A Survey on LLM-as-a-Judge
-
ArXiv URL: http://arxiv.org/abs/2411.15594v5
-
作者: Hexiang Tan; Xuhui Jiang; Chengjin Xu; Jian Guo; Wei Li; Honghao Liu; Jiawei Gu; Yinghan Shen; Zhichao Shi; Shengjie Ma; 等2人
-
发布机构: Chinese Academy of Sciences; Imperial College London; International Digital Economy Academy; Peking University; Renmin University of China; The Hong Kong University of Science and Technology
引言
在众多领域,准确和一致的评估对决策至关重要,但由于固有的主观性、可变性和规模问题,这仍然是一项艰巨的任务。传统评估方法面临一个两难困境:以专家驱动为代表的主观方法虽然全面,但成本高、难扩展且一致性差;而以自动度量(如BLEU、ROUGE)为代表的客观方法虽然可扩展性与一致性强,但往往只关注表面词汇重叠,无法捕捉深层语义,在故事生成等任务上表现不佳。
近年来,大语言模型 (Large Language Models, LLMs) 在各个领域取得了巨大成功,催生了 “LLM-as-a-Judge”(将LLM用作评判者)这一新兴概念。LLM能够处理多样的评估任务,结合了自动方法的可扩展性与专家判断的细致、情境敏感推理,为解决上述评估困境提供了极具前景的方案。LLM作为评判者,能够以更低的成本和更高的效率,承担传统上由人类专家担任的角色。
然而,LLM-as-a-Judge的广泛应用仍面临两大挑战:一是缺乏系统性的综述,导致定义模糊、理解零散、实践不一;二是其可靠性问题,简单使用LLM并不能保证评估结果与既定标准对齐。这些挑战凸显了深入研究如何构建可靠的LLM-as-a-Judge系统的必要性。
为应对这些挑战,本文对LLM-as-a-Judge领域进行了系统性综述。本文首先通过非正式和正式的定义,回答了“什么是LLM-as-a-Judge”这一基本问题。接着,对现有方法进行分类,探讨“如何使用LLM-as-a-Judge”。为了解决核心问题“如何构建可靠的LLM-as-a-Judge系统”,本文深入探讨了两个方面:(1)提升LLM-as-a-Judge系统可靠性的策略;(2)评估这些系统可靠性的方法论。此外,本文还探讨了实际应用场景、挑战和未来的研究方向,旨在为该领域的科研人员和实践者提供一份基础性的参考。
 图1: 本文的整体框架
图1: 本文的整体框架
背景与方法
LLM模拟人类推理并根据预定义规则评估特定输入的能力,为“LLM-as-a-Judge”铺平了道路。LLM作为评判者的核心在于利用其评估对象、行为或决策。它涵盖了多种角色,如评分员 (Graders)、评估员 (Evaluators/Assessors)、批评家 (Critics)、验证者 (Verifiers)、考官 (Examiners) 以及奖励/排序模型 (Reward/Ranking Models) 等。
当前,关于如何有效使用LLM-as-a-Judge的定义大多是非正式或模糊的。因此,本文首先提供一个正式定义:
\[\mathcal{E}\leftarrow\mathcal{P}_{\mathcal{LLM}}\left(x\oplus\mathcal{C}\right)\]- $\mathcal{E}$: 整个LLM-as-a-Judge流程最终获得的期望评估结果,可以是分数、选项、标签或句子等。
- $\mathcal{P}_{\mathcal{LLM}}$: 对应LLM定义的概率函数,其生成过程是一个自回归过程。
- $x$: 待评估的输入数据,可以是文本、图像、视频等任何可用类型。
- $\mathcal{C}$: 输入$x$的上下文,通常是提示模板或对话中的历史信息。
- $\oplus$: 组合算子,将输入$x$与上下文$\mathcal{C}$结合,具体操作(如放置在开头、中间或结尾)根据上下文而变化。
该公式反映了LLM作为一种自回归生成模型的本质,它基于上下文生成后续内容,并从中提取目标评估结果。基于此公式,实现LLM-as-a-Judge的基本方法可被分为四大类:上下文学习 (In-Context Learning)、模型选择 (Model Selection)、后处理方法 (Post-processing Method) 和 评估流水线 (Evaluation Pipeline)。
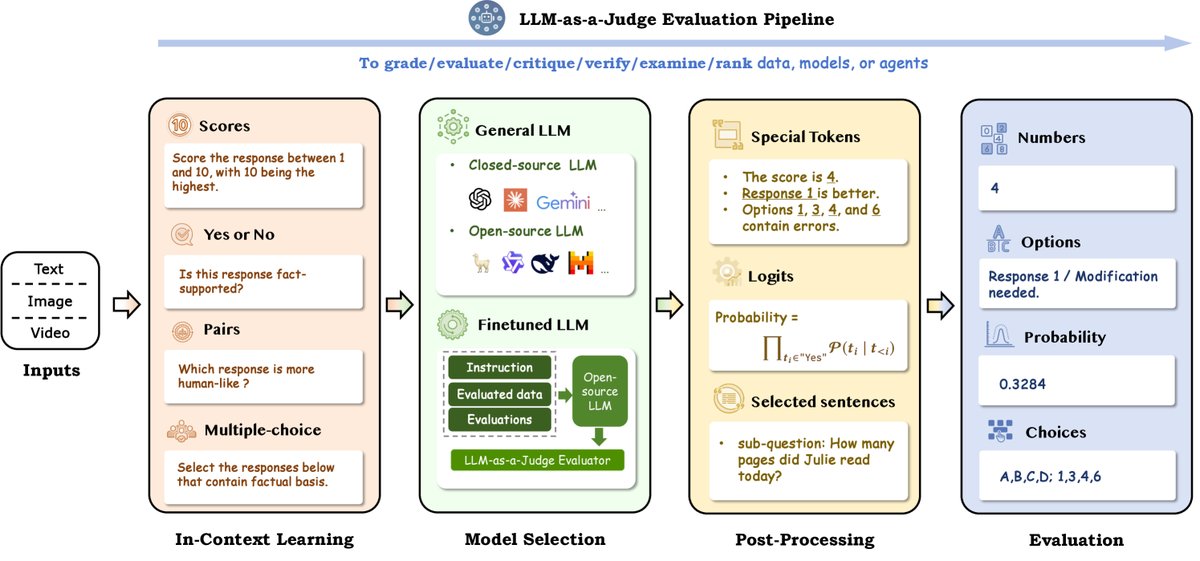 图2: LLM-as-a-Judge 评估流水线
图2: LLM-as-a-Judge 评估流水线
上下文学习
上下文学习 (In-Context Learning, ICL) 通过提供指令和示例来指导模型的推理和判断,是应用LLM-as-a-Judge的核心环节。该过程涉及输入设计和提示设计。输入设计需考虑评估变量的类型、输入方式和位置。提示设计主要有四种方法:
生成分数
使用分数来表示评估结果是一种直观的方式。分数可以是离散的,如1-5分或1-10分;也可以是连续的,如0-1或0-100。最简单的方式是在上下文中设定分数范围和评分标准。更复杂的场景则可能提供详细的评分维度,例如使用李克特量表 (Likert scale) 对准确性、连贯性、事实性和全面性等多个维度进行评分,并给出一个综合总分。
``\(评估为新闻文章所写摘要的质量。在以下四个维度上对每个摘要进行评分:{维度_1}, {维度_2}, {维度_3}, 和 {维度_4}。你应该在1(最差)到5(最好)的范围内评分。 文章:{文章} 摘要:{摘要}\)`$$ 图4: 来自Gao等人(2023b)的李克特量表评分模板
回答是否问题
“是/否”问题要求对一个给定陈述的准确性做出判断,回答是简单直接的二元选择(是/否,真/假)。这种评估常用于中间过程,为反馈循环创造条件。例如,在\(Reflexion\)等方法中,通过自我反思生成反馈;在自改进场景中,用于判断是否需要修改。此外,它也常用于测试知识的准确性。
\(`\) 该句子是否得到了文章的支持?回答“是”或“否”。 文章:{文章} 句子:{句子} \(`\) 图5: 是/否评估的示例模板
进行成对比较
成对比较 (Pairwise comparison) 是指在两个选项中选择更优或更符合特定标准的一个。这是一种相对评估,比评分模式更符合人类的判断习惯。研究表明,在成对比较中,LLM与人类评估的一致性更高。这种方法可以扩展到更复杂的列表式比较 (list-wise comparisons)。常见的模式包括:
- 双选项模式:在两个选项中选出更好的一个。
- 三选项模式:引入“平局”选项,用于两者质量相当的情况。
- 四选项模式:进一步区分“都好”的平局和“都差”的平局。
\(`\) 给定一篇新闻文章,哪个摘要更好?回答“摘要0”或“摘要1”。你不需要解释原因。 文章:{文章} 摘要0:{摘要_0} 摘要1:{摘要_1} \(`\) 图6: 来自Gao等人(2023b)的成对比较模板
进行多项选择
多项选择 (Multiple-choice selections) 提供多个选项,评估者必须选择最合适或最正确的一个。与“是/否”问题相比,它提供了更广泛的响应范围,可以评估更深层次的理解或偏好。不过,这种提示设计相对前三种较为少见。
\(`\) 给你一个摘要和一些语义内容单元。对于每个语义单元,选择那些可以从摘要中推断出来的,并返回它们的编号。 摘要:{摘要} 语义内容单元:
- {SCU_1}
- {SCU_2} …… n. {SCU_n} \(`\) 图7: 多项选择的示例模板
模型选择
通用大语言模型
一种有效的方法是直接使用先进的通用LLM(如GPT-4)作为评判者。研究表明,基于GPT-4的评估器与专业人类评估员相比,展现出高准确性、一致性和稳定性。然而,如果所选模型在指令遵循或推理能力上有缺陷,LLM-as-a-Judge的效果会大打折扣。
微调大语言模型
由于使用外部API存在隐私泄露风险和可复现性问题,后续研究开始探索通过微调来构建专为评估任务设计的语言模型。例如,PandaLM、JudgeLM、Auto-J和Prometheus等工作通过在特定数据集上微调开源模型(如LLaMA、Vicuna),使其具备评估能力。
微调评判模型的典型流程包括三个步骤:
- 数据收集:训练数据通常包含指令、待评估对象和评估结果(来自GPT-4或人类标注)。
- 提示设计:根据评估方案设计提示模板。
- 模型微调:遵循指令微调范式,训练模型根据指令和输入生成评估结果及解释。
尽管这些微调模型在特定测试集上表现优异,但其泛化能力往往较差,难以与GPT-4等强模型匹敌。
后处理方法
后处理旨在从LLM生成的概率分布中提炼出准确的评估结果。方法的选择应与上下文学习阶段的设计保持一致。主要有以下几种方法:
提取特定Token
当评估结果为分数、选项或“是/否”时,最常用的方法是使用规则匹配从模型生成的文本中提取相应的Token。然而,模型输出的格式可能不统一(如“Response 1 is better” vs “The better one is response 1”),这给规则提取带来了挑战。解决方案包括在提示中明确指定输出格式或使用少样本示例。
约束解码
约束解码 (Constrained decoding) 是一种强制LLM输出特定结构(如JSON)的技术。它通过一个有限状态机 (Finite State Machine, FSM) 来限制每一步生成的Token,确保输出的语法正确性。虽然能保证格式,但可能扭曲模型的原始概率分布,降低输出质量,并带来额外的计算开销。近期的工作如DOMINO、XGrammar和SGLang正在尝试解决这些问题。
归一化输出Logits
在涉及“是/否”判断的中间步骤中,一种常见方法是归一化输出的Logits,以获得一个0到1之间的连续分数。例如,通过计算模型生成“Yes”这个词的概率来量化其对某个推理步骤的置信度。自洽性分数 \($\rho\_{\text{Self-consistency}}\)$ 和自反思分数 \($\rho\_{\text{Self-reflection}}\)$ 就是通过这种方式计算的。最终分数由两者相乘得到:\($\rho\_{j}=\rho\_{\text{SC},j}\cdot\rho\_{\text{SR},j}}\)$。
选择句子
除了提取单个Token,后处理也可能涉及选择整个句子或段落。例如,在基于树状搜索的推理智能体中,LLM-as-a-Judge负责评估并选择最有前途的推理步骤(以句子形式存在)。
评估流水线
从输入到输出,上述步骤共同构成了LLM-as-a-Judge的评估流水线,通常应用于以下四种场景:
 图8: 使用LLM-as-a-Judge评估流水线的四种典型场景
图8: 使用LLM-as-a-Judge评估流水线的四种典型场景
LLM-as-a-Judge用于模型评估
使用强大的LLM(如GPT-4)作为人类评估的代理,来自动化评估其他LLM的性能,已成为一种普遍做法。通过精心设计的提示,其评估质量和与人类判断的一致性都很有前景。然而,API调用的成本和闭源模型的不可复现性仍然是挑战。为此,研究者们开始尝试微调开源模型(如SelFee, PandaLM)作为更经济的替代方案。
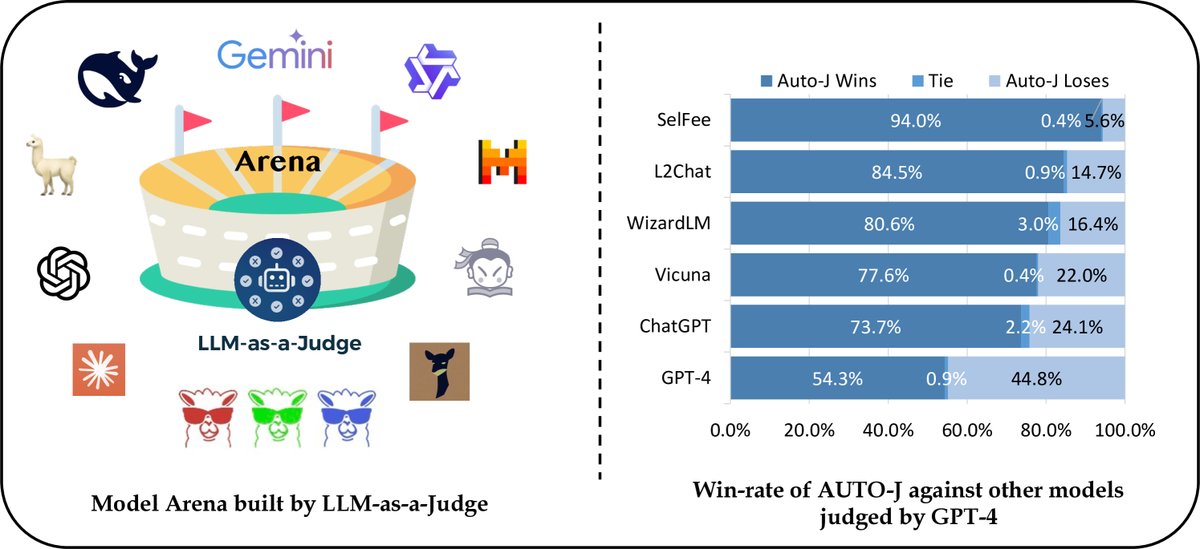 图9: LLM-as-a-Judge用于模型评估的场景说明。“胜-平-负”的例子来自Li等人(2023b)
图9: LLM-as-a-Judge用于模型评估的场景说明。“胜-平-负”的例子来自Li等人(2023b)
LLM-as-a-Judge用于数据评估
LLM-as-a-Judge为自动化数据标注提供了前所未有的机会,尤其是在需要大规模、高质量标注数据的场景。例如,在RLHF中,LLM可被用作奖励模型,评估不同模型输出是否符合人类偏好,从而筛选出高质量数据。在领域特定的数据生成任务中(如WizardMath),LLM也可以评估生成指令的质量。为了解决标注数据价值随模型性能提升而衰减的问题,\(Self-Taught Evaluator\)等方法通过迭代式的自我学习和修正,实现了评估器的持续自我进化。
LLM-as-a-Judge用于智能体
LLM-as-a-Judge在智能体 (Agent) 中的应用主要有两种形式:
- 评估整个智能体系统:构建一个“智能体评判者”,像人一样对另一个智能体的整体表现进行评估,减少人力投入。
- 在智能体流程中作为评估模块:在智能体的决策循环中,LLM-as-a-Judge可以评估每个动作或中间步骤的质量,为下一步决策提供反馈,例如\(Reflexion\)。
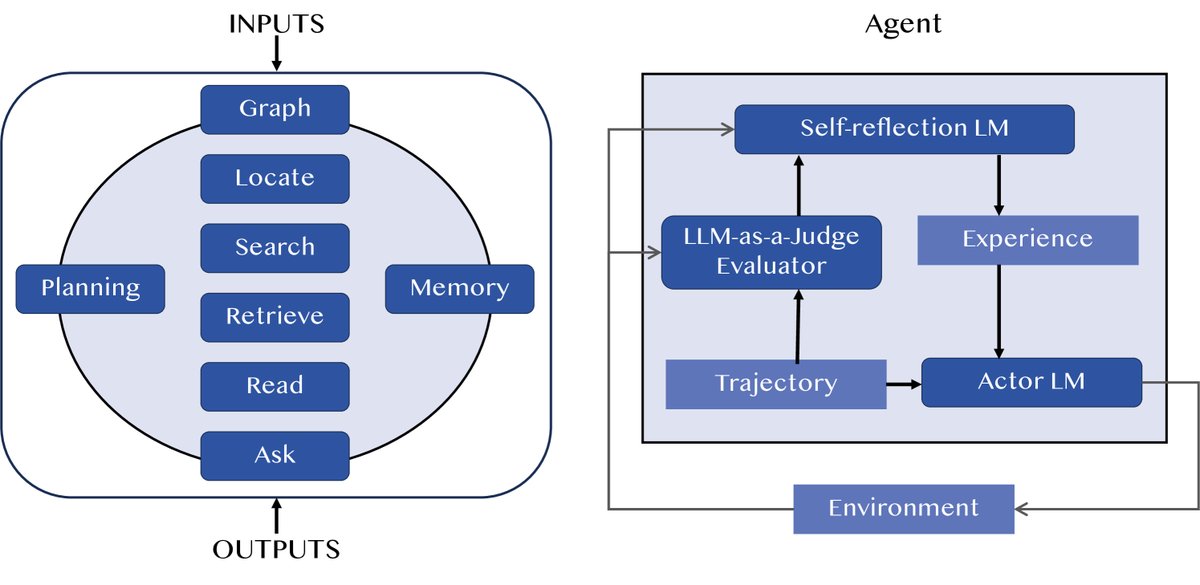 图10: 智能体中LLM-as-a-Judge的两种常见形式。左图是智能体即评判者,右图是在智能体流程中使用LLM-as-a-Judge。
图10: 智能体中LLM-as-a-Judge的两种常见形式。左图是智能体即评判者,右图是在智能体流程中使用LLM-as-a-Judge。
LLM-as-a-Judge用于推理/思维
推理是一个比判断更复杂的过程,但它依赖于判断来确保逻辑连贯和结果清晰。LLM-as-a-Judge成为增强LLM推理能力的关键工具,主要体现在两个框架中:
- 扩展训练时间:在训练阶段,LLM-as-a-Judge常作为奖励模型或评估器,用于强化学习(如DPO)或自优化过程,以生成高质量的推理数据集。
- 扩展测试时间:在推理阶段,当模型生成多个推理路径时(如“Best-of-N”),LLM-as-a-Judge负责评估并选择最准确、最连贯的那个。
快速实践
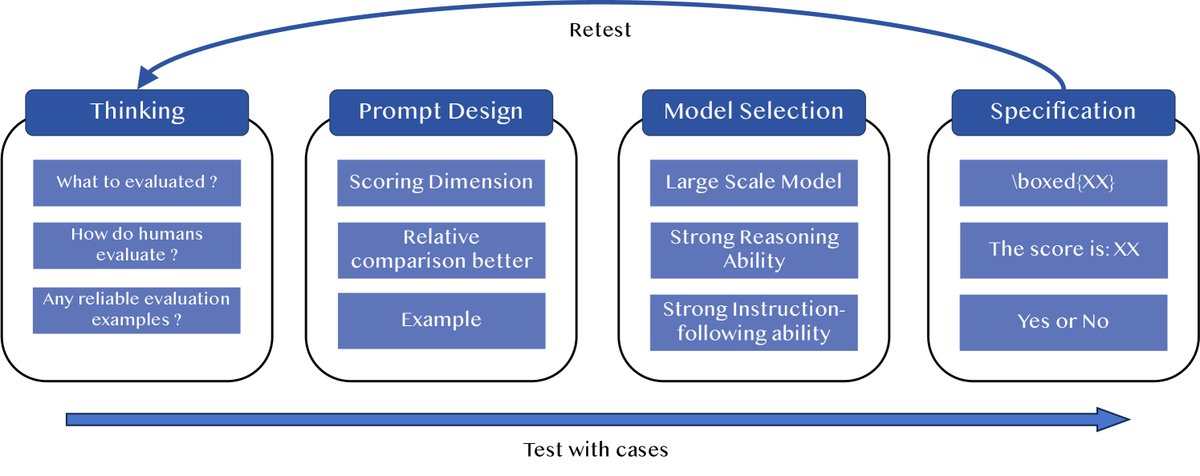 图11: 快速实践流程图
图11: 快速实践流程图
要有效应用LLM-as-a-Judge,建议遵循一个迭代测试和优化的流程。其成功与否高度依赖于任务复杂性、提示设计、模型选择和后处理方法等具体实现细节。一个快速实践的流程如下图所示,包含四个主要阶段:
- 思考阶段:明确评估目标,了解人类通常如何评估,并找到一些可靠的评估案例。
- 提示设计:精心设计提示的措辞和格式。指定评分维度、强调相对比较、并提供高质量示例是高效且通用的方法。
- 模型选择:选择具有强大推理和指令遵循能力的大模型,以保证评估的可靠性。
- 标准化输出:确保输出格式统一、结构化,例如使用特定格式(如\(\boxed{XX}\))、数值分数或二元响应。
整个过程应包含反复的案例测试和优化,通过对比不同模型或提示来验证改进效果。
改进策略
直接使用LLM进行评估任务时,其固有的偏见(如长度偏见、位置偏见、具体性偏见)会损害评估结果的可靠性。减轻这些偏见并提升LLM的整体评估性能是应用中的关键挑战。本节介绍三种改进策略,分别针对LLM-as-a-Judge正式定义中的三个关键环节:上下文 \($\mathcal{C}\)$、LLM自身能力 \($\mathcal{P}\_{\mathcal{LLM}}\)$ 和获取最终结果的后处理 $$$\mathcal{E}$`。
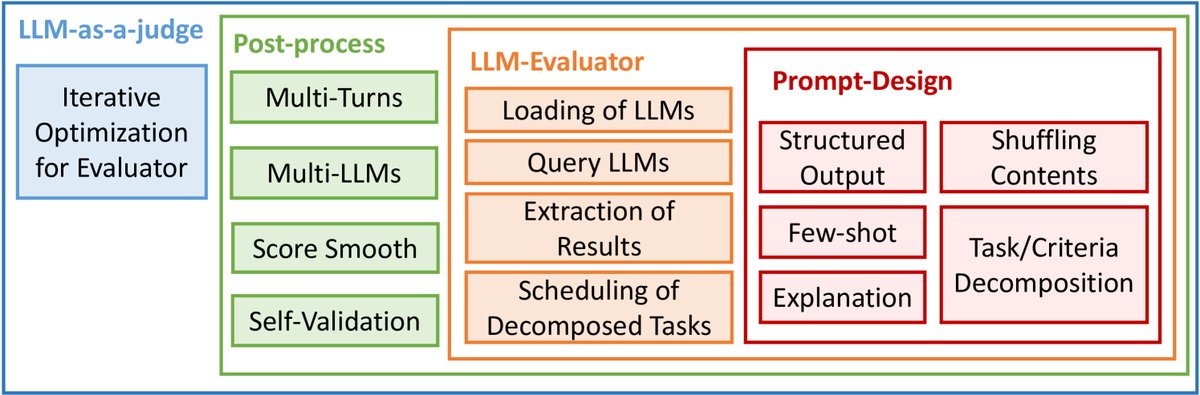 图12: 改进策略分类图
图12: 改进策略分类图
以下是图12中改进策略的结构化概述:
- 评估提示的设计策略 (3.1节)
- 优化LLM对评估任务的理解
- 少样本提示 (Few-shot prompting):如FActScore, SALAD-Bench等。
- 评估步骤分解:如G-Eval, DHP, SocREval等。
- 评估标准分解:如HD-Eval等。
- 内容随机排列:如Auto-J, JudgeLM, PandaLM等。
- 评估任务转换:如Liu等人的工作。
- 优化LLM的输出形式
- 约束输出为结构化格式:如G-Eval, DHP, LLM-EVAL等。
- 提供带解释的评估:如CLAIR, FLEUR等。
- 优化LLM对评估任务的理解
- LLM能力提升策略 (3.2节)
- 通过元评估数据集进行微调
- 例如:PandaLM, SALAD-Bench, OffsetBias, JudgeLM, CritiqueLLM。
- 基于反馈的迭代优化
- 例如:INSTRUCTSCORE, JADE。
- 通过元评估数据集进行微调
- 最终结果的优化策略 (3.3节)
- 整合多轮评估结果
- 多轮总结:如Sottana等人、PsychoBench、Auto-J的工作。
- 通过多个LLM进行投票
- 例如:CPAD。
- 整合多轮评估结果