AgentFold: Long-Horizon Web Agents with Proactive Context Management
-
ArXiv URL: http://arxiv.org/abs/2510.24699v1
-
作者: Zhengwei Tao; Yong Jiang; Pengjun Xie; Rui Ye; Huifeng Yin; Jingren Zhou; Kuan Li; Siheng Chen; Zhongwang Zhang; Fei Huang; 等15人
-
发布机构: Alibaba Group; Tongyi Lab
TL;DR
本文提出了一种名为 AgentFold 的新型网页智能体,它通过模仿人类主动管理心智暂存区的方式,在执行长时程任务时对上下文进行主动“折叠”和整合,从而在保持上下文简洁性的同时避免关键信息丢失,并以较小的模型规模实现了顶尖的性能。
关键定义
本文沿用了现有智能体的基础概念,并引入了以下几个核心定义来构建其方法:
- 上下文折叠 (Context Folding):AgentFold 的核心机制,指智能体在执行任务过程中主动对历史信息进行总结和压缩。它包含两种操作模式:
- 粒度压缩 (Granular Condensation):将最近一次交互的完整记录压缩成一个简洁的摘要块,以保留精细信息。
- 深度整合 (Deep Consolidation):将最近的交互与之前的一系列摘要块融合,形成一个更高层次、更粗粒度的摘要,适用于一个子任务完成后总结其最终结论。
-
多尺度状态摘要 (Multi-scale State Summaries):作为智能体的长时记忆,这是一个由多个摘要块组成的有序序列。每个摘要块 \(s_{x,y}\) 记录了从第 \(x\) 步到第 \(y\) 步的交互摘要,其粒度可变,从而能以不同尺度保存历史信息。
-
最新交互 (Latest Interaction):作为智能体的高保真工作记忆,它完整、无损地记录了最近一次的交互,包括智能体的简要思考(解释)、执行的工具调用以及环境返回的观察结果。
- Fold-Generator: 本文为训练 AgentFold 而专门开发的自动化数据收集流程。由于现有数据集无法满足训练需求,该流程利用强大的大语言模型,通过一系列拒绝采样机制,生成包含高质量上下文管理操作的训练轨迹。
相关工作
当前的网页智能体研究主要构建于 ReAct 范式之上,即在一个“推理-行动-观察”的循环中与环境交互。然而,这种模式在处理长时程任务时面临一个关键瓶颈:上下文管理策略的权衡困境。
- 现状与瓶颈:
- 纯追加(Append-Only)策略:以 ReAct 为代表的方法将所有历史交互记录完整地保留在上下文中。这种方式虽然保证了信息的完整性,但随着任务变长,上下文会迅速被原始网页数据中的噪声填满,导致智能体难以识别关键信号,做出次优决策。
- 全量总结(Full-History Summarization)策略:一些新方法在每一步都对整个历史进行总结,以保持上下文的整洁。然而,这种机械式的压缩策略存在巨大风险,即在任何一次总结中都可能过早地、不可逆地丢失关键细节,导致“灾难性遗忘”。
- 本文旨在解决的问题: 本文旨在解决上述“保留冗余噪声”与“冒信息丢失风险”之间的尖锐矛盾。目标是设计一种能够像人类一样主动管理其认知工作区(上下文)的智能体,使其能够在长时程任务中既能保持上下文的重点突出和简洁高效,又能避免关键信息的意外丢失。
本文方法
概述
AgentFold 模仿人类的认知过程,其核心设计在于将智能体的上下文定义为一个动态的认知工作区,并赋予智能体主动管理和塑造该工作区作为其核心推理能力的一部分。
AgentFold 的工作区主要由三部分构成:固定的用户问题、经过整理的多尺度状态摘要 (Multi-scale State Summaries)(作为长期记忆),以及高保真的最新交互 (Latest Interaction)(作为即时工作记忆)。在每个迭代步骤中,智能体的推理会产生一个多部分响应,包括一个用于管理历史摘要的折叠指令 (folding directive)、对其思维过程的解释以及下一步的行动。折叠指令会立即更新长期记忆,而行动所产生的观察结果则与行动本身一起,构成下一个周期的“最新交互”。这个循环将上下文管理从一个被动的副产品转变为一个主动、可学习的核心步骤,解决了在保留细节和防止上下文膨胀之间的矛盾。
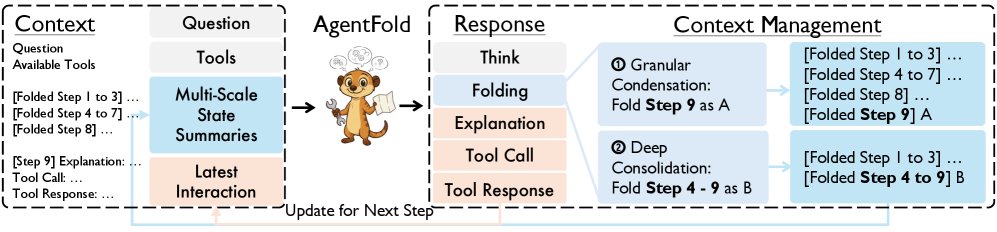 AgentFold 在一个中间步骤的概览。AgentFold 上下文中的两个关键部分是:多尺度状态摘要(记录先前信息的多个折叠块)和最新交互(最近一步的完整记录)。AgentFold 以四个块作为响应:思考、折叠、解释和工具调用(这会带来一个附加的工具响应)。折叠指令有两种操作模式:粒度压缩(保留有用信息,折叠单步)和深度整合(当这些步骤完成一个子任务并且中间细节对于进一步解决任务不重要时,用一个粗略的总结折叠多个步骤)。
AgentFold 在一个中间步骤的概览。AgentFold 上下文中的两个关键部分是:多尺度状态摘要(记录先前信息的多个折叠块)和最新交互(最近一步的完整记录)。AgentFold 以四个块作为响应:思考、折叠、解释和工具调用(这会带来一个附加的工具响应)。折叠指令有两种操作模式:粒度压缩(保留有用信息,折叠单步)和深度整合(当这些步骤完成一个子任务并且中间细节对于进一步解决任务不重要时,用一个粗略的总结折叠多个步骤)。
AgentFold 的上下文:多尺度状态摘要与最新交互
AgentFold 的上下文被精心设计为一个包含四个部分的动态认知工作区,以支持战略性的长远规划和精确的即时行动。
- 问题 (Question):作为任务的锚点,持续提醒智能体的最终目标。
- 可用工具 (Available Tools):定义了智能体在环境中的行动能力,列出所有工具的名称、描述和参数。
- 多尺度状态摘要 (Multi-scale State Summaries):作为智能体 curated 的长期记忆。它以不同粒度保存历史步骤,关键发现可以作为独立的精细摘要保留,而不太重要的中间步骤则可以被整合成更粗略的抽象块。
- 最新交互 (Latest Interaction):作为高保真的工作记忆,提供最近一次交互的完整记录,包括解释、工具调用和观察结果。
在第 \(t\) 步,提供给智能体的上下文 \(C_t\) 是一个三元组:
\[C_{t}=(Q,T,S_{t-2},I_{t-1})\]其中 \($Q\)$ 和 \($T\)$ 是不变的用户问题和工具列表。\($S\_{t-2}\)$ 是多尺度状态摘要,一个动态更新的过往步骤压缩摘要序列,表示为 \($S\_{t-2}=(s\_{x\_1,y\_1}, s\_{x\_2,y\_2}, \ldots, s\_{x\_m,y\_m})\)$,其中每个 \($s\_{x,y}\)$ 是对第 \($x\)$ 到 \($y\)$ 步连续交互的文本摘要。\($I\_{t-1}\)$ 是最新交互,即第 \($t-1\)$ 步的完整交互记录,\($I\_{t-1}=(e\_{t-1}, a\_{t-1}, o\_{t-1})\)$。
这种结构化设计两全其美:最新交互提供了做出短期决策所需的无损原始细节,而多尺度状态摘要则提供了一个无噪声、抽象化的任务概览,使智能体能够进行连贯的长期推理,从而直接缓解了现代网页智能体在上下文全面性与简洁性之间的权衡难题。
AgentFold 的响应:思考、折叠、解释、行动
在每一步,AgentFold 生成一个结构化的多部分文本响应 \($R\_t\)$,该响应可被解析为一个四元组:
\[R_{t}=\text{AgentFold}(C_{t};\theta)\rightarrow(th_{t},f_{t},e_{t},a_{t})\]-
思考 (Thinking, \($th\_t\)$): 一个详细的思维链独白,智能体在此分析上下文并权衡上下文折叠和后续行动的选项。
- 折叠 (Folding, \($f\_t\)$): 智能体用于塑造其长期记忆的明确指令,采用 JSON 格式 \($f\_t = \{\text{"range": [k, t-1], "summary": "}\sigma\_t\text{"}\}\)$。\($k\)$ 是折叠的起始步骤ID,\($\sigma\_t\)$ 是智能体生成的替换摘要。该指令支持两种操作模式:
- 粒度压缩 (Granular Condensation) (\($k = t-1\)$):仅折叠最新交互,将其转化为一个新的、细粒度的摘要块。这用于增量步骤,保留历史轨迹的最高分辨率。
- 深度整合 (Deep Consolidation) (\($k < t-1\)$):将最新交互与先前的一系列摘要融合为一个粗粒度的摘要。当一个子任务(例如,经过多步验证一个事实)完成后,此操作可以将整个过程抽象为最终结论,从而清除中间步骤的噪声。
-
解释 (Explanation, \($e\_t\)$): 从思考过程中提炼出的对所选行动动机的简明阐述。
- 行动 (Action, \($a\_t\)$): 智能体选择的外部行动,可以是工具调用,也可以是最终答案。
这个响应结构将行动规划与上下文管理紧密耦合,形成一个自调节循环:规划行动需要回顾历史,这为决定保留哪些信息提供了信号;而整理历史则能加深对当前状态的理解,从而做出更有效的行动决策。
AgentFold 的训练:数据轨迹收集
为了训练 AgentFold,本文开发了 Fold-Generator,一个专门的数据收集流程,用于生成带有复杂上下文管理操作的训练轨迹。鉴于即便是最先进的 LLM 也难以通过简单的提示工程可靠地生成 AgentFold 所需的结构化多部分响应,该流程采用了一套拒绝采样机制 (rejection sampling mechanism),丢弃格式错误或包含过多环境错误的轨迹,以确保数据质量。
最终,Fold-Generator 生成一个高质量的交互对集合 \($\{(C\_t, R\_t^\*)\}\_N\)$,用于对开源 LLM 进行监督微调 (Supervised Fine-Tuning, SFT)。这种训练方法将复杂的“生成-过滤”策略内化到 AgentFold 模型的权重中,使其从一种脆弱的、依赖提示的指令,转变为一种强大、内化的技能,并显著提高了推理效率。
讨论
AgentFold 的设计克服了 ReAct 模式(导致上下文饱和)和全历史摘要(有信息丢失风险)的局限性。其核心优势在于能够根据任务需求灵活调整折叠策略。
例如,一个关键细节在每轮全历史摘要中幸存的概率若为 99%,在 100 步后其完整保留的概率仅为 \($0.99^{100} \approx 36.6\%\)$,在 500 步后更是骤降至 \($0.99^{500} \approx 0.6\%\)$。AgentFold 通过粒度压缩将此细节保留在一个独立的摘要块中,使其免于不必要的重复处理,从而规避了这种复合风险。同时,通过深度整合,AgentFold 能够像外科手术般精确地剪除已完成子任务的繁琐过程,解决了 ReAct 模式中不可避免的上下文膨胀问题。
这种将上下文管理作为可学习核心动作的设计,使 AgentFold 成为其自身信息工作区的主动管理者 (active curator),实现了在长时程复杂任务中鲁棒性与效率的显著提升。
实验结论
实验基于 Qwen3-30B-A3B-Instruct-2507 模型进行训练,并在四个基准上进行了评估:BrowseComp、BrowseComp-ZH(评估信息定位能力)、WideSearch(评估广泛搜索能力)和 GAIA(评估通用智能体能力)。
结果与分析
| 模型 | 参数 | BrowseComp | BrowseComp-ZH | WideSearch F1 | GAIA |
|---|---|---|---|---|---|
| Proprietary Agents | |||||
| OpenAI Deep Research | - | 42.1 | 42.0 | 56.6 | 21.0 |
| Claude-4-Opus | - | - | - | 61.1 | 51.5 |
| OpenAI-o3 | - | 36.7 | 42.0 | 66.8 | 64.9 |
| Claude-4-Sonnet | - | 35.8 | 38.0 | 66.8 | 49.6 |
| OpenAI-o4-mini | - | 37.1 | - | 60.1 | 43.1 |
| Open-Source Agents | |||||
| WebExplorer | 7B | 25.8 | 29.5 | 45.4 | 4.6 |
| DeepDive | 13B | 24.3 | - | - | 13.9 |
| WebDancer | 13B | 18.2 | 19.3 | 47.7 | 2.5 |
| DeepDiver-V2 | 22B | 31.8 | - | - | 19.0 |
| Kimi-K2-Instruct | 32B | 30.0 | - | 60.0 | 20.0 |
| MiroThinker-70B | 70B | 32.7 | 34.0 | 54.9 | 15.6 |
| GLM-4.5-355B-A32B | 355B | 33.3 | 36.0 | 62.7 | 45.4 |
| DeepSeek-V3.1-671B-A37B | 671B | 30.0 | 34.0 | 52.3 | 61.3 |
| AgentFold-30B-A3B (本文) | 30B | 37.6 | 39.0 | 67.0 | 43.1 |
上表结果显示,AgentFold-30B-A3B 确立了开源智能体的新 SOTA,并且与顶尖的闭源系统表现出强大的竞争力。
- 超越大模型:在 BrowseComp 数据集上,AgentFold (37.6%) 显著超过了体量是其 20 多倍的 DeepSeek-V3.1-671B (30.0%),证明了先进的上下文管理架构可以弥补模型规模上的巨大差距。
- 顶级性能:在 WideSearch 基准上,AgentFold 取得了 67.0% 的最高分,超越了包括 OpenAI-o3 和 Claude-4-Sonnet 在内的所有闭源智能体。
上下文效率分析
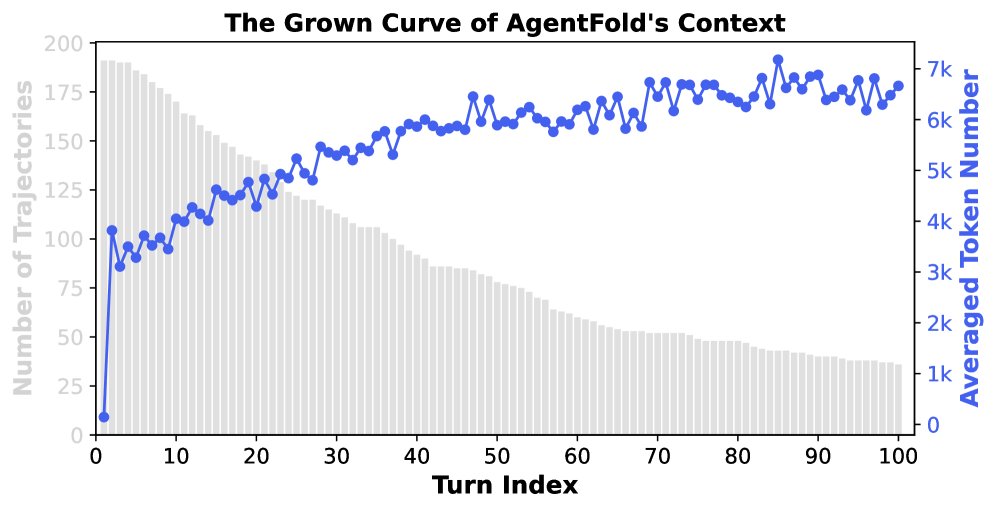
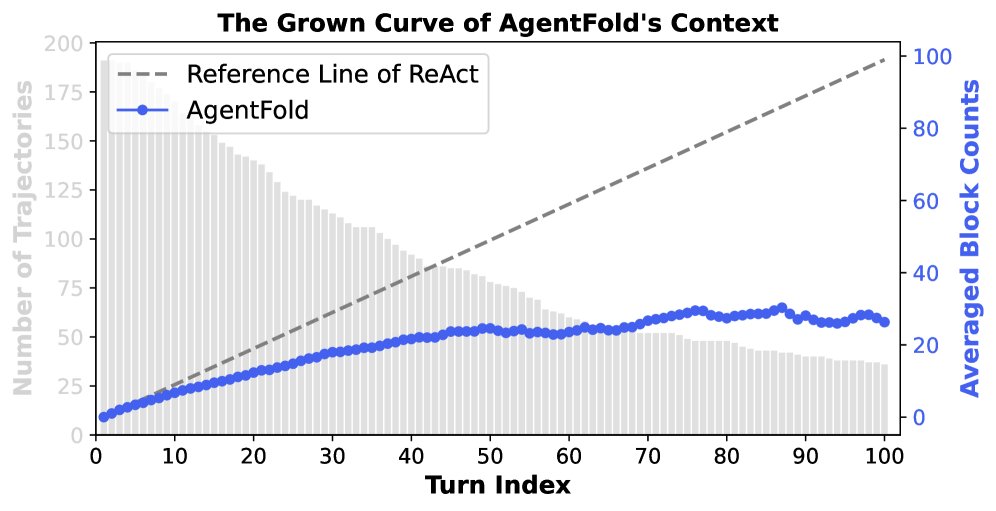
对 BrowseComp 基准测试中轨迹的分析进一步验证了 AgentFold 的上下文管理效率。
- 极度紧凑的上下文(左图):AgentFold 的上下文长度以极慢的亚线性速率增长,在 100 轮交互后,平均 token 数从约 3.5k 增长到 7k,远未达到模型 128k 的上下文窗口上限。这证明了“折叠”操作在防止上下文膨胀方面的有效性。实验中超过 20% 的任务因达到 100 步上限而被强制终止,而此时上下文仅占用极小部分,这表明 AgentFold 在处理更长、更复杂的任务上具有巨大潜力。
- 结构简洁(右图):与上下文块数随步数线性增长的 ReAct 相比,AgentFold 的块数增长同样呈亚线性。这得益于深度整合操作,它将多个历史步骤合并为单个摘要,保持了上下文在结构上的简洁和认知上的易管理性。
最终结论
实验结果有力地证明了 AgentFold 范式的有效性。通过引入主动的、智能的上下文折叠机制,AgentFold 成功解决了长时程任务中的上下文管理难题。它不仅在多个关键基准上取得了 SOTA 性能,更重要的是,它展示了通过精巧的架构设计,较小规模的模型也能够达到甚至超越体量远大于自身的模型,为未来高效、强大的 AI 智能体的发展开辟了新的道路。