A Survey on Multimodal Large Language Models
-
ArXiv URL: http://arxiv.org/abs/2306.13549v4
-
作者: Chaoyou Fu; Sirui Zhao; Enhong Chen; Ke Li; Shukang Yin; Tong Xu; Xing Sun
-
发布机构: Tencent YouTu Lab; University of Science and Technology of China
引言
近年来,大型语言模型 (Large Language Models, LLMs) 取得了显著进展,通过扩大数据和模型规模,展现出指令遵循 (instruction following)、上下文学习 (In-Context Learning, ICL) 和思维链 (Chain of Thought, CoT) 等惊人的涌现能力。然而,LLMs 本质上是“视觉盲区”,只能理解文本。与此同时,大型视觉模型 (Large Vision Models, LVMs) 虽然视觉能力强大,但在推理方面相对落后。
鉴于这种互补性,LLM 和 LVM 的结合催生了多模态大型语言模型 (Multimodal Large Language Model, MLLM) 这一新领域。MLLM 指的是基于 LLM、具备接收、推理和输出多模态信息能力的模型。与传统的判别式或生成式多模态方法相比,MLLM 有两大特征:
- MLLM 基于数十亿参数规模的 LLM,这是以往模型不具备的。
- MLLM 采用新的训练范式,如多模态指令微调 (multimodal instruction tuning),以释放其全部潜力。
得益于这两大特征,MLLM 展现出许多新能力,例如根据图片编写网站代码、理解梗图的深层含义以及无需光学字符识别 (OCR-free) 的数学推理。自 GPT-4 发布以来,MLLM 领域的研究热潮迅速兴起。本综述旨在梳理 MLLM 的基本概念、主要方法和最新进展。
2 架构
一个典型的 MLLM 可抽象为三个模块:一个预训练的模态编码器 (modality encoder)、一个预训练的 LLM 和一个连接它们的模态接口 (modality interface)。打个比方,模态编码器如同人的眼睛/耳朵,接收并预处理信号;LLM 如同大脑,进行理解和推理;模态接口则负责对齐不同模态。部分 MLLM 还包含一个生成器,用于输出文本以外的其他模态。

2.1 模态编码器
编码器将原始信息(如图像、音频)压缩成更紧凑的表示。通常不从零开始训练,而是使用已预训练好的编码器,例如通过图文对预训练实现了视觉和文本语义对齐的 CLIP。这样可以更容易地将其与 LLM 对齐。
表 I: 常用图像编码器总结
| 型号 | 预训练数据集 | 分辨率 | 样本量 (B) | 参数量 (M) |
|---|---|---|---|---|
| OpenCLIP-ConvNext-L | LAION-2B | 320 | 29 | 197.4 |
| CLIP-ViT-L/14 | OpenAI’s WIT | 224/336 | 13 | 304.0 |
| EVA-CLIP-ViT-G/14 | LAION-2B,COYO-700M | 224 | 11 | 1000.0 |
| OpenCLIP-ViT-G/14 | LAION-2B | 224 | 34 | 1012.7 |
| OpenCLIP-ViT-bigG/14 | LAION-2B | 224 | 34 | 1844.9 |
选择编码器时,通常考虑分辨率、参数大小和预训练语料等因素。许多研究证实,使用更高分辨率能带来显著性能提升。提升分辨率的方法主要分为两类:
- 直接缩放 (Direct scaling):直接向编码器输入更高分辨率的图像,通常需要对编码器进行微调或替换。
- 分块法 (Patch-division):将高分辨率图像切割成多个图块 (patch),然后将这些子图与一张降采样后的全局图一同送入编码器,分别捕捉局部和全局特征。
2.2 预训练 LLM
使用预训练好的 LLM 更为高效实用。这些模型通过在海量网络语料上进行预训练,已内化了丰富的世界知识,并具备强大的泛化和推理能力。
表 II: 常用开源 LLM 总结
| 模型 | 发布日期 | 预训练数据规模 | 参数量 (B) | 语言支持 | 架构 |
|---|---|---|---|---|---|
| Flan-T5-XL/XXL | 2022年10月 | - | 3/ 11 | en, fr, de | 编码器-解码器 |
| LLaMA | 2023年2月 | 1.4T tokens | 7/ 13/ 33/ 65 | en | 因果解码器 |
| Vicuna | 2023年3月 | 1.4T tokens | 7/ 13/ 33 | en | 因果解码器 |
| LLaMA-2 | 2023年7月 | 2T tokens | 7/ 13/ 70 | en | 因果解码器 |
| Qwen | 2023年9月 | 3T tokens | 1.8 / 7/ 14/ 72 | en, zh | 因果解码器 |
研究发现,扩大 LLM 的参数规模也能带来性能提升。例如,将 LLM 从 7B 扩展到 13B,模型在各项基准上均有提升。此外,稀疏的专家混合 (Mixture of Experts, MoE) 架构也受到关注,它能在不增加计算成本的情况下扩大总参数量,从而获得比同等计算量的密集模型更好的性能。
2.3 模态接口
由于 LLM 只能感知文本,必须有接口来弥合自然语言与其他模态之间的鸿沟。端到端训练成本高昂,因此主要有两种更实用的方法:
1. 可学习连接器 (Learnable Connector) 该模块负责将非文本信息投射到 LLM 能理解的空间。根据多模态信息融合的方式,可分为两类:
- Token 级融合 (Token-level fusion):将编码器输出的特征转换为 token,与文本 token 拼接后一起送入 LLM。常见方法包括使用一组可学习的查询 token(如 BLIP-2 中的 Q-Former)或简单的多层感知机 (MLP)(如 LLaVA)。
- 特征级融合 (Feature-level fusion):在 LLM 的 Transformer 层之间插入额外模块,以实现文本和视觉特征的深度交互与融合。例如,Flamingo 插入交叉注意力层,而 CogVLM 在每层插入一个视觉专家模块。
2. 专家模型 (Expert Model) 另一种方式是借助专家模型(如图像字幕模型)将多模态输入直接转换为文本描述,然后将这些描述送入 LLM。这种方法简单直接,但可能在转换过程中丢失信息,灵活性不如可学习连接器。
3 训练策略与数据
一个成熟的 MLLM 通常经历三个训练阶段:预训练 (pre-training)、指令微调 (instruction-tuning) 和对齐微调 (alignment tuning)。每个阶段都有不同的目标和数据需求。
3.1 预训练
训练细节 预训练的主要目标是对齐不同模态并学习多模态世界知识。这一阶段通常使用大规模的图文对等数据。训练任务一般是自回归地预测图像的描述文本,使用标准的交叉熵损失函数。通常会冻结预训练的编码器和 LLM,只训练可学习的接口,以在保留预训练知识的同时实现模态对齐。
表 III: 描述数据的简化模板
| Input: |
| Response: {caption} |
注:只有红色部分用于损失计算。
数据 预训练数据主要用于模态对齐和提供世界知识,可分为粗粒度和细粒度两类。
表 IV: 常用的预训练数据集
| 数据集 | 样本量 | 日期 |
| 粗粒度图文 | ||
| CC-3M | 3.3M | 2018 |
| CC-12M | 12.4M | 2020 |
| SBU Captions | 1M | 2011 |
| LAION-5B | 5.9B | 2022年3月 |
| LAION-COCO | 600M | 2022年9月 |
| COYO-700M | 747M | 2022年8月 |
| 细粒度图文 | ||
| ShareGPT4V-PT | 1.2M | 2023年11月 |
| LVIS-Instruct4V | 111K | 2023年11月 |
| ALLaVA | 709K | 2024年2月 |
| 视频-文本 | ||
| MSR-VTT | 200K | 2016 |
| 音频-文本 | ||
| WavCaps | 24K | 2023年3月 |
- 粗粒度数据:通常来自网络爬取,数据量大,但描述简短且有噪声,如 CC、SBU、LAION 和 COYO 系列数据集。
- 细粒度数据:近期研究开始使用强大的 MLLM(如 GPT-4V)生成高质量数据。这类数据描述更长、更准确,但成本较高,数据量相对较小,如 ShareGPT4V 数据集。
3.2 指令微调
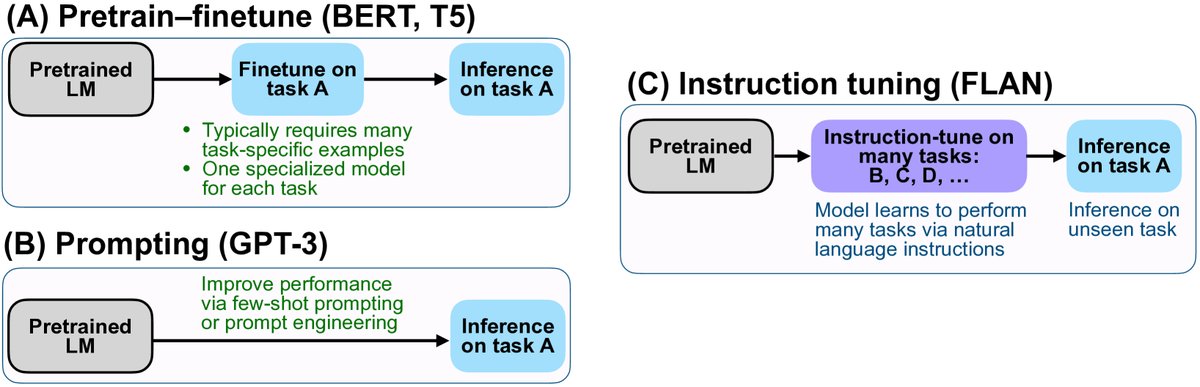
简介 指令微调旨在教会模型理解并完成用户指令,从而使其能泛化到未见过的任务,提升零样本 (zero-shot) 性能。
训练细节 多模态指令样本通常包含一个指令、一个输入-输出对。模型根据指令和多模态输入预测答案。训练目标是最大化生成正确答案的概率,即标准的自回归损失。
表 V: 多模态指令数据的简化模板
| 下面是一条描述任务的指令。请撰写一个适当地完成请求的回复。 |
| Instruction: |
| Input: { |
| Response: |
训练目标可以表示为:
\[\mathcal{L}(\theta)=-\sum_{i=1}^{N}\log p(\mathcal{R}_{i} \mid \mathcal{I},\mathcal{M},\mathcal{R}_{<i};\theta)\]其中 $\mathcal{I}$ 是指令,$\mathcal{M}$ 是多模态输入,$\mathcal{R}$ 是真实回复。
数据收集 收集指令数据通常有三种方法:
- 数据适配 (Data Adaptation):将现有的高质量任务特定数据集(如 VQA、字幕数据集)转换为指令格式。通过手动设计或 GPT 辅助生成多样的指令模板。
- 自指令 (Self-Instruction):利用强大的 LLM(如 GPT-4/GPT-4V)和少量人工标注的示例来生成大规模的指令数据。LLaVA 是该方法的典型代表。
- 数据混合 (Data Mixture):将多模态指令数据与纯文本的对话数据混合训练,以提升模型的对话和指令遵循能力。
表 VII: 通过自指令生成的流行数据集总结
| 数据集 | 样本量 | 模态 | 来源 | 构成 |
|---|---|---|---|---|
| LLaVA-Instruct | 158K | I + T $\rightarrow$ T | MS-COCO | 23K字幕 + 58K多轮QA + 77K推理 |
| LVIS-Instruct | 220K | I + T $\rightarrow$ T | LVIS | 110K字幕 + 110K多轮QA |
| ALLaVA | 1.4M | I + T $\rightarrow$ T | VFlan, LAION | 709K字幕 + 709K单轮QA |
| Video-ChatGPT | 100K | V + T $\rightarrow$ T | ActivityNet | 7K描述 + 4K多轮QA |
| VideoChat | 11K | V+T $\rightarrow$ T | WebVid | 描述 + 摘要 + 创作 |
| Clotho-Detail | 3.9K | A + T $\rightarrow$ T | Clotho | 字幕 |
数据质量 研究表明,指令微调数据的质量比数量更重要。
- 提示多样性 (Prompt Diversity):多样的指令有助于提升模型性能和泛化能力。
- 任务覆盖范围 (Task Coverage):研究发现,视觉推理任务比字幕和问答任务更能有效提升模型性能,且增加指令的复杂性可能比增加任务多样性更有益。
3.3 对齐微调
简介 对齐微调主要用于使模型与特定的人类偏好对齐,例如生成更少幻觉 (hallucination) 的回复。主要技术有基于人类反馈的强化学习 (Reinforcement Learning with Human Feedback, RLHF) 和直接偏好优化 (Direct Preference Optimization, DPO)。
训练细节
- RLHF:包含三个步骤:
- 监督微调:训练一个初始策略模型。
- 奖励建模:用人类偏好数据对 $(y_w, y_l)$ 训练一个奖励模型 $r_\theta$,使其为更优的回复 $y_w$ 打高分。
- 强化学习:使用 PPO 算法优化策略模型,使其在最大化奖励的同时不过于偏离初始策略。
- DPO:一种更简单的替代方法,它无需显式训练奖励模型,而是直接使用一个简单的二元分类损失函数从偏好数据中学习。其目标函数如下:
数据 对齐微调的数据收集核心是获取对模型回复的反馈,即判断哪个回复更好。这类数据收集成本更高,数据量也相对较少。
表 VIII: 对齐微调数据集总结
| 数据集 | 样本量 | 模态 | 来源 |
|---|---|---|---|
| LLaVA-RLHF | 10K | I + T $\rightarrow$ T | 人类 |
| RLHF-V | 5.7K | I + T $\rightarrow$ T | 人类 |
| VLFeedback | 380K | I + T $\rightarrow$ T | GPT-4V |
4 评测
评测 MLLM 是开发过程的关键环节。与传统多模态模型相比,MLLM 的评测有新特点:(1) MLLM 功能通用,需要全面评测;(2) MLLM 表现出许多需要特别评估的涌现能力。评测方法可根据问题类型分为闭集 (closed-set) 和开集 (open-set) 两类。
4.1 闭集
闭集问题的答案选项是预定义且有限的。评测通常在特定任务的数据集上进行,可以通过标准指标(如准确率、CIDEr 分数)来量化评估。评测设置通常是零样本或在特定任务上微调。
为了进行更全面的定量比较,研究者们开发了专门为 MLLM 设计的新基准 (benchmark)。例如:
- MME:一个综合性评测基准,包含 14 个感知和认知任务。
- MMBench:专门用于评测模型多个维度能力的基准,使用 ChatGPT 将开放式回复与预定义选项进行匹配。
- Video-ChatGPT 和 Video-Bench:专注于视频领域的评测基准。
- POPE:专门用于评估模型幻觉程度的基准。
4.2 开集
与闭集问题相反,开集问题的回复可以更灵活,MLLM 通常扮演聊天机器人的角色。由于聊天内容不固定,评判比闭集输出更复杂。评判标准可分为三类:
- 人工评分 (Manual scoring):由人类评估员根据特定维度(如自然图像理解、图表理解)对精心设计的问题的回复进行打分。
- GPT 评分 (GPT scoring):由于人工评估成本高昂,一些研究探索使用 GPT-4 等强模型来对回复进行多维度(如帮助性、准确性)评分。
- 案例研究 (Case study):通过展示具体案例来直观地展示模型的能力。
(原文在4.2节中途截断)