Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents
-
ArXiv URL: http://arxiv.org/abs/2510.24702v1
-
作者: Tianbao Xie; Tao Yu; Zhihao Yuan; Xiang Yue; Graham Neubig; Xingyao Wang; Shuyan Zhou; Huan Sun; Tianyue Ou; Ziru Chen; 等19人
-
发布机构: All Hands AI; Carnegie Mellon University; Duke University; Fujitsu; The Ohio State University; University of Hong Kong
TL;DR
本文提出了一种名为智能体数据协议 (Agent Data Protocol, ADP) 的轻量级表示语言,它通过将来自不同来源、格式各异的智能体训练数据统一为标准模式,解决了数据碎片化问题,从而实现了对大型语言模型智能体进行大规模、多样化且高效的监督式微调。
关键定义
本文的核心是提出了一套用于统一智能体数据的协议和架构。关键定义如下:
-
智能体数据协议 (Agent Data Protocol, ADP):一种轻量级的表示语言和数据模式,旨在作为异构智能体数据集和下游统一训练流程之间的“中间语”。它通过提供一个标准化的结构来表示智能体的交互轨迹,解决了数据格式不一致的问题。
-
轨迹 (Trajectory):ADP 中用于表示一次完整智能体交互的基本单位。一个 \(Trajectory\) 对象包含交互的核心序列,即一系列交替出现的 \(Action\) 和 \(Observation\)。
- 动作 (Action):代表智能体在环境中做出的决策和行为。ADP 将其分为三类:
- API 动作 (API Action):用于表示对工具或 API 的函数调用,如网页浏览 \(click(element_id)\)。
- 代码动作 (Code Action):用于表示代码的生成和执行,支持多种编程语言。
- 消息动作 (Message Action):用于表示智能体与用户之间的自然语言交流。
- 观察 (Observation):代表智能体从环境(或用户)接收到的感知信息和反馈。ADP 将其分为两类:
- 文本观察 (Text Observation):捕获来自用户指令或环境反馈(如代码执行结果)的文本信息。
- 网页观察 (Web Observation):专门用于表示网页的状态和内容,包括 HTML、无障碍树、URL 等信息。
相关工作
当前,基于大型语言模型(LLM)的智能体研究依赖于高质量的训练数据,这些数据需要捕捉多步推理、工具使用和环境交互的复杂性。数据的收集方法多种多样,包括人工创建、合成生成和记录智能体部署轨迹等。这些方法已经催生了大量涵盖编码、软件工程、工具使用和网页浏览等任务的数据集。
然而,尽管数据源丰富,但大型语言模型的智能体监督式微调(SFT)在学术研究中仍然很少见。其关键瓶颈在于数据碎片化:
- 格式不一致:现有的智能体训练数据集大多采用自定义的表示格式、动作空间和观察结构,导致数据集之间互不兼容。
- 集成成本高:研究人员若想结合多个数据集进行训练,需要为每个数据集和每个智能体框架编写特定的数据转换脚本,工程量巨大且难以维护。
- 缺乏系统性分析:数据格式的混乱使得跨数据集的量化分析和比较变得异常困难,阻碍了对数据质量和覆盖范围的深入理解。
本文旨在解决上述数据碎片化和标准化缺失的问题,通过提出一个统一的数据协议来打通不同数据集与训练框架之间的壁垒。
本文方法
为解决数据碎片化问题,本文提出了智能体数据协议(ADP),一个旨在统一异构智能体训练数据的标准模式。
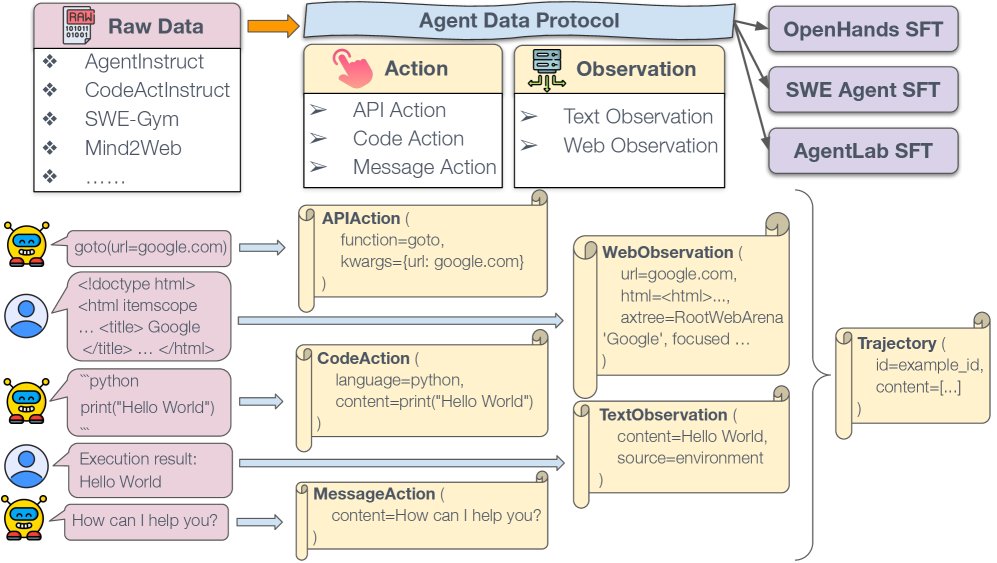 ADP概览。来自AgentInstruct、CodeActInstruct、SWE-Gym和Mind2Web等不同来源的原始数据被转换为标准化的ADP格式。ADP将数据统一为Trajectory对象,包括两个核心组件:动作(API动作、代码动作、消息动作)和观察(文本观察、网页观察)。这种标准化表示使得与各种智能体SFT流程的无缝集成成为可能。
ADP概览。来自AgentInstruct、CodeActInstruct、SWE-Gym和Mind2Web等不同来源的原始数据被转换为标准化的ADP格式。ADP将数据统一为Trajectory对象,包括两个核心组件:动作(API动作、代码动作、消息动作)和观察(文本观察、网页观察)。这种标准化表示使得与各种智能体SFT流程的无缝集成成为可能。
设计原则
ADP的设计遵循三大核心原则:
- 简洁性 (Simplicity):ADP 采用简单直观的结构,消除了针对每个数据集进行专门工程改造的需要,降低了大规模数据利用的门槛。
- 普适性 (Universality):ADP 提供了一个统一的表示方法,能够将各种格式的现有智能体数据集标准化,解决了数据格式碎片化的问题。
- 表达性 (Expressiveness):ADP 的设计确保了复杂的智能体交互轨迹可以被准确无误地表达,同时不丢失关键信息,使其能覆盖编码、浏览、工具使用等不同领域的任务。
架构
ADP 的核心是将智能体的交互过程抽象为一个 \(Trajectory\) 对象,该对象由一个交替出现的动作 (Action) 和观察 (Observation) 序列构成。
- 动作 (Actions) 被细分为三种类型:
- \(APIAction\):捕捉工具使用,如 \(click("button_id")\)。
- \(CodeAction\):处理代码生成与执行,如执行一段 Python 代码。
- \(MessageAction\):记录与用户的自然语言对话。
- 观察 (Observations) 被细分为两种类型:
- \(TextObservation\):记录来自用户或环境的文本反馈,如代码执行的输出。
- \(WebObservation\):专门用于网页任务,捕捉页面的 HTML、无障碍树、URL 等丰富信息。
这种“动作-观察”的抽象是 ADP 的核心洞见。它抓住了智能体交互的本质,即在环境中执行动作并接收反馈。通过对这些基本单元进行标准化,ADP 能够在保留原始数据丰富语义的同时,将原本不兼容的数据集整合起来。
转换流程
为了将 ADP 应用于实践,本文设计了一个三阶段的转换流程:
- 原始数据到 ADP (Raw→ADP):此阶段将各种异构的原始数据集转换为统一的 ADP 格式。开发者只需为每个新数据集编写一个转换脚本,将其特有的动作和观察映射到 ADP 的标准空间。
- ADP 到 SFT 格式 (ADP→SFT):此阶段将标准化的 ADP 轨迹数据转换为特定智能体框架所需的监督式微调(SFT)格式。每个智能体框架(如 OpenHands, SWE-Agent)因其架构和工具接口的不同,需要不同的训练数据格式。开发者只需为自己的智能体框架编写一个从 ADP 到 SFT 的转换脚本。
- 验证 (Validation):通过自动化检查来确保数据的正确性和一致性,例如验证工具调用格式、对话结构等,以保证训练数据的高质量。
创新点
ADP 最核心的创新在于引入了一个“中间语”,从而极大地降低了数据整合的工程复杂度。
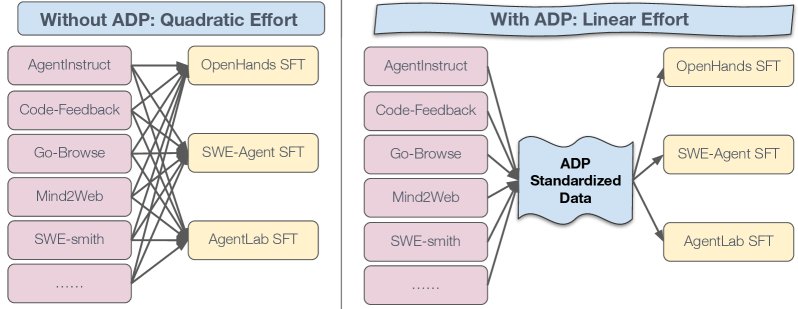
- 左图 (无 ADP):在没有 ADP 的情况下,对于 \(D\) 个数据集和 \(A\) 个智能体框架,研究者需要编写 \(D * A\) 个独立的转换脚本,工程量是二次方级别 \(O(D×A)\)。
- 右图 (有 ADP):有了 ADP,每个数据集只需要一个 Raw→ADP 转换器,每个智能体框架也只需要一个 ADP→SFT 转换器。总工程量降低为线性级别 \(O(D+A)\)。
这一转变使得新的数据集可以被社区内所有支持 ADP 的智能体框架即时使用,而新的智能体框架也可以立刻利用所有已转换为 ADP 格式的数据。这种模式摊销了数据转换的成本,加速了整个社区的研究迭代速度。
实验结论
本文通过在多个基准测试上的实验,验证了 ADP 在提升智能体模型性能和简化开发流程方面的有效性。
跨数据集分析
通过将13个不同的数据集转换为ADP格式,本文进行了统一的量化分析,揭示了不同任务领域数据的特性。
| 数据集 | 平均轮次 | 动作分布 (API/代码/消息 %) | 思维覆盖率 (%) |
|---|---|---|---|
| AgentInstruct | 8.2 | 64/10/26 | 100.0 |
| Code-Feedback | 4.0 | 0/58/42 | 82.8 |
| CodeActInstruct | 4.0 | 0/65/35 | 98.6 |
| Go-Browse | 3.9 | 70/0/30 | 100.0 |
| Mind2Web | 9.7 | 90/0/10 | 0.0 |
| Nebius SWE-Agent… | 16.2 | 67/27/6 | 100.0 |
| NNetNav | 8.2 | 80/0/20 | 99.9 |
| openhands-feedback | 10.1 | 89/0/11 | 99.9 |
| Orca AgentInstruct | 18.3 | 11/73/16 | 91.7 |
| SWE-Gym | 1.3 | 0/15/85 | 84.0 |
| SWE-smith | 19.7 | 61/25/14 | 42.0 |
| Synatra | 26.8 | 56/40/4 | 90.1 |
| WebArena | 1.0 | 100/0/0 | 99.9 |
分析显示:
- 交互长度差异大:软件工程(SWE)任务的交互轮次显著更长。
- 动作分布与领域相关:网页浏览数据集严重依赖 API 动作,而编码数据集则以代码动作为主。
- 普遍存在“思考”过程:大多数数据集都包含了智能体对其行为的解释(Thought Coverage),这对训练具有可解释性的模型至关重要。
ADP数据显著提升智能体性能
实验结果表明,使用 ADP 统一后的数据集进行训练,能够大幅提升模型在多个领域的性能,平均增益约20%。
| SOTA 与本文 7-8B 模型对比 | SWE-Bench Verified | WebArena | AgentBench | GAIA |
|---|---|---|---|---|
| SOTA (其它模型) | Claude 3.5 Sonnet: 33.6 | GPT-4o: 18.6 | GPT-4o: 24.1 | GPT-4o: 30.1 |
| 本文ADP训练模型 | Qwen2.5-7B (OH): 20.4 | Qwen2.5-7B (AL): 21.0 | Qwen3-8B (OH): 27.1 | Qwen2.5-7B (OH): 9.1 |
| SOTA 与本文 13-14B 模型对比 | SWE-Bench Verified | WebArena | AgentBench | GAIA |
|---|---|---|---|---|
| SOTA (其它模型) | Claude 3.5 Sonnet: 33.6 | GPT-4o: 18.6 | GPT-4o: 24.1 | GPT-4o: 30.1 |
| 本文ADP训练模型 | Qwen3-14B (SA): 34.4 | Qwen3-14B (AL): 22.2 | Qwen3-14B (OH): 20.8 | - |
| SOTA 与本文 32B 模型对比 | SWE-Bench Verified | WebArena | AgentBench | GAIA |
|---|---|---|---|---|
| SOTA (其它模型) | Claude 3.5 Sonnet: 33.6 | GPT-4o: 18.6 | GPT-4o: 24.1 | GPT-4o: 30.1 |
| 本文ADP训练模型 | Qwen3-32B (SA): 40.3 | Qwen3-32B (AL): 22.9 | Qwen3-32B (OH): 34.7 | - |
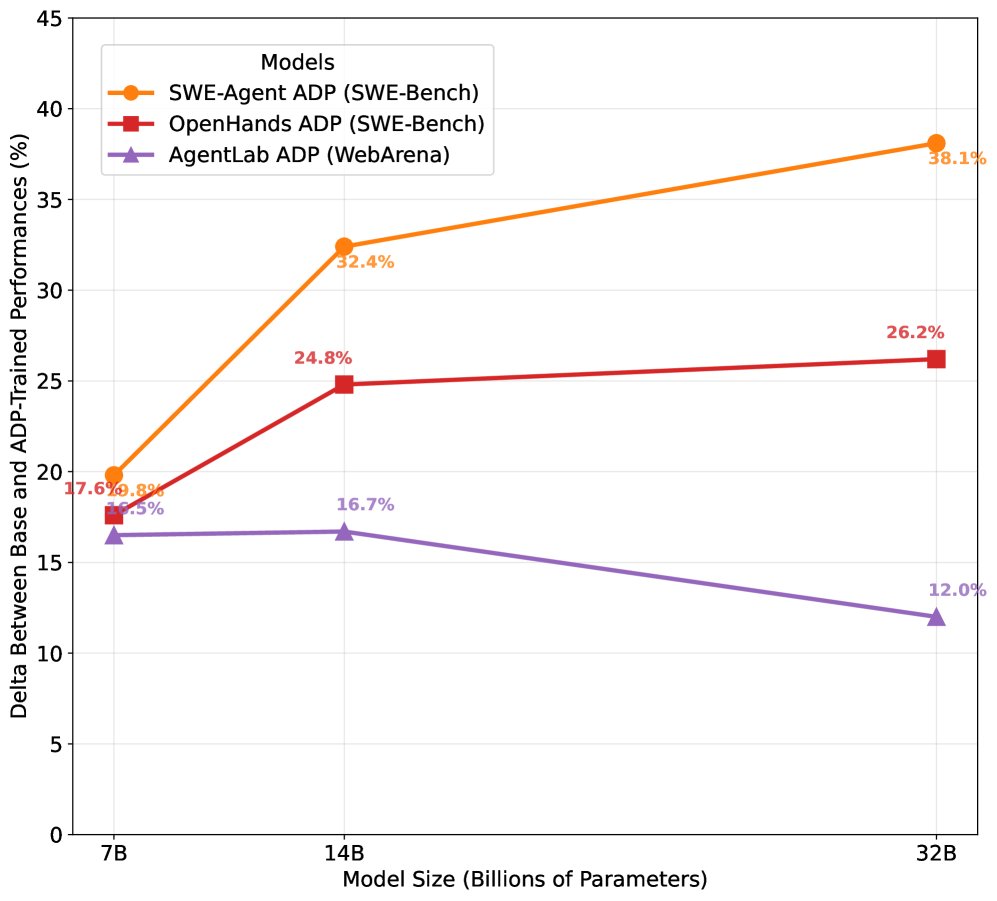
- 在 SWE-Bench(软件工程)上,7B 模型性能从 0.4% 跃升至 20.2%,32B 模型达到 40.3%,超越了 Claude 3.5 Sonnet。
- 在 WebArena(网页浏览)和 AgentBench(通用工具)上,各尺寸模型均取得稳定且显著的性能提升。
- 随着模型规模的增长(从 7B 到 32B),ADP 带来的性能增益持续存在,证明了该方法的普适性和可扩展性。

多样化数据带来跨任务迁移能力
实验证明,使用混合了多个领域的 ADP 数据集进行训练,比仅使用特定领域的单个数据集效果更好。
| 基准测试 | 智能体框架 | 仅使用特定领域数据训练 | 使用混合的ADP数据训练 |
|---|---|---|---|
| SWE-Bench | SWE-Agent | 1.0% | 10.4% |
| SWE-Bench | OpenHands | 11.0% | 13.2% |
| WebArena | AgentLab | 16.0% | 18.7% |
| AgentBench | OpenHands | 21.5% | 24.5% |
| GAIA | AgentLab | 0.6% | 2.5% |
例如,在 SWE-Bench 任务上,使用混合的 ADP 数据训练的模型达到了 10.4% 的准确率,远高于仅使用 SWE-smith 数据集训练的 1.0%。这表明数据多样性促进了模型的跨任务泛化能力。
ADP简化了对新智能体框架的适配
ADP 将数据适配的工程量从 \(O(D×A)\) 降至 \(O(D+A)\)。本文通过代码行数(LOC)进行了量化说明:
- Raw→ADP:将 13 个数据集转换为 ADP 格式,总共需要约 4892 行代码。
- ADP→SFT:将 ADP 数据转换为 3 个不同的智能体框架格式,平均每个框架仅需约 77 行代码。
| 智能体框架 | 总 LOC |
|---|---|
| OpenHands CodeActAgent | ~150 |
| SWE-Agent | ~50 |
| AgentLab | ~30 |
| 平均 | ~77 |
在没有 ADP 的情况下,若要支持 100 个智能体框架,社区总工程量约为 \(4892 * 100 = 489,200\) LOC。而采用 ADP 后,总工程量约为 \(4892 + 77 * 100 = 12,592\) LOC,减少了超过 97% 的重复工作。这极大地降低了新智能体框架接入现有数据生态的门槛。
总结
ADP 通过建立一个统一的数据“中间语”,成功地将碎片化的智能体数据生态整合为一个可扩展的训练流程。实验证明,这种方法不仅大幅提升了模型在编码、浏览和工具使用等多个领域的性能,还通过促进数据多样性增强了模型的泛化能力,并显著降低了社区的开发和维护成本。
未来的工作方向包括将 ADP 扩展到多模态数据、统一评估和环境设置,以及持续开源共建,以催化智能体训练领域的下一波发展。