Agentic Meta-Orchestrator for Multi-task Copilots
-
ArXiv URL: http://arxiv.org/abs/2510.22781v1
-
作者: Xiaofeng Zhu
-
发布机构: Microsoft Corporation
TL;DR
本文提出了一种名为“智能体元编排器” (Agentic Meta-Orchestrator, AMO) 的新架构,用于构建可扩展的多任务Copilot服务,该架构通过学习排序模型进行智能体路由,利用LoRA臂实现高效多任务推理,并通过元学习决策树来动态规划推理路径。
关键定义
- 智能体元编排器 (Agentic Meta-Orchestrator, AMO):本文提出的核心架构,旨在管理和协调多任务Copilot中的多个智能体。它集成了智能体编排、多任务推理和推理规划三大功能,以应对动态增加的智能体和复杂的任务需求。
- 智能体编排器 (Agentic Orchestrator):AMO的关键组件之一,负责将用户请求路由到最合适的智能体。它创新地将此问题建模为学习排序 (learning-to-rank) 任务,而非传统的多分类任务。通过对智能体的自然语言描述进行排序,该方法在新增智能体时具有很强的可扩展性。
- LoRA臂 (LoRA Arms):一种为实现高效多任务推理而设计的内存优化框架。它让多个任务共享同一个基础大语言模型,但为每个任务独立训练和加载特定的低秩适应 (Low-Rank Adaptation, LoRA) 权重(即“臂”)。在推理时,这些“臂”可以同时应用,从而在显著节省内存的同时处理多个任务。
- 元学习决策树 (Meta-learning Decision Tree):AMO的规划组件,是一个经过训练的决策模型,用于为给定的用户提示选择最优的推理路径(即智能体/模型的组合与调用顺序)。与基于启发式规则或LLM实时规划的方法不同,该决策树通过学习历史数据来生成确定性、可操作的行动计划,其中每个节点代表一个智能体或模型。
相关工作
当前,构建强大的多智能体(multi-agent)系统面临着诸多挑战。一方面,像ChatGPT这样的大语言模型(LLM)虽然功能强大,但在处理特定领域任务时,常因知识过时或缺乏定制化而表现不佳。例如,它们无法提供最新的产品价格或根据用户上下文给出特定建议。
为了解决这一问题,业界开始采用领域智能体来扩展LLM的能力,但这引入了新的瓶颈:
- 智能体编排挑战:随着智能体数量的动态增长,如何高效、准确地将用户请求分发给正确的智能体成为一个难题。传统的文本分类方法在智能体类别增加时缺乏可扩展性,而基于相似度的方法则难以处理描述重叠或用户意图模糊的情况。
- 部署效率挑战:为每个任务部署一个独立的微调模型会消耗巨大的内存和计算资源,这在实际生产环境中是不可持续的。
- 推理规划挑战:现有的规划框架如RAG(检索增强生成)是基于简单的人工启发式规则,而AutoGen等框架则依赖于LLM的实时规划,这在智能体数量和组合方式增多时,难以保证规划的最优性和稳定性。
本文旨在解决以上三大核心问题:如何实现可扩展的智能体编排、高效的多任务模型部署以及自动化的最优推理规划。
本文方法
本文提出的 Agentic Meta-Orchestrator (AMO) 架构由三个核心创新组件构成,分别应对编排、效率和规划的挑战。
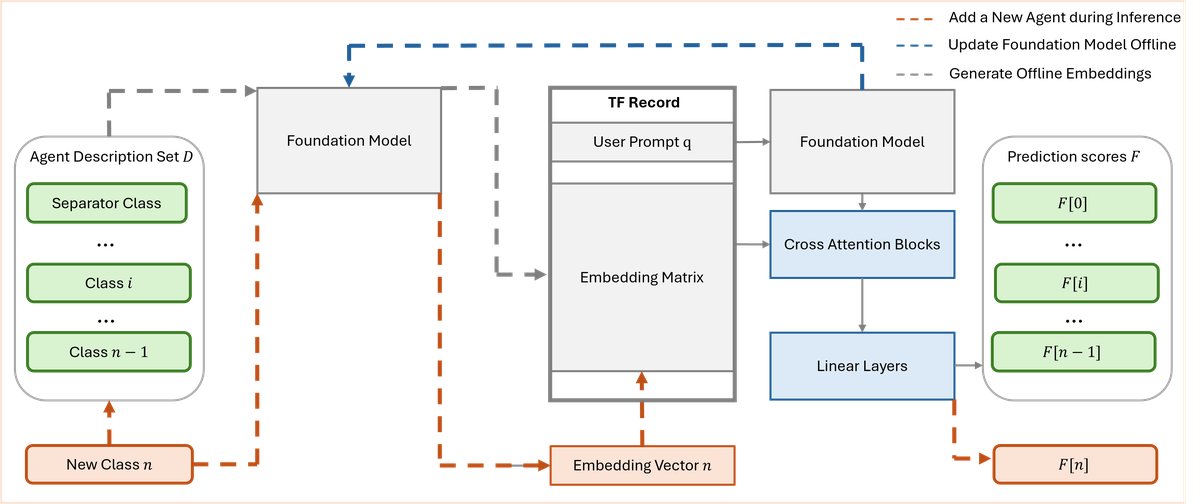
智能体编排器:基于学习排序的可扩展路由
为了解决传统分类方法在智能体数量增加时难以扩展的问题,本文将智能体选择任务重新定义为一个学习排序 (learning-to-rank) 问题。
- 设计思路:不同于将智能体视为离散的类别,该方法将每个智能体的自然语言描述(例如,“查询价格”、“比较产品”)视为待排序的“候选文档”。
- 实现方式:
- 利用通用的嵌入模型(如BERT、Sentence Transformers)为用户提示(query)和所有智能体描述(documents)生成向量表示。
- 训练一个Listwise多级学习排序模型。该模型的目标是为与用户提示更相关的智能体预测更高的分数。损失函数(如uRank loss)被用来优化排序列表的概率。
- 巧妙地引入一个“分隔符类 (Separator Class)”,其作用是动态决定\(top-k\)的边界。在推理时,所有排名低于此“分隔符”的智能体都被视为与当前用户提示不相关。
- 优点:当系统需要添加新智能体时,无需重新训练整个模型,只需将其描述加入候选列表即可,极大地提升了系统的可扩展性和灵活性。
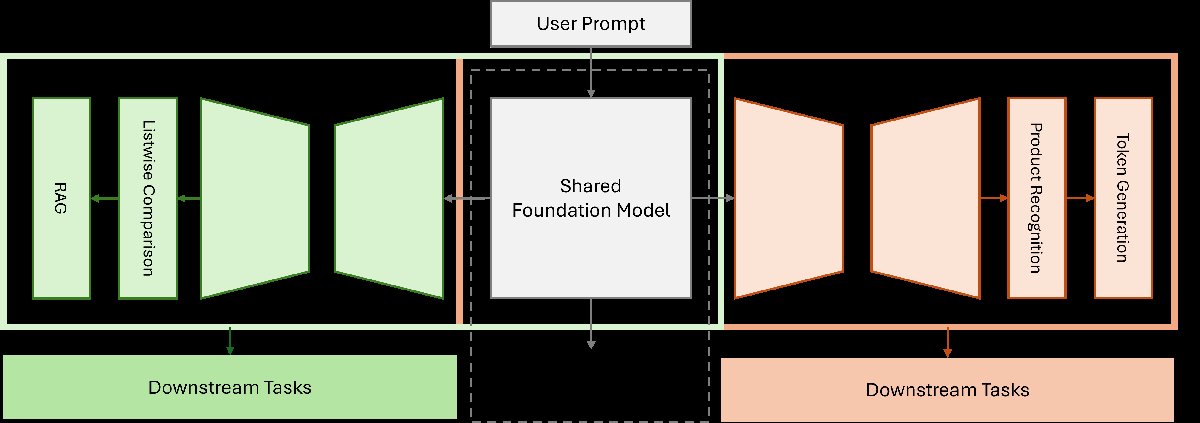
LoRA Arms:高效的多任务并行推理
针对同时部署多个微调模型导致的内存消耗巨大的问题,本文提出了LoRA Arms框架。
- 设计思路:该框架的核心思想是在共享基础模型的同时,为每个任务维护独立的、轻量化的适配器。
- 实现方式:
- 所有任务(如产品实体识别、多轮对话上下文理解等)共享一个基础LLM的内存。
- 为每个任务独立训练一个LoRA模块(即一个“Arm”),这些模块只包含少量可训练参数。
- 在推理时,系统可以根据需要同时加载一个或多个LoRA Arms,并将它们与基础模型结合,并行或串行地执行多个任务。
- 优点:这种方法显著降低了内存占用,提高了计算资源的利用率,使得在单个服务中支持多个复杂的下游工作负载成为可能。
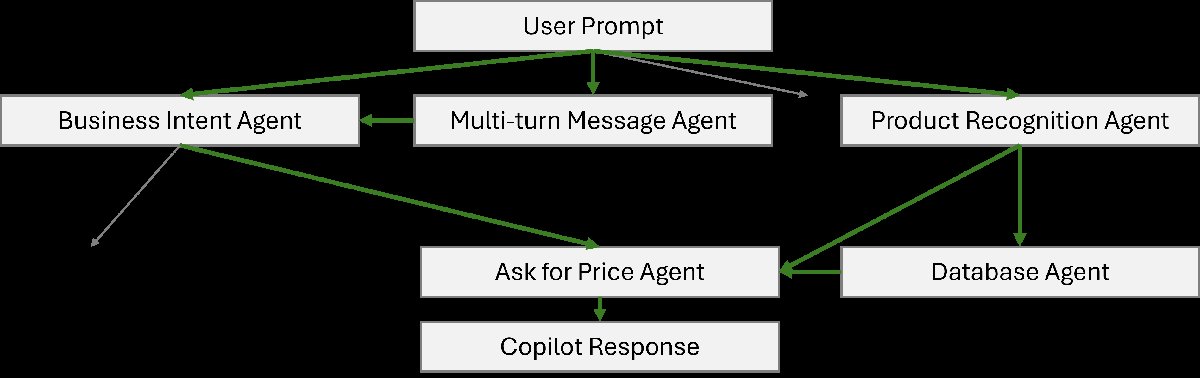
元学习规划器:基于决策树的推理路径选择
为了克服现有规划策略依赖人工规则或不稳定的LLM实时规划的缺点,本文提出了一种元学习方法来自动学习最优的推理计划。
- 设计思路:将推理规划本身视为一个学习任务,通过训练一个模型来决定针对不同用户提示应采取何种智能体调用序列。
- 实现方式:
- 构建一个决策树模型,其中每个节点代表一个智能体或模型(例如,业务意图识别、产品识别、数据库查询)。
- 使用包含用户提示、各种智能体的处理结果以及最终理想响应的端到端数据来训练这个决策树。
- 模型学习为不同类型的用户提示选择最佳的推理路径(即从根节点到叶节点的 traversal path)。例如,一个询问价格的提示可能会触发“业务意图”->“产品识别”->“数据库”->“询问价格”这一系列智能体的调用。
- 优点:生成的规划路径是确定性和可操作的,并且在添加新智能体时可以通过重新训练来更新规划策略,比固定的 heuristic 或昂贵的实时LLM规划更高效、更稳定。
实验结论
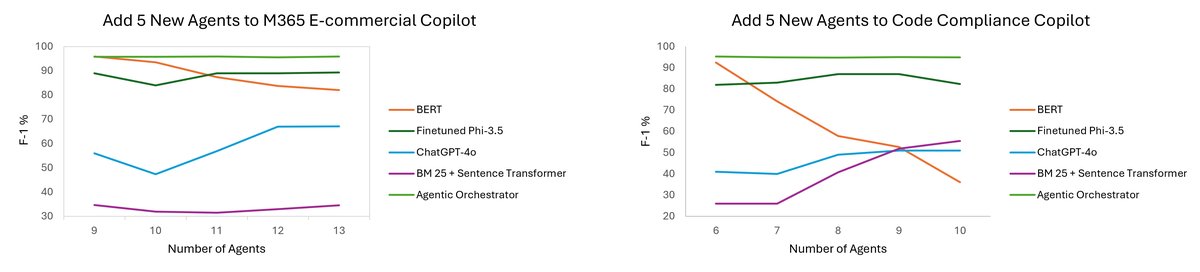
本文通过在两个真实的生产级Copilot服务——M365电子商务Copilot和代码合规性Copilot——上的实验,验证了AMO架构的有效性。
- 智能体编排性能:实验表明,随着智能体数量的增加,本文提出的基于学习排序的编排器性能保持稳定。相比之下,传统的BERT分类模型在智能体从9个增加到13个时,F-1分数显著下降。这证明了该方法在可扩展性方面的巨大优势。
- 分层分类任务:在Amazon产品评论数据集上的扩展实验表明,本文的uRank损失函数结合Sentence Transformer在三级分层分类任务上均取得了优于传统监督分类器和基于LLM(ChatGPT-4, Phi-4)的少样本学习方法的准确率。
| 亚马逊产品评论数据集 | 1级准确率 | 2级准确率 | 3级准确率 |
|---|---|---|---|
| Agentic Orchestrator扩展 | 0.95 | 0.81 | 0.72 |
| 监督文本分类器 | 0.90 | 0.75 | 0.66 |
| ChatGPT-4 | 0.87 | 0.71 | 0.59 |
| Phi-4 |
-
端到端系统性能:在M365电子商务和代码合规性两个场景中,完整的AMO系统在ROUGE-L、BERTScore和多任务F-1等指标上均显著优于基线模型(公司内部GPT-3.5 Turbo)、微调的Phi-3.5、ChatGPT-4o以及基于LLM规划的AutoGen框架。这证明了AMO的整体架构,特别是其元学习规划器,相比于依赖LLM的实时上下文理解和规划,具有更强的有效性。
-
最终结论:本文提出的AMO架构通过将智能体路由、多任务推理和推理规划分别用学习排序、LoRA Arms和元学习决策树进行创新设计,成功构建了一个可扩展、高效且规划能力强的多智能体系统。该架构在微软的生产环境中得到了验证,并可推广到旅游、电商等其他行业,为构建复杂的AI系统提供了有效的解决方案。