Alita-G: Self-Evolving Generative Agent for Agent Generation
-
ArXiv URL: http://arxiv.org/abs/2510.23601v1
-
作者: Jiacheng Guo; Xinzhe Juan; Mengdi Wang; Hongru Wang; Jiayi Geng; Yimin Wang; Jingzhe Shi; Peihang Li; Xuan Qi; Jiahao Qiu; 等12人
-
发布机构: Hong Kong University; King’s College London; Princeton University; Shanghai Jiao Tong University; The Chinese University of Hong Kong; Tsinghua University; University of Michigan
TL;DR
本文提出了Alita-G,一个自进化生成智能体框架,它通过系统性地生成、抽象和管理一系列称为模型上下文协议(Model Context Protocol, MCP)的工具,将一个通用智能体转化为特定领域的专家,从而在提升复杂推理任务准确率的同时降低了计算成本。
关键定义
本文的核心是围绕模型上下文协议(Model Context Protocol, MCP)的生成和使用来构建智能体。
- 模型上下文协议 (Model Context Protocol, MCP): 由 Anthropic 提出的一个标准化框架,用于在 AI 系统和外部工具或数据源之间实现无缝集成。在本文中,MCP 是一个自包含的功能模块,包含可执行代码、功能描述和使用场景,智能体可以在解决任务的过程中生成并调用它。
- MCP Box: 一个经过提炼和抽象的 MCP 仓库。它汇集了智能体在解决一系列领域任务时从成功轨迹中生成的、并经过泛化处理的 MCP 工具。这个“工具箱”是 Alita-G 实现领域专长的核心。
相关工作
当前,尽管自进化智能体取得了快速进展,但仍存在明显瓶颈。现有的进化机制通常范围狭窄,仅针对单一任务进行优化,而无法将一个通用智能体提升为能处理一系列相关任务的领域专家。此外,进化机制也偏于浅层,大多局限于改写提示词(prompt rewriting)或基于错误进行重试,而不是对整个智能体架构进行端到端的、任务导向的深度适应。真正的复杂任务需要规划、分解、工具使用和记忆等多方面能力的协同提升,而不仅仅是孤立的模块优化。
本文旨在解决上述问题,提出一种新的自进化范式:通过任务驱动的、端到端的适应,将一个通用智能体(general-purpose agent)转变为能够高效解决特定领域内一系列任务的领域专家(domain expert)。
本文方法
本文提出的 Alita-G 框架通过一个系统化的流程,将通用智能体的能力提炼并固化为可复用的领域专用工具,最终生成一个领域专家智能体。其核心流程包括任务驱动的MCP生成、MCP抽象与盒构建、基于RAG的MCP选择以及特化智能体执行四个阶段。
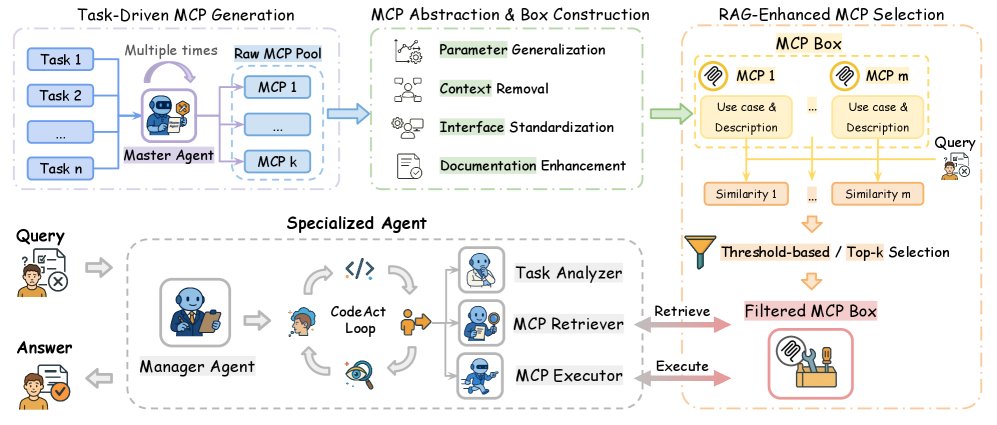
任务驱动的MCP生成
框架的起点是一个强大的通用型“主智能体”(Master Agent)。给定一个领域内的任务集合 $\mathcal{T}={(x_{i},y_{i})}_{i=1}^{N}$,主智能体被引导去解决这些任务。在解决过程中,它不仅要输出最终答案,还要将可复用的子解决方案模块化为独立的MCP。每个生成的MCP包含代码、功能描述和触发其创建的任务上下文。
为了保证质量,框架采用多重执行策略,即每个任务被重复执行 $K$ 次。只有在成功完成任务(即 $\pi_{\text{master}}(x_{i})=y_{i}$)的执行轨迹中生成的MCP才会被收集起来,形成一个原始的MCP池 $\mathcal{L}$。
\[\mathcal{L}=\{\text{MCP}_{i,j}^{(k)}\mid\pi_{\text{master}}^{(k)}(x_{i})=y_{i},\;i\in[N],j\in[J_{k,i}],k\in[K]\}\]MCP抽象与“MCP Box”构建
原始的MCP是与具体任务实例高度相关的。为了使其具有通用性,框架使用一个大语言模型对原始MCP池 $\mathcal{L}$ 中的每个MCP进行抽象处理。这个过程包括:
- 参数化:将硬编码的数值替换为可配置的参数。
- 上下文移除:剥离任务特定的引用,保留核心功能逻辑。
- 接口标准化:确保MCP遵循统一的调用协议,如FastMCP。
- 文档增强:生成清晰的文档字符串和类型注解。
经过抽象后,所有泛化后的MCP被统一存放到一个名为“MCP Box” ($\mathcal{B}$) 的仓库中。这个仓库保留了每个MCP的实现多样性,以最大化覆盖潜在的任务变化。
RAG增强的MCP选择
在推理阶段,当面对一个新任务 $x_{\text{new}}$ 时,为了从“MCP Box”中高效地筛选出最相关的工具,框架引入了基于检索增强生成(Retrieval-Augmented Generation, RAG)的选择机制。
- 上下文表示:对于“MCP Box”中的每个MCP,将其功能描述(description)和使用案例(use case)拼接成一个复合上下文表示。
-
语义嵌入与相似度计算:使用预训练的嵌入模型 $\phi$ 分别计算新任务查询 $x_{\text{new}}$ 和每个MCP上下文的嵌入向量 $\mathbf{e}_{\text{query}}$ 和 $\mathbf{e}_{m}$。然后通过余弦相似度计算它们之间的相关性得分 $s_m$。
\[s_{m}=\frac{\mathbf{e}_{\text{query}}\cdot\mathbf{e}_{m}}{\ \mid \mathbf{e}_{\text{query}}\ \mid _{2}\ \mid \mathbf{e}_{m}\ \mid _{2}}\] - 工具筛选:框架支持两种筛选策略:
- 阈值法 (Threshold-based): 选择相关性得分 $s_m$ 高于预设阈值 $\tau$ 的所有MCP。
- Top-K法 (Top-k): 选择相关性得分最高的 $K$ 个MCP。
这种RAG机制确保了智能体在执行任务时,只携带一个高度相关且精简的工具集,从而提升效率和准确性。
特化智能体架构与推理
最终生成的特化智能体 $\pi_{\text{specialized}}$ 集成了主智能体的核心推理能力、精心构建的“MCP Box”以及RAG工具选择机制。其架构主要包括:
- 任务分析器 (Task Analyzer):处理输入任务并生成嵌入表示。
- MCP检索器 (MCP Retriever):执行RAG选择算法,筛选相关工具。
- MCP执行器 (MCP Executor):提供运行时支持,动态调用选定的MCP。
在推理时,特化智能体首先分析任务,通过RAG从“MCP Box”中检索出一套定制化的工具集,然后在后续的推理和执行循环中调用这些工具来解决问题,从而实现了从通用能力到领域专长的转化。
实验结论
本文在GAIA、PathVQA和Humanity’s Last Exam (HLE) 等多个基准上进行了广泛实验,结果证明了Alita-G框架的有效性。
-
性能显著提升:Alita-G生成的特化智能体在所有基准上均超越了包括其自身“主智能体”在内的基线模型。特别是在高难度的GAIA基准上,Alita-G (3x) 取得了 83.03% 的 pass@1 和 89.09% 的 pass@3 准确率,创造了新的SOTA记录。这相对于ODR-smolagents (55.15%) 和Alita-G自身的主智能体 (75.15%) 都是巨大的提升。
-
“MCP Box”丰富度与性能正相关:实验通过对比单次执行生成(1x)和三次执行生成(3x)的“MCP Box”发现,更丰富的“MCP Box”(3x)能带来更高的准确率。这验证了多次执行能够捕获更全面、更鲁棒的工具集,从而提升智能体的解决能力。
-
准确率与效率双赢:特化智能体在取得更高准确率的同时,也显著提升了计算效率。在GAIA上,Alita-G (3x) 的平均Token消耗比其基线主智能体降低了约 15.5%。这得益于RAG机制提供的精准工具集,避免了智能体在大量无关工具中进行搜索,实现了性能和成本的双重优化。
下表展示了 Alita-G 与其他基线方法在不同基准测试上的性能对比。
| 方法 | 模型 | GAIA (pass@1/3) | PathVQA (pass@1) | HLE (pass@1) | 平均Tokens |
|---|---|---|---|---|---|
| OctoTools | GPT-4 | 48.00 / 52.00 | - | - | - |
| ODR-smolagents | GPT-4 | 55.15 / - | - | - | - |
| Alita-G Master Agent | Claude-Sonnet-4 | 75.15 / 80.00 | 52.00% | 24.00% | 12,305 |
| Alita-G (1x) | Claude-Sonnet-4 | 80.00 / 84.91 | 55.00% | 29.00% | 11,043 |
| Alita-G (3x) | Claude-Sonnet-4 | 83.03 / 89.09 | 60.00% | 33.00% | 10,394 |
- RAG内容分析:对RAG检索内容进行的消融实验表明,同时使用MCP的“功能描述”和“使用案例”作为检索依据时效果最好,在GAIA上的准确率达到83.03%。单独使用其中任何一个都会导致性能下降,证明了两者结合能提供最全面的上下文信息,以实现最精准的工具检索。
| RAG内容 | Level 1 | Level 2 | Level 3 | 平均值 |
|---|---|---|---|---|
| 描述 + 使用案例 | 86.79 | 83.13 | 70.76 | 83.03 |
| 仅描述 | 84.91 | 81.39 | 73.08 | 81.82 |
| 仅使用案例 | 83.01 | 79.06 | 61.53 | 77.57 |
最终结论是:本文提出的Alita-G框架为构建领域专家智能体提供了一个原则性且有效的方法。通过自动生成、抽象和检索复用MCP工具,该框架能够将通用智能体进化为在特定领域内更准确、更高效的专家,实现了性能和效率的双重提升。