A Survey on LLM Mid-training
-
ArXiv URL: http://arxiv.org/abs/2510.23081v1
-
作者: Yang Bai; Xuemiao Zhang; Rongxiang Weng; Hongfei Yan; Rumei Li; Chen Zhang; Xunliang Cai; Jingang Wang
-
发布机构: Meituan; Peking University
LLM 中间训练综述
概览
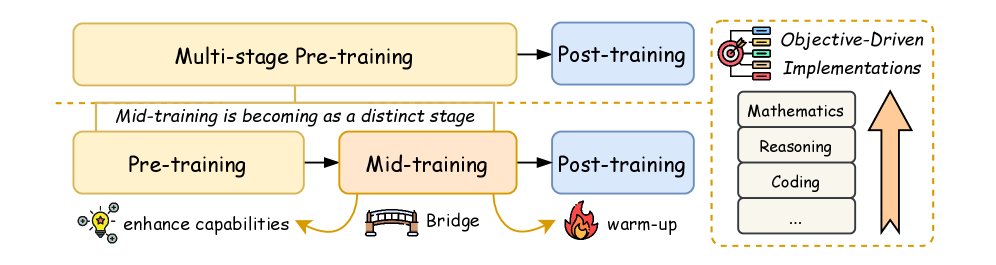
当代大型语言模型 (LLM) 的开发已从单一的预训练模式演变为复杂的多阶段优化框架。预训练通过接触大规模多样化语料库为模型奠定基础能力,而后续的优化阶段则系统性地增强特定能力。中间训练 (mid-training) 作为连接预训练和后训练的关键桥梁,其重要性日益凸显。
中间训练的特点是利用中等规模的计算资源和目标明确的大规模数据。它通过课程引导的方式接触领域特定数据,前向传播专业能力的潜力;同时通过保留一定比例的通用数据,后向保留基础通用能力。经验证据表明,相比预训练,中间训练能以更少的数据和计算量带来更显著的性能提升。
本文将中间训练正式定义为一个独特的模型开发阶段,它保留了预训练的下一词元 (token) 预测目标,但通过精心策划的数据混合(通常包含高质量的领域数据和指令数据)来系统性地提升特定技能。这与持续预训练 (continued pre-training) 不同,后者通常不考虑优化器状态或分布保持,可能导致通用能力丧失。中间训练则是一个有过渡意图的、审慎的设计阶段。
中间训练协调三大能力领域:
- 核心认知技能:如数学、推理。
- 任务执行:如指令遵循、编码、智能体 (Agent) 行为。
- 可扩展性:如长上下文处理、多语言能力。
下图展示了中间训练在 LLM 开发全景中的位置。
数据策管
中间训练的数据通常是通用高质量语料库与专业格式数据(如问答对、指令数据、数学和代码等领域数据)的混合。本节将详细探讨数据策管的端到端工作流程,包括数据收集、合成、选择、去污染和混合,如下图所示,各环节顺序可根据需求调整。
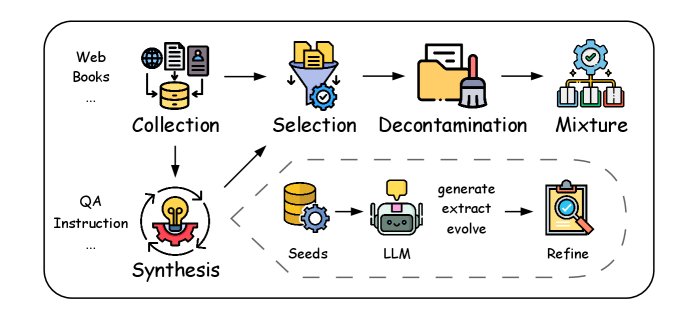
数据收集
中间训练的数据来源与预训练类似,包括网络爬取语料、数字化书籍和人工标注材料。常用的网络爬取工具有 Trafilatura,广泛使用的数据集有 CommonCrawl、Wikipedia、C4、Pile 等。此外,中间训练还会收集特定格式的数据,如 Stack Exchange QA、RedStone、MegaMath 等问答对数据集。所有收集的数据都会经过初步清洗和质量过滤,以确保数据的完整性和可靠性。
数据合成
数据合成通过重构、转换或生成稀缺数据类型(如智能体数据)来提升数据的信息密度和整体质量,有效解决了数据稀缺、多样性不足等问题。鉴于中间训练的数据规模,目前主流的合成方法都由 LLM 驱动,可分为三类:
- 蒸馏 (Distillation):利用强大的 LLM 通过精心设计的提示词直接生成数据,或蒸馏出更小的合成模型。此方法高度依赖 LLM 的能力,后续常伴有严格的质量过滤。具体技术包括:
- 风格改写:将低质量、嘈杂的语料库转化为信息密度更高的表达。
- 特定格式的扩散合成:设计特定提示词,基于语料库生成海量的问答对或指令数据。
- 低资源语言翻译与多模态合成。
-
提取 (Extraction):利用 LLM 从收集的语料库中直接提取自然的问答对或其他格式的数据,然后进行后续精炼。例如,WebInstruct 通过“召回-提取-精炼”的流程从网页内容中获取高质量问答对。
- 演化 (Evolution):通过设计的循环迭代过程生成增强版的问题和解决方案,尤其适用于数学领域。例如,MathGenie 从种子数据中增强解题方案,然后逆向翻译成新的数学问题,从而创造出多样且可靠的合成数据。
数据选择
数据选择是在中间训练阶段从原始数据中筛选出高质量或领域特定样本的过程,其粒度比预训练阶段更细。主要方法有两种:
- 目标采样 (Targeted sampling):通过降采样相关性较低的领域或升采样领域特定内容来调整数据分布。
- 评估器过滤 (Rater-based filtering):使用专门的评分模型(Rater)来评估数据质量。常用的评估器包括 FastText 分类器、FineWeb-Edu 分类器和 QuRater 评估模型。
目前的瓶颈在于如何将预训练数据高效地筛选为高质量的通用数据集,这通常需要协同组合多个评估器来精挑细选。
数据去污染
数据去污染是基础模型预处理的关键步骤,旨在从训练语料中剔除无意义、敏感或与基准测试相关的内容,以减轻数据泄露风险并确保公平评估。主要挑战在于平衡数据移除与模型性能保持,因为现有方法都存在假阳性(过度过滤导致泛化能力下降)和假阴性(去污染不彻底导致基准分数虚高)的问题。
目前最主流的实现方法是 N-gram 匹配,因其简单且可扩展。然而,它无法捕捉词汇变化的语义等价性。基于嵌入的方法(如余弦相似度)语义敏感性更强,但计算成本高昂。混合方法(如 N-gram 结合最长公共子序列)显示出效果提升,但缺乏普适性。
数据混合
中间训练通过策略性地混合不同形式的数据来增强特定能力。数据构成通常是高质量通用语料与特殊格式数据的融合,其比例根据特定目标量身定制。
高质量通用语料通常从预训练数据中筛选而来,用于维持模型基础的语言鲁棒性,并减轻分布偏移风险。
特殊格式数据主要包括:
- 问答 (QA) 数据:以知识密集或推理驱动为特点,擅长构建显式知识表示和增强少样本适应性。不同类型的 QA 数据可针对不同能力,如短 CoT QA 强化事实知识,长 CoT QA 培养迭代推理能力。
- 指令 (Instruction) 数据:结构上与后训练阶段的指令微调数据相似。研究表明,在中间训练中加入少量(如1%)指令数据,可以显著减少 SFT 阶段所需的指令微调量,并提升 RL 效果。
- 长上下文 (Long-context) 数据:通常来源于书籍、维基和高质量论文,通过升采样或合成来增强模型处理长序列的能力。
确定最佳混合比例的方法主要有:
- 经验驱动分配:如 Llama-3 为新数据集分配 30% 的权重。
- 代理实验推断:OLMo 2 使用 microanneals(在小数据子集上进行缩减的退火运行)来从小规模试验中推断大规模混合的效果。RegMix 则将比例优化视为一个回归任务,通过在多种混合配置上训练许多小模型来预测未知混合的性能。这些方法依赖于稳定性假说,即数据混合比例的性能排序在不同模型规模和 Token 数量下保持一致。
训练策略
中间训练的训练策略主要集中在学习率(LR)调度上,同时其他超参数配置也对结果有显著影响。
学习率调度
学习率调度对训练的稳定性、效率和最终性能至关重要。典型的学习率调度包含预热 (warm-up) 阶段和衰减 (decay) 阶段。预热阶段通常采用线性预热,能提高训练稳定性。衰减阶段则可以采用线性、余弦或指数衰减等策略。
值得注意的是,衰减阶段常被分为缓速衰减期和快速衰减期,而高质量数据通常在快速衰减期引入。此外,像 Warmup-Stable-Decay (WSD) 这样的多阶段调度器,引入了一个稳定的高学习率训练阶段,帮助模型探索参数空间,从而提升优化效率和泛化性能,已成为当前广泛采用的实践。
不同学习率调度器对比。
| 阶段 | 调度器类型 | 公式 |
|---|---|---|
| 预热 (Warm-up) | 线性 (Linear) | \(\eta=\frac{s}{W}{\eta}_{\max},\quad 0\leq s\leq W\) |
| 稳定 (Stable) | - | \(\eta=\eta,\quad 0\leq s\leq T\) |
| 衰减 (Decay) | 线性 (Linear) | \(\eta={\eta}_{\max}-({\eta}_{\max}-{\eta}_{\min})\cdot\frac{s}{S},\quad 0\leq s\leq S\) |
| 余弦 (Cosine) | \(\eta={\eta}_{\min}+\frac{1}{2}({\eta}_{\max}-{\eta}_{\min})(1+\cos(\pi\frac{s}{S})),\quad 0\leq s\leq S\) | |
| 指数 (Exponential) | \(\eta={\eta}_{\max}\cdot e^{-ks}\) | |
| 多阶段 | WSD | \(WSD(T;s)=\begin{cases}\frac{s}{W}\eta, & s<W \\ \eta, & W<s<T \\ f(s-T)\eta, & T<s<S \end{cases}\) |
其他训练设置
与学习率调度一同配置的关键超参数主要是批量大小 (batch size)。增加批量大小可以减小随机梯度估计的方差,从而允许在训练中采用更高的学习率。在退火阶段,批量大小通常受数据规模影响,并可能进行动态调整。
模型架构优化
长上下文扩展
旋转位置编码 (Rotary Position Embedding, RoPE) 已成为 LLM 的标准位置编码方法。然而,在固定上下文长度上预训练的 LLM 在处理更长序列时会性能下降,因此需要基于 RoPE 的长上下文扩展方法。
RoPE 通过一个旋转张量来编码词元的位置信息。给定一个隐藏向量 $h=[h_{0},h_{1},…,h_{d-1}]$ 和一个位置索引 $m$,RoPE 的操作如下:
\[f(h, m) = [..., h_{2i} \cos(m\theta_i) - h_{2i+1} \sin(m\theta_i), h_{2i} \sin(m\theta_i) + h_{2i+1} \cos(m\theta_i), ...]\]其中 $\theta_{j}=b^{-2j/d}, j\in{0,1,…,d/2-1}$。
常见的 RoPE 扩展变体包括:
位置插值 (Position Interpolation, PI)
PI 方法将位置索引 $m$ 按比例缩小为 $m/\alpha$,从而将原始位置范围插值到更长的上下文窗口。
NTK 感知插值 (NTK-aware Interpolation, NTK)
NTK 认为 PI 对所有维度进行同等插值可能导致高频信息丢失。因此,NTK 通过调整基频 $b$ 来引入一种非线性插值策略。
Yet another RoPE extensioN (YaRN)
YaRN 采用一个斜坡函数,在不同维度上以不同比例组合 PI 和 NTK。此外,它引入了一个温度因子 $t=\sqrt{1+\ln(s)/d}$ 来缓解长输入导致注意力分布偏移的问题。
YaRN 目前在生产系统中代表了性能和效率的最佳平衡。
衰减缩放定律
与预训练缩放定律不同,衰减缩放定律 (Decay Scaling Laws) 考虑了衰减阶段的独特起点,为预测影响训练效率的关键变量提供了定制化方法。这些定律主要关注预测以下变量:模型大小、数据比例(通用与专业)以及训练 Token 数量。该定律为理解衰减阶段各因素间的相互作用及其对模型性能的影响提供了结构化框架,但仍需进一步研究以完善。
评估
中间训练阶段的模型评估遵循已建立的标准化基准,如下表所示。评估框架涵盖通用、数学、编码、智能体和长上下文等多个领域,并与下文详述的中间训练目标战略性对齐。
中间训练的基准测试。
| 领域 | 能力 | 基准测试 |
|---|---|---|
| 通用 | 知识 | MMLU, TriviaQA, NaturalQuestions |
| 推理 | ARC, HellaSwag, WinoGrande, BIG-Bench Hard | |
| 数学 | 推理 | GSM8K, MATH |
| 编码 | 代码生成 | HumanEval, MBPP |
| 代码补全 | HumanEval | |
| 代码修复 | HumanEval-Fix, Code-Fix | |
| 代码推理 | HumanEval-NL, Code-Reasoning | |
| 智能体 | 工具使用 | ToolBench, AgentBench |
| 长上下文 | 推理 | NarrativeQA, QuALITY, ScrollS |
目标驱动的实现
目标驱动的实现是中间训练的方法论基石。这些能力增强目标可系统性地分为四大相互关联的领域:通用能力、核心认知能力、任务执行能力和扩展能力。本节将解构这些目标的实现方式,并分析主流模型如何利用定制化的数据策管、训练策略和架构优化来达成这些目标。
主流模型中提及的中间训练目标。
| 模型 | 目标 |
|---|---|
| Phi-3.5 | 通用, 多语言, 长上下文 |
| Phi-4 | 通用, 数学, 编码 |
| Llama-3 | 通用, 推理 |
| OLMo 2 | 通用, 编码 |
| Yi-Lightning | 通用, 编码 |
| … | … |
通用能力
在中间训练期间保持和增强模型的通用理解与生成能力是一个关键的优化方向。这要求精心设计的干预措施,以减轻灾难性遗忘 (catastrophic forgetting),同时提升模型的特定能力。如上表所示,所有主流模型都深入研究了在提升其他目标的同时保持通用性能。
实证分析表明,保留经过严格策管的预训练数据子集至关重要。通过优化数据组成和平衡比例,可以显著提升下游任务的性能和泛化鲁棒性。