AgentInit: Initializing LLM-based Multi-Agent Systems via Diversity and Expertise Orchestration for Effective and Efficient Collaboration
-
ArXiv URL: http://arxiv.org/abs/2509.19236v1
-
作者: Min Zhang; Liang Ding; Yutong Wang; Xuebo Liu; Miao Zhang
-
发布机构: Harbin Institute of Technology; The University of Sydney
TL;DR
本文提出了一种名为 AgentInit 的多智能体系统(Multi-Agent System, MAS)初始化方法,该方法通过生成一组多样化的候选智能体,并利用以任务相关性和团队多样性为目标的帕累托最优原则进行团队选择,来优化智能体团队的构成,从而提升协作效率与任务表现。
关键定义
本文提出或沿用了以下对理解论文至关重要的核心概念:
- AgentInit: 本文提出的核心方法,一个用于初始化基于大语言模型(LLM)的多智能体系统的框架。它包含两个关键模块:标准化智能体生成(Standardized Agent Generation)和平衡的团队选择(Balanced Team Selection)。
- 标准化智能体生成 (Standardized Agent Generation): AgentInit的第一个模块。它通过多轮迭代,利用规划器智能体(Planner Agent)、观察者智能体(Observer Agent)和格式化智能体(Formatter Agent)生成一个标准化的候选智能体池。其核心在于先以自然语言形式自由生成智能体描述,再通过“自然语言到格式”(NL-to-Format)机制进行标准化,以便后续进行公平评估。
- 平衡的团队选择 (Balanced Team Selection): AgentInit的第二个模块,也是其核心创新点。该模块将团队构建视为一个多目标优化问题,通过帕累托最优原则,在“任务相关性”和“智能体多样性”两个维度上寻找最优平衡点,从而筛选出最佳的智能体团队。
- 任务相关性 (Task Relevance): 用于团队选择的关键指标之一。它通过计算团队中所有智能体描述的嵌入向量与用户查询(query)嵌入向量之间余弦相似度的平均值来量化。
- 智能体多样性 (Agent Diversity): 用于团队选择的另一个关键指标。它使用 Vendi Score 来度量,该分数基于团队内各智能体描述嵌入向量之间构成的相似度矩阵的特征值计算得出,能有效衡量团队成员之间的差异性。
相关工作
当前,基于大语言模型的多智能体系统已成为解决复杂任务的重要范式。许多现有框架(如AutoGen、CAMEL)仍依赖人工设计的角色和交互模式。虽然一些自动化方法(如Agent-Verse、AutoAgents、EvoAgent)尝试自动生成智能体,但它们通常直接通过大语言模型的交互来完成初始化,缺乏对后续协作效果的充分考虑。
这个过程存在以下关键瓶瓶颈:
- 团队冗余与无关性:直接生成的智能体团队可能包含与任务无关或功能重叠的成员,导致任务偏离、效率低下。
- LLM内在偏见:大语言模型在评估和筛选自身生成内容时存在自偏好(self-preference bias)等问题,难以有效剔除低质量或冗余的智能体。
因此,本文旨在解决的问题是:如何设计一个更鲁棒的自动化初始化机制,以构建一个既高效又协作良好的智能体团队,从根源上避免因初始化不当导致系统性能下降的问题。
本文方法
本文提出的 AgentInit 框架旨在通过优化初始团队结构来提升多智能体系统的效率和效果。其核心思想源于现实世界中高效团队的组建原则:成员不仅需要具备专业能力(任务相关性),团队整体也需要具备多样性以应对复杂挑战。AgentInit 通过“标准化智能体生成”和“平衡的团队选择”两个阶段来实现这一目标。

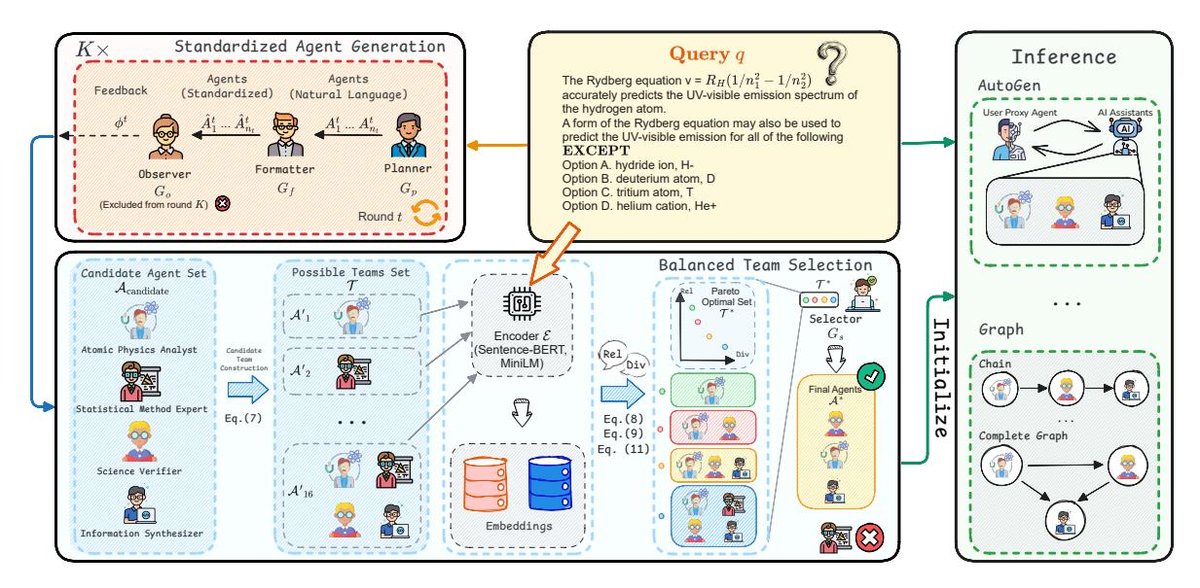
标准化智能体生成 (Standardized Agent Generation)
此阶段的目标是生成一个高质量且格式统一的候选智能体池 $\mathcal{A}_{\text{candidate}}$。该过程通过规划器(Planner Agent, $G_p$)、观察者(Observer Agent, $G_o$)和格式化(Formatter Agent, $G_f$)三个智能体的协作,经过多轮迭代完成。
-
任务分解与智能体构建:规划器 $G_p$ 首先将用户查询分解为多个子任务 ${\tau_i^t}$,然后为每个子任务设计一个相应的智能体 $A_i^t$。这个过程可以表示为:
\[G_p = (G_{p_2} \circ G_{p_1})\]其中 $G_{p_1}$ 负责任务分解, $G_{p_2}$ 负责智能体构建。
-
NL-to-Format 标准化:为了便于后续的公平评估和选择,格式化智能体 $G_f$ 会将以自然语言描述的智能体 $A_i^t$ 转换为统一的标准化格式(如JSON),得到 $\hat{A}_i^t$。这种“先生成后格式化”的策略避免了在生成阶段因严格格式限制而影响智能体质量的问题。
\[\left\{\hat{A}_{i}^{t}\right\}_{i=1}^{n_{t}} = G_{f}\left(\left\{A_{i}^{t}\right\}_{i=1}^{n_{t}}\right)\] -
评估与反馈:观察者 $G_o$ 在每轮结束时评估子任务分解和智能体分配的合理性,并提供反馈 $\phi^t$ 用于下一轮的优化。
\[\phi^{t} = G_{o}\left(\left\{\hat{A}_{i}^{t}\right\}_{i=1}^{n_{t}}, \left\{\tau_{i}^{t}\right\}_{i=1}^{n_{t}}\right)\] -
多轮迭代:上述过程重复进行 $K$ 轮,最终生成一个精炼的候选智能体集合 $\mathcal{A}_{\text{candidate}}$。
平衡的团队选择 (Balanced Team Selection)
这是 AgentInit 的核心创新所在。该模块将团队选择问题建模为一个多目标优化问题,旨在同时优化任务相关性和团队多样性。
-
候选团队构建:首先,从候选智能体池 $\mathcal{A}_{\text{candidate}}$ 中,生成所有规模在预设范围 $[N_{\min}, N_{\max}]$ 内的可能团队组合,构成候选团队集合 $\mathcal{T}$。
-
多目标优化与帕累托前沿:接着,通过寻找帕累托最优集(Pareto optimal set)$\mathcal{T}^*$ 来筛选团队。帕累托最优集包含所有“非支配”的团队方案,即不存在任何一个其他团队方案能同时在两个目标上都更优。
\[\mathcal{T}^{*} = \left\{ \mathcal{A} \in \mathcal{T} \middle \mid \begin{array}{l} \nexists \mathcal{A}' \in \mathcal{T}, \\ \operatorname{Rel}(\mathcal{A}', q) \ge \operatorname{Rel}(\mathcal{A}, q) \land \\ \operatorname{Div}(\mathcal{A}') \ge \operatorname{Div}(\mathcal{A}) \end{array} \right\}\] - 目标定义:
-
任务相关性 (Relevance):使用预训练的文本编码器 $\mathcal{E}$ 将智能体描述和用户查询编码为向量。相关性定义为团队中所有智能体与查询之间余弦相似度的平均值。
\[\operatorname{Rel}(\mathcal{A}',q) = \frac{1}{ \mid \mathcal{A}' \mid } \sum_{\hat{A} \in \mathcal{A}'} \frac{\mathcal{E}(A) \cdot \mathcal{E}(q)}{\ \mid \mathcal{E}(\hat{A})\ \mid \ \mid \mathcal{E}(q)\ \mid }\] -
团队多样性 (Diversity):采用 Vendi Score 来衡量。首先为每个候选团队 $\mathcal{A}’$ 构建一个成员间相似度矩阵 $S$,然后基于该矩阵的特征值 $\lambda_i$ 计算分数。
\[\operatorname{Div}(\mathcal{A}') = \exp\left(-\sum_{i=1}^{ \mid \mathcal{A}' \mid } \lambda_i \log \lambda_i\right)\]
-
-
最终团队选择:最后,一个选择器智能体(Selector Agent, $G_s$)会从帕累托最优集 $\mathcal{T}^*$ 中,根据用户查询选出最合适的最终团队 $\mathcal{A}^*$。
\[\mathcal{A}^* = G_s(\mathcal{T}^*, q)\]
通过这种方式,AgentInit 能够组建出一个专业能力强(高相关性)且成员互补(高多样性)的智能体团队。
实验结论
核心实验结果
实验结果表明,AgentInit 在性能和效率上均优于现有方法。
- 性能优越:在多个基准测试(如MMLU、GSM8K、HumanEval)和不同的大语言模型(Qwen2.5、Deepseek-V3)上,AgentInit 的性能均稳定超过了 CoT、AutoAgents、EvoAgent 等SOTA初始化方法以及预定义策略。在 Qwen2.5 和 Deepseek-V3 上的平均性能分别高出SOTA方法1.2和0.9个点。
表1:AgentInit 与其他基线方法在完全图(Complete Graph)结构下的性能对比 基于 Qwen2.5-72B-Instruct 模型
| 方法 | MMLU | GSM8K | AQUA | MultiArith | SVAMP | HumanEval | Avg. |
|---|---|---|---|---|---|---|---|
| Vanilla | 81.1 | 90.4 | 82.1 | 97.8 | 92.7 | 84.7 | 88.1 |
| CoT | 81.4 | 92.2 | 84.2 | 100.0 | 93.4 | 84.6 | 89.3 |
| AgentPrune | 83.7 | 92.8 | 85.0 | 99.4 | 93.2 | 87.6 | 90.3 |
| MAS none | 82.4 | 92.8 | 83.4 | 100.0 | 93.2 | 83.5 | 89.2 |
| Pre-defined | 82.3 | 93.4 | 83.6 | 100.0 | 93.7 | 87.0 | 90.0 |
| EvoAgent | 83.7 | 93.4 | 84.6 | 100.0 | 92.9 | 83.9 | 89.8 |
| AutoAgents | 85.3 | 92.7 | 83.8 | 100.0 | 92.9 | 86.0 | 90.1 |
| AgentInit | 87.3 | 94.1 | 85.0 | 100.0 | 93.5 | 88.0 | 91.3 |
基于 Deepseek-V3-671B-Instruct 模型
| 方法 | MMLU | GSM8K | AQUA | MultiArith | SVAMP | HumanEval | Avg. |
|---|---|---|---|---|---|---|---|
| Vanilla | 85.6 | 94.5 | 84.6 | 100.0 | 93.9 | 88.4 | 91.2 |
| CoT | 84.3 | 95.0 | 85.2 | 100.0 | 93.6 | 89.3 | 91.2 |
| AgentPrune | 89.5 | 95.3 | 86.7 | 100.0 | 93.6 | 87.2 | 92.1 |
| MAS none | 87.6 | 95.2 | 86.7 | 100.0 | 92.0 | 87.6 | 91.5 |
| Pre-defined | 88.2 | 95.5 | 87.1 | 100.0 | 94.6 | 88.5 | 92.3 |
| EvoAgent | 92.2 | 94.9 | 87.5 | 99.4 | 92.5 | 88.4 | 92.5 |
| AutoAgents | 90.2 | 95.4 | 86.7 | 99.4 | 93.3 | 91.7 | 92.8 |
| AgentInit | 92.8 | 95.7 | 87.5 | 100.0 | 94.3 | 91.7 | 93.7 |
最佳结果被加粗,次佳结果被下划线标出。
- 效率提升:通过“平衡的团队选择”模块过滤掉冗余智能体,AgentInit 在推理过程中显著降低了Prompt Token和Completion Token的消耗(见表2)。
- 框架适应性强:无论是在链式、星型、分层等图结构框架,还是在AutoGen这类松散耦合的框架中,AgentInit 都能取得稳定的最佳性能(见表3),展现了其强大的适应性。
核心机制验证
- 消融研究:
- 迭代轮数:实验表明,生成阶段的迭代轮数设为 K=3 时效果最佳,更多的迭代带来的收益递减。
- 标准化步骤:去除“NL-to-Format”标准化步骤会导致性能下降,证明了此步骤对于后续公平选择的重要性。
- 选择目标:仅考虑单一目标(仅相关性或仅多样性)的策略均不如同时平衡两者的 AgentInit。这验证了多目标优化的有效性。
- 选择策略:与不进行选择、随机选择等策略相比,AgentInit 的帕累托最优选择策略显著更优,证明了性能提升来源于其合理且有针对性的选择过程。
-
目标与性能关系分析:
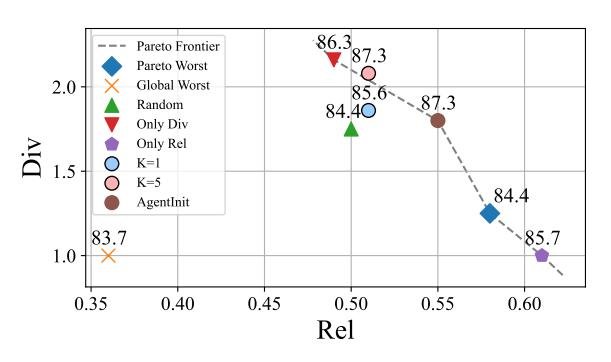 如图所示,最佳性能并非出现在相关性或多样性最高的地方,而是集中在两者取得平衡的中间区域。这直观地证明了单纯最大化任一指标都无法保证最优性能,而 AgentInit 的平衡策略是有效的。
如图所示,最佳性能并非出现在相关性或多样性最高的地方,而是集中在两者取得平衡的中间区域。这直观地证明了单纯最大化任一指标都无法保证最优性能,而 AgentInit 的平衡策略是有效的。 - 其他关键发现:
- 可迁移性:由单个或少量查询生成的智能体团队能够有效迁移到相似任务上,大大降低了为每个任务重新初始化的计算开销。
- 可扩展性:团队选择过程即使在候选智能体数量增加时也保持了较高的效率。对于更大规模的候选集,可以使用 NSGA-II 等启发式算法高效地近似帕累托最优解。
- 团队冗余减少:实验数据显示,经过 AgentInit 优化的团队,其成员间的最大相似度显著降低,表明该方法能有效剔除功能重叠的智能体。
最终结论
AgentInit 作为一种新颖的多智能体系统初始化方法,通过在个体层面(标准化生成)和团队层面(平衡选择)进行联合优化,能够构建出任务对齐度高、分工明确、协作高效的智能体团队。实验证明,该方法不仅在多种任务和框架下显著提升了系统性能,还降低了资源消耗,为未来多智能体系统的初始化研究提供了有价值的实践方向。