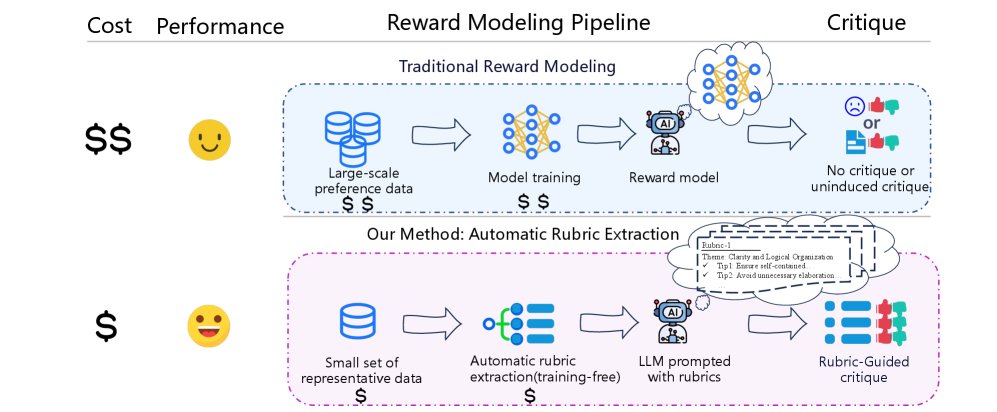
Auto-Rubric: Learning to Extract Generalizable Criteria for Reward Modeling
-
ArXiv URL: http://arxiv.org/abs/2510.17314v1
-
作者: Yunpeng Zhai; Zhaoyang Liu; Haoran Chen; Anni Zou; Haoyuan Hu; Sen Huang; Bolin Ding; Boyin Liu; Zhuo Zhang
-
发布机构: Alibaba Group; Ant Group
TL;DR
本文提出了一种名为 Auto-Rubric 的无训练框架,通过一个两阶段(查询特定的准则生成与查询无关的准则聚合)过程,仅用极少量偏好数据即可自动提取出可解释、可泛化且高效的奖励模型评估准则(Rubric)集。
关键定义
- Auto-Rubric: 本文提出的核心框架,是一个无需训练、数据高效的自动化流程,用于从人类偏好数据中提取和提炼高质量的评估准则。
- Theme-Tips Rubric (主题-提示准则): 本文方法最终产出的结构化、可解释的准则集。它由高层次、概括性的“主题”(Themes,如“优先考虑清晰度”)和具体、可操作的“提示”(Tips,如“确保叙事连贯”)组成,形成一个层次化的评估体系。
- 学习奖励模型 vs. 推理准则 (Learning a Reward Model vs. Inferring a Rubric Set): 本文提出的范式转变。传统方法通过大规模数据学习一个“黑箱”的奖励函数 $r_{\theta}(x,y)$。本文方法则旨在直接推理出解释人类偏好的、明确可读的准则集 $R$,使评估过程透明化。
- 编码率最大化 (Coding Rate Maximization): 一种信息论度量,被本文用于从大量候选准则中筛选出信息量最大、冗余度最低的核心准则子集。其目标是最大化所选准则嵌入向量所张成的空间体积,从而保证准则的多样性。
- 查询特定准则 (Query-Specific Rubric) vs. 查询无关准则 (Query-Agnostic Rubric): 本文两阶段方法的核心概念。第一阶段为每个具体的偏好对生成“查询特定准则”。第二阶段将这些零散、具体的准则聚合提炼成一套通用的、适用于任何查询的“查询无关准则”。
相关工作
当前的大语言模型对齐研究主要依赖于通过人类反馈强化学习(RLHF)来训练奖励模型(RM)。然而,这一主流方法存在两大瓶颈:
- 高昂成本与低可解释性:训练奖励模型需要海量的人类偏好标注数据,成本极高。同时,训练出的奖励模型如同一个“黑箱”,其决策逻辑不透明,难以诊断失败原因,并存在“奖励 hacking”的风险。
- 准则生成与优化的脱节:为了提升透明度,研究人员开始探索基于准则(Rubric)的评估方法。早期的专家撰写准则难以规模化,而自动生成的准则则充满了噪声、冗余和冲突,缺乏有效的验证和优化机制。这导致了可扩展性与可靠性之间的根本矛盾。
本文旨在解决上述问题,特别是弥合自动准则生成与优化之间的鸿沟。其目标是创建一个系统性框架,能够仅用少量数据,以一种无需训练的方式,自动生成、提炼、筛选并组织成一套高质量、可解释且通用的评估准则集,从而取代不透明的奖励模型。
本文方法
本文提出一个系统性的框架,从少量人类偏好样本中推理出一套通用的、可解释的评估准则。该方法的核心思想是从“学习奖励模型”转变为“推理评估准则”,如下图所示,整个流程分为两个主要阶段。
范式转变:从学习参数到推理准则
传统的奖励建模旨在学习一个参数化函数 $r_{\theta}(x,y)$,通过最大化对数似然来使其符合人类偏好:
\[\nP(y_{i}^{+}\succ y_{i}^{-} \mid x_{i})=\sigma(r\_{\theta}(x_{i},y_{i}^{+})-r\_{\theta}(x_{i},y_{i}^{-})).\]这个过程产出的 $r_{\theta}$ 是一个不透明的函数。
本文将优化目标从学习参数 $\theta$ 转换为直接推理出能最好解释偏好数据的准则集 $R$:
\[\nR_{\text{task}}^{\*}=\arg\max_{R}\sum_{i=1}^{N}\mathbb{I}[\text{eval}_{R}(x_{i},y_{i}^{+},y_{i}^{-})=\text{correct}].\]其中,评估函数 $\text{eval}_{R}(\cdot)$ 是一个由自然语言准则 $R$ 指导的透明推理过程,通常由一个大语言模型执行。为了解决直接搜索 $R$ 的棘手问题,本文设计了以下的生成与聚合两阶段流程。
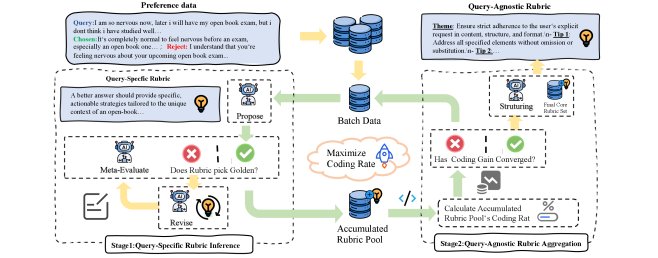
第一阶段:查询特定准则的生成 (Query-Specific Rubric Generation)
此阶段的目标是为每个偏好数据对 $(x_{i},y_{i}^{+},y_{i}^{-})$ 生成高质量、高度相关的准则。该过程通过一个“提出-评估-修订 (Propose-Evaluate-Revise)”的迭代循环实现,以保证准则的有效性。
- 提出 (Propose): 提案模型 $\mathcal{M}_{\text{propose}}$ 根据输入的查询和两个回答,生成一个初始的准则集 $R_{i}^{(0)}$。
- 评估 (Evaluate): 评估模型 $\mathcal{M}_{\text{evaluate}}$ 使用当前准则集 $R_{i}^{(t)}$ 对偏好对进行判断。这是一个关键的质量控制步骤。
- 修订 (Revise): 如果评估模型的判断与真实偏好不符,则说明当前准则 $R_{i}^{(t)}$ 存在问题。修订模型 $\mathcal{M}_{\text{revise}}$ 将根据失败的准则和原始输入,生成一个改进后的准则集 $R_{i}^{(t+1)}$。
该循环持续进行,直到评估模型做出正确判断或达到最大迭代次数。通过这种方式,可以为每个样本生成一个经过验证的、查询特定的准-则集 $R_{i}^{*}$,最终汇集成一个庞大的候选准则池 $\mathcal{R}_{\text{pool}}$。
第二阶段:查询无关准则的聚合 (Query-Agnostic Rubric Aggregation)
在获得庞大但冗余、零散的准则池 $\mathcal{R}_{\text{pool}}$后,此阶段的目标是提炼出一个简洁、全面且通用的核心准则集。
-
创新点:本文采用了一种信息论驱动的筛选策略,即最大化编码率 (Coding Rate)。其公式定义为:
\[\mathcal{C}(\mathbf{E}\_{R},\varepsilon)=\frac{1}{2}\log\det\left(\mathbf{I}+\frac{1}{\varepsilon^{2} \mid R \mid }\mathbf{E}\_{R}^{\top}\mathbf{E}\_{R}\right)\]最大化编码率等价于最大化准则嵌入向量所张成的空间体积,这能够有效筛选出语义上最多样化、最不冗余的准则。
- 筛选过程: 由于该优化问题是 NP-hard 的,本文采用贪心算法。从一个空集合开始,每一步都选择能带来最大边际信息增益(即编码率增量)的准则加入核心集 $R_{\text{core}}$,直到信息增益饱和(连续多步增益低于阈值)。
- 结构化: 最后,通过一个结构化语言模型将筛选出的核心准则组织成易于理解的“主题-提示 (Theme-Tips)”层级结构。
整个流程可以看作一个批处理迭代过程,不断从小批量数据中生成新的查询特定准则,并用它们来迭代优化通用的核心准则集,从而实现极高的数据效率。
准则分析框架
为了量化最终准则集的质量,本文还提出了一个分析框架,通过三个指标来评估每个准则 $r_j$ 的效用:
-
覆盖率 (Coverage): 衡量准则的普适性。
\[\text{Coverage}(r_{j})=\frac{1}{ \mid D_{\text{test}} \mid }\sum\_{i\in D_{\text{test}}}\mathbb{I}[\text{eval}_{\{r_{j}\}}(x_{i},y_{i}^{+},y_{i}^{-})\neq\text{tie}].\] -
精确率 (Precision): 衡量准则在提供有效判断时的可靠性。
\[\text{Precision}(r_{j})=P(\text{eval}_{\{r_{j}\}}\text{ is correct} \mid \text{eval}_{\{r_{j}\}}\neq\text{tie}).\] -
贡献度 (Contribution): 衡量准则在整个准则集中的不可替代性。
\[\text{Contribution}(r_{j})=\text{Acc}(R_{\text{task}})-\text{Acc}(R_{\text{task}}\setminus\{r_{j}\}).\]
该框架能验证准则集是否由互补的、平衡了通用性与专业性的准则组成。
实验结论
主要结果
- SOTA 性能: 本文方法在 RewardBench、RewardBench2、RM-Bench 和 JudgeBench 四个主流基准上均取得了当前最佳性能。例如,使用本文准则的 Qwen3-235B 在 RewardBench2 上达到 86.46% 的准确率。
- 跨模型尺寸的稳定提升: 本文的准则能显著提升不同规模基础模型的性能。特别地,它使得小模型也能具备强大能力,例如,Qwen3-8B 在使用本文准则后,其性能(在 RewardBench2 上为 80.91%)超越了专门的全量训练奖励模型 Skywork-Reward-V2-Qwen3-8B (78.20%)。
- 对不同来源数据的鲁棒性: 无论准则是从人类标注数据(HelpSteer3)还是 AI 标注数据(UltraFeedback)中提取,都能达到顶尖水平,证明了该框架能够从不同来源的偏好中捕捉到根本性的评估模式。
各模型在四个关键基准上的性能表现(百分比)
| 模型类别 | 模型 | RewardBench | RewardBench2 | RM-Bench | JudgeBench | 平均分 |
|---|---|---|---|---|---|---|
| 基础模型 | ||||||
| Qwen3-14B | 92.93 | 74.37 | 86.90 | 73.14 | 81.84 | |
| Qwen3-32B | 92.66 | 76.30 | 87.70 | 75.14 | 82.95 | |
| Qwen3-235B | 92.96 | 75.55 | 85.67 | 75.71 | 82.47 | |
| GPT-4o | 93.70 | 83.78 | 87.55 | 83.14 | 87.04 | |
| Few-shot | ||||||
| Qwen3-14B | 90.18 | 72.57 | 86.83 | 67.71 | 79.32 | |
| Qwen3-32B | 89.58 | 74.89 | 87.29 | 70.86 | 80.66 | |
| Qwen3-235B | 90.82 | 75.24 | 85.91 | 74.00 | 81.49 | |
| GPT-4o | 90.42 | 81.38 | 86.91 | 82.86 | 85.39 | |
| 全量训练 RM | ||||||
| ArmoRM | 90.40 | 66.50 | 69.30 | 59.70 | 71.48 | |
| J1 | 85.70 | – | 73.40 | 42.00 | 67.03 | |
| R3 | 93.30 | – | 82.70 | 60.00 | 78.67 | |
| RM-R1 (Qwen2-7B) | 87.50 | – | 82.10 | – | 84.80 | |
| RM-R1 (Yi-34B) | 89.30 | – | 84.90 | – | 87.10 | |
| Skywork-Reward-V2-Qwen1.5-7B | 92.90 | – | 79.10 | – | 86.00 | |
| Skywork-Reward-V2-Qwen1.5-32B | 90.90 | – | 83.90 | – | 87.40 | |
| Skywork-Reward-V2-Qwen3-8B | 93.70 | 78.20 | 82.60 | 73.40 | 81.98 | |
| 本文方法 (HelpSteer3) | ||||||
| Qwen3-8B | 93.50 | 80.91 | 88.28 | 75.71 | 84.60 | |
| Qwen3-14B | 93.74 | 81.66 | 83.15 | 79.71 | 84.57 | |
| Qwen3-32B | 93.80 | 82.27 | 88.11 | 80.86 | 86.26 | |
| Qwen3-235B | 94.61* | 86.46* | 89.51 | 85.43 | 89.07* | |
| 本文方法 (UltraFeedback) | ||||||
| Qwen3-8B | 93.10 | 80.54 | 88.60 | 75.43 | 84.42 | |
| Qwen3-14B | 93.67 | 80.91 | 88.72* | 78.86 | 85.54 | |
| Qwen3-32B | 93.03 | 80.69 | 87.50 | 79.14 | 85.09 | |
| Qwen3-235B | 94.54 | 85.97 | 88.60* | 87.14* | 89.06* |
数据效率与收敛性分析
实验证明了本文方法卓越的数据效率。通过一个早停机制,在信息增益饱和后停止迭代,最终仅使用了 70 个偏好对(占源数据 1.5%)就提炼出了最终的准则集。
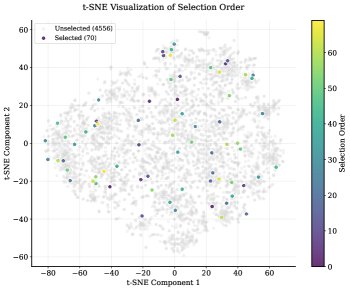
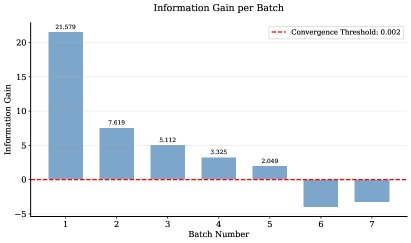
(a) t-SNE 可视化图显示,早期被选择的准则(颜色较深的点)广泛分布在不同语义簇中,表明算法优先选择多样化的准则以覆盖整个语义空间。(b) 信息增益图显示,编码率在前几个批次迅速增长后很快饱和,证明了方法的快速收敛性和高样本效率。
消融实验
消融实验验证了框架中各关键组件的必要性:
各框架组件的综合消融研究
| 组件类别 | 变体 | RewardBench2 | RM-Bench |
|---|---|---|---|
| 迭代优化 | |||
| 单次生成 | 79.84 | 86.07 | |
| 盲目修订(无失败准则反馈) | 81.98 (+2.14) | 85.79 (-0.28) | |
| 本文方法(完整迭代) | 82.27 (+2.43) | 88.11 (+2.04) | |
| 准则选择策略 | |||
| 随机选择 | 79.11 | 86.80 | |
| 本文方法(编码率) | 82.27 (+3.16) | 88.11 (+1.31) | |
| 层级结构 | |||
| 无特殊结构 | 81.14 | 87.41 | |
| 通用(带可选准则) | 80.01 (-1.13) | 86.28 (-1.13) | |
| 主题(无提示) | 80.77 (-0.37) | 87.59 (+0.18) | |
| 主题-提示 | 82.27 (+1.13) | 88.11 (+0.70) |
- 迭代优化: 完整的“提出-评估-修订”循环比单次生成和无反馈的修订效果更好,证明了验证驱动的反馈循环对于提升准则质量至关重要。
- 选择策略: 基于信息论的编码率最大化策略远胜于随机选择,表明有意识地追求多样性对于构建一个强大且不冗余的准则集至关重要。
- 层级结构: “主题-提示”的层级结构比扁平化的列表表现更优,说明通用准则(主题)和具体指导(提示)的结合是准则有效应用的关键。
- 跨模型泛化能力: 实验表明,本文方法提取的准则具有很强的可移植性。例如,将 Qwen3-32B 生成的准则应用于 GPT-4o,其在 RewardBench2 上的性能从 71.96% 飙升至 79.02%,证明了该方法捕获的是基础且可迁移的评估原则,而非特定模型的偏好。
核心准则分析
对最终提取的准则集进行量化分析,结果表明该准则集由高度互补的部分组成。例如,“优先考虑清晰度”这类基础准则具有极高的覆盖率(97.92%)和贡献度(移除后准确率下降 7.09%),是评估的基石。而“确保叙事连贯”这类专业准则虽然覆盖率较低(71.91%),但拥有最高的精确率(68.24%),能有效处理通用准则难以覆盖的特定场景。每个准则都具有显著的贡献度,证明了框架成功地构建了一个非冗余、功能互补的准则集合。