Asymmetric Proximal Policy Optimization: mini-critics boost LLM reasoning
-
ArXiv URL: http://arxiv.org/abs/2510.01656v1
-
作者: Yancheng He; Pablo Samuel Castro; Ling Pan; Wenbo Su; Jiashun Liu; Weixun Wang; Han Lu; Aaron Courville; Bo Zheng; Johan Obando-Ceron
-
发布机构: Alibaba Group; Hong Kong University of Science and Technology; Mila; Université de Montréal
TL;DR
本文提出了一种非对称近端策略优化(Asymmetric Proximal Policy Optimization, AsyPPO),该框架通过使用一组在非重叠数据上训练的轻量级“迷你评论家”(mini-critics),在保持计算高效的同时恢复了评论家(critic)在大型语言模型(LLM)推理任务中的关键作用,从而显著提升了学习的稳定性和最终性能。
关键定义
-
非对称近端策略优化 (Asymmetric Proximal Policy Optimization, AsyPPO):本文提出的核心框架。它采用与大型智能体(actor)模型规模不匹配的、更小、更轻量级的评论家模型(即“非对称”架构),以解决在LLM场景下训练全尺寸评论家带来的巨大计算开销和价值估计不准的问题。
-
迷你评论家 (Mini-critics):指在AsyPPO框架中使用的轻量级评论家模型。它们的参数量远小于智能体模型,通过集成(ensemble)的方式共同为大型智能体提供价值估计。
-
组级非重叠数据划分 (Group level non-overlap data division):一种为迷你评论家集成设计的特定数据划分策略。它将每个提示(prompt)生成的多条响应(response)均匀地、无重叠地分配给不同的评论家进行训练。此举旨在鼓励评论家之间的功能多样性,同时避免因数据不一致导致的感知不同步问题。
-
基于价值一致性的优势掩码 (Advantage masking based on value agreement):一种策略优化技巧。当多个迷你评论家对某个状态的价值估计趋于一致(即标准差很低)时,认为该状态提供的新信息有限。因此,在计算策略梯度时,会掩盖(mask)这些状态的优势值(advantage),从而使模型专注于从信息量更丰富的转换中学习。
-
基于价值分歧的熵过滤 (Entropy filtering based on value divergence):另一种策略优化技巧。当迷你评论家对某个状态的价值估计出现较大分歧(即标准差很高)时,认为该状态可能包含噪声或与推理任务无关的模式。因此,在计算熵正则化项时,会过滤掉这些高分歧状态,以抑制无效探索,促进更安全的策略学习。
相关工作
当前,近端策略优化(Proximal Policy Optimization, PPO)已成为提升LLM推理能力的主流强化学习(RL)方法。然而,将传统RL中的对称演员-评论家(actor-critic)架构直接应用于LLM时,面临着严峻的挑战。由于LLM的规模巨大,训练一个与智能体同样大小的评论家模型不仅计算成本高昂,而且在长序列、稀疏奖励的推理任务中,其价值估计往往不准确且难以收敛。
为了应对这些挑战,当前最先进的(SOTA)方法,如GRPO及其变体,大多选择放弃显式的评论家,转而使用平均优势基线(average advantage baselines)等粗粒度方法来估计优势。虽然这种范式转变在实践中取得了成功,但它也舍弃了RL的一个核心优势:通过鲁棒的状态价值估计来稳定训练过程,防止因优势估计偏差导致的策略崩溃。
本文旨在解决上述“评论家瓶颈”问题,即如何设计一种既能提供准确价值估计、又能在LLM尺度上保持计算效率和可扩展性的评论家架构。
本文方法
本文的核心思想是:利用预训练模型赋予LLM的强大初始表征能力,构建一个非对称的演员-评论家系统,通过一组轻量级的“迷你评论家”来有效指导一个大规模的智能体。该方法主要包含两个层面的创新。
轻量级价值估计
本文首先验证了一个关键假设:在RL4LLM领域,由于模型已经过预训练,使用一个小型评论家指导一个大型智能体是可行的。实验表明,即便是一个规模较小的评论家(如Qwen2-1.7B)也能为大型智能体(如Qwen2-8B)提供有效的学习信号。
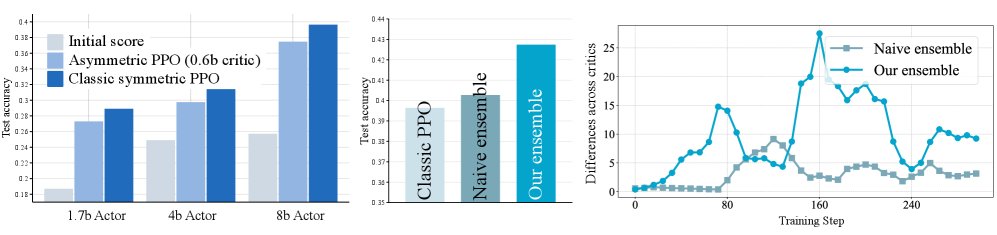
然而,单个小型评论家受限于其表达能力,在面对稀疏奖励和长尾推理路径时,其价值估计的准确性依然不如对称的PPO。为了解决此问题,本文没有采用简单的集成(ensemble)方法——因为从同一预训练模型初始化的评论家行为高度一致,无法提供多样性。
创新点:组级非重叠数据划分
本文提出了一种新颖的数据划分策略以促进评论家之间的差异化。具体做法是:对于每个prompt产生的一组响应,将它们均匀地划分为M个互不相交的子集 \($\mathcal{D}\_m\)$,每个子集分配给一个迷你评论家 \(V_m\) 进行训练。
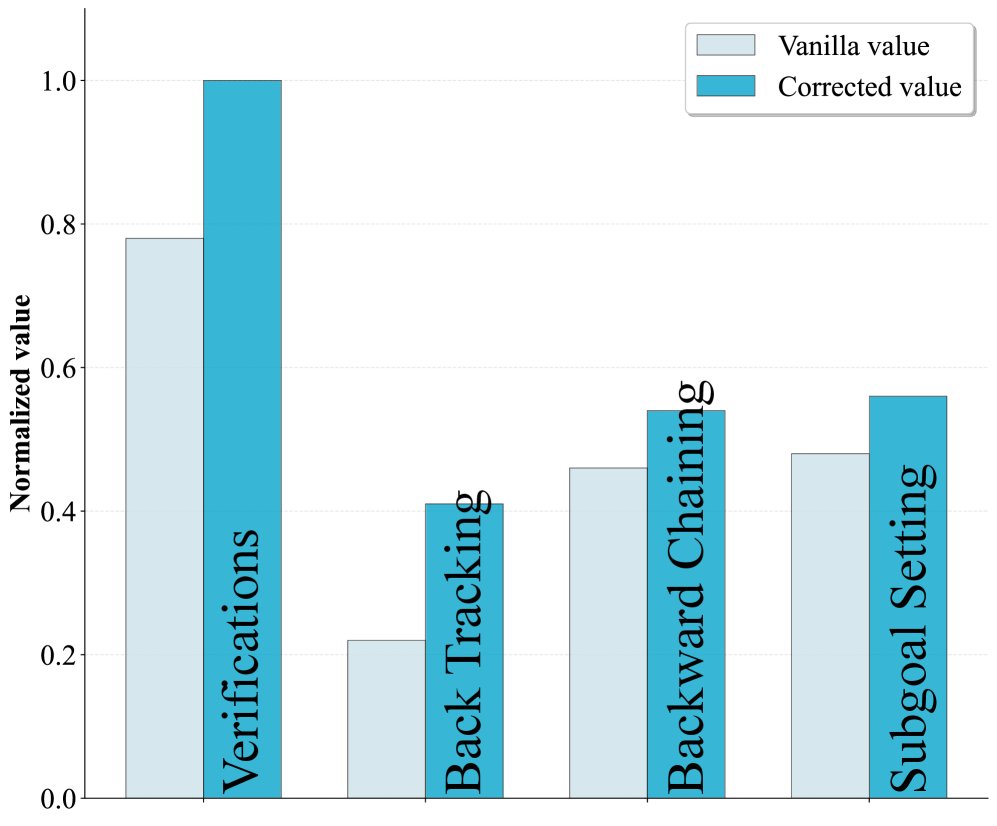
这种设计确保了在同一个prompt下,所有评论家都能观察到相似的推理模式(维持感知同步),但由于各自训练的响应和奖励不同,它们会学习到功能上互补的价值函数。训练评论家的损失函数如下:
\[\mathcal{L}_{\text{critic}}(\mathbf{\phi})=\sum_{m=1}^{M}\mathcal{L}_{\text{critic}}^{(m)}(\phi_{m})=\sum_{m=1}^{M}\mathbb{E}_{(s_{t},R_{t})\sim\mathcal{D}_{m}}\left[\left(V(s_{t};\phi_{m})-R_{t}\right)^{2}\right]\]其中 \($M\)$ 是迷你评论家的数量。最终的价值估计 \($\bar{V}\)$ 是所有迷你评论家价值的平均值,并用此计算优势 \($\bar{A}\_t\)$:
\[{\bar{A}_{t}}(\gamma,\lambda) = \sum_{l=0}^{T-t-1}(\gamma\lambda)^{l}\delta_{t+l}, \quad \delta_{t}=r_{t}+\gamma\bar{V}(s_{t+1})-\bar{V}(s_{t}); \quad \bar{V}(s_{t})=\frac{1}{M}\sum_{m=1}^{M}V_{m}(s_{t};\phi_{m})\]实验表明,仅使用两个迷你评论家就能带来质的飞跃,在效率和性能之间达到了最佳平衡。
策略损失重构
本文进一步利用迷你评论家集成带来的额外信息——价值估计的(不)一致性——来优化策略学习过程。评论家之间对同一状态价值估计的标准差 \($\sigma\_t\)$,被用作衡量该状态不确定性和信息量的信号。
创新点1:基于价值一致性的优势掩码
当评论家们对某个状态的价值估计高度一致(\($\sigma\_t\)$ 很低)时,表明该状态的后续动态很可能已被策略充分学习,继续优化该状态的收益不大。为避免过拟合并提高样本效率,本文提出对这类“低信息量”状态进行优势掩码,即在策略损失中将其优势值置零。
\[\mathcal{J}_{\mathrm{PPO}}(\theta)= \mathbb{E}\frac{1}{ \mid o \mid }\sum_{t=1}^{ \mid o \mid }{\mathbb{I}^{A}}\cdot\min\Bigg(\mathcal{IS}_{t}\cdot{\bar{A}_{t}},\,\mathrm{clip}\left(\mathcal{IS}_{t},\,1{-}\epsilon,\,1{+}\epsilon\right){\bar{A}_{t}}\Bigg);\;{\mathbb{I}^{\text{A}}_{t}=\begin{cases}0,&\text{if }\sigma_{t}\in Low_{k}(\sigma)\\ 1,&\text{otherwise}\end{cases}}\]其中 \($\mathbb{I}^{\text{A}}\_{t}\)$ 是一个指示函数,当 \($\sigma\_t\)$ 属于最低的 \(k%\) 时取值为0。实验证明,这种方法在高数据复用率下能显著提升学习效率。
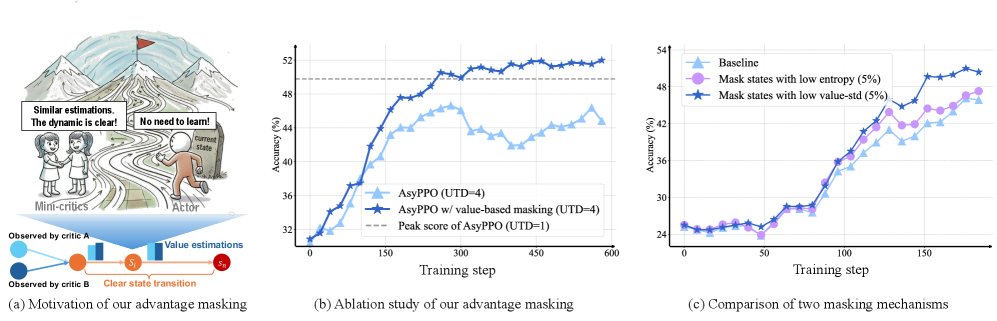
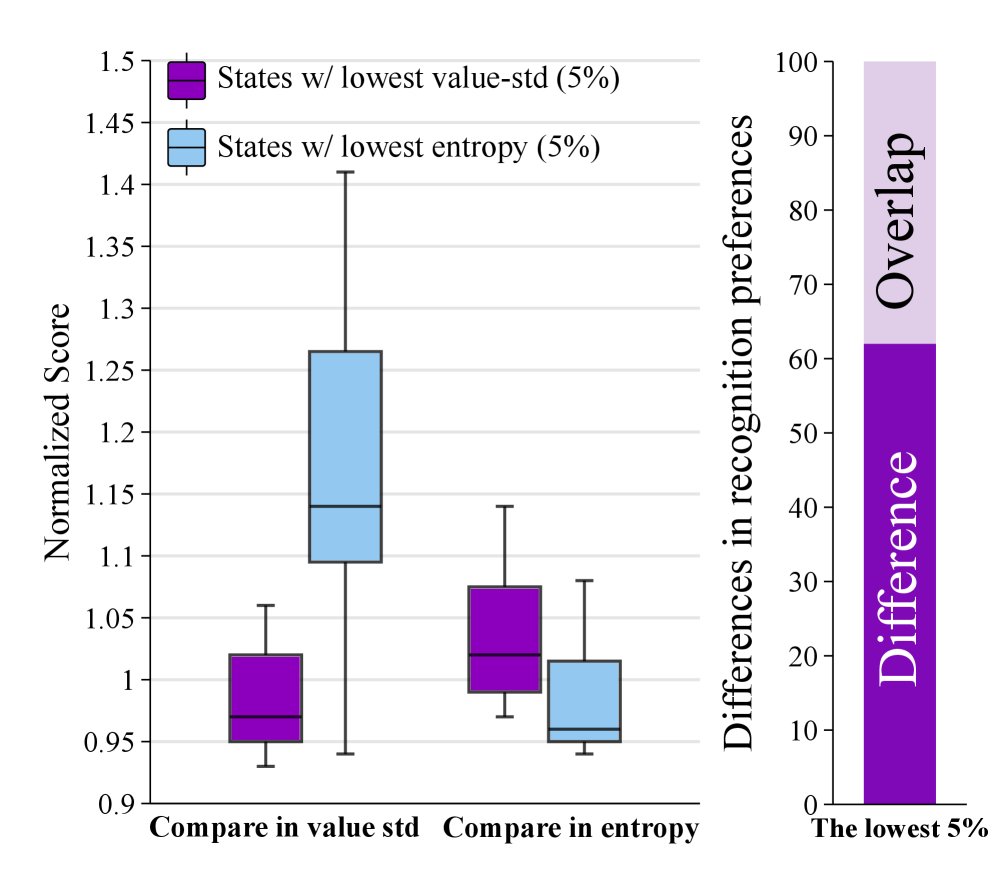
创新点2:基于价值分歧的熵过滤
当评论家们对某个状态的价值估计存在巨大分歧(\($\sigma\_t\)$ 很高)时,表明该状态可能与最终结果的关联度低,或者包含许多与推理无关的噪声(如无关紧要的副词、感叹词等)。在这些状态上进行探索是低效的。因此,本文提出在计算熵正则化项时,过滤掉这些高分歧状态,以引导模型进行更“安全”和有意义的探索。
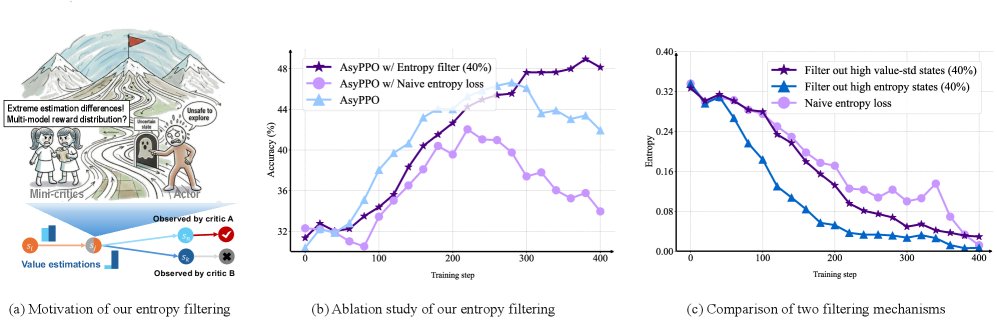
修改后的完整PPO目标函数如下:
\[\mathcal{J}_{\mathrm{PPO}}(\theta)= \mathbb{E}_{\left[q\sim P(Q),\ o\sim\pi_{\theta_{\mathrm{old}}}(O \mid q)\right]}\frac{1}{ \mid o \mid }\sum_{t=1}^{ \mid o \mid }\Bigg[{\mathbb{I}^{\text{A}}_{t}}\cdot\min\Bigg(\mathcal{IS}_{t}\cdot{\bar{A}_{t}},\,\mathrm{clip}\left(\mathcal{IS}_{t},\,1{-}\epsilon,\,1{+}\epsilon\right){\bar{A}_{t}}\Bigg) +{\beta\cdot\mathbb{I}^{\mathcal{H}}_{t}\cdot\mathcal{H}\left[\pi_{\theta}(\cdot \mid s_{t})\right]}\Bigg]\]其中 \($\mathbb{I}^{\mathcal{H}}\_{t}\)$ 是熵过滤的指示函数,当 \($\sigma\_t\)$ 属于最高的 \(h%\) 时取值为0。这种方法有效避免了朴素熵正则化可能导致的策略崩溃。
完整的AsyPPO算法流程总结如下:
| Asymmetric PPO 算法 (使用两个迷你评论家) |
|---|
| 输入: 智能体 \($\pi\_{\theta}\)$,迷你评论家 \(V_{\phi_{\{1,2\}}}\) |
| 循环 直到达到最大训练步数: |
| 1. 使用当前策略 \($\pi\_{\theta}\)$ 生成一批响应 \(O\)。 |
| 2. 为每个评论家构建训练子集,并根据公式更新 \(V_{\phi_{\{1,2\}}}\)。 |
| 3. 计算评论家的平均价值 \($\bar{V}\)$,并通过GAE计算修正后的优势 \($\bar{A}\)$。 |
| 4. 计算所有状态的价值标准差 \($\sigma(O)\)$$。 |
| 5. 生成优势掩码向量 \($\mathbb{I}^{A} \leftarrow Low\_{k}(\sigma(O))\)$ 和熵过滤向量 \($\mathbb{I}^{\mathcal{H}} \leftarrow Top\_{h}(\sigma(O))\)$。 |
| 6. 使用重构后的PPO损失函数(包含掩码和过滤)更新智能体 $$$\pi_{\theta}`。 |
实验结论
本文通过一系列实验,验证了AsyPPO方法的有效性和泛化能力。
主要发现
- 性能提升:在仅使用5000个样本进行训练后,AsyPPO在多个数学推理基准测试(如AIME、MATH-500等)上,性能稳定超过了GRPO和经典PPO等强基线。例如,在AIME上性能提升超过6%,在MATH上超过3%。
- 计算效率:AsyPPO的非对称架构显著降低了计算开销。相比于对称PPO,其训练步骤的平均耗时和峰值GPU内存使用都大幅降低,效率与放弃评论家的GRPO相当。
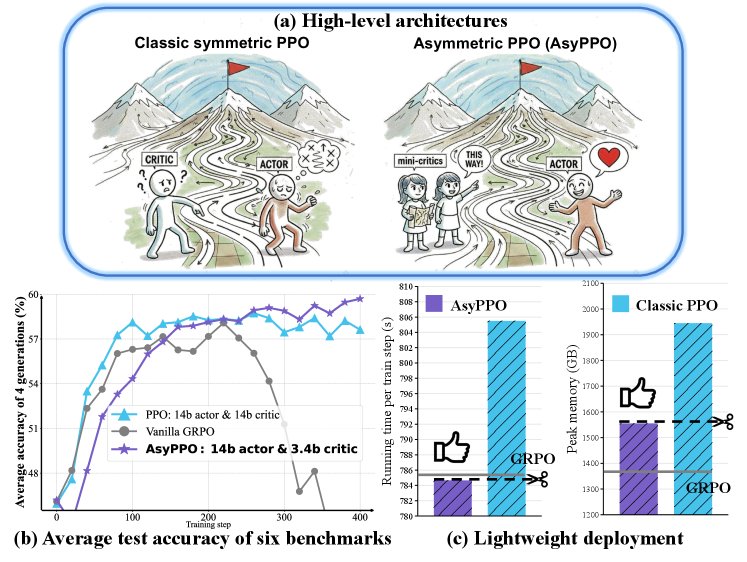
- 对大型模型的泛化能力:AsyPPO成功地将能力泛化到了更大的模型上。实验中,由两个Qwen2-4B迷你评论家指导的Qwen2-14B智能体取得了最佳性能。更重要的是,AsyPPO使得更小的评论家(如Qwen2-1.7B)也能有效指导14B的大模型,而朴素的单评论家非对称PPO在这种设置下会失败。

消融研究
一系列消融实验揭示了AsyPPO各组件的最佳配置:
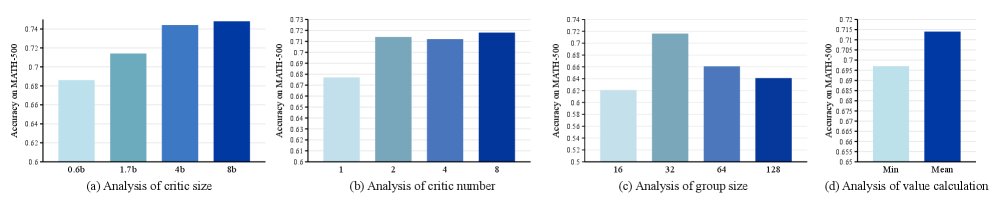
- 评论家系统:增加评论家模型的尺寸可以持续提升策略性能。而评论家的数量则存在一个“甜点”,两个迷你评论家足以实现性能的质变,更多评论家带来的收益不成比例。
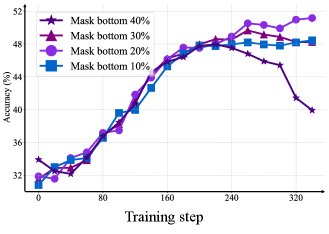
- 优势掩码:掩盖价值标准差最低的20%的状态时,模型学习效率最高。
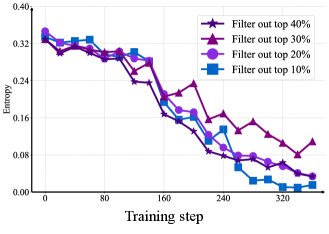
- 熵过滤:从熵正则化中过滤掉价值标准差最高的20%的状态,能在探索与利用之间取得最佳平衡,更大的过滤比例会导致熵崩溃。
- 价值聚合:使用多个评论家价值估计的均值(mean)比使用最小值(min)效果更好,这表明在LLM推理任务中,价值过高估计(overestimation)可能不是主要问题。

最终结论
本文成功地将RL4LLM中的评论家瓶颈问题重新定义为一个架构设计问题。提出的AsyPPO框架通过双轻量级迷你评论家和非重叠数据训练策略,不仅恢复了评论家在策略优化中的关键作用,还利用评论家之间的一致性/分歧信号来精细化策略更新,最终在提升LLM推理能力的同时,兼顾了计算效率和可扩展性,为设计可扩展、高效的RL4LLM算法指明了新的方向。