ARM-FM: Automated Reward Machines via Foundation Models for Compositional Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2510.14176v1
-
作者: Pablo Samuel Castro; Glen Berseth; Roger Creus Castanyer; Faisal Mohamed; Cyrus Neary
-
发布机构: Google DeepMind; Mila – Quebec AI Institute; The University of British Columbia; Université de Montréal
TL;DR
本文提出了ARM-FM框架,利用基础模型(Foundation Models, FMs)从自然语言指令中自动生成奖励机(Reward Machines, RMs),为组合式强化学习(Compositional Reinforcement Learning)提供结构化的奖励信号,以解决长时程、稀疏奖励任务并实现泛化。
关键定义
本文的核心是提出了一种新型的奖励机,并在此基础上构建了整个框架。
- 奖励机 (Reward Machines, RMs):本文沿用已有的定义。奖励机是一种有限状态自动机,用于编码复杂的、具有时序性的强化学习任务。其形式化定义为元组 $\langle U, u_I, \Sigma, \delta, R, F, \mathcal{L} \rangle$,其中:
- $U$: 有限的状态集合,每个状态代表一个子任务。
- $u_I$: 初始状态。
- $\Sigma$: 触发状态转移的事件符号集合。
- $\delta$: 状态转移函数。
- $R$: 奖励函数,根据当前RM状态和环境转移给出奖励。
- $F$: 最终状态集合,表示任务完成。
- $\mathcal{L}$: 标签函数,将底层的环境状态和动作映射到RM的事件符号。
- 语言对齐奖励机 (Language-Aligned Reward Machines, LARMs):这是本文提出的核心概念。LARM是一种特殊的奖励机,它为每个RM状态 $u$ 额外配备了(1)一段自然语言指令 $l_u$ 和(2)一个嵌入函数 $\phi(\cdot)$,该函数将语言指令 $l_u$ 映射到一个嵌入向量 $z_u = \phi(l_u)$。这个嵌入向量 $z_u$ 使得具有相似语义的子任务(如“拿起蓝钥匙”和“拿起红钥匙”)在表示空间中彼此接近,从而为策略的知识共享、技能迁移和零样本泛化提供了机制。
相关工作
当前强化学习领域在奖励函数设计上面临核心挑战:
- 奖励稀疏:在许多复杂任务中,智能体(Agent)很难通过随机探索获得有效的学习信号。
- 奖励函数设计困难:手动设计密集的奖励函数不仅耗时耗力,还容易出现漏洞,导致智能体“钻空子”(Reward Hacking)。
- 高级规划与低级控制脱节:虽然基础模型(FMs)擅长从自然语言中理解和分解高级任务,但它们生成的抽象计划难以转化为强化学习所需的具体、结构化的奖励信号,导致智能体无法有效学习。
- 奖励机(RMs)的局限:RMs作为一种理论上优秀的任务分解和奖励规范形式,因其设计过程复杂且需要专家手动构建,其实际应用受到了极大限制。
本文旨在解决上述问题,特别是如何将FMs的高级推理能力与RL的低级控制需求相结合,通过自动化构建RMs来弥合这一差距,从而将模糊的人类意图转化为具体、可执行的学习信号。
本文方法
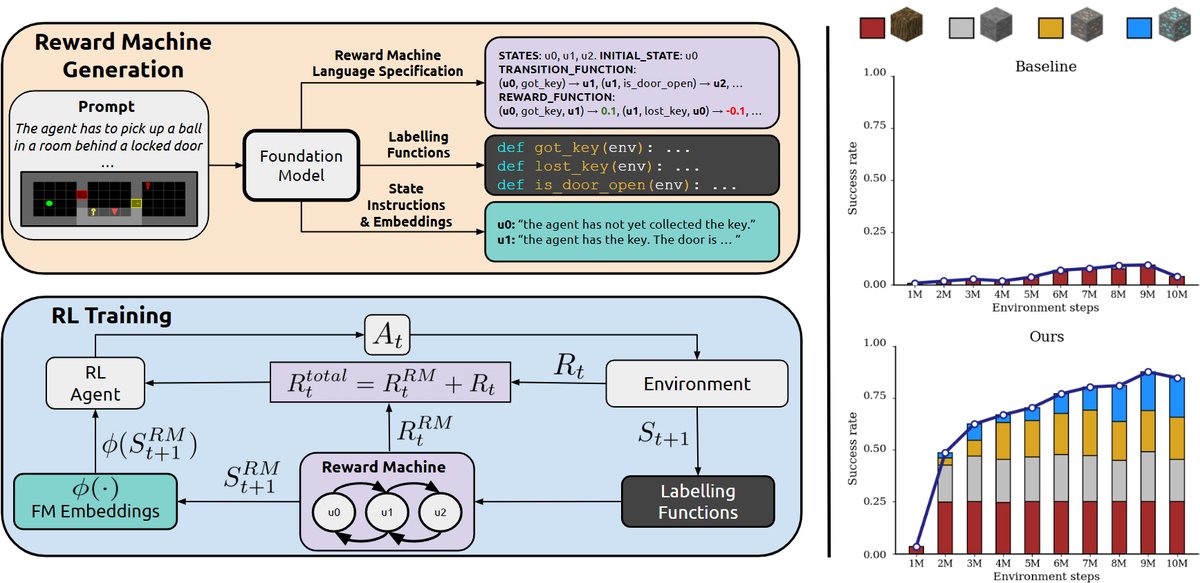
本文提出了一种名为ARM-FM(Automated Reward Machines via Foundation Models)的自动化奖励设计框架。该框架利用FMs的推理能力,将复杂的自然语言任务描述自动翻译成结构化的任务表示,供强化学习训练使用。
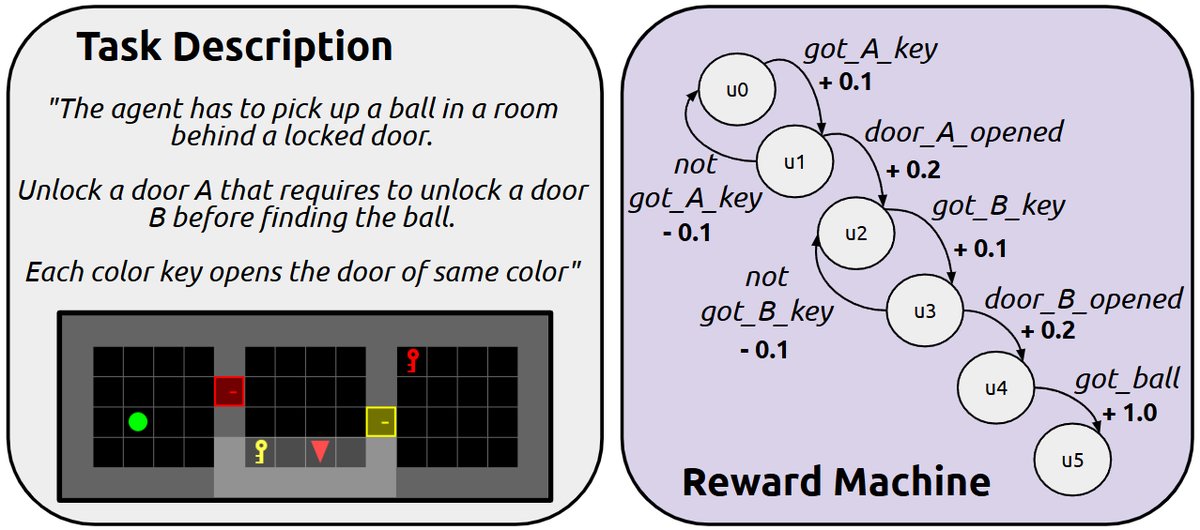
整个框架包含两大核心组件:一是使用FMs自动构建语言对齐奖励机(LARMs),二是通过将策略与LARM状态的语言嵌入相关联,从而实现结构化奖励、泛化和技能复用。
语言对齐奖励机 (LARM)
创新点
本文的核心创新在于提出了LARM。它在标准RM的基础上,为每个RM状态 $u$ 增加了对应的自然语言描述 $l_u$ 和其嵌入向量 $z_u$。这一设计至关重要,因为它构建了一个语义技能空间:策略可以根据这些嵌入向量进行条件化,从而自然地在相关子任务之间共享知识,实现跨任务的迁移、组合和零样本泛化。
LARM的自动构建
本文提出了一套流程,通过迭代式地提示(prompting)一个FM,从语言和图像共同构成的任务描述中自动构建LARM。
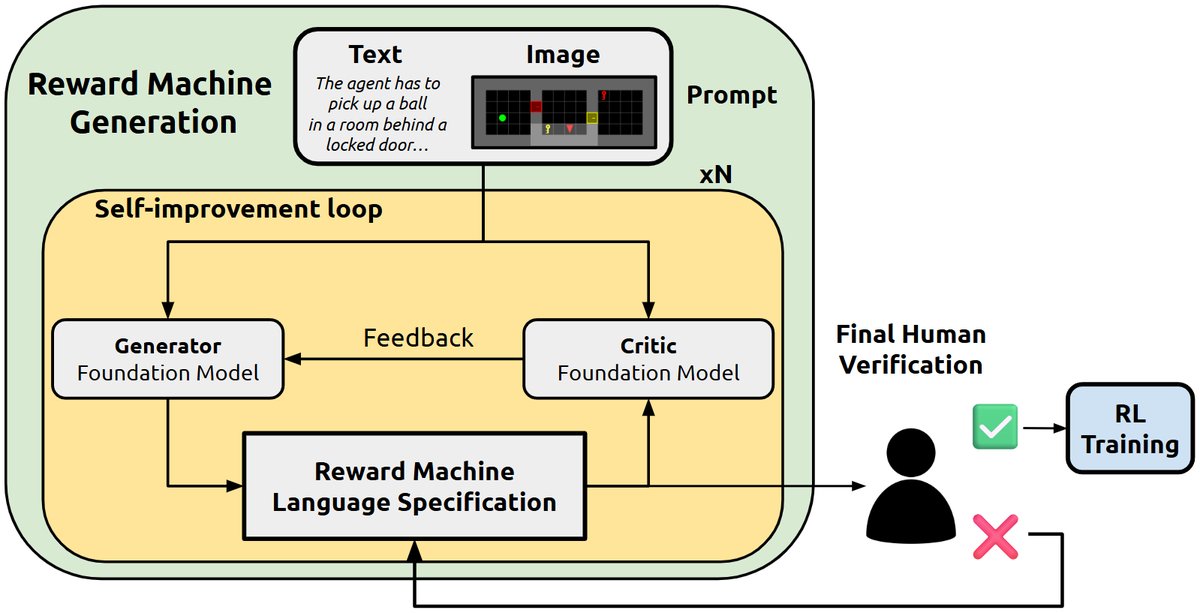
具体来说,该流程采用多轮自我改进(self-improvement)机制,利用成对的FMs来逐步精化RM的规范。最终,FM会生成完整的LARM,包括:
- 自动机结构:RM的状态和转移关系。
- 可执行的标签函数($\mathcal{L}$):通常以Python代码形式生成,用于检测环境中的关键事件。
- **各状态的自然语言指令($l_u$)和嵌入($z_u$) **。
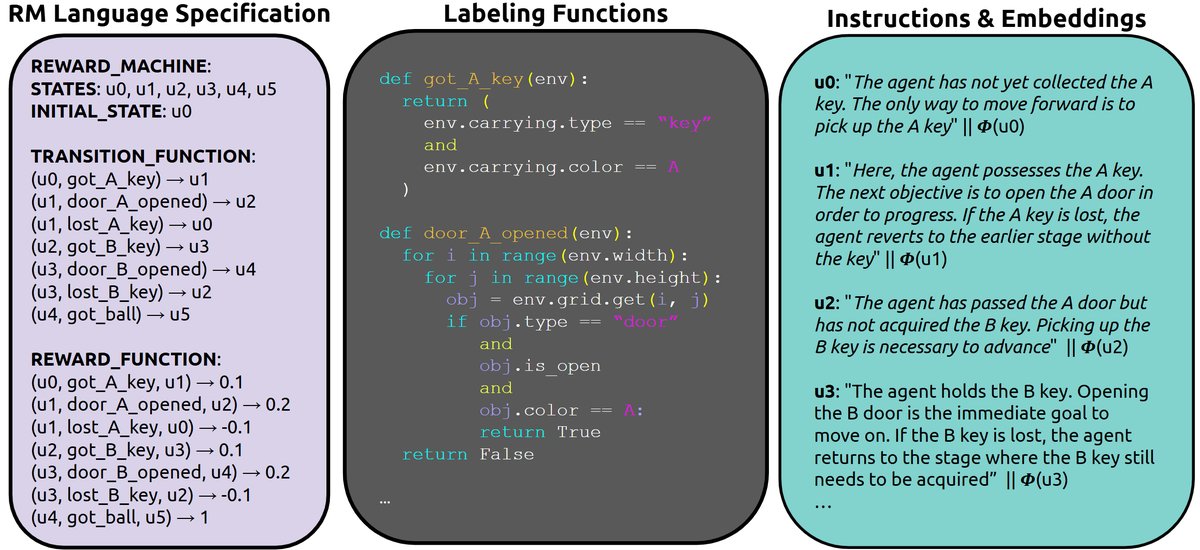
实践证明,FM生成的LARM不仅可解释性强,而且由于遵循自然语言规范,也易于人类修改和验证。
结合LARM的强化学习
引入LARM后,智能体的训练过程在一个增强的状态空间 $\mathcal{S} \times \mathcal{U}$(即环境状态与RM状态的笛卡尔积)上进行。
优点
该方法的核心优点在于其策略 $\pi(s_t, z_{u_t})$ 同时以环境状态 $s_t$ 和当前LARM状态的语言嵌入 $z_{u_t}$ 为条件。这种基于语言的策略条件化是实现泛化的中心机制,它创建了一个语义接地的技能空间,使得“拿起蓝钥匙”和“拿起红钥匙”这类指令在嵌入空间中自然邻近,为广泛的经验重用和高效的策略迁移开辟了道路。
在训练过程中,智能体的学习循环如下:
- 在$t$时刻,智能体根据当前环境状态$s_t$和LARM状态嵌入$z_{u_t}$,选择一个动作$a_t \sim \pi(s_t, z_{u_t})$。
- 环境转移到新状态$s_{t+1}$,并返回基础奖励$R_t$。
- 标签函数$\mathcal{L}(s_{t+1}, a_t)$判断是否发生了某个符号事件。
- 如果事件发生,LARM会根据转移函数$\delta$更新状态至$u_{t+1}$,并提供一个额外的RM奖励$R^{\text{RM}}_t$。
- 用于策略更新的总奖励为$R^{\text{total}}_t = R_t + R^{\text{RM}}_t$。
这个过程将稀疏的最终任务奖励分解为一系列密集的、结构化的子任务奖励,极大地简化了学习过程。
实验结论
本文在一系列具有挑战性的环境中对ARM-FM进行了评估,覆盖了离散和连续控制领域。
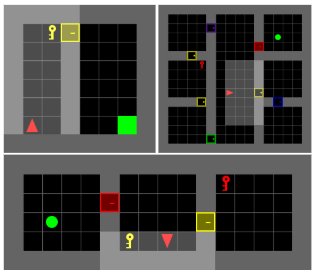
稀疏奖励任务
在MiniGrid环境套件中,这些任务因奖励稀疏而极具挑战性。
- 结果:在DoorKey任务中,无论地图是固定的还是程序化生成的,ARM-FM(DQN+RM)都稳定地超越了所有基线方法(DQN, DQN+ICM, LLM-as-agent)。在更难的KeyCorridor等长时程任务中,ARM-FM是唯一能够解决所有任务并获得近乎完美奖励的方法,而其他基线则完全无法取得进展。


复杂3D环境扩展
在基于Minecraft的程序化3D环境Craftium中,任务是采集一系列资源来最终挖到钻石。
- 结果:与LARM结合的PPO智能体能够稳定地完成整个长序列任务,而基线PPO智能体几乎无法取得进展。
- 意义:这个结果尤为重要,因为它证明了ARM-FM能够成功地将一个完全由FM自动生成的RM应用到具有高维视觉和动作空间的复杂环境中,有效分解了高级目标。
机器人操控
在Meta-World连续控制基准测试中,为机器人手臂设计奖励通常需要大量手动工程。
- 结果:ARM-FM无需手动设计低级奖励信号,通过生成的RM提供了比稀疏奖励更丰富的学习信号,使得SAC智能体取得了更高的成功率。
- 意义:这证明了ARM-FM框架同样适用于连续控制领域。

通过语言嵌入实现泛化
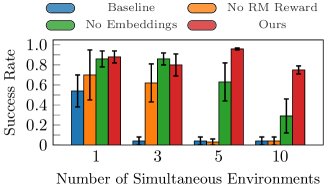
-
多任务学习:一项消融研究表明,在同时训练多个任务时,完整的ARM-FM方法(同时使用LARM的结构化奖励和状态嵌入)表现最为稳健。只使用奖励或只使用嵌入都会导致性能下降,证明了两者对于鲁棒的多任务学习都是不可或缺的。
-
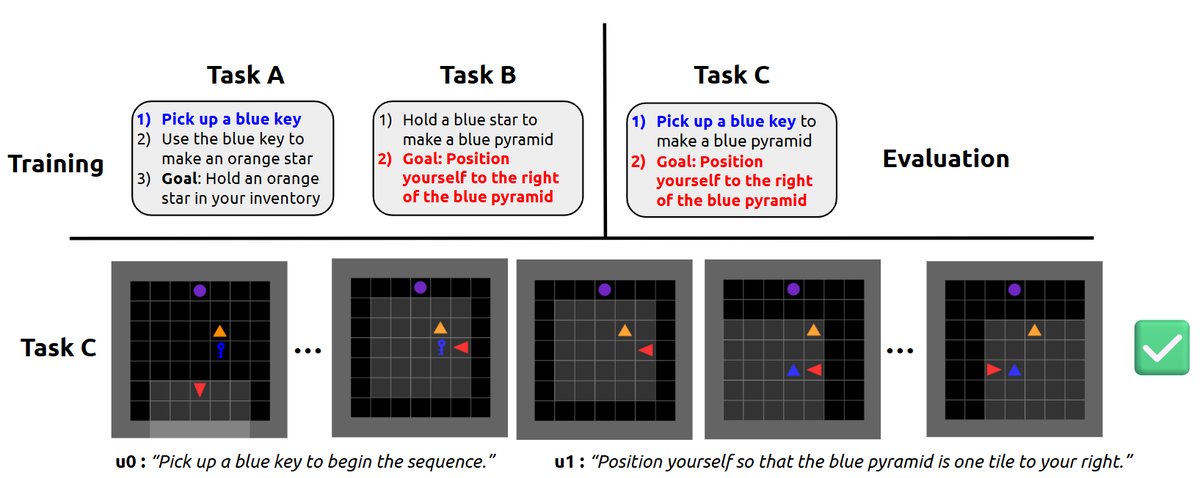
零样本泛化:
- 实验设计:在一个新任务上测试一个已在其他任务上训练好的策略,这个新任务的LARM由之前见过的子任务组合而成。
- 结果:智能体成功地零样本解决了这个全新的组合任务,无需任何额外训练。
- 原因:当新任务的LARM转移到一个新子任务时,其状态嵌入$z_{u’}$与训练中见过的相似子任务的嵌入在语义空间中非常接近。因此,策略能够复用已学到的相关技能来完成新任务。
深入分析
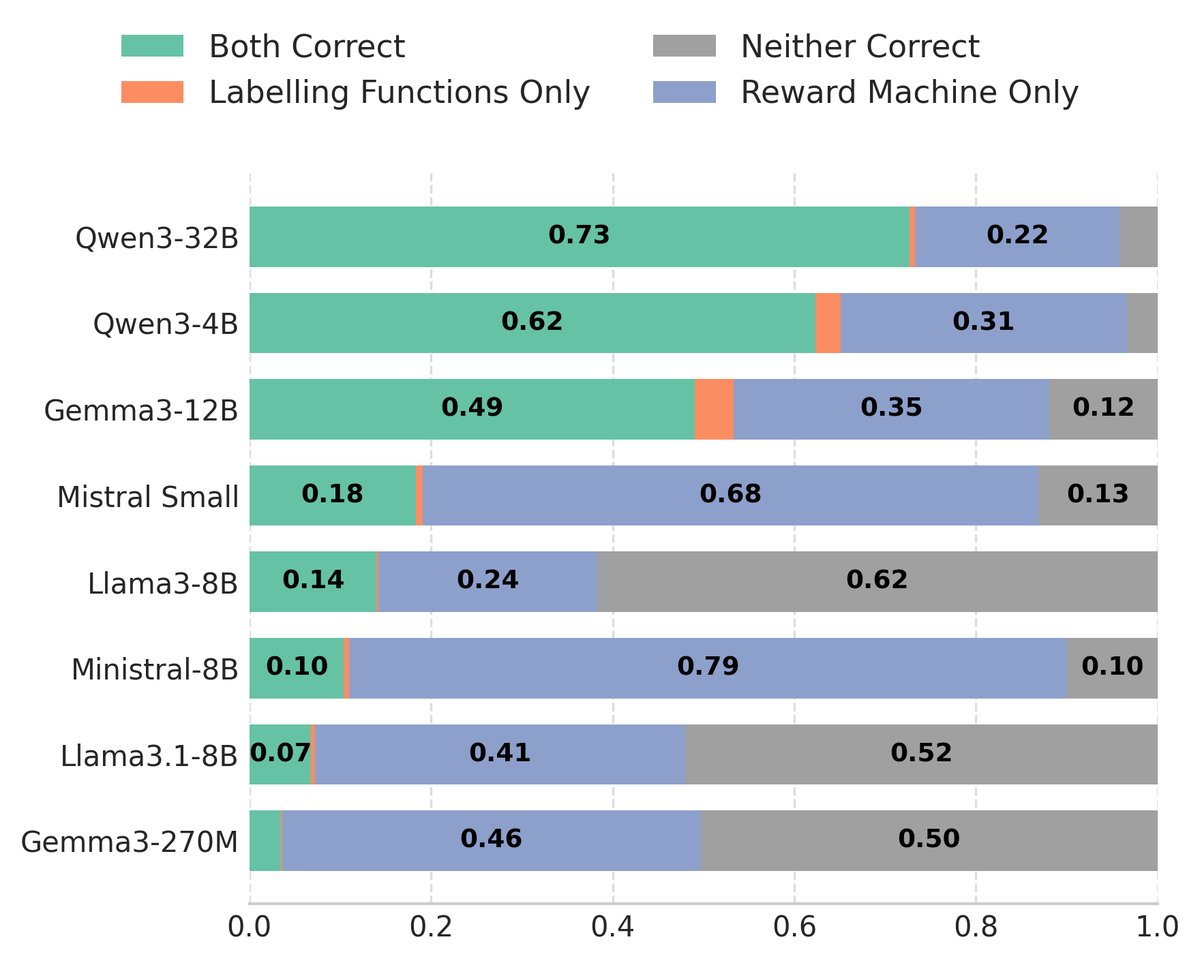
- FM生成质量:实验比较了不同规模的开源FM生成LARM的能力。结果显示出明显的规模效应:更大的模型(如Claude 3 Opus)在生成完全正确的RM结构和标签函数方面表现得更好。
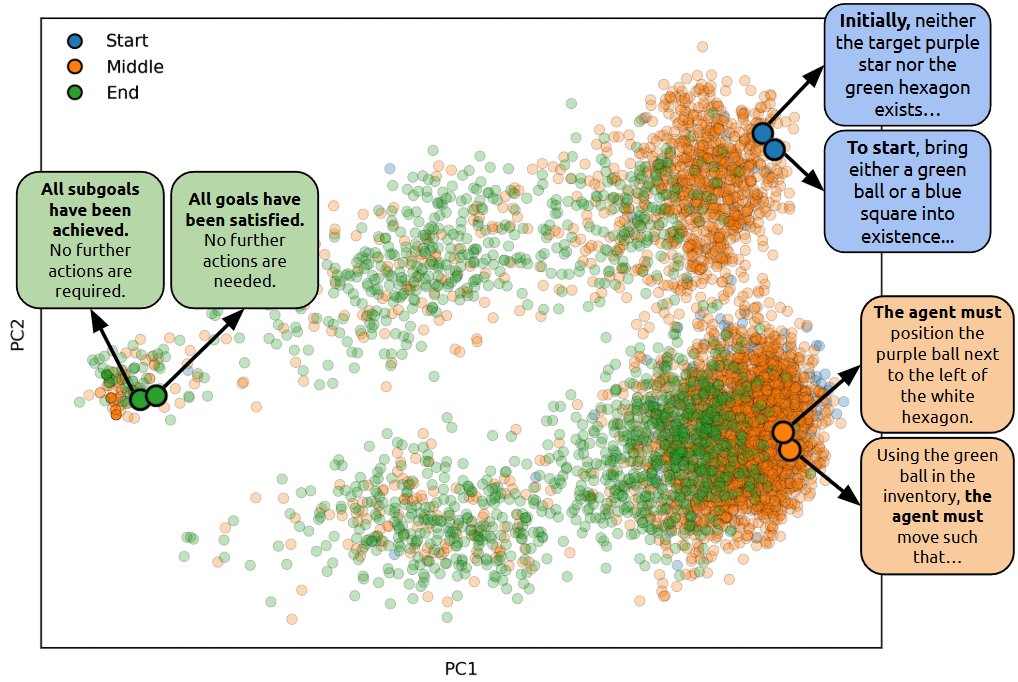
- 嵌入的语义结构:通过PCA对1000个任务的LARM状态指令嵌入进行可视化,结果显示嵌入空间形成了清晰的、有意义的簇。来自不同任务但语义相似的指令(如“前往目标”、“拿起物品”)聚集在一起,证实了FM能够产生一个连贯的表示空间,这是技能迁移的基础。
总结
本文的实验有力地证明了ARM-FM框架的有效性。它不仅能将稀疏奖励任务转化为易于学习的密集奖励任务,显著提升了样本效率,而且能够扩展到复杂的3D和连续控制领域。最重要的是,通过语言对齐的奖励机,该框架实现了鲁棒的多任务学习和零样本泛化能力,为构建更通用、更具可解释性的强化学习智能体开辟了新的道路。