Artificial Hippocampus Networks for Efficient Long-Context Modeling
-
ArXiv URL: http://arxiv.org/abs/2510.07318v1
-
作者: Weihao Yu; Xuehan Xiong; Yunhao Fang; Shu Zhong; Lai Wei; Qinghao Ye
-
发布机构: ByteDance
TL;DR
本文提出了一种名为人工海马网络(Artificial Hippocampus Networks, AHN)的框架,通过一个可学习的循环模块将滑窗外的Key-Value缓存压缩为固定大小的长期记忆,从而在显著降低计算和内存成本的同时,高效地处理长序列上下文。
关键定义
- 人工海马网络 (Artificial Hippocampus Network, AHN):一个受认知科学中多重存储记忆模型(Multi-Store Model of memory)启发的、可学习的神经网络模块。它的核心功能是循环地将超出注意力滑窗范围的历史信息(即Key-Value对)压缩成一个固定大小的紧凑表示,作为模型的长期记忆。
- 双重记忆框架 (Dual-Memory Framework):本文提出的结合了两种记忆类型的框架。
- 无损短期记忆 (Lossless Short-Term Memory):由Transformer的滑动窗口Key-Value缓存构成,保留了近期上下文的全部信息,但容量有限。
- 压缩长期记忆 (Compressed Long-Term Memory):由AHN生成并维护的固定大小的循环状态(hidden state),它概括了所有滑窗之外的远期上下文信息。
相关工作
当前的长序列建模领域存在一个根本性的权衡:
- RNN类模型:使用固定大小的隐藏状态作为压缩式记忆。这种方法在处理每一步时具有恒定的计算和内存成本,因此非常高效。然而,将所有历史信息压缩到固定大小的向量中不可避免地会导致信息丢失,特别是在需要精确回忆远距离信息的任务上表现不佳。
- Transformer类模型:使用Key-Value (KV)缓存作为无损记忆,能够保留所有历史token的完整信息,保真度高。但其代价是,KV缓存大小随序列长度线性增长,注意力计算成本随序列长度二次方增长,这在处理极长序列时带来了巨大的计算和内存瓶颈。
本文旨在解决上述效率与保真度之间的权衡问题。具体而言,本文的目标是设计一种新的机制,既能像RNN一样高效,又能像Transformer一样更好地保留长距离依赖信息,从而有效处理超长上下文。
本文方法
本文提出的方法核心是人工海马网络(AHN),它模仿了生物大脑海马体将短期记忆整合为长期记忆的功能,构建了一个高效的双重记忆系统。
创新点
该方法的核心创新在于引入了一个独立的、可学习的压缩模块(AHN),将Transformer的滑动窗口注意力机制与RNN类模型的循环压缩能力有机结合,而不是简单地丢弃窗口外的信息。
- 双重记忆协同工作: 模型同时维护两种记忆:
- 近期上下文 (无损): 一个大小为 \(W\) 的滑动窗口内的KV缓存,通过标准的因果自注意力机制处理,保证了对近期信息的高保真度捕捉。
- 远期上下文 (压缩): 当一个token的位置 \(t-W\) 移出滑动窗口时,其对应的KV对 \((k_{t-W}, v_{t-W})\) 不会被丢弃,而是被送入AHN。
-
循环压缩机制: AHN作为一个RNN类的模块,接收移出窗口的KV对,并更新其内部的隐藏状态 \(h\)。这个更新过程是循环的:
\[h_{t-W}=\text{AHN}((k_{t-W},v_{t-W}),h_{t-W-1})\]其中 \(h_{t-W}\) 是包含了直到位置 \(t-W\) 的所有历史信息的压缩记忆。这个固定大小的隐藏状态 \(h\) 扮演了长期记忆的角色。
- 信息融合与输出: 在生成当前位置 \(t\) 的输出时,查询向量 \(q_t\) 会同时从两种记忆中提取信息:
- 与滑动窗口内的KV对 \(\{(k_{i},v_{i})\}_{i=t-W+1}^{t}\) 进行注意力计算。
- 与AHN维护的压缩记忆 \(h_{t-W}\) 进行交互。 最终的输出 \(y_t\) 是这两部分信息的融合:
方法实例化:AHN-GDN
AHN是一个通用概念,可以用多种RNN类架构实现。本文以GatedDeltaNet (GDN) 为例,实例化了AHN-GDN。其记忆更新规则为:
\[h_{t-W} = \alpha(x_{t-W})(\mathbf{I}-\beta(x_{t-W})k_{t-W}^{T}k_{t-W})h_{t-W-1}+\beta(x_{t-W})k_{t-W}^{T}v_{t-W}\]其中,\(\alpha\) 和 \(\beta\) 是由输入 \(x_{t-W}\) 决定的门控函数。
优点
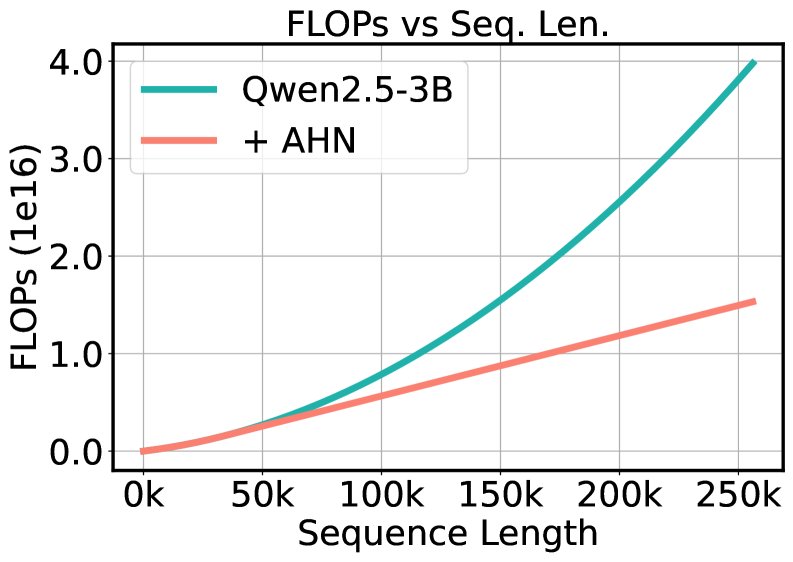
- 高效性:通过将窗口外历史压缩到固定大小的隐藏状态,AHN将注意力的计算复杂度从 \(O(L^2)\) 降低到 \(O(WL)\),并将KV缓存的内存需求从 \(O(L)\) 降低到 \(O(W)\),其中 \(L\) 是序列总长,\(W\) 是窗口大小。这使得模型能以几乎恒定的内存开销处理任意长度的序列。
- 信息保持:与简单地丢弃窗口外信息的滑动窗口注意力(SWA)不同,AHN通过循环压缩保留了长程上下文的概要信息,避免了灾难性遗忘。
- 灵活性与兼容性:AHN可以作为即插即用的模块,与现有的预训练Transformer模型(如Qwen)结合,只需训练少量新增参数即可。
| 复杂度对比 | 全注意力 (Full Attention) | AHN-GDN 增强模型 |
|---|---|---|
| 可训练参数 | $2DH(N_q+N_{kv})$ | $2DH(N_q+N_{kv})+3DN_q+H^2N_q$ |
| KV缓存大小 | $2LHN_{kv} \sim O(L)$ | $2WHN_{kv}+H^2N_q \sim O(W)$ |
| 推理FLOPs | $4LDH(N_q+N_{kv})+2HN_qL^2 \sim O(L^2)$ | $4LDH(N_q+N_{kv})+… \sim O(WL)$ |
L: 序列长度, W: 窗口大小, H: 注意力头数, D: 头维度, N_q/N_kv: 查询/键值头数
训练框架
为了高效地训练AHN模块,本文采用了一种自蒸馏(self-distillation)方案。
- 教师模型: 使用原始的、带有全注意力机制的预训练大语言模型。
- 学生模型: 将同一模型的注意力层替换为滑动窗口注意力和AHN模块。
-
训练目标: 冻结预训练模型的主体参数,仅训练新增的AHN模块参数。优化目标是最小化学生模型与教师模型输出概率分布之间的KL散度 $$\text{KL}(p’ p)$$。
这种方法利用了教师模型的强大能力来指导AHN学习如何有效地压缩上下文信息,比从零开始使用标准的下一词预测(Cross-Entropy loss)更加高效和稳定。
实验结论
实验基于Qwen2.5系列模型(3B, 7B, 14B),并在LV-Eval, InfiniteBench, LongBench等长上下文基准上进行了评估。
- 性能超越基线: 在LV-Eval (128k序列长度) 和InfiniteBench等超长上下文基准上,AHN增强后的模型性能显著优于标准的滑动窗口注意力(SWA)基线和压缩Transformer(CT)基线。
| 模型 (Qwen2.5-3B) | LV-Eval Avg. | InfiniteBench Avg. | FLOPs (128k) | 缓存 (128k) |
|---|---|---|---|---|
| 全注意力 | 4.41 | 68.3 | 1.00x | 1.00x |
| SWA + Sinks | 2.50 | 58.7 | 0.59x | 0.26x |
| AHN-GDN (本文) | 5.88 | 72.1 | 0.59x | 0.26x |
- 媲美甚至超越全注意力: 惊人的是,尽管AHN模型使用了压缩记忆,其在多个任务上的平均得分甚至超过了计算成本高昂的全注意力模型。例如,在LV-Eval上,AHN-GDN将Qwen2.5-3B的分数从4.41提升到5.88,同时FLOPs减少40.5%,KV缓存减少74.0%。
-
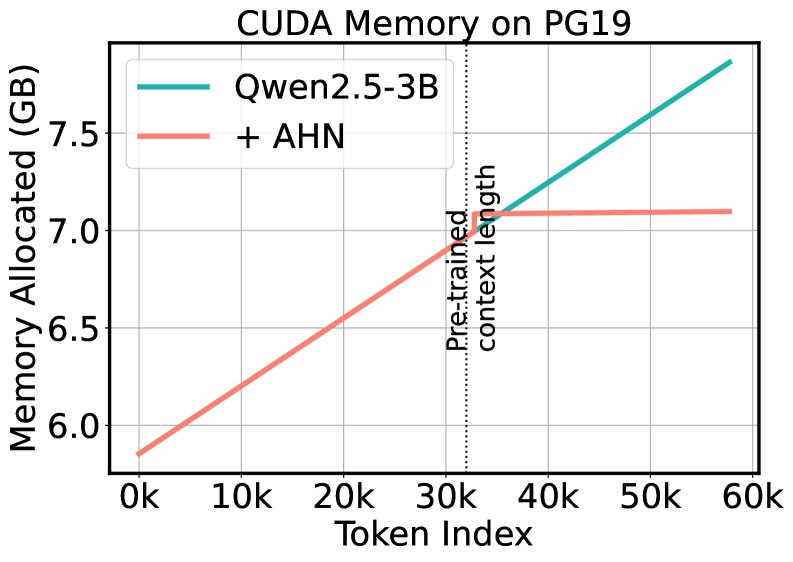
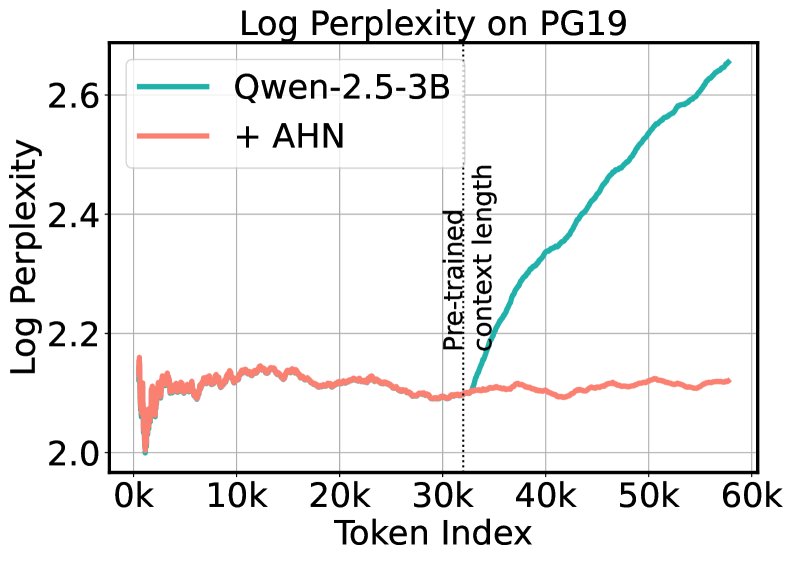
效率优势显著: 在处理长达57k token的PG19书籍文本时,标准模型在上下文窗口(32k)耗尽后困惑度急剧上升,而AHN模型则能保持稳定的低困惑度。同时,AHN模型的内存占用几乎保持恒定,而标准模型则线性增长,充分验证了其在长序列处理上的效率优势。
- 消融研究:
- 训练目标: 实验证明,使用自蒸馏(KL散度)进行训练的效果远优于使用传统交叉熵损失(CE),后者导致性能大幅下降。这表明教师模型的密集信号对于指导AHN学习通用压缩策略至关重要。
- 训练策略: 在训练时使用随机化的滑动窗口大小,能让模型更好地泛化到不同的上下文长度,避免对特定窗口大小过拟合。
- 机制探索: 通过梯度可视化发现,AHN在压缩时会有选择性地保留关键信息(如数学符号和数字),而忽略不那么重要的信息(如代词和特殊token),证明了其作为一种有效的、有针对性的压缩模块。

最终结论: 人工海马网络(AHN)作为一个轻量级架构组件,成功地弥合了RNN类模型的效率与Transformer模型的保真度之间的差距。它通过将窗口外信息压缩为固定大小的记忆,使得模型能够在显著降低内存和计算成本的同时,在长上下文任务上取得极具竞争力的性能。