All You Need is One: Capsule Prompt Tuning with a Single Vector
-
ArXiv URL: http://arxiv.org/abs/2510.16670v1
-
作者: Yiming Cui; Cheng Han; Wenhao Yang; Heng Fan; Qifan Wang; Lifu Huang; Xiaotian Han; Dongfang Liu; Yiyang Liu
-
发布机构: ByteDance; Case Western Reserve University; Lamar University; Meta AI; Rochester Institute of Technology; U.S. Naval Research Laboratory; University of California, Davis; University of Missouri-Kansas City; University of North Texas
TL;DR
本文提出了一种名为胶囊提示调优(Capsule Prompt Tuning, CaPT)的新型参数高效微调方法,通过将实例感知(instance-aware)信息和任务感知(task-aware)信息创新性地融合到一个单一的“胶囊”提示向量中,解决了传统提示学习方法依赖繁琐的长度搜索且与输入序列交互不足的问题。
关键定义
- 胶囊提示调优 (Capsule Prompt-Tuning, CaPT):一种新颖的提示调优框架。它在模型的每一层使用一个单一的可学习“胶囊”向量,该向量与从输入实例中动态提取的均值表示相结合,形成一个既包含任务级指导又包含实例级语义的自适应提示。
- 注意力锚点 (Attention Anchor):本文发现的一个现象。指将一个蕴含实例信息的Token放置在序列最前端时,该Token能够与输入序列中的关键结构信息(如分隔符、关键词)建立强大的注意力连接,并被输入序列中的其他Token持续关注。这种机制能有效引导模型的注意力,加强指导信号与输入内容的互动。
- 胶囊提示 (Capsule Prompt):CaPT方法中用于指导模型的核心元素。在模型的第 \(i\) 层,它由一个可学习的参数向量 \(p^i\) 和一个从前一层输出(或初始输入)中计算出的实例感知均值表示相加而成。这个单一的向量 \(S^i\) 既紧凑又信息丰富。
相关工作
当前,参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,特别是基于软提示(soft prompts)的提示学习,已成为使大语言模型(LLMs)适应下游任务的主流范式。然而,现有方法存在两大瓶颈:
- 缺乏与实例的有效交互:传统的软提示主要编码任务感知(task-aware)信息,以一种“一刀切”的方式指导模型。本文的初步研究发现,这些提示在注意力机制中主要关注彼此,而与输入序列中的关键结构化信息缺乏有效的互动,这限制了模型对不同输入语义的适应能力。
- 依赖繁琐的超参数搜索:确定最佳的提示长度通常需要进行耗时和计算密集型的网格搜索。这不仅增加了训练开销,而且过长或设计不当的提示甚至可能损害模型性能。
本文旨在解决上述两个问题,即如何设计一种既能有效融入实例感知(instance-aware)信息以增强与输入的互动,又能摆脱对提示长度搜索依赖的高效提示学习方法。
本文方法
关键发现
本文的动机源于对现有软提示方法的两个关键洞察:
软提示的注意力局限性
通过分析深度提示调优(Deep Prompt-Tuning)的注意力图谱,本文发现标准软提示存在一个显著问题:它们主要将注意力集中在提示内部(自注意力),而很少关注输入文本中承载关键结构和语义信息的Token(如“sentence”、“1”、“:”等)。相比之下,输入文本的Token本身倾向于关注这些关键结构。这表明,纯任务感知的设计使软提示与输入内容在语义层面产生了脱节。
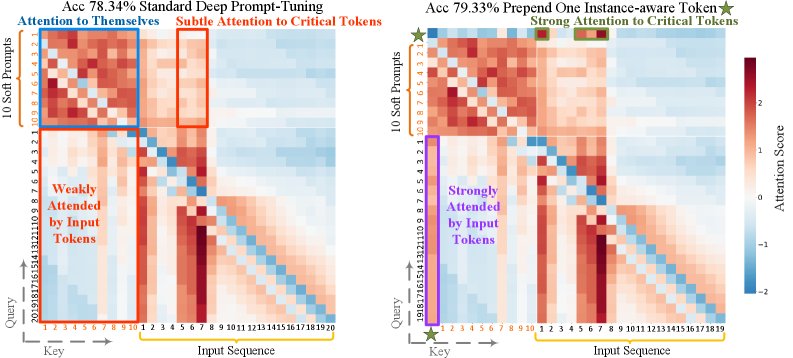 注意力分数在T5-Base的RTE验证集上对所有头和编码器层取平均。深红色表示高注意力,深蓝色表示低注意力。左图为使用10个软提示的传统方法,右图为在软提示前增加一个实例感知Token。
注意力分数在T5-Base的RTE验证集上对所有头和编码器层取平均。深红色表示高注意力,深蓝色表示低注意力。左图为使用10个软提示的传统方法,右图为在软提示前增加一个实例感知Token。
实例感知信息的潜力
为了解决上述问题,本文进行了一项初步研究,即在不进行额外微调的情况下,直接将输入序列通过池化压缩成一个或多个实例感知的Token,并将其添加到软提示之前。
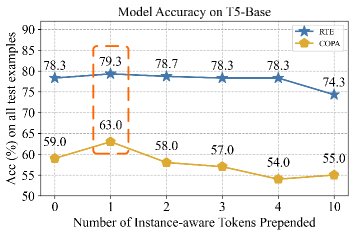 结果显示,即使在测试时简单地加入一个(长度为1)实例感知Token,模型在RTE和COPA任务上的准确率也得到了显著提升。
结果显示,即使在测试时简单地加入一个(长度为1)实例感知Token,模型在RTE和COPA任务上的准确率也得到了显著提升。
这一惊人的结果揭示了实例感知信息的巨大潜力。进一步的注意力分析(如上图右侧所示)发现,这个单一的实例感知Token表现出一种截然不同的行为:
- 它能持续地将注意力投向输入序列中的关键结构Token。
- 它能成功地吸引来自输入序列中其他Token的注意力。
本文将这种现象命名为“注意力锚点”(Attention Anchor),它像一个锚一样,将指导信号(prompt)和输入内容(input)紧密地联系起来,促进了上下文信息的有效流动。这一发现构成了本文方法的核心基础。
胶囊提示调优 (CaPT)
基于以上发现,本文提出了胶囊提示调优(CaPT),一个轻量级、自适应的提示框架。其核心思想是用一个高质量的、动态生成的单一“胶囊提示”取代传统的多个静态软提示。
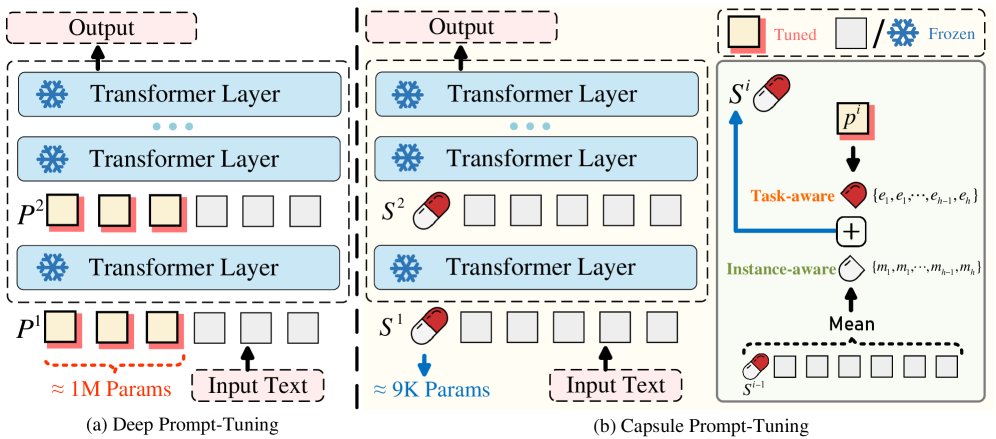
CaPT的整体架构如上图(b)所示。具体而言,其工作流程如下:
在每个Transformer层 \(i\),CaPT引入一个可学习的向量 \(p^i\),它编码了任务感知的通用指导。该层的最终提示 \(S^i\) 是由 \(p^i\) 和一个从前一层输出中提取的实例感知信息相加动态生成的。
形式上,对于第 $i$ 层:
- 生成实例感知信号:
- 对于第一层 ($i=1$),实例感知信号由输入嵌入 $E$ 的均值产生:$\texttt{Mean}(E)$。
- 对于后续层 ($i \geq 2$),实例感知信号由前一层处理后的提示输出 $\underline{S}^{i-1}$ 和序列表示 $H^{i-1}$ 拼接后的均值产生:$\texttt{Mean}(\underline{S}^{i-1}\oplus H^{i-1})$。
-
构建胶囊提示: 将可学习向量 \(p^i\) 与实例感知信号相加,得到该层的胶囊提示 \(S^i\)。
\[{\color[rgb]{0,0.5,0}S^{i}} = {\color[rgb]{0.87109375,0.3203125,0.22265625}p^{i}} + \texttt{Mean}(\dots)\] -
模型前向传播: 将胶囊提示 \(S^i\) 与该层的输入 \(H^(i-1)\) 拼接,送入Transformer层 \(L_i\) 进行处理,得到新的输出 $\underline{S}^{i}$ 和 $H^{i}$。
\[\underline{S}^{i},H^{i} = {\color[rgb]{0.12890625,0.3984375,0.78515625}L_{i}}({\color[rgb]{0,0.5,0}{S^{i}}}, H^{i-1})\]
创新点
- 信息融合:CaPT的核心创新在于将静态、可学习的任务感知向量 \(p^i\) 与动态、依赖输入的实例感知信号 \(Mean(...)\) 相结合,创造出一个单一但功能强大的胶囊提示。
- 质量优于数量:它摒弃了依赖大量软提示的传统思路,转而关注如何提升单个提示的质量和信息密度。
- 动态自适应:每层的提示都会根据前一层的输出来动态调整,使指导信号在整个模型中能够与不断演变的上下文表示保持对齐。
优点
- 极致的参数效率:每层仅增加一个可学习向量,使其成为一种“几乎无参数”的微调方法。
- 消除长度搜索:由于提示长度固定为1,完全避免了传统提示学习中耗时费力的网格搜索过程。
- 强大的上下文关联:通过构建“注意力锚点”,显著增强了指导信号与输入内容之间的互动,从而改善了模型的上下文理解能力和最终性能。
实验结论
| 模型 | 可调参数 | FT | Head | P-Tuning v2 | XPrompt | CaPT (本文) |
|---|---|---|---|---|---|---|
| T5-Base | 220M | 83.20 | 79.99 | 82.26 | 82.49 | 82.90 |
| (可调%) | 100% | 0.05% | 0.1% | 0.1% | 0.003% | |
| T5-Large | 770M | 83.60 | 80.52 | 83.00† | 83.18 | 84.03 |
| (可调%) | 100% | 0.02% | 0.1% | 0.1% | 0.001% | |
| Llama3.2 | 1B | - | 79.35 | 80.20 | - | 80.89 |
| (可调%) | - | 0.01% | 0.15% | - | 0.001% | |
| Qwen-2.5 | 1.5B | - | 80.40 | 81.65 | - | 82.01 |
| (可调%) | - | 0.01% | 0.12% | - | 0.0009% |
在SuperGLUE上的平均准确率(%)。FT指全量微调,Head指仅微调分类头。
实验结果证明了CaPT方法的有效性和高效性:
- 性能优越:如上表所示,CaPT在各种规模和架构的模型上(包括Encoder-Decoder的T5和Decoder-only的Llama、Qwen)均取得了持续优异的性能。在T5-Base上,它显著缩小了与全量微调的差距;在T5-Large上,其性能甚至超越了全量微调0.43%,同时优于P-Tuning v2等强基线方法。
- 参数效率极高:CaPT的可调参数量极低(在所有模型上均≤0.003%),远低于其他PEFT方法,展现了其“几乎无参数”的特性。
- “注意力锚点”的验证:实验中的注意力可视化分析证实,与使用单个软提示的基线相比,CaPT的胶囊提示能够更成功地与输入序列建立双向的、上下文敏感的注意力连接,验证了“注意力锚点”的有效性。
- 表现平平的场景:一个有趣的观察是,CaPT在Decoder-only模型(Llama3.2, Qwen-2.5)上的性能提升幅度相较于Encoder-Decoder模型(T5)要小。本文推测这可能与模型架构和预训练目标的内在差异有关。
最终结论是,CaPT作为一个简单而强大的提示学习框架,通过创新地融合实例感知和任务感知信息,不仅实现了顶尖的性能和极致的参数效率,还为设计更懂上下文的提示方法提供了新的视角。