AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
-
ArXiv URL: http://arxiv.org/abs/2305.14387v4
-
作者: Carlos Guestrin; Percy Liang; Jimmy Ba; Ishaan Gulrajani; Tatsunori Hashimoto; Tianyi Zhang; Xuechen Li; Yann Dubois; Rohan Taori
-
发布机构: Stanford; University of Toronto
TL;DR
本文提出了AlpacaFarm,这是一个旨在使用大型语言模型(LLM)模拟人类反馈,从而以低成本、高效率地研究、开发和评估人类反馈学习方法的仿真框架。
关键定义
- AlpacaFarm:一个为研究“从人类反馈中学习”的方法而设计的模拟框架(simulation framework)。它包含三个核心组件:
- 模拟偏好生成器:使用API形式的大型语言模型(如GPT-4)代替人类标注员,生成成对偏好数据。
- 自动化评估协议:一个自动化的评估流程,通过计算模型输出与参考模型(Davinci003)输出之间的胜率(win-rate)来衡量模型性能。
- 参考方法实现:一套已验证的、流行的“从成对反馈中学习”(LPF)算法的参考实现,如PPO、Best-of-n等。
- 从成对反馈中学习 (Learning from Pairwise Feedback, LPF): 本文研究的核心问题设置。其流程为:针对一个给定的指令(instruction)$x$,模型生成两个候选响应 $(y_0, y_1)$,然后由标注员(人类或模拟器)选择更优的一个。算法基于这些成对的偏好数据 ${(x, y_0, y_1, z)}_{j}$ 进行学习和优化,其中 $z$ 表示哪个响应更优。
- 模拟偏好 (Simulated Preference) $p_{\text{sim}}$: AlpacaFarm的核心技术,指通过精心设计的提示(prompt)让大型语言模型来模仿人类对两个候选响应的偏好判断。其关键在于不仅追求与人类判断的高一致性,还通过混合多个不同提示的“模拟标注员”并注入随机噪声来模拟真实人类标注的多样性与不确定性。
- 监督微调 (Supervised Fine-tuning, SFT): 在进行LPF之前的初始步骤。使用一组高质量的“指令-响应”对来微调一个预训练好的语言模型,使其具备初步的指令遵循能力。这个SFT模型是所有后续LPF方法的起点。
相关工作
当前,诸如ChatGPT等大型语言模型通过从人类反馈中学习(尤其是强化学习,RLHF)获得了强大的指令遵循能力。然而,这一过程由于缺乏公开的实现细节而显得非常神秘和难以复现。研究和改进这些方法面临三大瓶颈:
- 高昂的成本:收集人类反馈数据既耗时又昂贵。
- 缺乏可靠的评估:对开放式生成任务的评估通常需要人类参与,这使得评估过程不具有可复现性且成本高。
- 缺少参考实现:像PPO等关键算法在指令遵循场景下的有效、公开的实现非常稀少。
本文旨在解决上述三大挑战,通过创建一个名为AlpacaFarm的低成本、可复现、且经过验证的仿真框架,来加速对指令遵循模型的研发和理解。
本文方法
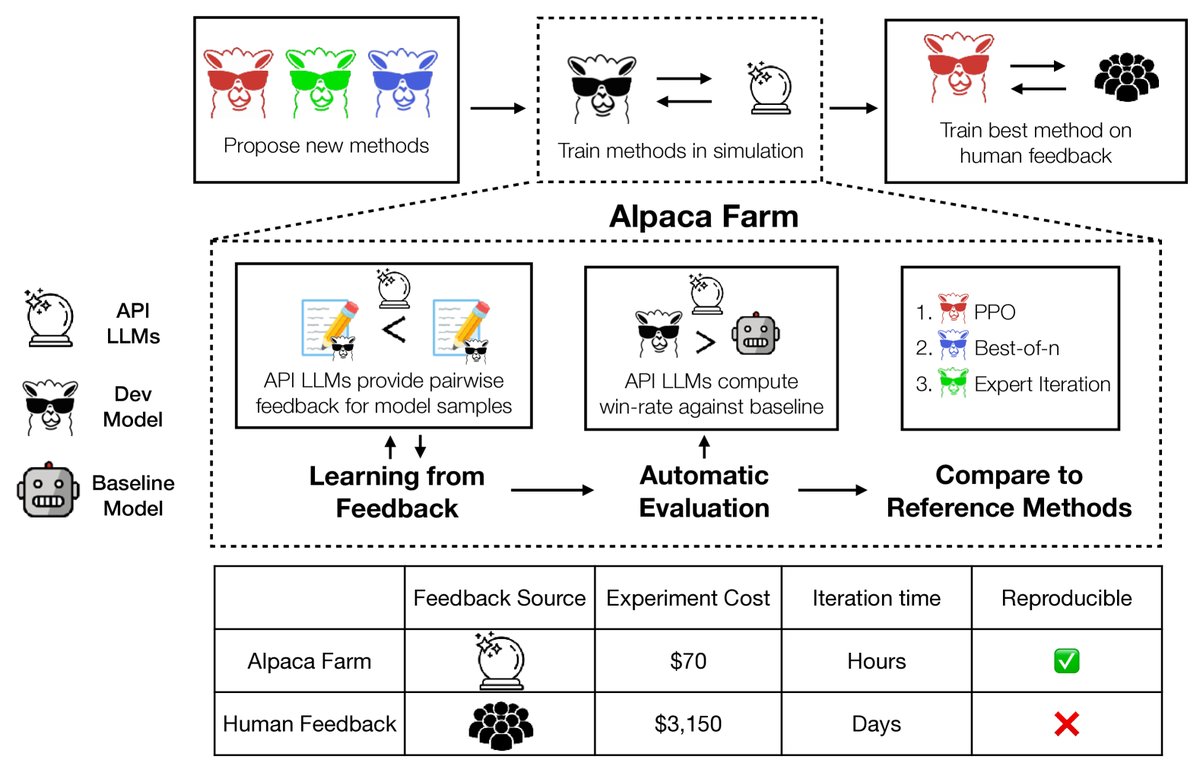
图1: AlpacaFarm是一个模拟沙盒,能够对从人类反馈中学习的大型语言模型进行快速且廉价的实验。它通过(预言机)API LLM模拟人类反馈,提供经过验证的评估协议,并提供一套参考方法实现。
AlpacaFarm的构建围绕三个核心组件展开,旨在为从成对反馈中学习(LPF)的研究提供一个完整的工具链。
1. 模拟成对偏好反馈 $p_{\text{sim}}$
本文方法的核心创新在于设计了一个能够低成本、高保真地模拟人类偏好判断的模拟器。
- 基本思路:使用强大的API LLM(如GPT-4)来代替人类标注员。通过向LLM提供指令、两个候选响应以及评分标准,让其输出哪个响应更好。
- 创新点:模拟人类可变性:与仅仅追求高一致性的简单模拟器不同,AlpacaFarm的模拟器旨在捕捉真实人类反馈中的“噪声”和“不一致性”,因为这正是LPF任务的挑战之一。
- 模拟标注员间差异 (Inter-annotator variability):创建了一个包含13个不同“模拟标注员”的池子。每个模拟标注员使用不同的API模型(如GPT-4, ChatGPT)、不同的提示格式、不同的上下文示例(in-context examples)或不同的批处理大小来产生判断,以此模仿不同人类标注员的偏好差异。
- 模拟标注员内差异 (Intra-annotator variability):在训练数据生成阶段,以25%的概率随机翻转模拟标注员的偏好选择,注入无偏噪声,以模拟单个标注员可能出现的判断摇摆。
通过这种设计,生成的模拟偏好数据比人类众包便宜约50倍,同时能更好地复现真实训练动态(如奖励过优化现象)。
2. 自动化评估协议
为了快速迭代和比较不同方法,AlpacaFarm建立了一套自动化的评估流程。
- 评估指标:采用胜率 (win-rate)。将待评估模型的输出与一个固定的参考模型(本文使用Davinci003)的输出进行成对比较,计算待评估模型被认为更优的百分比。这个比较过程由一个专门的评估模拟器 $p_{\text{sim}}^{\text{eval}}$ 完成(该模拟器使用13个标注员的池子,但不注入随机噪声)。
- 评估指令集:为了使评估具有代表性,本文构建了一个包含805条指令的评估集。该集合并非随意创建,而是通过分析真实世界用户与Alpaca Demo的交互数据,然后组合了多个公开的评估数据集(如Self-instruct, OASST, Vicuna等)来模仿真实用户查询的分布和多样性。
| 来自AlpacaFarm评估数据的示例指令 |
|---|
| Discuss the causes of the Great Depression |
| Make a list of desirable Skills for software engineers to add to LinkedIn. |
| I’m trying to teach myself to have nicer handwriting. Can you help? |
| What if Turing had not cracked the Enigma code during World War II? |
| Take MLK speech “I had a dream” but turn it into a top 100 rap song |
表1: AlpacaFarm评估数据中的指令示例。

图2: 评估指令的根动词分布,显示了其多样化的覆盖范围。
3. 参考方法实现
AlpacaFarm提供了对多种LPF方法的经过验证的参考实现,为后续研究提供了坚实的基线。这些方法都从一个经过监督微调(SFT)的LLaMA 7B模型开始。
- 直接作用于成对偏好的方法:
- Binary FeedME: 只在成对比较中胜出的响应上继续进行监督微调。
- Binary reward conditioning: 将“胜出”或“落败”的标签作为前缀加入输入,然后进行微调。
- Direct Preference Optimization (DPO): 一种直接根据偏好数据优化策略的方法。
- 基于代理奖励模型的方法: 这类方法首先训练一个奖励模型来预测偏好,然后通过该奖励模型来优化策略。
- Best-of-$n$: 在推理时,从模型生成 $n$ 个样本,然后用奖励模型选出最优的一个。
- Expert iteration: 将Best-of-$n$选出的最优样本作为新的高质量数据,用于进一步微调模型。
- PPO (Proximal Policy Optimization): 一种强化学习算法,最大化奖励模型给出的分数,同时通过KL散度惩罚项防止模型偏离初始SFT模型太远。
- Quark: 一种改进的训练方法,根据奖励分数对样本分箱,并主要在最高分的箱内进行训练。
实验结论
端到端验证:模拟器能有效预测真实世界排名
这是本文最重要的结论:在AlpacaFarm中训练和评估的方法排名,与使用真实人类反馈进行训练和评估的排名高度一致。 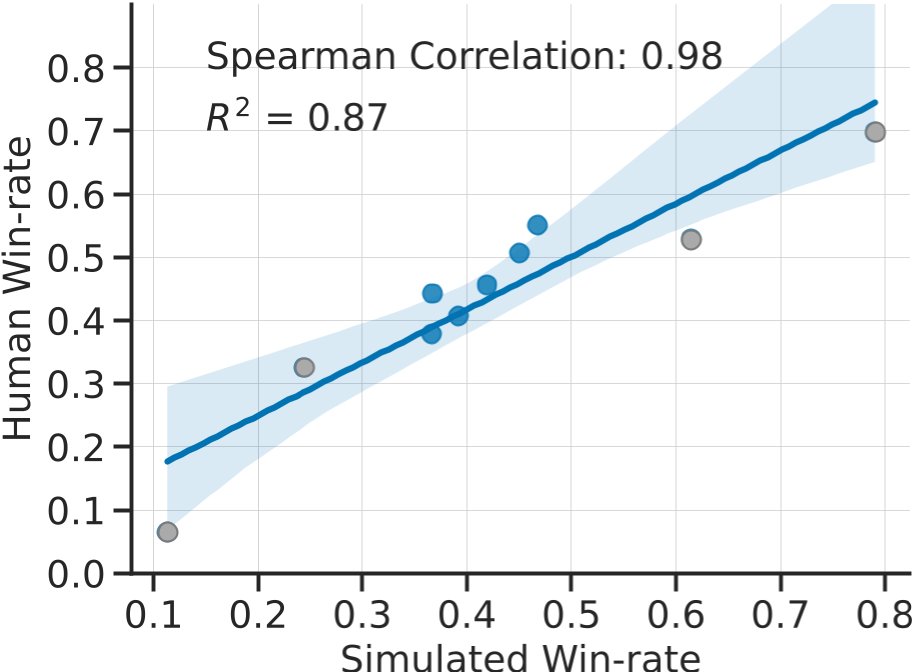
图3: 方法在AlpacaFarm(x轴)和真实人类反馈流程(y轴)中的胜率对比。两者的排名表现出极高的相关性(Spearman相关系数为0.98),证明了AlpacaFarm作为方法开发工具的有效性。
模拟器组件验证
- 偏好模拟器复刻了人类的关键特征:
- 高一致性与低成本: AlpacaFarm的评估模拟器 $p_{\text{sim}}^{\text{eval}}$ 与人类多数票的一致性达到65%,与人类标注员之间的平均一致性(66%)相当,而成本仅为人类标注的1/25。
- 可变性是关键: 实验证明,简单的、低可变性的GPT-4模拟器虽然一致性更高,但无法复现奖励过优化(over-optimization)现象。而AlpacaFarm通过模拟人类标注的可变性,成功再现了这一现象:随着模型在代理奖励上分数持续走高,其真实胜率(由人类或评估模拟器判断)先升后降。这表明AlpacaFarm的模拟器设计是正确且必要的。

图5: (左)人类反馈、(中)AlpacaFarm模拟器和(右)简单的GPT-4模拟器下的训练动态。前两者均表现出明显的奖励过优化(y轴胜率先升后降),而后者则没有,这会误导方法开发。
- 评估协议具有现实代表性:
- AlpacaFarm的评估指令集上得到的模型胜率,与在真实的Alpaca Demo用户查询数据集上得到的胜率高度相关($R^2=0.97$),证明该评估集可以作为真实世界简单交互场景的有效代理。
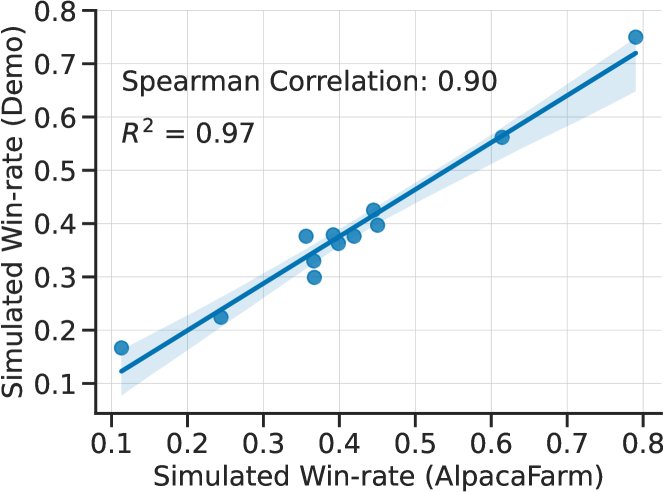
图6: AlpacaFarm评估集上的胜率(y轴)与真实世界Alpaca Demo交互数据上的胜率(x轴)的相关性图。
LPF方法基准测试
在AlpacaFarm和真实人类数据上的实验得到了一致的结论:
| 方法 | 模拟胜率 (%) | 人类胜率 (%) |
|---|---|---|
| GPT-4*† | $79.0\pm 1.4$ | $69.8\pm 1.6$ |
| ChatGPT*† | $61.4\pm 1.7$ | $52.9\pm 1.7$ |
| PPO | $46.8\pm 1.8$ | $55.1\pm 1.7$ |
| DPO | $46.8\pm 1.7$ | - |
| Best-of-1024 | $45.0\pm 1.7$ | $50.7\pm 1.8$ |
| Expert Iteration | $41.9\pm 1.7$ | $45.7\pm 1.7$ |
| SFT 52k | $39.2\pm 1.7$ | $40.7\pm 1.7$ |
| SFT 10k | $36.7\pm 1.7$ | $44.3\pm 1.7$ |
| Binary FeedME | $36.6\pm 1.7$ | $37.9\pm 1.7$ |
| Quark | $35.6\pm 1.7$ | - |
| Binary Reward Conditioning | $32.4\pm 1.6$ | - |
| Davinci001* | $24.4\pm 1.5$ | $32.5\pm 1.6$ |
| LLaMA 7B* | $11.3\pm 1.1$ | $6.5\pm 0.9$ |
表2: 各方法对Davinci003的胜率。PPO和Best-of-n在SFT基线之上有显著提升。
- SFT效果显著:仅监督微调(SFT)一步就带来了大部分性能提升。
- PPO表现最佳:在所有训练时(training-time)LPF方法中,PPO表现最好,将人类评估的胜率从SFT的44%提升至55%。
- Best-of-n简单有效:作为一种推理时(inference-time)方法,Best-of-n表现非常有竞争力,仅次于PPO,说明了奖励模型的有效性。
- 部分方法效果不佳:直接从成对偏好学习的方法(如Binary FeedME)以及Expert Iteration和Quark,相较于SFT基线没有明显提升。
- 输出分析:性能提升的一个重要原因是模型学会了生成更长、更详细的回答,这同时被模拟器和人类标注员所偏爱。
总结
AlpacaFarm是一个成功构建的、经过端到端验证的仿真框架。它能够可靠地预测不同LPF方法在真实人类反馈下的相对表现,从而极大地降低了相关研究的成本和周期。基准测试结果表明,基于奖励模型的PPO和Best-of-n是提升指令遵循能力的有效方法。