A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly
-
ArXiv URL: http://arxiv.org/abs/2312.02003v3
-
作者: Yue Zhang; Eric Sun; Yifan Yao; Yuanfang Cai; Kaidi Xu; Jinhao Duan
-
发布机构: Drexel University
大型语言模型(LLM)安全与隐私综述:善、恶与丑
引言
大型语言模型 (Large Language Model, LLM) 是一种拥有海量参数的语言模型,通过预训练任务(如掩码语言建模和自回归预测)来理解和处理人类语言。一个强大的LLM应具备四个关键特征:对自然语言上下文的深刻理解、生成类人文本的能力、上下文感知能力(尤其是在知识密集型领域)以及强大的指令遵循能力。
LLM在安全社区也获得了广泛关注。例如,GPT-3在一个代码库中发现了213个安全漏洞。这些初步尝试促使本文探讨关于LLM安全与隐私的三个核心研究问题:
- RQ1 (善): LLM如何在不同领域对安全和隐私产生积极影响?
- RQ2 (恶): 在网络安全领域使用LLM会带来哪些潜在风险和威胁?
- RQ3 (丑): LLM自身存在哪些漏洞和弱点,以及如何防御这些威胁?
为回答这些问题,本文回顾了281篇相关论文,并将其分为三类:“善”(有益的应用)、“恶”(攻击性应用)和“丑”(LLM的漏洞及防御)。
本文发现:
- 善 (§4): LLM对安全社区的积极影响最大,尤其在代码安全和数据安全与隐私方面。在代码的全生命周期(安全编码、测试、检测、修复)中,LLM的应用通常优于传统方法。
- 恶 (§5): LLM也可被用于攻击,尤其是在用户层面,如制造虚假信息和进行社会工程。这是由于其类人推理能力。
- 丑 (§6): LLM的漏洞分为AI模型固有漏洞(如数据投毒)和非AI模型固有漏洞(如提示注入)。防御策略可在模型架构、训练和推理阶段实施。模型提取、参数提取等攻击的研究仍很有限,而安全指令微调等新兴防御技术则需要更多探索。
本文贡献: 本文首次全面总结了LLM在安全与隐私中的角色,涵盖了其积极影响、潜在风险、自身漏洞及防御机制。本文发现LLM对安全领域的贡献多于其负面影响,并指出用户级攻击是当前最主要的威胁。
背景
大型语言模型 (LLM)
LLM是语言模型的演进,其规模在Transformer架构出现后显著增加。这些模型在巨大的数据集上进行训练,以理解和生成高度模仿人类语言的文本。一个合格的LLM应具备四个关键特征:
- 深刻理解自然语言:能从中提取信息并执行翻译等任务。
- 生成类人文本:能完成句子、撰写段落甚至文章。
- 上下文感知:具备领域专业知识,即“知识密集型”特性。
- 强大的解决问题能力:能利用文本信息进行信息检索和问答。
流行LLM的比较
下表展示了不同供应商提供的多种语言模型,显示了该领域的快速发展。较新的模型如GPT-4不断涌现。虽然多数模型不开源,但BERT、LLaMA等模型的开源促进了社区发展。通常,模型参数越多,能力越强,计算需求也越高。“可调优性” (Tunability) 指的是模型是否可以针对特定任务进行微调。
| 模型 | 日期 | 提供商 | 开源 | 参数 | 可调优 |
|---|---|---|---|---|---|
| gpt-4 | 2023.03 | OpenAI | ✗ | 1.7T | ✗ |
| gpt-3.5-turbo | 2021.09 | OpenAI | ✗ | 175B | ✗ |
| gpt-3 | 2020.06 | OpenAI | ✗ | 175B | ✗ |
| cohere-medium | 2022.07 | Cohere | ✗ | 6B | ✓ |
| cohere-large | 2022.07 | Cohere | ✗ | 13B | ✓ |
| cohere-xlarge | 2022.06 | Cohere | ✗ | 52B | ✓ |
| BERT | 2018.08 | ✓ | 340M | ✓ | |
| T5 | 2019 | ✓ | 11B | ✓ | |
| PaLM | 2022.04 | ✓ | 540B | ✓ | |
| LLaMA | 2023.02 | Meta AI | ✓ | 65B | ✓ |
| CTRL | 2019 | Salesforce | ✓ | 1.6B | ✓ |
| Dolly 2.0 | 2023.04 | Databricks | ✓ | 12B | ✓ |
概览
范围
本文旨在对LLM背景下的安全和隐私研究进行全面的文献综述,确定当前的技术水平并找出知识缺口。本文的焦点严格限定在安全与隐私问题上。
研究问题
本文围绕以下三个核心研究问题展开:
- 善 (§4): LLM如何对安全和隐私做出积极贡献?
- 恶 (§5): LLM如何被用于恶意目的,可能助长哪些网络攻击?
- 丑 (§6): LLM自身存在哪些漏洞,它们如何威胁安全与隐私?
本文收集了281篇相关论文,其中“善”类83篇,“恶”类54篇,“丑”类144篇。如下图所示,大多数论文发表于2023年,显示出该领域研究热度的迅速上升。
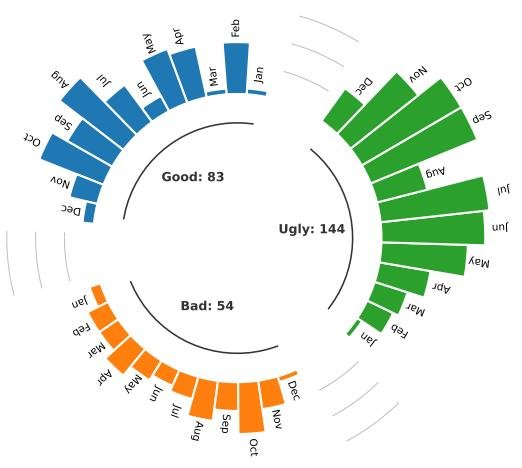
发现 I: 在安全相关应用中,大多数研究者倾向于利用LLM来增强安全性(如漏洞检测),而不是将其用作攻击工具。总体而言,LLM对安全社区的贡献是积极大于消极的。
积极影响(善)
本节探讨LLM在代码安全和数据安全与隐私方面的有益应用。
LLM在代码安全中的应用
LLM能够利用其强大的语言理解和上下文分析能力,在代码安全的整个生命周期中发挥关键作用,包括安全编码、测试用例生成、漏洞/恶意代码检测以及代码修复。
| 生命周期 | 工作 | 编码(C) | 测试用例生成(TCG) | 漏洞检测 | 恶意代码检测 | 修复 | LLM | 领域 | 相比SOTA的优势 |
|---|---|---|---|---|---|---|---|---|---|
| RE | Sandoval等 [234] | ○ | Codex | - | 风险可忽略 | ||||
| RE | SVEN [98] | ○ | CodeGen | - | 更快/更安全 | ||||
| RE | SALLM [254] | ○ | ChatGPT等 | - | – | ||||
| RE | Madhav等 [197] | ○ | ChatGPT | 硬件 | – | ||||
| RE | Zhang等 [343] | + | ChatGPT | 供应链 | 更有效的案例 | ||||
| RE | Libro [136] | + | LLaMA | - | ↑ 覆盖率 | ||||
| RE | TitanFuzz [56] | + | Codex | DL库 | ↑ 覆盖率 | ||||
| RE | FuzzGPT [57] | + | ChatGPT | DL库 | ↑ 覆盖率 | ||||
| RE | Fuzz4All [313] | + | ChatGPT | 语言 | 高质量测试 | ||||
| RE | WhiteFox [321] | + | GPT4 | 编译器 | 更快4倍 | ||||
| RE | Zhang等 [337] | + | ChatGPT | API | ↑ 覆盖率,但FP/FN高 | ||||
| RE | CHATAFL [190] | + | ChatGPT | 协议 | 低FP/FN,但FP/FN高 | ||||
| RE | Henrik [105] | + | N/A | - | 不优于SOTA | ||||
| RE | Apiiro [74] | + | ChatGPT | - | 成本效益高 | ||||
| RE | Noever [201] | + | ChatGPT | - | – | ||||
| RE | Bakhshandeh等 [15] | + | ChatGPT | - | – | ||||
| RE | Moumita等 [218] | + | ChatGPT | - | – | ||||
| RE | Cheshkov等 [41] | + | GPT | - | 减少人工 | ||||
| RE | LATTE [174] | + | Codex | - | ↑ 准确率/速度 | ||||
| RE | DefectHunter [296] | + | ChatGPT | 区块链 | 修复更多漏洞 | ||||
| RE | Chen等 [37] | + | ChatGPT | 区块链 | CI流水线 | ||||
| RE | Hu等 [110] | + | LLaMa | Web应用 | – | ||||
| RE | KARTAL [233] | + | Codex | 库 | – | ||||
| RE | VulLibGen [38] | + | Codex | 硬件 | Zero-shot | ||||
| RE | Ahmad等 [3] | + | Codex等 | APR | ↑ 准确率 | ||||
| RE | InferFix [125] | + | ChatGPT | APR | ↑ 准确率 | ||||
| RE | Pearce等 [211] | + | + | ChatGPT等 | APR | ↑ 准确率 | |||
| RE | Fu等 [83] | + | ChatGPT | APR | – | ||||
| RE | Sobania等 [257] | + | + | ||||||
| RE | Jiang等 [123] | + |
- 安全编码 (Secure Coding): 研究表明,在LLM(如OpenAI Codex)辅助下,开发者编写的代码并未引入更多安全风险。SVEN等方法通过连续提示引导LLM生成更安全的代码,成功率显著提高。
- 测试用例生成 (Test Case Generating): LLM被用于生成安全测试用例,在供应链攻击、深度学习库模糊测试 (fuzzing) 和协议模糊测试等场景中,其生成的测试用例覆盖率和效率均超过现有工具。例如,Fuzz4All在多种语言上的覆盖率平均提高了36.8%。
- 漏洞代码检测 (Vulnerable Code Detecting): GPT-4等LLM在检测软件漏洞方面表现出色,其发现的漏洞数量远超传统静态分析工具。然而,也有研究指出LLM在某些场景下会产生较高的误报率。在智能合约、Web应用等特定领域,LLM也展现了强大的漏洞检测能力。
- 恶意代码检测 (Malicious Code Detecting): 利用LLM的自然语言处理能力来检测恶意软件是一个新兴方向。Apiiro等工具通过将代码表示为向量来识别恶意软件包。
- 漏洞/错误代码修复 (Vulnerable/Buggy Code Fixing): LLM在程序修复任务中表现出强大的能力。即便是未经专门漏洞修复训练的LLM,也能修复不安全的代码。ChatGPT在修复错误方面与标准程序修复方法相当,ChatRepair等框架进一步提升了其代码修复能力。
发现 II: 大多数研究(25篇中的17篇)认为,基于LLM的方法在代码安全方面优于传统方法,具有代码覆盖率更高、检测准确率更高、成本更低等优点。LLM方法最常被诟病的问题是在检测漏洞时倾向于产生较高的假阴性 (false negatives) 和假阳性 (false positives)。
LLM在数据安全与隐私中的应用
LLM在数据安全领域也做出了贡献,主要体现在数据完整性、机密性、可靠性和可追溯性等方面。
| 工作 | 特性 | 模型 | 领域 | 相比SOTA的优势 |
|---|---|---|---|---|
| … | I C R T | |||
| Fang [294] | ○+○+ | ChatGPT | 勒索软件 | - |
| Liu等 [187] | ○+○+ | ChatGPT | 勒索软件 | - |
| Amine等 [73] | ○○○+ | ChatGPT | 语义 | 与SOTA相当 |
| HuntGPT [8] | ○○○+ | ChatGPT | 网络 | 更有效 |
| Chris等 [71] | ○○○+ | ChatGPT | 日志 | 减少人工 |
| AnomalyGPT [91] | ○○○+ | ChatGPT | 视频 | 减少人工 |
| LogGPT [221] | ○○○+ | ChatGPT | 日志 | 减少人工 |
| Arpita等 [286] | +○++ | BERT等 | - | - |
| Takashi等 [142] | ++○+ | ChatGPT | 钓鱼 | 高精度 |
| Fredrik等 [102] | ++○+ | ChatGPT等 | 钓鱼 | 有效 |
| IPSDM [119] | ++○+ | BERT | 钓鱼 | - |
| Kwon等 [149] | +○++ | ChatGPT | - | 对非专家友好 |
| Scanlon等 [237] | +++○ | ChatGPT | 取证 | 更有效 |
| Sladić等 [255] | +++○ | ChatGPT | 蜜罐 | 更真实 |
| WASA [297] | ++○○ | - | 水印 | 更有效 |
| REMARK [340] | ++○○ | - | 水印 | 更有效 |
| SWEET [154] | ++○○ | - | 水印 | 更有效 |
- 数据完整性 (Data Integrity, I): 保证数据在生命周期内不被篡改。LLM被用于理论上提出针对勒索软件的防御策略,如实时分析和自动策略生成。在异常检测方面,LLM可以识别可能破坏数据完整性的可疑行为,且无需过多人工干预。
- 数据机密性 (Data Confidentiality, C): 防止敏感信息被未经授权的访问。LLM可用于数据脱敏,通过用通用标记替换个人身份信息(PII)来保护用户隐私。此外,ChatGPT也被用于帮助非专家实现加密算法,从而保护数据机密性。
- 数据可靠性 (Data Reliability, R): 保证数据的准确性。LLM在检测钓鱼网站和钓鱼邮件方面表现出高精度和召回率,其效果甚至超过人类。
- 数据可追溯性 (Data Traceability, T): 追踪数据的来源和历史。在数字取证中,LLM可用于分析日志、内存转储等操作系统产物。在知识产权保护方面,数字水印 (Watermarking) 技术被用于在LLM的输出中嵌入难以察觉的信号,以追踪内容使用情况,防止抄袭和滥用。
发现 III: LLM在数据保护方面表现出色,通常优于现有解决方案且需要更少的人工干预。在各类安全应用中,ChatGPT是使用最广泛的LLM模型。
消极影响(恶)
本节探讨LLM的攻击性应用,根据其在系统架构中的位置,将其分为五类。
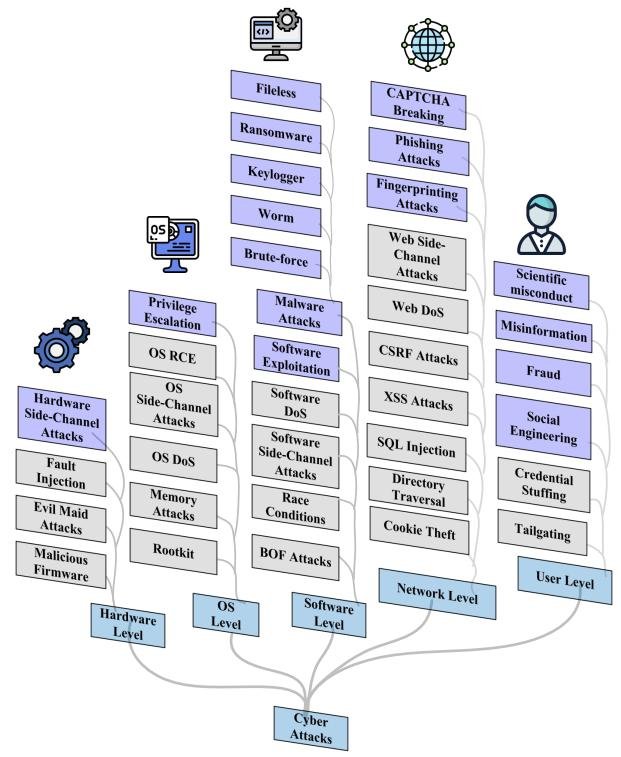
分类体系总结
本文将基于LLM的网络攻击分为五个层级:
- 硬件层攻击 (Hardware-Level Attacks): LLM虽不能直接物理访问硬件,但可分析硬件相关的侧信道 (side-channel) 信息泄露,以推断密钥等秘密信息。
- 操作系统层攻击 (OS-Level Attacks): LLM缺乏执行OS级攻击所需的低级系统访问权限。但它们可用于分析从OS收集的信息,从而辅助攻击。已有研究展示了LLM如何分析虚拟机状态、识别漏洞并自动执行攻击。
- 软件层攻击 (Software-Level Attacks): 最普遍的软件层攻击是利用LLM创建恶意软件 (malware)。研究表明,LLM擅长根据功能描述构建恶意软件模块,并能生成多种逃避杀毒软件检测的恶意软件变体。
- 网络层攻击 (Network-Level Attacks): LLM被广泛用于发起网络钓鱼 (phishing) 攻击,通过生成高度个性化和令人信服的钓鱼邮件来提高点击率。此外,LLM还可能破解用于区分人机的CAPTCHA验证码。
- 用户层攻击 (User-Level Attacks): 这是最普遍的攻击类型。LLM能够生成极其令人信服但虚假的内容,并关联看似无关的信息,从而被用于多种恶意活动。
- 虚假信息 (Misinformation): LLM生成的虚假内容更难被检测,且可能使用更具欺骗性的风格。
- 社会工程 (Social Engineering): LLM可以从看似无害的文本中推断出用户的个人属性(如位置、收入),甚至直接提取个人信息。
- 学术不端 (Scientific Misconduct): LLM能够生成连贯的原创文本,甚至完整的学术论文,这给检测学术不端行为带来了巨大挑战。
- 欺诈 (Fraud): 出现了专为网络犯罪设计的工具,如FraudGPT和WormGPT,它们缺乏安全护栏,可用于生成欺诈邮件、策划攻击。
发现 IV: 用户层攻击是最普遍的,这主要归因于LLM日益增强的类人推理能力,使其能生成逼真的对话和内容。目前,LLM对操作系统和硬件功能的访问权限有限,这限制了其他层级攻击的普遍性。
LLM的漏洞与防御(丑)
本节探讨LLM自身的漏洞、面临的威胁以及相应的防御对策。
LLM的漏洞与威胁
本文将针对LLM的威胁分为两类:AI模型固有漏洞和非AI模型固有漏洞。
- AI模型固有漏洞 (AI Model Inherent Vulnerabilities): 这类漏洞源于机器学习模型本身的特性。