AgentFrontier: Expanding the Capability Frontier of LLM Agents with ZPD-Guided Data Synthesis
-
ArXiv URL: http://arxiv.org/abs/2510.24695v1
-
作者: Yong Jiang; Pengjun Xie; Xuanzhong Chen; Zhen Zhang; Jingren Zhou; Fei Huang; Liangcai Su; Xinyu Wang; Zile Qiao; Guoxin Chen
-
发布机构: Alibaba Group; Tongyi Lab
TL;DR
本文提出了 AgentFrontier,一个基于教育心理学“最近发展区”(ZPD)理论的数据合成框架,通过自动生成位于大语言模型(LLM)能力边界上的复杂推理数据,从而系统性地提升智能体(Agent)的跨领域、综合推理能力。
关键定义
本文为将教育学理论应用于大语言模型智能体训练,提出并具象化了以下核心概念:
- 最近发展区 (Zone of Proximal Development, ZPD):源自教育心理学,本文将其操作化定义为这样一个认知空间:一个基础的、不使用工具的 LLM 无法独立解决其中的任务,但一个更强大的、使用工具的增强型智能体则可以成功解决。位于 ZPD 内的数据被认为是推动模型能力发展的最高效训练材料。
- 知识较少的同伴 (Less Knowledgeable Peer, LKP):代表一个基础的、无工具辅助的 LLM。它被用来衡量一个任务是否能被模型仅凭其内在知识解决,从而确定其能力下限。
- 知识更渊博的他者 (More Knowledgeable Other, MKO):代表一个配备了工具套件(如网络搜索、代码执行)的、能力更强的智能体。它用于判断一个对 LKP 而言过难的任务是否在辅助下可解,从而界定 ZPD 的上界。
- AgentFrontier 引擎 (AgentFrontier Engine):本文提出的核心数据合成框架。该引擎通过 LKP 和 MKO 之间的“对抗性校准”过程,系统性地生成需要跨文档知识融合与深度推理的问答数据,并将其精确地过滤和校准到目标模型的 ZPD 内。
相关工作
当前,尽管大语言模型在基础推理任务上表现出色,但在需要深度、跨领域和综合性推理的复杂场景中仍然面临瓶颈。这种差距主要归因于现有训练数据的两大缺陷:
- 缺乏对智能体能力的系统性培养:现有语料库很少能统一地训练模型使用工具、自我反思、迭代规划和多步推理等高级智能体技能。
- 数据合成范式的局限性:现有数据合成方法多为“以查询为中心”(生成现有问答对的变体)或“以文档为中心”(从单个文档生成问答对)。这两种方法主要考察局部信息理解,类似于对学生的单章节测验,而无法培养其跨越整个课程体系进行综合分析的能力。
因此,本文旨在解决一个核心问题:如何自动、可扩展地合成高质量、高难度的训练数据,这些数据能够精确地挑战并拓展 LLM 智能体的能力边界(Frontier),特别是其进行多源信息融合与复杂推理的能力。
本文方法
本文的核心贡献是 AgentFrontier 数据引擎,一个基于 ZPD 理论的、旨在自动生成复杂推理数据的三阶段框架。该框架能够主动地创造并校准数据难度,推动 LLM 从知识检索器向高级推理智能体演进。
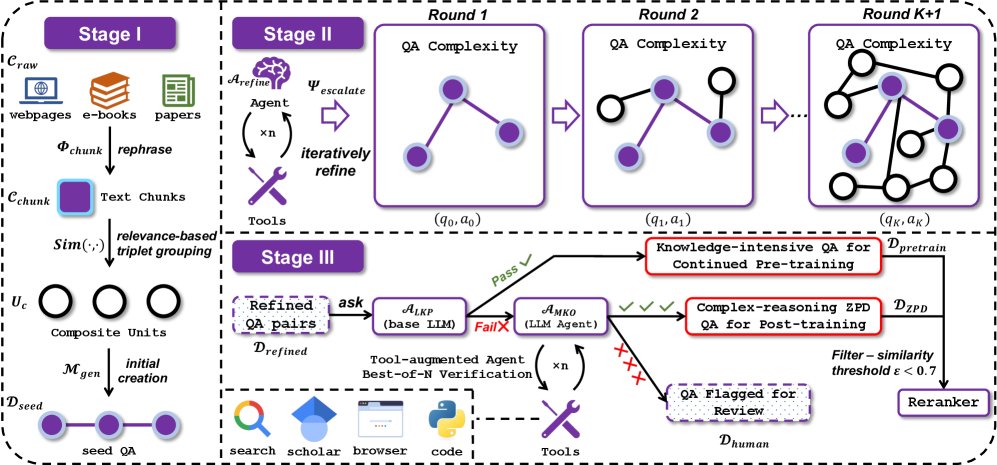
第一阶段:生成用于知识融合的种子问题
此阶段旨在创造天生就需要融合多个信息源才能回答的问题。
- 语料库预处理:从包含一百万份公开文档的多学科原始语料库 $\mathcal{C}_{\text{raw}}$ 开始,使用一个强大的 LLM(Qwen3-235B-A22B)作为分块函数 $\Phi_{\text{chunk}}$,将其清洗并浓缩为信息密集的文本块 $\mathcal{C}_{\text{chunk}}$。
- 构建复合单元:为了避免组合搜索带来的计算爆炸,本文采用了一种基于检索的高效方法。首先为所有文本块建立向量索引,然后为每个块 $c_i$ 检索其 $k$ 个最近邻。在这些邻居中,搜索具有高主题一致性的三元组 $(c_i, c_j, c_k)$ 作为“复合单元” $U_c$。
- 生成种子问答:将这些复合单元输入给生成器模型 $\mathcal{M}_{\text{gen}}$,合成初始的问答对 $(q_0, a_0)$。由于每个问题源自多个相关但不同的文本块,这确保了种子问题本身就具备知识融合的需求。
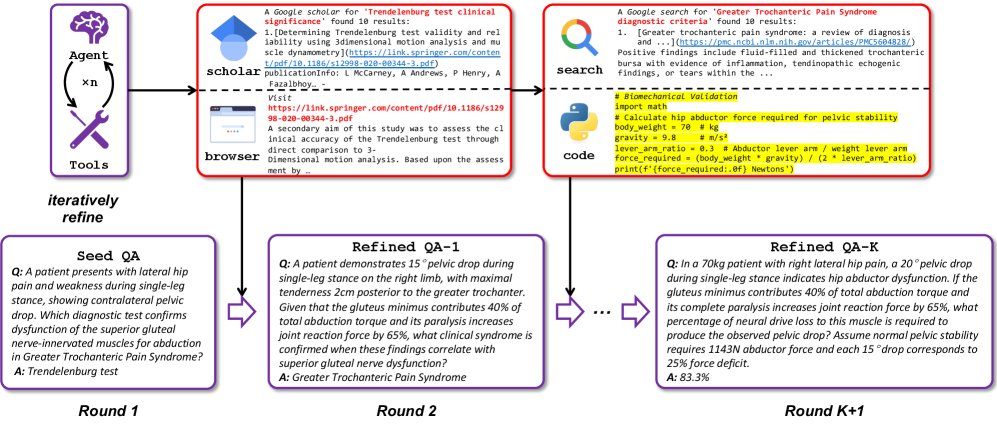
第二阶段:通过智能体优化来提升复杂度
此阶段通过一个配备工具套件(包括网络搜索、学术搜索、浏览器、代码执行器)的优化智能体 $\mathcal{A}_{\text{refine}}$,对种子问答进行迭代式增强。 智能体对每个问答对 $(q_k, a_k)$ 应用一个“提升算子” $\Psi_{\text{escalate}}$,从四个维度进行丰富:
- 扩展背景:主动查询外部知识源,拓宽问题的信息范围。
- 深化概念:对核心概念进行深入分析,抽象出高阶原则。
- 交叉验证:进行多源事实核查与内容增强,提升深度和准确性。
- 引入计算:利用代码执行能力,构建需要定量计算或逻辑模拟的问答。
这个自举过程形成了一个良性循环,每一轮的输出都成为下一轮的输入,从而逐步构建出具有复杂推理路径的高难度问答数据集 $\mathcal{D}_{\text{refined}}$。
第三阶段:基于 ZPD 的过滤与校准
这是本文方法的创新核心,用于从复杂数据中筛选出最具训练价值的部分。
- 定义 LKP 与 MKO:实例化两个智能体角色:一个是没有工具的基础 LLM 作为“知识较少的同伴”($\mathcal{A}_{\text{LKP}}$),另一个是配备工具的强大 LLM 作为“知识更渊博的他者”($\mathcal{A}_{\text{MKO}}$)。
- ZPD 校准:
- 步骤一:LKP 测试。对于每个候选问答对 $(q, a)$,首先让 $\mathcal{A}_{\text{LKP}}$ 尝试解答。如果成功,说明该任务对于当前模型来说太简单,被划分到用于持续预训练的知识密集型数据集 $\mathcal{D}_{\text{pretrain}}$。
- 步骤二:MKO 验证。如果 $\mathcal{A}_{\text{LKP}}$ 解答失败,该任务则被传递给 $\mathcal{A}_{\text{MKO}}$。$\mathcal{A}_{\text{MKO}}$ 会进行 $N=3$ 次的“最佳答案”(Best-of-N, BoN)验证。
- 如果 MKO 至少有一次成功解答,那么该问答对被认为处于模型的 ZPD内(即有挑战性但通过辅助可学),并被收入最终的“前沿水平”微调数据集 $\mathcal{D}_{\text{ZPD}}$。
- 如果 MKO 三次均失败,说明该任务可能存在缺陷或难度过高,被移交人工分析。
- 多样性过滤:最后,通过一个重排序模型(reranker model)进行语义冗余过滤,确保最终数据集 \(D_ZPD\) 中的问题具有多样性。
通过这套流程,AgentFrontier 引擎能够持续、可扩展地生成校准到模型能力前沿的复杂推理数据。
ZPD Exam:一个自我演进的 LLM 智能体基准
为了评估快速发展的 LLM 智能体,本文还提出了 ZPD Exam,一个能与模型能力共同演进的自动化基准。
基准构建
ZPD Exam 利用 AgentFrontier 引擎生成,但使用与训练数据完全不相交的语料库(30,000篇2023-2025年发表的科研论文),确保评估的公正性。其核心设计理念是:
- 基于知识前沿:问题源自最新的科学文献,杜绝了仅靠模型内部参数知识就能回答的可能性。
- ZPD 对齐:通过严格的对抗性过滤,一个问题必须满足双重约束才能入选:(1)基线模型在无工具辅助下三次尝试均失败;(2)同一模型在有工具辅助下三次尝试均能成功。这确保了题目精确地位于模型的 ZPD 边界。
最终生成的 ZPD Exam-v1 包含1024个公开问题,覆盖数学、计算机、物理等9个学科。
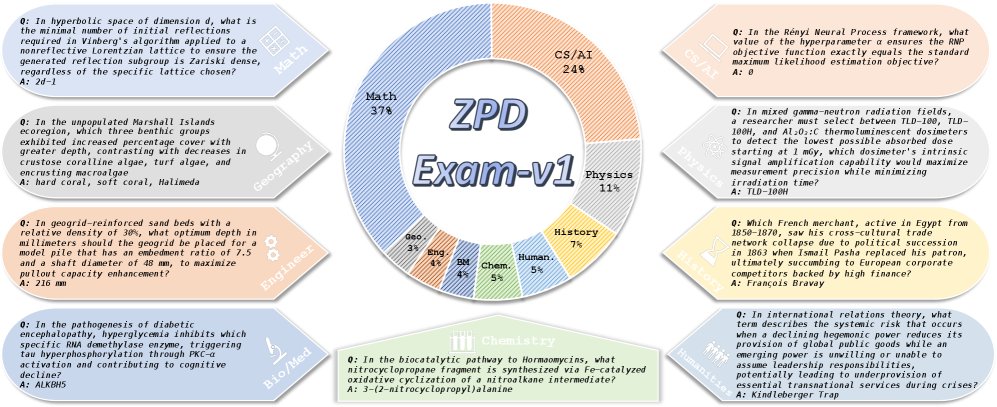
作为诊断工具的 ZPD Exam
ZPD Exam 不仅是一个排行榜,更是一个诊断工具。它将智能体的表现清晰地划分为三个区域,揭示了其能力发展阶段:
- 内在知识区:无工具辅助的 LLM 在此区域得分极低,验证了这些任务超出了其“闭卷”能力范围。
- 最近发展区(ZPD):有工具辅助但表现不完美的智能体处于此区域。它们的失败往往不是因为工具使用错误,而是因为更高阶的“推理瓶颈”——缺乏战略规划、跨工具调用的信息综合能力。
- 能力掌握区:顶尖智能体(如 DeepSeek-V3.1)在此区域表现出色,它们超越了推理瓶颈,能像 MKO 一样无缝整合工具探索和推理过程,解决了远超其内在能力的问题。
实验结论
实验设置
- 训练数据:使用 AgentFrontier 引擎生成训练数据。同时,为了对比,也使用了三个公开的智能体微调数据集:TaskCraft、MegaScience 和 MiroVerse。所有数据集都被处理成包含12,000条高质量轨迹,并进行了训练轮数归一化。
- 模型:主要在 Qwen3 系列模型(包括 Qwen3-8B、Qwen3-32B 和 Qwen3-30B-A3B-Thinking-2507)上进行微调。
- 基准:在四个高难度基准上进行评估:Humanity’s Last Exam (HLE)、ZPD Exam-v1、R-Bench-T 和 xBench-ScienceQA。
-
训练方法:采用拒绝采样微调(Rejection Sampling Fine-Tuning, RFT),其损失函数为:
\[\mathcal{L}_{\text{RFT}}(\theta) = -\sum_{i=1}^{K}\sum_{j=1}^{L_{i}}\log p_{\theta}\Big(r_{j}^{(i)} \mid q^{(i)}, r_{j-1}^{(i)}, o_{j-1}^{(i)}\Big)\]其中,模型只在生成的推理报告 \(r_j\) 上计算损失。
各训练数据集的统计信息如下表所示,AgentFrontier 在工具使用上表现出更好的平衡性和多样性。
| 数据集 | 平均轮数 | 平均调用次数(总计) | 学术搜索 | 浏览器 | 代码 |
|---|---|---|---|---|---|
| TaskCraft | 3.38 | 1.04 | 0.14 | 1.19 | 0.01 |
| MegaScience | 2.68 | 0.26 | 0.56 | 0.49 | 0.37 |
| MiroVerse | 2.18 | 0.12 | 0.04 | 0.09 | 0.93 |
| AgentFrontier | 3.32 | 0.32 | 0.66 | 0.82 | 0.52 |
主要结果
-
总体性能的压倒性优势:在所有基准测试中,使用 AgentFrontier 数据集微调的 Qwen3-30B-A3B-Thing-2507 模型均取得了当前最佳(SOTA)性能,显著优于使用其他数据集训练的模型。
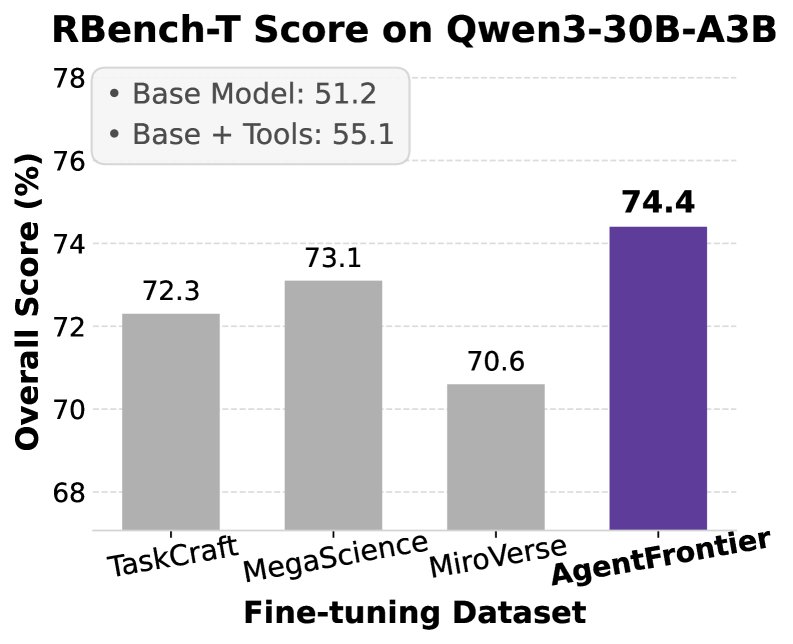
-
HLE 基准上的学科级主导地位:在极具挑战性的 HLE 基准上,AgentFrontier 训练的模型不仅总分领先,更在几乎所有细分学科(如数学、物理、化学、计算机科学等)上都取得了最佳表现。这证明了 AgentFrontier 能够全面提升模型在广泛学术领域的专家级问题解决能力,而非偏科。例如,在 Qwen3-30B-A3B 模型上,AgentFrontier 在 HLE 的所有8个学科中均排名第一,总分达到25.67%。
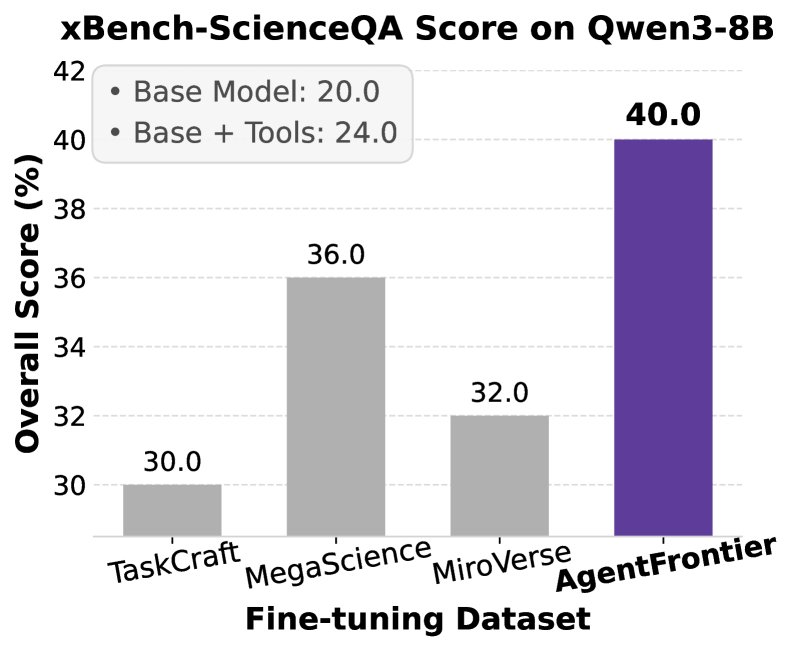
- BoN 分析验证了难度和潜力:对 AgentFrontier 数据集进行的 Best-of-N 分析显示,pass@1 的准确率为21.7%,而 pass@8 则跃升至40.7%。这表明:
- 难度丰富性:数据集包含大量“有挑战但可解”的问题,为模型提供了丰富的学习信号。
- 强化学习潜力:pass@1 和 pass@8 之间的巨大差距证明,即使模型首次尝试失败,其策略分布中也包含了成功的备选方案,这是未来通过强化学习进一步提升性能的关键前提。
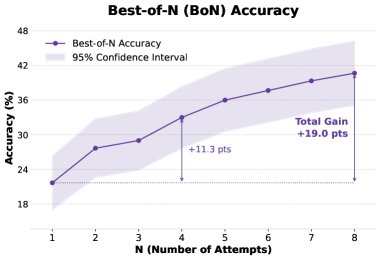
- AgentFrontier 成功的原因分析:AgentFrontier 的优势源于其 ZPD 设计理念。它迫使模型学习知识融合(Knowledge Fusion)和战略性的工具编排(Strategic Tool Orchestration),而不是简单的信息检索或单一工具的重复使用。其训练出的智能体在解决中等复杂度(15轮以内)问题上表现尤为突出,这正是现实世界中多数复杂任务的范畴。
最终结论
AgentFrontier 框架通过其创新的 ZPD 引导的数据合成和校准机制,被证明是一种极其有效的方法。它能够生成高质量的训练数据,显著提升 LLM 智能体在需要多步、跨领域、多工具协作的复杂任务上的推理和解决问题的能力,成功地将模型的能力边界向前推进。