Are Large Language Models Sensitive to the Motives Behind Communication?
-
ArXiv URL: http://arxiv.org/abs/2510.19687v1
-
作者: Kerem Oktar; Addison J. Wu; Ryan Liu; Thomas L. Griffiths
-
发布机构: Anthropic; Princeton University
TL;DR
本文通过借鉴认知科学的理性模型,系统性地研究了大型语言模型(LLMs)是否能像人类一样识别和评估沟通背后的动机(即“动机警惕性”),发现它们在受控实验中表现出类似人类的能力,但在复杂的现实世界场景中表现不佳,不过简单的引导提示可以改善其表现。
关键定义
本文引入或重点使用了以下几个核心概念:
-
动机警惕性 (Motivational Vigilance):源于社会认知理论,指个体在接收信息时,能够主动追踪信息来源的意图 (intentions) 和激励 (incentives),从而判断信息是否带有偏见(例如,是善意的还是自私的),并据此决定应在多大程度上信任和采纳该信息。这是人类进行选择性社会学习的关键能力。
-
理性模型 (Rational Model):本文采用认知科学家 Oktar 等人提出的理性模型作为评估 LLM 动机警惕性的“黄金标准”。该模型将警惕性形式化为一种递归的社会推理过程:听者通过推理说话者的意图和激励来评估信息,而说话者则通过预判听者的推理来选择最能实现其沟通目标的言辞。
-
有意传达的信息 (Deliberately Communicated Information):指说话者为了影响听者而特意传达的信息,例如产品推销或建议。
-
偶然观察到的信息 (Incidentally Observed Information):指并非为了直接说服听者而无意中透露的信息,例如偷听到的他人真实想法或日记内容。这两种信息的区分是测试基础警惕能力的第一步。
相关工作
当前,LLMs 处理的大部分在线信息都源于人类有目的的沟通,这些信息不可避免地受到个人动机和激励因素的影响。然而,现有研究表明 LLMs 在这方面存在明显缺陷,例如易受“越狱”攻击、表现出“奉承”(sycophancy)行为(即附和用户的错误观点而非陈述事实)、容易被在线环境中的误导性信息(如弹窗广告)干扰。这些问题暴露出 LLMs 训练范式中的一个核心瓶颈:过度优先考虑遵循用户指令和满足用户偏好,而缺乏对信息来源动机的批判性审查能力。
尽管已有研究探讨了 LLMs 的心智理论 (Theory of Mind)、从众行为等社会能力,但目前学术界仍缺乏一个系统性的框架来衡量 LLM 在处理带有动机的沟通时的“警惕性”。
本文旨在填补这一空白,通过引入认知科学中成熟的理论和实验范式,首次对 LLM 的动机警惕性进行全面、严谨的量化评估。
本文方法
本文设计了三个递进的实验范式,以评估 LLM 在不同情境下的动机警惕性能力。
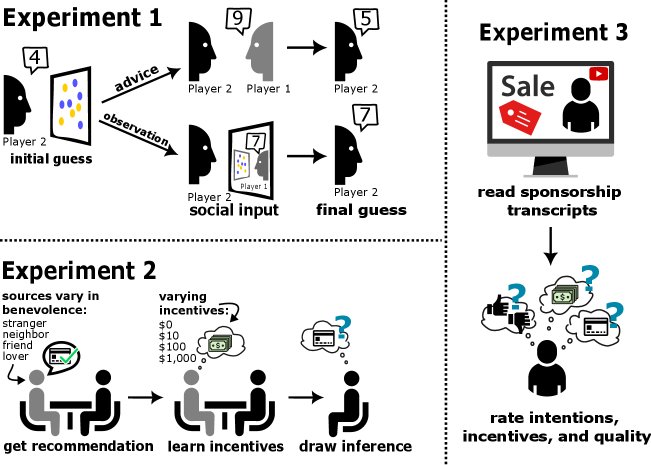
实验 1: 区分不同信息来源
该实验旨在测试 LLM 是否具备最基本的警惕能力,即区分“有意传达的信息”和“偶然观察到的信息”。
- 实验设置:本文改编了经典的双人判断任务。任务中,两名玩家(均由 LLM 扮演)需计算图片中蓝黄圆圈的数量差。玩家2 会收到来自玩家1 的信息,该信息可能是玩家1 故意给出的“建议”(有意传达),也可能是玩家2“窥探”到的玩家1 的真实答案(偶然观察)。实验还设置了合作与竞争两种不同的激励结构。
- 创新点:为解决 LLM 不受人类实验中时间限制影响的问题,本文通过向图片中添加噪声来增加任务难度,从而有效诱导 LLM 的不确定性,使其能够表现出信念更新的过程。
实验 2: 对动机进行精细校准
该实验旨在测试 LLM 是否能像人类一样,根据说话者的意图(如亲疏远近)和激励(如佣金高低)来精细地调整其信任程度。
- 方法核心:本文引入 Oktar 等人提出的理性模型作为评估基准。该模型通过数学公式刻画了听者如何根据说话者的善意度 \(λ\)、自身收益 \(R_L\) 和说话者收益 \(R_S\) 进行推理。
- 说话者的联合效用由其善意度 \(λ\) 决定:
- 说话者选择某个言论 \(u\) 的概率取决于该言论可能带来的联合效用:
- 警惕的听者通过贝叶斯推理,反向推断被推荐选项的真实价值 \(R_L\):
-
实验设置:在金融、房地产和医疗等场景中,让 LLM 评估来自不同可信度(角色)和激励水平的说话者所给出的产品推荐。通过提示,引出 LLM 对说话者的“信任分数”(对应 \(λ\))、“激励分数”(对应 \(R_S\))和“影响分数”(对应 $$P(R_L u)$$),并将其“影响分数”与基于其自身信任和激励分数的理性模型预测值进行比较。
实验 3: 在真实场景中的泛化能力
该实验旨在测试 LLM 在受控环境中习得的警惕性是否能迁移到充满噪声和复杂上下文的真实世界场景中。
- 数据集构建:本文创建了一个全新的、更贴近生态效度的测试集。通过 SponsorBlock 和 YouTube API,搜集了 300 个真实的 YouTube 视频赞助广告片段,并提取了其标题、频道信息和广告脚本。为避免模型先验知识的干扰,所有品牌和产品名称均被匿名化处理。
- 实验设置:类似于实验2,让 LLM 评估每个赞助视频中推广的产品质量、YouTuber 的可信度以及 YouTuber 从中获得的激励。然后,再次将其判断与理性模型的预测进行比较,以衡量其在自然情境下的警惕性。
实验结论
实验 1: LLM 具备基础的辨别能力
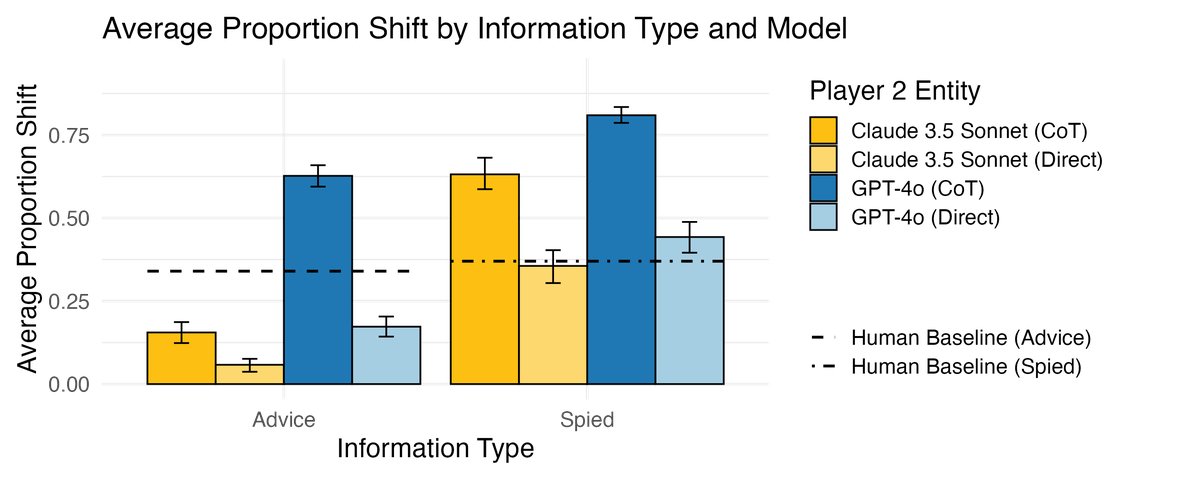
- LLMs 能够成功区分有意图的建议和无意图的观察信息。它们在收到“建议”时,对其答案的调整幅度显著小于收到“窥探”到的答案时,这与人类行为一致,表明 LLM 具备基本的动机警惕性。
- 一个有趣的发现是,思维链 (CoT, Chain-of-Thought) 提示虽然能增强推理,但也会让 LLM 对外部信息更加信任,导致其行为模式反而偏离了人类的警惕性特征。
实验 2: 前沿 LLM 在受控场景中表现出高度理性的警惕性
- 前沿模型表现优异:顶级的非推理型 LLMs(如 GPT-4o, Claude 3.5 Sonnet)表现出与理性模型高度一致的警惕行为,其判断与模型预测值的相关性(Pearson’s r)普遍在 0.8 到 0.9 之间,其中 GPT-4o 表现最佳(平均 $r = 0.911$)。
- LLM 比理性模型更“像人”:这些前沿模型的判断与人类数据的相关性甚至高于理性模型,这表明它们可能捕捉到了一些人类在评估建议时使用的、理性模型之外的启发式或偏见。
- 模型能力与规模正相关:相比之下,推理专用模型(如 o1, DeepSeek-R1)和小型模型(如 Llama 3.1-8B)的警惕性表现要差得多,其判断与理性模型的相关性较低。这表明动机警惕性是一种随着模型规模和能力提升而涌现的能力。
| 模型 (Model) | 与理性模型的相关性 (Corr. with rational model) | 与人类数据的相关性 (Corr. with human data) |
|---|---|---|
| GPT-4o | 0.911 | 0.871 |
| Claude 3.5 Sonnet | 0.865 | 0.817 |
| Gemini 1.5 Flash | 0.803 | 0.763 |
| Llama 3.1-70B | 0.781 | 0.749 |
| anyscale/o2-22b | 0.724 | 0.692 |
| anyscale/o1-70b | 0.697 | 0.639 |
| Llama 3.1-8B | 0.603 | 0.583 |
| anyscale/o3-mini | 0.536 | 0.509 |
| Gemma 2-9B | 0.490 | 0.457 |
| Llama 3.1-4.5B | 0.389 | 0.364 |
| DeepSeek-R1 | 0.326 | 0.301 |
实验 3: 警惕性在真实场景中失效,但可被引导
- 泛化能力差:在面对真实的 YouTube 广告时,所有 LLM 的动机警惕性都急剧下降,其判断与理性模型的预测相关性骤降至 $r < 0.2$。这表明,在复杂、充满噪声的真实环境中,模型难以有效利用其潜在的警惕能力,容易被无关信息分散注意力。
- 引导提示有效:然而,一个简单的干预措施——使用基于警惕性的提示词引导 (vigilance-based prompt steering),即在提示中明确强调说话者的意图和激励——能够显著提升 LLM 的表现,使其判断与理性模型的一致性大幅增加。
总结
本文的研究表明,当前的 LLMs 拥有一种潜在的、基础的动机警惕性,使其能够在简单的、受控的环境中对信息来源的动机进行推理。然而,这种能力非常脆弱,在没有明确指导的情况下,很难泛化到充满挑战的现实世界应用中。为了让 LLM 智能体在真实世界中安全、有效地为用户服务,未来的研究需要进一步提升模型将这种潜在能力稳健地应用于复杂场景的泛化能力。