM会对可能的行动进行推理,并选择最优的一个以完成任务,从而实现了超越简单问答的自主决策和问题解决能力。
Agentic 持续预训练
Agentic 持续预训练 (Agentic Continual Pre-training, Agentic CPT) 使MLLM能够在不遗忘已有知识的前提下,持续整合来自不同领域的最新知识,并增强其规划和工具使用能力。此阶段的训练数据通常是大规模的合成语料库,优化目标是最大似然估计(Maximum Likelihood Estimation):
\[\mathcal{L}_{\mathrm{MLE}}(\theta)=-\sum_{t=1}^{T}\log p_{\theta}(x_{t}\mid x_{<t}),\]其中 $x_t$ 是时间步 $t$ 的目标Token,$x_{<t}$ 是前面的Token序列。
Agentic 监督微调
Agentic 监督微调 (Agentic Supervised Fine-tuning, Agentic SFT) 通常在强化学习之前进行,作为一个初始化阶段。它利用包含详细智能体轨迹的高质量数据集,为模型提供一个强大的策略先验。这些数据集通常通过逆向工程、基于图的合成等方法生成。SFT的目标是使模型与行动执行模式对齐,其优化目标同样是最大似然估计。
Agentic 强化学习
Agentic 强化学习 (Agentic Reinforcement Learning, Agentic RL) 是一种后训练范式,它利用探索和基于奖励的反馈来精炼智能体的能力。其核心目标是通过迭代优化决策策略来最大化期望累积奖励。两种经典的RL算法被广泛应用:PPO 和 GRPO。
PPO (Proximal Policy Optimization): PPO是一种演员-评论家(actor-critic)算法,它通过一个裁剪的目标函数来稳定策略更新,在促进探索的同时避免与先前策略偏离过大。其目标函数定义为:
\[\mathcal{J}_{PPO}(\theta)=\mathbb{E}_{(I,T)\sim p_{\mathcal{D}},\,o\sim\pi_{\theta_{\text{old}}}}\frac{1}{ \mid o \mid }\sum_{t=1}^{ \mid o \mid }\min\Bigg(\frac{\pi_{\theta}(o_{t}\mid I,T)}{\pi_{\theta_{\text{old}}}(o_{t}\mid I,T)}A_{t},\;\mathrm{clip}\Bigg(\frac{\pi_{\theta}(o_{t}\mid I,T)}{\pi_{\theta_{\text{old}}}(o_{t}\mid I,T)},\,1-\epsilon,\,1+\epsilon\Bigg)A_{t}\Bigg).\]其中 $\epsilon$ 是裁剪参数,$A_t$ 是优势估计。通常还会加入KL散度惩罚项以保持语言连贯性。
GRPO (Group-wise Reward Policy Optimization): GRPO是PPO的一个简化变体,它无需训练一个单独的价值函数模型,而是直接从一组响应(rollouts)中估计基线,降低了训练成本。对于每个问题,GRPO从旧策略中采样一组响应,计算它们的奖励,然后将奖励归一化得到相对优势 $\hat{A}_i$。其训练目标为:
\[\mathcal{J}_{\mathrm{GRPO}}(\theta)=\mathbb{E}_{(I,T)\sim p_{\mathcal{D}},\,o\sim\pi_{\theta_{\text{old}}}(\cdot \mid I,T)}\Biggl[\frac{1}{n}\sum_{i=1}^{n}\min\!\Biggl(\frac{\pi_{\theta}(o_{i}\mid I,T)}{\pi_{\theta_{\mathrm{old}}}(o_{i}\mid I,T)}\hat{A}_{i},\;\mathrm{clip}\!\Bigl(\frac{\pi_{\theta}(o_{i}\mid I,T)}{\pi_{\theta_{\mathrm{old}}}(o_{i}\mid I,T)},\,1-\epsilon,\,1+\epsilon\Bigr)\hat{A}_{i}\Biggr)-\beta D_{\mathrm{KL}}\!\left(\pi_{\theta}\,\ \mid \,\pi_{\mathrm{ref}}\right)\Biggr],\]其中 $\hat{A}_i$ 是归一化优势,$\pi_{\mathrm{ref}}$ 是用于KL正则化的参考策略。
Agentic 评估
Agentic MLLM在解决复杂问题时会生成长期的行动轨迹,因此评估可以分为两个互补的维度:过程评估和结果评估。
过程评估 (Process Evaluation): 此维度关注智能体是否能生成准确的中间过程,例如精确的推理步骤或恰当的工具调用。它评估推理路径的逻辑一致性和工具使用的合理性,反映了中间过程的透明度、可靠性和鲁棒性。
结果评估 (Outcome Evaluation): 此维度衡量智能体在各种下游任务中产生准确、有用解决方案的能力。它反映了智能体系统的泛化能力和解决问题的能力。
这两个维度共同为评估Agentic MLLM提供了一个全面的框架,既捕捉了其内部过程的质量,也评估了其最终产出的有效性。
Agentic MLLM 分类体系
本节将Agentic MLLM的核心能力分为三个组成部分:内部智能、外部工具调用和环境交互。
- 内部智能是Agentic MLLM的认知核心,包括长链推理、反思和记忆。它使模型能够构建连贯的推理链和战略计划,协调后续行动。
- 在内部智能的协调下,Agentic MLLM可以主动调用各种外部工具,如搜索信息、执行代码来增强推理。
- 通过深思熟虑的规划和工具使用,Agentic MLLM与虚拟或物理环境进行交互,感知外部世界并接收反馈,从而在现实世界中实现动态适应。
Agentic 内部智能
Agentic 内部智能 (Agentic internal intelligence) 指模型为实现目标而深思熟虑地组织和协调行动的能力,是有效执行任务的基石。对于MLLM而言,实现这种智能依赖于三种互补能力的整合:推理(reasoning)、反思(reflection) 和 记忆(memory)。这些能力共同使模型能够连贯地构建、验证和完善其决策过程。下文将回顾在MLLM中提升这三种内部智能维度的最新方法。(原文此处引用了表I,但未提供表格内容)
Agentic 推理
Agentic 推理 (Agentic reasoning) 指在生成最终答案之前,有意识地生成中间推理步骤的过程,这显著增强了模型解决复杂问题的能力。目前增强推理能力的方法主要可分为三大类:基于提示的方法 (Prompt-based approaches)、监督微调 (Supervised Fine-tuning) 和 强化学习 (Reinforcement Learning)。
基于提示的方法通过在提示中加入“让我们一步步解决问题”之类的指令,引导MLLM生成明确的中间推理步骤。这种策略鼓励模型在得出最终答案前阐明多步推理轨迹,即思维链(Chain-of-Thought, CoT)。
在此基础上,后续工作从深度和广度上扩展了CoT推理:
- Best-of-N (BoN) 方法:独立生成多个推理路径,然后使用奖励模型或启发式评分函数选出最佳路径。例如,VisualPRM和MM-PRM训练专门的奖励模型来评估和选择推理轨迹。
- 树搜索 (Tree search) 方法:将推理路径扩展为树状结构,允许进行超越线性链的结构化探索。例如,VisuoThink通过渐进的视觉-文本推理实现多模态慢思考,并结合前瞻性树搜索。
- 蒙特卡洛树搜索 (Monte Carlo Tree Search, MCTS):通过随机 rollout 和统计评估,在探索和利用之间取得平衡,逐步扩展有希望的分支。例如,AStar利用MCTS衍生的“思想卡片”来提升推理能力。