A Survey on Parallel Reasoning
-
ArXiv URL: http://arxiv.org/abs/2510.12164v1
-
作者: Boye Niu; Haifeng Wang; Linghui Meng; Chen Zhu; Yilong Chen; Enhong Chen; Zhi Zheng; Jing Liu; Zhongli Li; Tong Xu; 等12人
-
发布机构: Baidu; USTC; University of Sydney
引言
现代大型语言模型 (Large Language Models, LLMs) 通过扩展参数和训练数据,获得了强大的基础能力。随后的研究探索了推理时扩展,如扩展思维链 (Chain-of-Thought, CoT),显著提升了推理性能。在此基础上,本文探讨了一种正交的方法:并行推理 (Parallel Reasoning, PR),它通过并发探索多条推理路径来拓宽推理的广度和深度。
标准的序贯推理在处理复杂任务时常常表现得很脆弱,容易陷入所谓的“前缀陷阱” (prefix trap):一旦模型在早期确定了一条推理路径,就很难自我纠正。并行推理模仿了广度优先搜索,通过一次性探索多条路径来增强鲁棒性,从而更充分地利用模型的潜力。
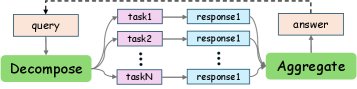
并行推理的核心思想是在回答问题前并行地进行多次尝试,然后聚合这些提出的解决方案。该过程始于一个发散步骤,模型在此步骤中并发探索多条推理路径。这可以通过并行生成多个完整的候选解决方案或将问题分解为同时解决的子任务来实现。在并行生成之后,一个收敛步骤将各种输出聚合成一个单一的最终响应。与序贯推理的串行执行相比,并行方法旨在通过从一组多样化的潜在解决方案中识别出正确答案来增强鲁棒性。
作为一种新颖的推理范式,并行推理具有几个显著优点:
- 提升响应质量:通过探索多条路径,PR 能产生比单路径方法更高质量的回答,从而改善用户体验。这代表了模型实际性能的真正提升。
- 与 CoT 范式正交:CoT 通过逐步推理扩展了推理深度,而 PR 通过并发探索扩展了推理广度。这种设计使 PR 能够独立扩展,并从基础模型能力的进步中持续受益。
- 提高计算效率:特别是在与算法-系统协同设计优化(如 KV 缓存重用)相结合时,PR 能够以更高的计算效率实现与序贯推理相当甚至更优的性能。
- 启发更广泛的策略:PR 体现的并行主义核心哲学也为加速推理的更广泛策略提供了信息,例如并行解码和推测执行。
为了系统地梳理这一领域,本文提出了一个并行推理的分类体系,涵盖三个关键维度:
- 非交互式并行推理 (Non-interactive Parallel Reasoning):模型独立生成多种尝试,然后产出最终答复。
- 交互式并行推理 (Interactive Parallel Reasoning):在推理过程中,各推理路径之间存在主动交互。
- 效率 (Efficiency):涵盖了旨在加速并行推理的工程设计和受并行主义原则指导的新型解码方法。
定义与公式化
本文提出了并行推理的正式定义:它是一种推理时范式,通过从单个查询生成并聚合多个并发的推理路径,来增强语言模型的推理能力,从而产生一个更鲁棒的最终响应。
形式上,给定一个输入查询 $Q$,语言模型 $M$ 通过一个包含分解、并行处理和聚合三个阶段的流水线来产生最终预测 $\Pi(Q)$:
\[\Pi(Q)=(A\circ P_{M}\circ D)(Q)\]在这里,$D$ 是一个分解算子,它将输入查询映射到一组子输入;$P_M$ 表示模型 $M$ 对这些输入进行并行应用;$A$ 是一个聚合算子,它将中间结果合成为最终响应。这个公式捕捉了并行推理的核心:同时处理多条推理路径并将其合成为一个连贯的输出,这与传统序贯推理形成对比。
- 分解 ($D$):给定查询 $Q$,分解算子生成一组 $n$ 个子输入 $\mathbf{T}={T_1, T_2, \dots, T_n}$。在最简单的情况下,$D$ 可以是一个恒等映射,即对所有 $i$ 都有 $T_i=Q$,以从相同的提示开始探索不同的推理轨迹。
- 并行处理 ($P_M$):将语言模型 $M$ 并发应用于每个子输入 $T_i$,产生一组中间结果 $\mathbf{R}={R_1, \dots, R_n}$。
- 聚合 ($A$):将中间结果集 $\mathbf{R}$ 合并为单一、连贯的预测。聚合算子 $A$ 的行为由其粒度(在序列层面还是 Token 层面聚合)和聚合函数的选择来表征。
基于此定义,并行推理与其他推理时策略区别开来。与将问题分解为严格序贯步骤的思维链 (CoT) 不同,并行推理并发处理多个子输入。它也不同于长思维过程,后者通过自反思和自提炼迭代地扩展单一推理链(水平扩展),而并行推理通过同时生成多个不同的推理路径来垂直扩展计算。
非交互式并行推理
在非交互式并行推理中,多个候选推理路径在没有明确通信的情况下生成,随后通过一个收敛步骤将这些多样化的输出聚合起来,产生一个单一的答案。其形式化表示为:
\[\Pi(Q)=A(P_{M}(Q_{1},\dots,Q_{n}))\]其中 $Q_1, \dots, Q_n$ 是输入查询 $Q$ 的相同副本。本节将该范式分为三类进行探讨。
自洽性
并行推理的基础概念源于自洽性 (Self-Consistency)。该方法促使一个模型生成多个响应,然后通过投票过程选出最常见的一个。
\[A(R)=\mathop{\mathrm{argmax}}\_{a}\sum\_{i=1}^{n}\mathbf{I}(E(P_{M}(Q_{i}))=a)\]其中 $E(\cdot)$ 是从输出序列中提取最终答案的函数,$a$ 是候选答案,$\mathbf{I}(\cdot)$ 是指示函数。其基本原理是,随着生成答案数量的增加,模型会收敛到一个高置信度的解决方案,这比单一易受噪声影响的推理路径更准确。
然而,这种方法的计算成本高昂。为了解决这个问题,早期的工作如 Adaptive-Consistency 引入了动态停止准则来优化计算预算。更先进的方法如 DeepConf 通过利用模型的内部置信度分数来进一步优化,它可以在生成过程中动态终止低置信度的推理路径,或用这些分数为最终投票加权,从而在提升精度的同时大幅减少计算量。
为了将该方法推广到开放式任务,Soft Self-Consistency 用基于模型聚合生成概率的“软”投票取代了多数投票。同时,Universal Self-Consistency 使用 LLM 自身来判断和选择候选答案中最一致的一个。这种从简单共识到基于模型的判断的演变,为更复杂的聚合范式的发展奠定了基础。
基于排序
自洽性方法通过多数投票来确定最终答案,但其局限在于正确答案可能存在于解空间中,却并非最频繁的答案,因此无法被选中。相比之下,基于排序的方法利用外部评分函数——即验证器 (verifier) 或奖励模型 (Reward Model, RM)——来评估和排序所有候选答案。
\[A(R)=E\left(\mathop{\mathrm{argmax}}\_{R_{i}\in\mathbf{R}}V(R_{i})\right)\]其中 $V(\cdot)$ 是一个为输出序列分配质量分数的评分或验证函数。这通常通过 Best-of-N (BoN) 采样范式实现。
研究表明,BoN 是扩展模型能力的一个基本轴线,但它也带来了两个挑战:计算分配的效率和验证器的质量。
- 效率挑战:固定的采样策略往往在简单查询上过度消耗计算,而在复杂查询上投入不足。Latency-TTC 引入了一种查询自适应方法,通过一个综合考虑了 Token 成本和时钟延迟的效用函数,为每个查询动态选择最优的推理方法和预算。
- 验证器质量挑战:验证器是排序的关键,已发展出两种主要方法:结果奖励模型 (Outcome Reward Models, ORMs) 和过程奖励模型 (Process Reward Models, PRMs)。ORM 对整个推理链进行整体评分,而 PRM 为每个中间步骤提供更细粒度的反馈,确保过程的逻辑连贯性。为了打破对昂贵人工标注的依赖,新的验证器训练方法不断涌现,如将验证视为下一个 Token 预测任务的 Generative Verifier (GenRM),以及自动化过程监督的 MATH-SHEPHERD。
更先进的方法转向相对判断,如 PairJudge RM 通过配对比较进行淘汰赛来筛选候选者。为了降低昂贵验证器的计算成本,BoNBoN 采用多阶段分层策略,先用高效的排序器初筛,再用强大的验证器对有希望的子集进行重排。
一个更深刻的转变是从“选择”最佳答案转向“综合”出一个新的、更优的解决方案。这通常通过“探索者-合成者”架构实现。例如,A2R 框架发现合成器的能力是性能的关键驱动因素,从而提出“小模型探索、大模型合成”的高效配置。类似地,SSA 和 SEAT 框架通过强化学习训练专门的聚合器模型来审查、协调和综合最终答案。与此不同,GSR 训练一个统一模型来同时扮演生成者和提炼者的角色。
结构化推理
另一条研究路线标志着从思维链的线性进展到结构化推理 (Structure Reasoning) 的关键转变,这是一种动态的问题解决拓扑范式。
- 代表性方法:
- Tree-of-Thoughts (ToT):将推理框架化为树搜索,支持并行探索、自评估和剪枝多个解决方案路径。
- Graph-of-Thoughts (GoT):采用图结构,解锁了更复杂的操作,如聚合不同推理线和通过反馈循环提炼思想。
- Cumulative Reasoning (CR):采用迭代方法,通过顺序解决子问题并将每个验证过的结果累积到下一步的上下文中,来确保逻辑的鲁棒性。
这些复杂结构引入了巨大的搜索空间和推理开销,催生了两个并行的优化方向:搜索算法和效率优化。
- 搜索算法优化:Self-Evaluation Guided Beam Search 使用模型的内在批判能力作为启发式信息来修剪搜索束。Process Supervision with MCTS 则利用搜索算法不仅进行引导,还生成细粒度数据以逐步增强模型能力。
- 效率优化:在不同抽象层次上进行:
- 提示层:Skeleton-of-Thought 先生成简洁大纲再并行扩展,以减少延迟。
- 系统层:Dynamic Parallel Tree Search 通过先进的 KV 缓存管理来优化执行。
- 理论层:Atom-of-Thoughts 重新定义了过程,以防止计算负载累积。
最后,一类框架采取了不同的哲学方法,通过重新定义 LLM 的角色来根本性地转移“智能的所在地”。Self-ask 迫使 LLM 将其思维过程外化为明确的子问题。ThinkSum 将 LLM 重新定位为专门的“系统1”(联想知识检索),并将“系统2”(逻辑推理)卸载到外部模型。Reasoning via Planning (RaP) 则将任务重构为经典的 AI 规划问题,将 LLM 用作灵活的语义模拟器,而外部算法(如 MCTS)提供战略智能。这种概念上的转变预示着混合认知架构的兴起。
交互式并行推理
交互式并行推理是一种更细粒度的范式,其中多个推理路径或智能体在推理过程中并行运作并动态交换信息,而不是独立生成最后才聚合。形式上:
\[\Pi(Q) =A\!\left(\{R_{i}^{(T)}\}\_{i=1}^{n}\right),\] \[R_{i}^{(t+1)} =P\!\left(T_{i};\,\{R_{j}^{(t)}\}\_{j\neq i}\right).\]其中 $R_i^{(t)}$ 表示第 $i$ 个分支在交互轮次 $t$ 的中间输出。每个分支的更新都依赖于自身的输入 $T_i$ 和其他分支的中间输出。这种实时通信支持动态纠错,减轻了早期错误的影响,从而产生更鲁棒和高效的推理。交互主要有两种形式:内部交互和多智能体交互。
内部交互
内部交互 (Intra-interaction) 并行推理允许单个模型内的不同推理路径在生成期间共享中间信息。形式上,每个分支根据自身的输入 $T_i$ 和从其他分支聚合的共享信息 $\mathcal{S}(\cdot)$ 进行更新。
\[\Pi(Q) =A\!\left(\{R_{i}^{(T)}\}\_{i=1}^{n}\right),\] \[R_{i}^{(t+1)} =P\!\left(T_{i},\;\mathcal{S}\!\left(\{R_{j}^{(t)}:j\neq i\}\right)\right).\]这种交互机制使每个路径都能根据其他路径的进展进行调整,从而比独立采样更具鲁棒性。根据信息交换发生的时间和方式,可分为几类:
- 调度导向的交互:模型自适应地控制探索的分支数量和终止时机。例如,Entropy-based termination 利用语义多样性与正确性之间的负相关性,在达成共识后停止探索以减少冗余计算。Thread-based frameworks 引入了显式的 \(spawn\) 和 \(join\) 操作来控制分支的创建与合并。
- 分阶段或逐步交互:不同推理路径周期性地共享部分结果以吸收同伴反馈。例如,LeaP 允许每个路径生成简洁的摘要并路由到其他路径,以帮助纠正局部次优轨迹。CoSD 则将推测性解码转变为一个协作过程,让多个草稿在生成期间交换概率和语义信息。
- 解码层面的紧密耦合:各路径可以持续访问彼此的输出。例如,Group Think 实例化多个“思考者”,其 Token 流在每一步都相互可见,从而产生自发的分工并减少冗余。Hogwild! Inference 则通过让并发工作者共享键值缓存来实现类似效果。
多智能体交互
多智能体交互 (Inter-interaction) 并行推理涉及多个模型或智能体 (agents) ${M_1, M_2, \ldots, M_k}$,它们在推理过程中交换中间结果。每个智能体 $M_i$ 基于原始查询 $Q$ 和聚合了其他智能体贡献的交互函数 $\mathcal{I}(\cdot)$ 来更新其输出 $R_i^{(t+1)}$。最终预测 $\Pi(Q)$ 是通过在所有智能体的输出上应用聚合算子 $A$ 得到的。
\[\Pi(Q) =A\!\left(\{R_{i}^{(T)}\}\_{i=1}^{k}\right),\] \[R_{i}^{(t+1)} =M_{i}\!\left(Q,\;\mathcal{I}\!\left(\{R_{j}^{(t)}:j\neq i\}\right)\right).\]