A Systematic Survey on Large Language Models for Evolutionary Optimization: From Modeling to Solving
-
ArXiv URL: http://arxiv.org/abs/2509.08269v1
-
作者: Kay Chen Tan; Ran Cheng
引言
优化技术已成为解决工程设计、经济规划和科学发现等领域复杂问题的关键。实践中,优化算法分为精确方法和近似方法,但没有任何一种算法能普适于所有问题(“没有免费的午餐”定理),这使得算法的选择、配置和设计高度依赖专家知识。机器学习,特别是强化学习(RL),虽被用于降低这种复杂性,但其泛化能力有限。
近期,大型语言模型(LLM, Large Language Models)凭借其强大的语言理解、复杂逻辑推理和开放域知识泛化能力,为优化领域的研究带来了新机遇。LLM不仅能将自然语言描述的优化问题转化为数学模型,还能作为独立的优化器或与传统算法协同工作。
尽管潜力巨大,LLM在优化领域的应用仍处于早期阶段,并暴露出一些局限性,例如作为独立优化器时性能常不及经典算法。为系统性梳理这一新兴交叉领域,本文做出以下贡献:
- 全面的文献综述:系统总结了近期关于LLM用于优化的代表性方法、最新进展和关键应用。
- 结构化的分类体系:提出了一个将现有工作分为优化建模和优化求解两大阶段的分类框架。其中,优化求解进一步细分为三种范式:LLM作为优化器、用于算法的底层LLM和用于算法的高层LLM。
- 挑战与未来方向:通过对比LLM驱动方法与传统方法,识别了核心挑战和研究空白,并展望了构建智能优化生态系统的未来方向。
本文结构如图1所示,核心内容集中在第四、五节,分别阐述LLM在优化建模和优化求解中的应用。
| Ref. | Venue | LM | LO | LL | HL |
|---|---|---|---|---|---|
| Wu et al. [30] | TEVC, 2024 | ✓ | ✓ | ||
| Huang et al. [31] | SWEVO, 2024 | ✓ | ✓ | ||
| Chao et al. [32] | Research, 2024 | ✓ | |||
| Yu et al. [33] | arXiv, 2024 | ✓ | ✓ | ✓ | |
| Liu et al. [34] | arXiv, 2024 | ✓ | ✓ | ✓ | |
| Ma et al. [35] | TEVC, 2024 | ✓ | ✓ | ||
| 本文 | arXiv, 2025 | ✓ | ✓ | ✓ | ✓ |
相关综述与分类体系
已有多篇综述探讨了LLM在优化领域的应用(如表I所示),但多数侧重于优化的“求解”阶段,对“建模”阶段的关注有限。例如,一些工作从“LLM增强优化”和“优化增强LLM”的双向视角进行回顾,但前者仅限于LLM作为求解器或用于算法生成。其他综述或聚焦于进化算法(EA),或将建模视为次要应用。
与现有工作不同,本文对从“建模”到“求解”的完整工作流进行了系统性回顾,并提出了一个全新的分类体系(Taxonomy)来阐明LLM与优化过程的关系。该体系将该领域分为两大类,后者进一步细分为三个范式:
- LLM用于优化建模 (LLMs for Optimization Modeling):旨在将非结构化的自然语言问题描述自动转化为机器可解释和求解的数学优化模型。这是实现完全由LLM驱动的优化工作流的基础步骤,核心挑战是从模糊的自然语言过渡到精确的数学表述。现有方法主要分为基于提示和基于学习两类。
- LLM用于优化求解 (LLMs for Optimization Solving)
- LLM作为优化器 (LLMs as Optimizers):将LLM本身视为通用优化器,通过迭代式的自然语言交互来解决优化问题,不依赖传统的算法框架。该范式利用LLM的上下文学习和推理能力探索优化轨迹,是连接大模型与优化任务最早、最直接的尝试。
- 用于优化算法的底层LLM (Low-level LLM-assisted Optimization Algorithms):将LLM作为智能组件嵌入传统优化算法(如EA)内部,以增强特定操作,如种群初始化、算子设计、参数控制和适应度评估。这种范式将LLM与成熟的算法框架紧密结合,提升算法核心的效率和解的质量。
- 用于优化算法的高层LLM (High-level LLM-assisted Optimization Algorithms):LLM在顶层扮演协调者角色,而不是作为内部组件。具体分为算法选择(从算法池中为特定问题挑选最合适的算法)和算法生成(自主为特定任务设计新算法)。该范式将LLM的角色从内部助手提升到顶层设计者。
背景知识
由于当前LLM在算法内部组件控制、高层协调和算法生成方面的研究主要集中在进化算法上,本节将介绍相关背景技术。
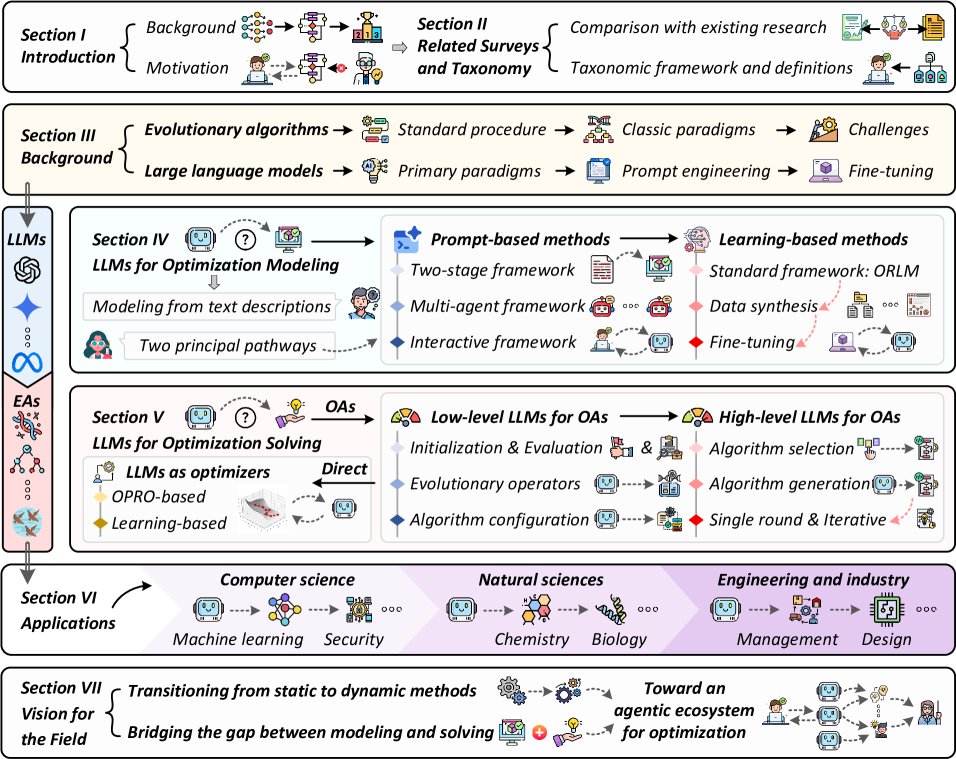
进化算法
进化算法(EA, Evolutionary Algorithms)是一类受生物进化启发的、基于群体的、无梯度的优化方法。如图2所示,EA的基本流程始于初始化一个候选解的种群。在每次迭代中,通过适应度函数评估个体,选择优良个体(父代)通过交叉、变异等遗传算子产生后代。新种群从父代和后代中择优产生。此循环持续至满足终止条件,最终返回性能最佳的个体。
EA已发展出多种经典范式,如遗传算法(GA, Genetic Algorithms)、遗传编程(GP, Genetic Programming)、差分进化(DE, Differential Evolution)和粒子群优化(PSO, Particle Swarm Optimization)。它们虽共享基于群体的迭代框架,但在搜索机制和应用领域上各不相同。相较于传统精确方法,EA在处理非凸、多模态和噪声问题上优势显著。然而,由于“没有免费的午餐”定理,实践者仍需投入大量精力选择、配置或设计合适的EA。
大语言模型
LLM的基础是Transformer架构,其通过自注意力机制捕捉全局的输入-输出依赖关系。基于此架构,形成了三种主要范式:
- 编码器-解码器模型 (如BART, T5):擅长序列到序列任务。
- 仅编码器模型 (如BERT):专注于上下文表示学习以进行语义理解。
- 仅解码器模型 (如ChatGPT, DeepSeek):利用自回归生成处理开放域任务,因其强大的生成和推理能力,在“LLM用于优化”的研究中占主导地位。
LLM的应用主要通过两种途径:提示工程(Prompt Engineering)和微调(Fine-tuning)。
-
提示工程:通过精心设计的指令引导LLM输出,而无需修改模型参数。从早期的零样本(zero-shot)和少样本(few-shot)提示,发展到更高级的结构化推理,如思维链(CoT, Chain-of-Thought)、思维树(ToT, Tree-of-Thought)等。
-
微调:在特定任务数据上更新模型参数,实现更深层次的适应。相关策略包括指令微调(Instruction fine-tuning)和对齐微调(Alignment fine-tuning),后者通过人类反馈强化学习(RLHF, Reinforcement Learning with Human Feedback)或直接偏好优化(DPO, Direct Preference Optimization)等技术,确保模型行为符合人类意图。
LLM用于优化建模
优化建模是优化工作流中的关键一步,传统上高度依赖专家知识。LLM为此带来了自动化的新机遇。
| 方法 | 发表 | 类型 | 技术总结 |
|---|---|---|---|
| 基于提示的方法 | |||
| Ner4OPT [66] | CPAIOR, 2023 | 两阶段 | 通过融合传统NLP方法微调模型进行命名实体识别。 |
| AOMG [67] | GECCO, 2023 | 直接 | 直接利用LLM生成数学模型。 |
| HG 2.0[68] | arXiv, 2023 | 两阶段 | 将LLM嵌入两阶段框架中。 |
| AMGPT [69] | arXiv, 2023 | 两阶段 | B采用微调模型进行约束分类。 |
| CoE [70] | ICLR, 2023 | 多智能体 | 使用11个专家智能体构建动态推理链。 |
| OptiMUS [71] | ICML, 2023 | 多智能体 | 开发一个指挥官智能体来协调建模、编程和评估过程。 |
| MAMS [72] | INFOR, 2024 | 多智能体 | 开发智能体间的交叉验证以取代依赖求解器的验证。 |
| EC [73] | SGC, 2024 | 两阶段 | 将两阶段框架应用于能源管理系统。 |
| CAFA [74] | NeurIPS, 2024 | 两阶段 | 通过基于代码的形式化增强建模性能。 |
| MAMO [75] | NAACL, 2024 | 两阶段 | 开发MAMO基准,并扩展了常微分方程。 |
| NL2OR [76] | arXiv, 2024 | 两阶段 | 预定义抽象结构约束来规范LLM的输出。 |
| TRIP-PAL [77] | arXiv, 2024 | 两阶段 | 将两阶段框架应用于旅行规划。 |
| OptLLM [78] | arXiv, 2024 | 交互式 | 支持单次输入和交互式输入两种模式。 |
| OptiMUS-0.3 [79] | arXiv, 2024 | 多智能体 | 在OptiMUS基础上引入自校正提示和结构感知建模。 |
| MeetMate [80] | TiiS, 2024 | 交互式 | 为用户输入处理开发具有五个可选任务选项的交互式系统。 |
| VL [81] | CUI, 2025 | 交互式 | 在对话交互中将用户优先级转换为优化约束。 |
| LLM-MCTS [82] | arXiv, 2025 | 两阶段 | 在假设空间上进行分层蒙特卡洛树搜索。 |
| EquivaMap [83] | arXiv, 2025 | 两阶段 | 通过LLM生成变量映射函数,并进行轻量级验证。 |
| MAP [84] | arXiv, 2025 | 多智能体 | 部署多个独立审查员来评估建模结果。 |
| ORMind [85] | arXiv, 2025 | 多智能体 | 用结构化、可预测的工作流取代指挥官智能体。 |
| 基于学习的方法 | |||
| LM4OPT [86] | INFOR, 2024 | 微调 | 在NL4OPT数据集上逐步微调模型。 |
| ORLM [27] | OR, 2024 | 数据合成 | 通过扩展和增强合成数据,并微调开源模型。 |
| ReSocratic [87] | ICLR, 2024 | 数据合成 | 提出逆向数据合成方法并构建OPTIBENCH基准。 |
| LLMOPT [88] | ICLR, 2024 | 微调 | 引入模型对齐和自校正机制以缓解幻觉现象。 |
| BPP-Search [89] | arXiv, 2024 | 数据合成 | 解决数据合成中缺少细节的问题。 |
| OptMATH [90] | arXiv, 2025 | 数据合成 | 开发可扩展的双向数据合成方法。 |
| LLMBO [91] | arXiv, 2025 | 微调 | 提出一种微调低成本LLM以解决特定业务挑战的方法。 |
| SIRL [92] | arXiv, 2025 | 微调 | 将外部优化求解器集成为强化学习的可验证奖励验证器。 |
| Step-Opt [93] | arXiv, 2025 | 数据合成 | 通过迭代问题生成方法增加问题复杂性。 |
| DPLM [94] | arXiv, 2025 | 数据合成 | 结合前向生成的多样性和逆向生成的可靠性。 |
| OptiTrust [95] | arXiv, 2025 | 数据合成 | 开发一个可验证的合成数据生成流程。 |
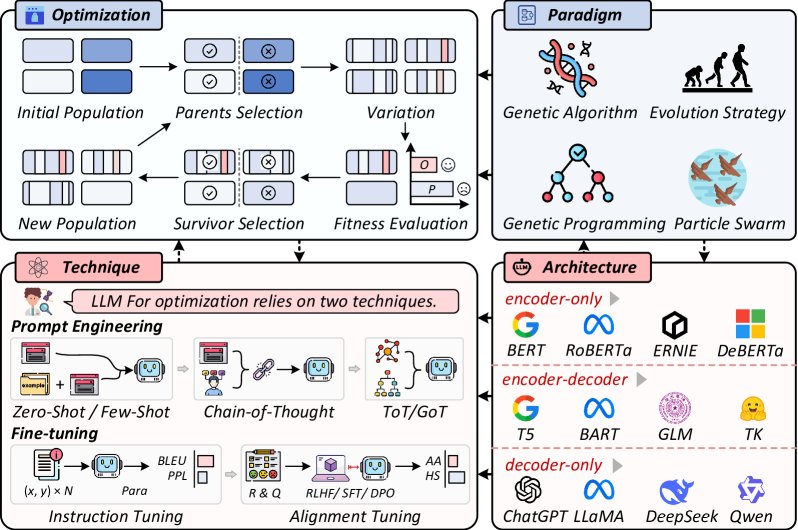
基于提示的方法
早期研究如OptGen [98]首次尝试将自然语言问题描述转换为数学模型,并催生了NL4OPT竞赛。该竞赛将任务分解为两阶段:1)命名实体识别(NER)和2)从标注文本生成完整模型。最初依赖BERT等轻量级模型,随着GPT-3.5等强大LLM的出现,研究者开始尝试直接生成模型的单步方法,但其对于复杂问题的准确性不足。
因此,研究逐渐转向采用LLM进行两阶段建模。例如,Holy Grail 2.0 [68]框架建议使用专用模型进行NER,然后将建模任务分解为实体关系识别、模型形式化和代码生成。这种两阶段方法已成功应用于能源管理[73]、旅行规划[77]等领域。
为进一步提升性能,研究者探索了其他提示范式,其中最具代表性的是多智能体框架和交互式框架。
- 多智能体框架:将建模任务分解为多个专家子任务,由多个LLM协同完成。例如,Chain-of-Experts [70] 初始化了11类专家智能体,由一个指挥官协调。后续工作如OptiMUS [71] 和 ORMind [85] 对协作模式进行了不同探索,前者强调指挥官的审查,后者则采用更结构化、可预测的工作流来提升可靠性。
- 交互式框架:允许用户与模型持续互动,逐步完善问题描述。例如,OptLLM [78] 支持单次和交互式输入,而MeetMeta [80] 系统允许用户在对话中动态增删约束或调整优先级。
随着研究深入,研究者开始针对特定挑战提出解决方案。在模型生成方面,为应对巨大的假设空间,一些工作将LLM与蒙特卡洛树搜索(MCTS)结合以高效探索[82],另一些则通过预定义结构来约束LLM输出[76]。在模型验证方面,MAMO基准[75]被提出用于更广泛的评估,包括常微分方程系统。
尽管基于提示的框架潜力巨大,但其依赖闭源LLM API引发了数据安全和隐私担忧,且模型固有的数学推理能力限制了其性能上限。这些问题推动研究范式向基于学习的方法转变。
基于学习的方法
基于学习的方法通过微调模型参数,将优化建模知识内化到LLM中。早期工作(如LM4OPT [86])通过在现有数据集上微调开源模型提升了建模能力,但与GPT-4等闭源模型仍有差距。
ORLM [27] 框架是一个里程碑,它提出了一种包含扩展和增强的两阶段数据合成策略,系统地为模型微调准备高质量数据。通过该策略,研究者合成了包含自然语言描述、数学模型和可执行代码的结构化数据,并用其微调了一系列开源模型。实验证明,微调后的开源模型性能显著优于单步GPT-4建模和经典的基于提示的方法。
这一“数据合成-模型微调-评估”的工作流被后续研究广泛采纳。
- 在数据合成方面,ReSocratic [87] 提出了逆向合成方法(从数学公式反向生成自然语言描述),OptMATH [90] 开发了可控复杂度的双向数据合成框架。
- 在微调方法方面,一些工作引入多指令微调和自校正机制以缓解“幻觉”现象[88],另一些则将强化学习与外部求解器结合(如SIRL框架[92]),利用求解器作为验证器提供可靠的奖励信号,提升生成内容的真实性。
挑战
- 基于提示的方法:虽然易于部署,但对闭源API的依赖带来了数据安全和隐私风险。此外,即便是最先进的模型(如GPT-4),其数学推理能力的局限性也导致了建模的准确性和鲁棒性问题。
- 基于学习的方法:尽管数据合成为模型微调提供了可能,但如何高效生成高质量、有代表性的数据集以最大化学习效率仍是开放问题。此外,该研究方向尚处早期,需要更广泛的探索来充分发掘其潜力。
LLM用于优化求解
优化求解是工作流的核心阶段,LLM的出现为其注入了新的活力。本节将现有工作分为三大范式。
| 方法 | 发表 | 类型 | 技术总结 |
|---|---|---|---|
| LLM作为优化器 | |||
| OPRO [28] | ICLR, 2023 | 基于提示 | 通过优化轨迹和问题描述进行迭代优化。 |
| toLLM [110] | KDD, 2023 | 基于提示 | 设计四个典型任务来评估LLM的性能边界。 |
| EvoLLM [111] | GECCO, 2024 | 基于提示 | 用候选解质量排名取代传统的优化轨迹。 |
| MLLMO [112] | MCII, 2024 | 基于提示 | 利用多模态LLM联合处理问题描述和地图可视化以解决CVRP问题。 |
| POM [113] | NeurIPS, 2024 | 基于学习 | 预训练一个通用的、零样本黑盒优化基础模型。 |
| OPTO [114] | NeurIPS, 2024 | 基于提示 | 用丰富的、结构化的执行轨迹取代传统的优化轨迹。 |
| VRMA [115] | arXiv, 2024 | 基于提示 | 利用多模态LLM处理二维平面点分布图作为输入。 |
| ROPRO [116] | ACL, 2024 | 基于提示 | 讨论OPRO的模型依赖性并识别其在小规模模型上的局限性。 |
| BBOLLM [29] | arXiv, 2024 | 基于提示 | 对LLM在离散和连续黑盒优化问题上进行评估。 |
| LLMS [117] | arXiv, 2024 | 基于学习 | 用指令-解对微调LLM以解决调度问题。 |
| ECLIPSE [118] | NAACL, 2024 | 基于提示 | 将迭代优化应用于越狱攻击策略。 |
| LLOME [119] | arXiv, 2024 | 基于学习 | 整合偏好学习来训练LLM以满足复杂的生物物理约束。 |
| LLMDSM [120] | arXiv, 2024 | 基于提示 | 将迭代优化应用于设计结构矩阵排序。 |
| LMCO [121] | WCL, 2024 | 基于提示 | 将迭代优化应用于无线网络设计。 |
| MGSCO [122] | arXiv, 2025 | 基于提示 | 使用多模态LLM处理抽象图结构的可视化表示。 |
| ORFS [123] | arXiv, 2025 | 基于提示 | 将迭代优化应用于芯片设计中的自动参数调优。 |
| 用于优化算法的底层LLM | |||
| LMX [124] | TELO, 2023 | 算子 | 利用LLM作为智能算子进行文本基因组的交叉和重组。 |
| GPT-NAS [125] | arXiv, 2023 | 初始化 | 利用LLM进行带有先验知识的NAS初始化。 |
| LMEA [126] | CEC, 2023 | 算子 | 使用LLM作为交叉、变异和选择算子来指导EA。 |
| LLM-PP [127] | arXiv, 2023 | 初始化 | 利用LLM作为性能预测器来辅助初始化过程。 |
| LMOEA [128] | EMO, 2023 | 算子 | 通过零样本提示将LLM作为搜索算子赋能MOEA/D以解决多目标优化问题。 |
| OFPLLM [129] | AI, 2023 | 初始化 | 辅助非专业用户初始化金融问题。 |
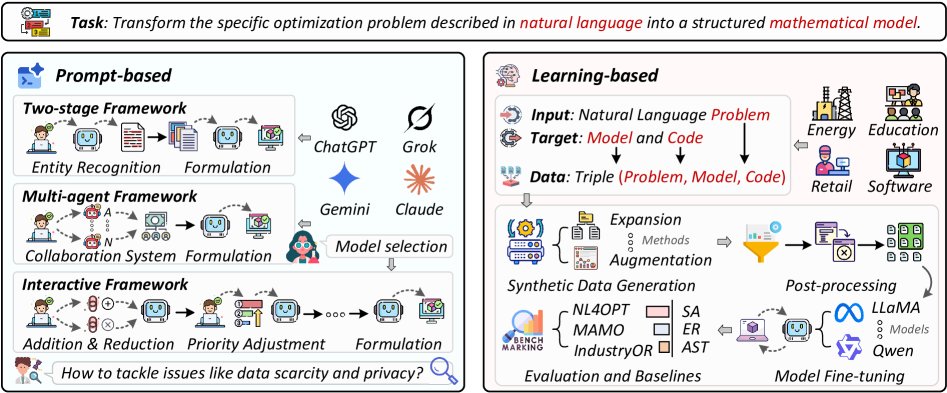
LLM作为优化器
在此范式中,LLM直接作为通用优化器,通过自然语言交互迭代求解问题(如图4)。OPRO [28] 是一个代表性工作,它通过向LLM提供包含问题描述和过往优化轨迹的提示,让LLM迭代地生成新的候选解或优化指令。这种方法已被应用于各种任务,如越狱攻击策略[118]和芯片设计中的参数调优[123]。后续研究对该范式进行了改进,例如EvoLLM [111] 用候选解的质量排名信息取代完整的优化轨迹,以简化提示内容。此外,多模态LLM(MLLM)也被用于处理包含视觉信息的问题,如车辆路径问题(CVRP)[112]。
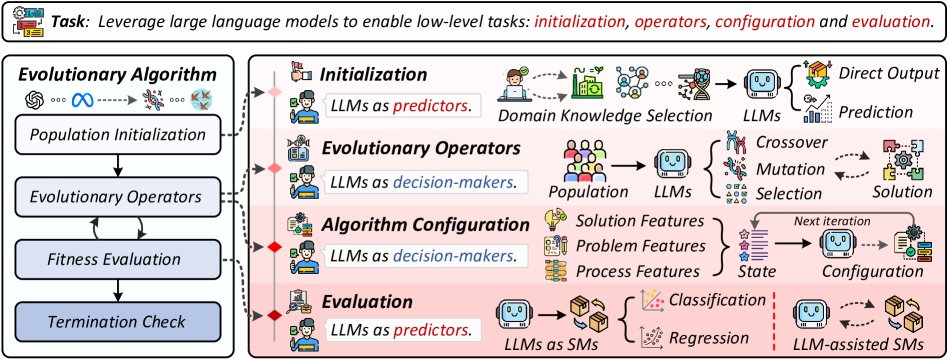
用于优化算法的底层LLM
该范式将LLM作为智能组件嵌入传统优化算法中,以增强特定算子或流程(如图5)。这与将LLM作为独立优化器不同,它旨在将LLM的分析能力和领域知识与成熟的算法框架(如EA)紧密集成。典型应用包括:
- 种群初始化:利用LLM的先验知识生成高质量的初始解,如在神经架构搜索(NAS)中的应用[125]。
- 算子设计:将LLM用作智能的交叉、变异或选择算子,以指导进化过程[126]。例如,LMX [124] 利用LLM对文本基因组进行交叉和重组。
- 参数控制与适应度评估等。
通过赋能传统组件,使其能更智能地适应不同问题特性和搜索状态,该范式在算法核心层面提升了效率和解的质量。
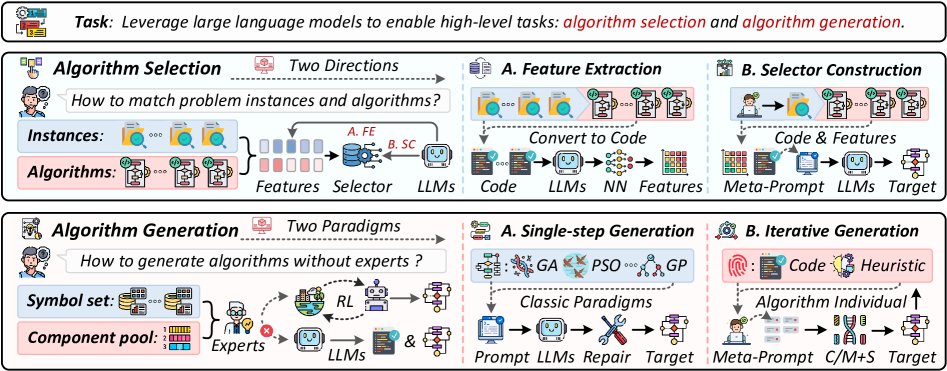
用于优化算法的高层LLM
该范式关注顶层协调,而非内部组件,主要分为算法选择和算法生成两类(如图6)。
- 算法选择:利用LLM分析问题实例的特征,从一个算法库中选择最适合的算法。
- 算法生成:让LLM更进一步,根据特定任务自主设计全新的算法。
这种方法赋予LLM对整个优化工作流的全局视角,将其角色从内部辅助者提升为顶层架构师。
挑战
LLM在优化求解中的应用同样面临挑战。
- 作为优化器:性能常不及专门设计的经典算法[29],且可扩展性受限。
- 作为算法组件:如何有效、高效地将LLM的语义推理能力与传统算法的数值计算相结合是一个核心难题。
- 高层设计:如何确保LLM生成的算法在理论上是可靠的,并且在实践中是高效的,仍需深入研究。