AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2509.08755v1
-
作者: Qi Zhang; Yu-Gang Jiang; Rui Zheng; Wenxiang Chen; Xuesong Yao; Tao Gui; Zhengyin Du; Jiecao Chen; Jiazheng Zhang; Yufei Xu; 等22人
-
发布机构: ByteDance; Fudan University; Shanghai Innovation Institute
TL;DR
本文提出了一个名为 AgentGym-RL 的强化学习框架和一个名为 ScalingInter-RL 的渐进式训练方法,旨在通过多轮交互式决策,从零开始(无需监督微调)训练大型语言模型(LLM)智能体,以解决长时程复杂任务。
关键定义
本文提出或沿用了以下对理解论文至关重要的核心概念:
- AgentGym-RL: 一个专为 LLM 智能体设计的新型强化学习(Reinforcement Learning, RL)训练框架。它具备模块化、解耦的架构,支持多种真实世界场景和主流 RL 算法,旨在通过智能体与环境的多轮交互进行端到端的策略优化。
- ScalingInter-RL: 一种渐进式交互缩放(Progressive Scaling Interaction)的训练方法。其核心思想是在 RL 训练过程中动态调整智能体与环境的最大交互轮数。训练初期使用较少的交互轮数以“利用”(exploitation)已有知识快速掌握基础技能;随着训练进行,逐步增加交互轮数以鼓励“探索”(exploration),从而学习更复杂的策略,最终达到稳定优化与性能提升的目的。
- 部分可观测马尔可夫决策过程 (Partially Observable Markov Decision Process, POMDP): 本文沿用此经典模型来对智能体任务进行数学形式化。一个 POMDP 由元组 $(\mathcal{U}, \mathcal{S}, \mathcal{A}, \mathcal{O}, \mathcal{T} , r)$ 定义,分别代表指令空间、状态空间、动作空间、观测空间、状态转移函数和奖励函数。智能体的目标是在此框架下学习一个策略 $\pi_\theta$ 来最大化累积奖励。
相关工作
当前,大型语言模型(LLM)正从聊天机器人向能够处理真实世界长时程任务的自主智能体演进。通过与环境的探索和交互来学习是智能体发展的理想模式,因此强化学习(RL)成为一种自然的技术路径。
尽管已有研究将 RL 应用于 LLM 领域,但多数工作局限于单轮推理任务,未能解决智能体在复杂环境中进行多轮交互决策的问题。少数尝试训练多轮交互智能体的研究,在任务复杂性、环境多样性以及优化稳定性方面存在局限,导致性能不佳。
本文旨在解决的核心问题是:当前社区缺乏一个统一、有效、端到端的交互式多轮 RL 框架,该框架需要能够支持在多样化的真实环境中,从零开始(不依赖监督微调作为预备步骤)训练 LLM 智能体,并确保训练过程的稳定性和高效性。
本文方法
框架:AgentGym-RL
AgentGym-RL 是一个为训练多轮交互 LLM 智能体而设计的全新强化学习框架。它基于 AgentGym 构建,但在环境多样性、算法支持和工程优化方面进行了大幅扩展。
架构
该框架采用模块化和解耦的设计,包含三个核心组件:
- 环境 (Environment) 模块: 通过标准化的服务器-客户端架构和统一的 HTTP 协议,提供多样化的交互场景。
- 智能体 (Agent) 模块: 封装智能体的推理和决策过程,支持长时程规划、自我反思等高级机制。
- 训练 (Training) 模块: 实现强化学习流程及其他训练方法,用于优化智能体策略。
这种即插即用的设计提供了高度的灵活性和可扩展性,研究者可以轻松集成新的环境、智能体架构和训练算法。
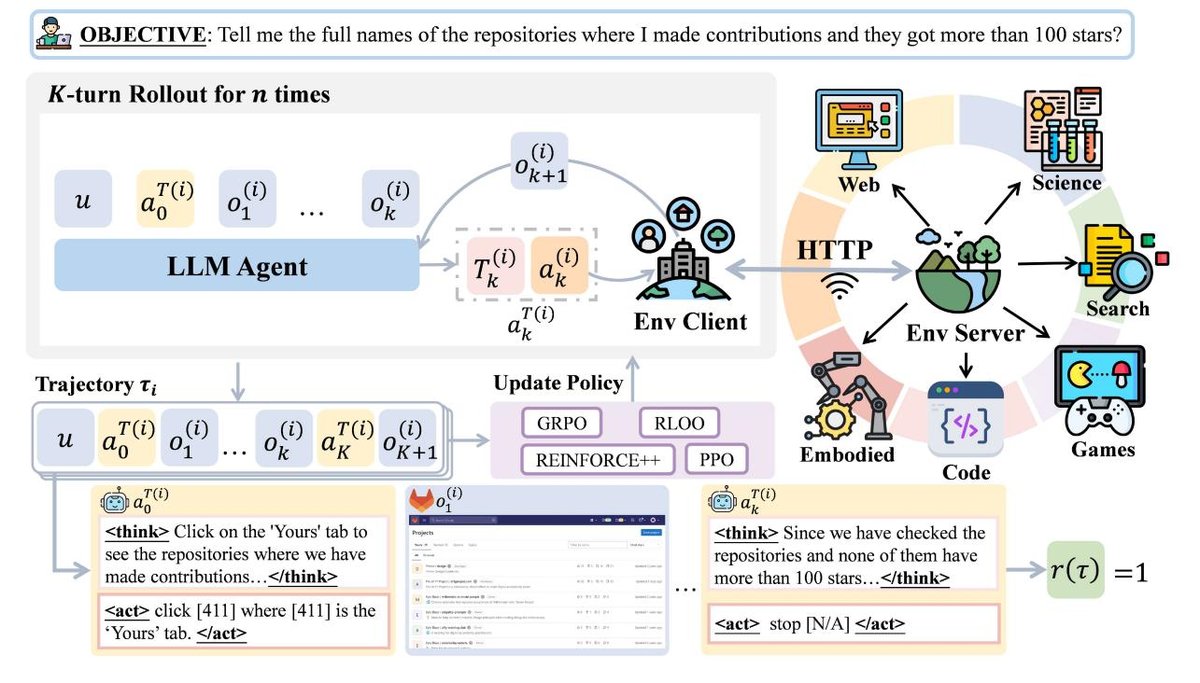 图 2: AgentGym-RL 框架概览。它具有解耦、灵活和可扩展的架构,包括环境、智能体和训练三个主要模块,支持多样的场景、环境和算法。
图 2: AgentGym-RL 框架概览。它具有解耦、灵活和可扩展的架构,包括环境、智能体和训练三个主要模块,支持多样的场景、环境和算法。
``$$python
伪代码示例
第1阶段:生成响应
task_ids = expand(task_ids, sample_num) envs = create_env_clients(task_ids, “webarena”, base_url) 并行执行: for (env, task_id) in zip(envs, task_ids): env.reset(task_id) handlers =[ RolloutHandler().add_user_message(env.observe()) for env in envs] for i in range(max_rounds) prompts = [h.get_prompt() for h in handlers] responses = actor.generate(prompts) results = thread_safe_list() 并行执行: for (env, response) in zip (envs, responses): results.append(env.step(response)) for (h, r, res) in zip(handlers, responses, results): h.add_assistant_message(r) h.add_user_message(res.state) h.score = res.score if all_done(handlers): break
第2阶段:准备经验
batch = gen_batch_from_rollout_handlers(handlers) batch = actor.compute_log_prob(batch) batch = reference.compute_ref_log_prob(batch) batch = compute_advantages(batch, method=”grpo”)
第3阶段:Actor训练
actor.update_actor(batch) $$`` 图 3: 框架使用示例的伪代码(橙色标记为提供的API),以及智能体-环境交互与训练流程的简化理论图。
特点
多样的场景与环境
为了培养智能体的综合能力(环境感知、长期规划、深度推理、反思修正),AgentGym-RL 覆盖了五大类真实世界场景:
- 网页导航 (Web Navigation): 在动态网站上执行预订、信息提取等任务。
- 深度搜索 (Deep Search): 使用浏览器、代码解释器等工具进行多步、目标导向的查询。
- 数字游戏 (Digital Games): 在交互式游戏中探索和解决问题。
- 具身任务 (Embodied Tasks): 控制虚拟身体在模拟环境中完成导航、操作等任务。
- 科学任务 (Scientific Tasks): 在基于物理和知识的环境中进行实验和解决问题。
全面的RL算法支持
框架以在线强化学习为核心,集成了一系列主流算法,包括:
- PPO (Proximal Policy Optimization): 通过裁剪策略更新来提升训练稳定性。
- GRPO (Group-wise Reward-normalized Policy Optimization): PPO 的一种变体,通过组内奖励归一化来增强高绩效动作。
- RLOO (Reinforcement Learning from Offline-and-Online data): 使用同批次样本平均奖励作为基线以减少方差的 REINFORCE 变体。
- REINFORCE++: 集成 PPO 式裁剪和 KL 惩罚的增强版 REINFORCE 算法。 此外,框架还支持监督微调(SFT)、直接偏好优化(DPO)和基于拒绝采样的 AgentEvol 等多种训练范式。
扩展性、可伸缩性与可靠性
为支持大规模研究,框架进行了大量工程优化:
- 扩展性: 模块化设计允许研究者轻松添加新环境、新算法。
- 可伸缩性: 通过子进程架构、并行化环境重置、全重置接口等优化,支持更大规模的并行和更长时程的训练。
- 可靠性: 修复了多个环境(如 TextCraft、SciWorld)中的内存泄漏问题,确保长时间训练的稳定性。
开源与社区贡献
AgentGym-RL 是一个完全开源的框架,提供详细文档、可复现的训练流程和标准化 API。其亮点包括:
- 标准化评估与可复现性: 提供自动化脚本,确保实验结果的公平比较和轻松复现。
- 可视化用户界面: 包含一个交互式 UI,允许研究者逐帧检查智能体的决策过程,可视化交互轨迹,从而加速模型调试和迭代。
 图 4: 框架的可视化用户界面概览。
图 4: 框架的可视化用户界面概览。
方法:ScalingInter-RL
动机与核心洞见
智能体通过与环境的外部交互来探索和积累解决任务所需的信息。然而,初步实验表明,从一开始就允许过多的交互轮数,会导致智能体陷入无效探索,最终使训练崩溃;而始终限制交互轮数,又会束缚智能体的探索能力,使其难以掌握复杂策略。这启发本文提出一种动态调整交互深度的训练方法。
方法描述
ScalingInter-RL 是一种渐进式扩展智能体-环境交互时程的训练策略,旨在平衡探索与利用,并稳定优化过程。其核心是根据一个预设的课程表 (curriculum schedule),在训练过程中逐步增加允许的最大交互轮数 $K$。
- 初期阶段 (利用): 训练从一个较小的最大交互轮数 $h_t$ 开始。这迫使智能体在有限的步骤内高效地解决问题,集中精力掌握基础技能和完成简单任务。
- 后期阶段 (探索): 随着训练的进行(例如每隔 $\Delta$ 步),最大交互轮数会增加:$h_{t+1} = h_t + \delta_h$。更长的交互时程激励智能体探索更长的决策路径,从而有机会学习到规划、反思、回溯等高阶行为。
通过这种从“利用”到“探索”的平滑过渡,ScalingInter-RL 使智能体的策略能力与交互深度相匹配,既保证了早期训练的效率和稳定,又实现了对长时程复杂任务的泛化。
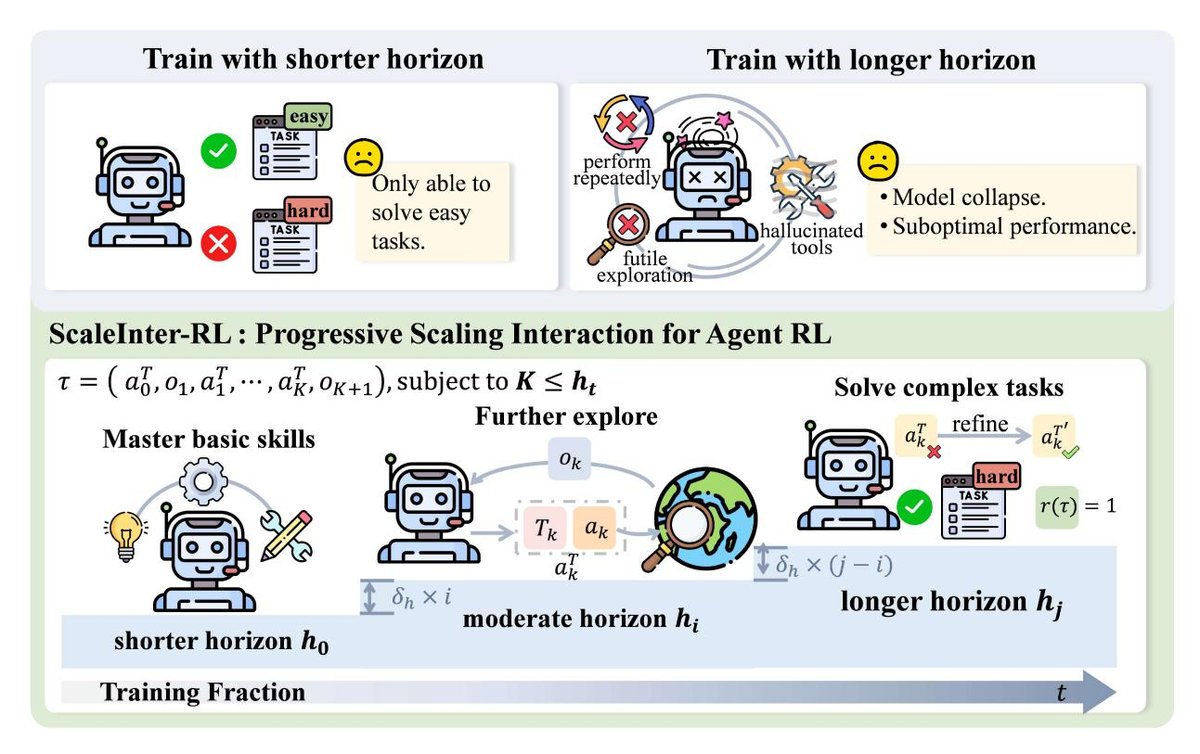 图 5: ScalingInter-RL 方法图示。它让智能体分阶段适应:初期限制交互轮数以优先利用、掌握基础技能;后期逐渐增加交互以促进探索、优化行为并解决更难的问题。
图 5: ScalingInter-RL 方法图示。它让智能体分阶段适应:初期限制交互轮数以优先利用、掌握基础技能;后期逐渐增加交互以促进探索、优化行为并解决更难的问题。
实验结论
本文通过在五个不同场景下的广泛实验,验证了 AgentGym-RL 框架和 ScalingInter-RL 方法的稳定性和有效性。
关键结果与洞察
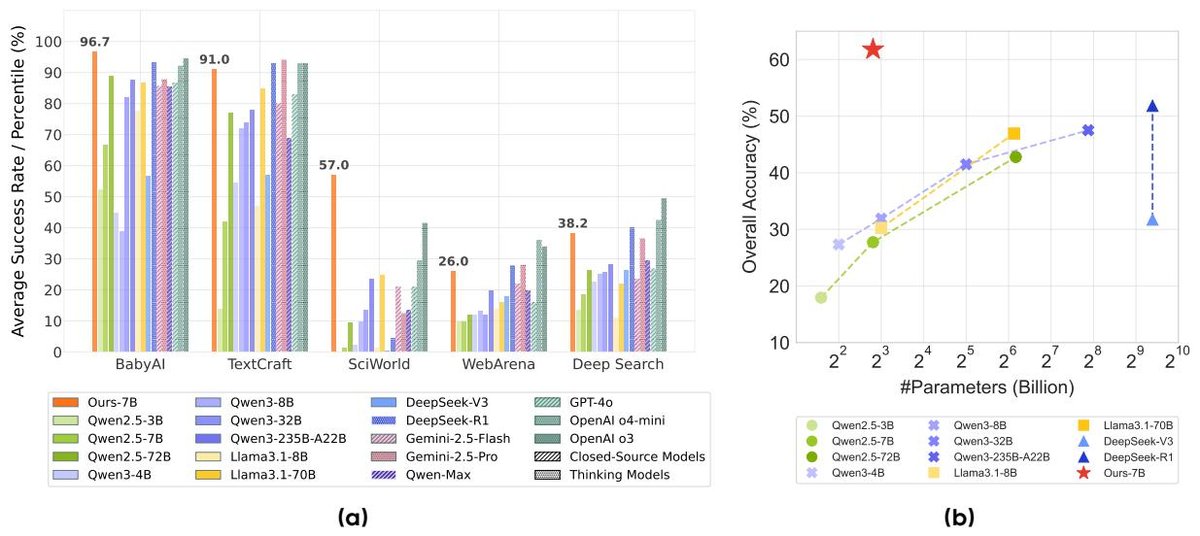 图 1 左: 不同智能体任务中,商业闭源模型、开源模型以及本文RL模型的性能对比。右: 性能与模型规模的关系。本文框架和方法协同作用,显著提升了开源7B模型的性能,达到甚至超过顶尖商业大模型的水平。
图 1 左: 不同智能体任务中,商业闭源模型、开源模型以及本文RL模型的性能对比。右: 性能与模型规模的关系。本文框架和方法协同作用,显著提升了开源7B模型的性能,达到甚至超过顶尖商业大模型的水平。
- RL显著提升开源模型智能: 如图1所示,经过 AgentGym-RL 训练的 7B 模型在五个场景中的平均成功率上,不仅远超其他开源模型,还优于 GPT-4o 和 Gemini-2.5-Pro 等顶尖商业闭源模型。
- ScalingInter-RL带来稳定且显著的性能提升: 该方法在所有环境中都一致地超越了基线 RL 方法。例如,在 WebArena 上性能提升超过10%,在 TextCraft 上提升了30分,达到SOTA水平。训练曲线(图6)也显示,该方法带来了稳定、持续的奖励增长。
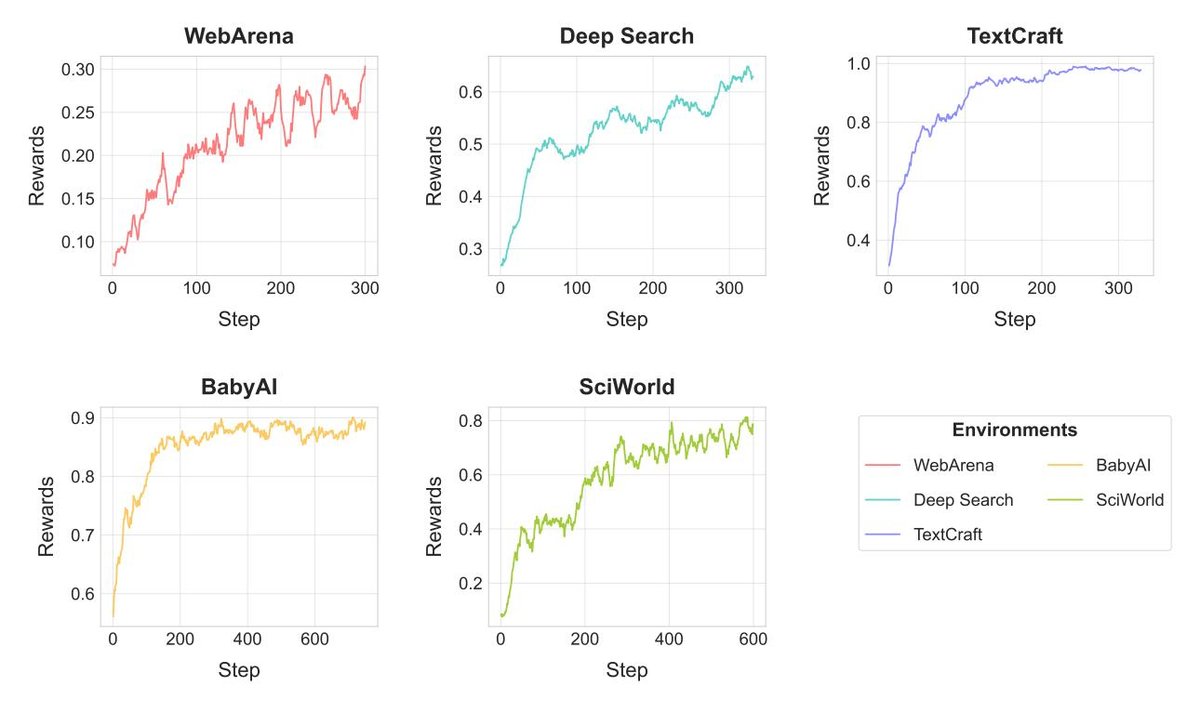 图 6: 不同环境下的训练奖励曲线。
图 6: 不同环境下的训练奖励曲线。
- 交互预算的影响: 实验(图7)表明,从一开始就使用大的交互预算(如10轮)虽然早期收益高,但很快会导致训练崩溃。而小的交互预算(如5轮)虽然稳定,但后期会遭遇性能瓶颈。这验证了 ScalingInter-RL 渐进式增加交互预算的有效性,它结合了两者的优点,实现了更高且更稳定的最终性能。
 图 7: 在深度搜索环境中,不同最大交互轮数下的训练动态。长轮次(如10)初期通过更丰富的探索获得更高奖励,但因高方差和过拟合很快崩溃。短轮次(如5)学习更稳定但探索不足,导致性能瓶颈。本文的 ScalingInter-RL 方法通过逐步增加交互时程,最终实现了更高、更高效的长期性能。
图 7: 在深度搜索环境中,不同最大交互轮数下的训练动态。长轮次(如10)初期通过更丰富的探索获得更高奖励,但因高方差和过拟合很快崩溃。短轮次(如5)学习更稳定但探索不足,导致性能瓶颈。本文的 ScalingInter-RL 方法通过逐步增加交互时程,最终实现了更高、更高效的长期性能。
- 后训练计算比模型规模更具扩展潜力: 如图1右侧所示,一个7B参数的 ScalingInter-RL 模型,其性能(约58.6%)远超参数量大近10倍的 Llama-3.1-70B(47%)和 Qwen2.5-72B(43%)。这表明,通过 RL 进行有针对性的后训练和增加测试时计算,比单纯扩大模型参数量能带来更显著的性能收益。
- 环境结构决定RL效率: RL 在规则明确、因果清晰的模拟世界(如TextCraft, BabyAI, SciWorld)中效果最显著(在SciWorld上提升近50分)。而在更开放、噪声更大的环境(如WebArena, Deep Search)中,虽然也有提升,但幅度相对温和。
具体任务表现
WebArena (网页导航)
| 模型 | Shopping | CMS | Maps | G & R | Overall |
|---|---|---|---|---|---|
| 商业闭源模型 | |||||
| GPT-40 | 20.00 | 13.33 | 10.00 | 20.00 | 16.00 |
| OpenAI o3 | 33.33 | 0.00 | 40.00 | 80.00 | 34.00 |
| Gemini-2.5-Pro | 26.67 | 26.67 | 0.00 | 60.00 | 28.00 |
| 开源模型 | |||||
| Qwen2.5-7B-Instruct | 14.29 | 6.67 | 0.00 | 16.67 | 9.76 |
| Qwen2.5-72B-Instruct | 13.33 | 13.33 | 0.00 | 20.00 | 12.00 |
| Llama-3.1-70B-Instruct | 26.67 | 6.67 | 20.00 | 10.00 | 16.00 |
| 本文 RL 模型 | |||||
| AgentGym-RL-7B | 20.00 | 33.33 | 0.00 | 30.00 | 22.00 |
| ScalingInter-7B | 33.33 | 26.67 | 20.00 | 20.00 | 26.00 |
本文的 ScalingInter-7B 模型在总体性能(26.00%)上显著优于 GPT-4o(16.00%),并与 Gemini-2.5-Pro(28.00%)相当。
Deep Search (深度搜索)
| 模型 | NQ | TriviaQA | PopQA | HotpotQA | 2Wiki | Musique | Bamboogle | Overall |
|---|---|---|---|---|---|---|---|---|
| 商业闭源模型 | ||||||||
| GPT-4o | 20.00 | 70.00 | 30.00 | 30.00 | 32.00 | 10.00 | 34.00 | 26.75 |
| OpenAI o3 | 28.00 | 70.00 | 56.00 | 46.00 | 64.00 | 29.00 | 74.00 | 49.50 |
| Gemini-2.5-Pro | 22.00 | 62.00 | 38.00 | 28.00 | 48.00 | 19.00 | 56.00 | 36.50 |
| 开源模型 | ||||||||
| Qwen2.5-7B-Instruct | 18.00 | 54.00 | 20.00 | 18.00 | 6.00 | 4.00 | 26.00 | 18.75 |
| DeepSeek-R1-0528 | 32.00 | 68.00 | 42.00 | 44.00 | 50.00 | 21.00 | 44.00 | 40.25 |
| 本文 RL 模型 | ||||||||
| AgentGym-RL-7B | 44.00 | 64.00 | 32.00 | 40.00 | 36.00 | 15.00 | 26.00 | 34.00 |
| ScalingInter-7B | 52.00 | 70.00 | 46.00 | 42.00 | 44.00 | 14.00 | 24.00 | 38.25 |
ScalingInter-7B 的总体得分(38.25)优于 GPT-4o 和 Gemini-2.5-Pro,并与顶尖开源模型 DeepSeek-R1(40.25)相当,在 NQ 和 TriviaQA 等子任务上达到 SOTA 水平。
TextCraft (数字游戏)
| 模型 | Depth 1 | Depth 2 | Depth 3 | Depth 4 | Overall |
|---|---|---|---|---|---|
| 商业闭源模型 | |||||
| OpenAI o3 | 100.00 | 100.00 | 84.00 | 0.00 | 93.00 |
| Gemini-2.5-Pro | 100.00 | 100.00 | 84.00 | 33.33 | 94.00 |
| 开源模型 | |||||
| Qwen2.5-7B-Instruct | 80.65 | 39.02 | 16.00 | 0.00 | 56.00 |
| DeepSeek-R1-0528 | 100.00 | 100.00 | 68.00 | 0.00 | 90.00 |
| 本文 RL 模型 | |||||
| AgentGym-RL-7B | 100.00 | 100.00 | 76.00 | 0.00 | 92.00 |
| ScalingInter-7B | 100.00 | 100.00 | 100.00 | 66.67 | 98.00 |
ScalingInter-7B 在此任务上表现出色,总体得分(98.00)达到 SOTA,并首次在最高难度(Depth 4)上取得了 66.67% 的成功率。
BabyAI (具身任务)
| 模型 | BossLevel |
|---|---|
| 商业闭源模型 | |
| GPT-4o | 28.00 |
| OpenAI o3 | 70.00 |
| Gemini-2.5-Pro | 62.00 |
| 开源模型 | |
| Qwen2.5-7B-Instruct | 11.00 |
| Qwen2.5-72B-Instruct | 40.00 |
| Llama-3.1-70B-Instruct | 44.00 |
| 本文 RL 模型 | |
| AgentGym-RL-7B | 82.00 |
| ScalingInter-7B | 84.00 |
ScalingInter-7B 再次取得 SOTA 成绩(84.00),远超所有商业和开源基线模型。
SciWorld (科学任务)
| 模型 | Average Steps | Score |
|---|---|---|
| 商业闭源模型 | ||
| GPT-4o | 14.28 | 49.38 |
| OpenAI o3 | 14.18 | 51.52 |
| Gemini-2.5-Pro | 14.12 | 53.65 |
| 开源模型 | ||
| Qwen2.5-7B-Instruct | 7.96 | 1.50 |
| Qwen2.5-72B-Instruct | 12.30 | 38.30 |
| Llama-3.1-70B-Instruct | 13.98 | 49.98 |
| 本文 RL 模型 | ||
| AgentGym-RL-7B | 11.22 | 48.00 |
| ScalingInter-7B | 12.18 | 50.50 |
RL 带来了巨大提升,ScalingInter-7B 将基础模型的得分从 1.50 大幅提升至 50.50,与顶尖商业模型 OpenAI o3 (51.52) 和 Gemini-2.5-Pro (53.65) 表现相当。