Autonomous Agents for Scientific Discovery: Orchestrating Scientists, Language, Code, and Physics
-
ArXiv URL: http://arxiv.org/abs/2510.09901v1
-
作者: Hongyi Ling; Yepeng Huang; Xiusi Chen; Junkai Zhang; Michael Sun; Xingyu Su; Xiaoxuan Wang; Xiner Li; Heng Ji; Wei Wang; 等15人
-
发布机构: Harvard Medical School; Massachusetts Institute of Technology; Texas A&M University; University of California, Los Angeles; University of Illinois Urbana Champaign
TL;DR
本文提出一个信息论框架来分析和构建用于科学发现的自主智能体(Autonomous Agents),通过对信息熵、可验证性和耗散的分析,建立了一套信息流转的分类体系,并在此基础上提出了一个衡量智能体自主能力的五级模型。
引言
科学发现正从传统的人类驱动模式,转向由大型语言模型(LLMs)驱动的自主系统(即智能体)加速的范式。尽管现有计算方法在特定领域取得了成功,但它们通常缺乏适应性和通用性,难以应对科学探索的广度和灵活性需求。LLMs的出现,以其强大的推理、规划和多模态处理能力,为构建统一、灵活的科学工作流提供了可能。
与现有的综述不同,本文旨在系统性地剖析LLM-based智能体在科学发现全周期(假设发现、实验设计与执行、结果分析与提炼)中的作用。本文的核心贡献在于:
- 建立一个信息论分析框架,用以理解自主科学发现的过程。
- 提出一个信息转化的分类体系(Taxonomy),以及一个评估科学智能体自主能力的五级模型。
- 识别现有方法的成就与局限,并展望未来方向。
面向科学发现的自主智能体概述
科学发现概述
科学发现是一个系统性地追求新知识或验证假设的过程。本文将其抽象为三个核心阶段:
- 假设发现 (Hypothesis Discovery):从海量数据和现有知识中识别有意义的问题,并形成可验证的科学假设。这是一个高度创造性的阶段,旨在揭示人类研究员难以发现的隐藏关联。
- 实验设计与执行 (Experimental Design and Execution):将高层级的科学目标转化为具体、可执行的协议。执行阶段将抽象策略变为经验证据,主要通过工具使用 (tool use) 和 工具创造 (tool creation) 来实现。目前LLM智能体主要集中在计算模拟而非湿实验。
- 结果分析与提炼 (Result Analysis and Refinement):分析实验输出,提炼科学洞见。这是一个迭代循环,通过审查结果、识别差异、并相应地修正假设或实验设计,来逐步优化科学成果。
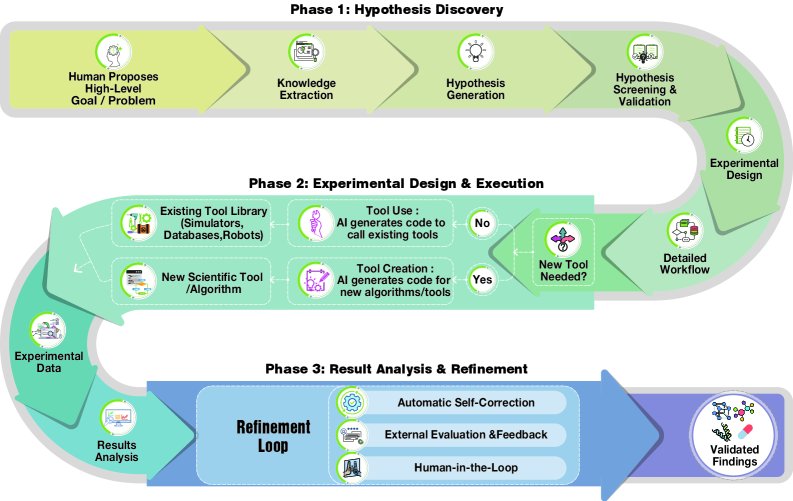
科学智能体概述
科学智能体是一种专门为模拟和自主执行科学研究过程而设计的AI系统。与通用LLM智能体不同,它们是高度领域特定和任务导向的。
下表总结了科学智能体与通用LLM智能体的关键区别:
| 特性 | 科学智能体 | 通用LLM智能体 |
|---|---|---|
| 主要目标 | 解决具体、复杂的科学问题,并产生新知识。 | 执行广泛、通用的任务(如对话、摘要)。 |
| 知识库 | 与专业的科学数据库、文献和模型深度集成。 | 基于广泛的互联网文本和通用知识。 |
| 推理 | 采用基于科学原理的严谨、多步逻辑推导和演绎。 | 通常采用常识性、启发式的推理。 |
| 工具使用 | 原生使用高度专业的软件(如模拟器)和硬件(如机器人)。 | 主要使用通用API(如搜索引擎、计算器)。 |
| 记忆 | 利用记忆积累领域知识,并从实验结果中学习。 | 主要用于维持对话上下文的短期记忆。 |
| 评估指标 | 成功与否由科学结果的准确性、可复现性和新颖性衡量。 | 成功与否由任务完成度、用户满意度衡量。 |
科学智能体的核心能力包括:
- 推理与规划:作为智能体的认知引擎,它能筛选海量文献数据以形成假设,并将高层目标分解为可执行步骤。
- 工具使用:作为连接认知与实践的桥梁,智能体不仅能调用模拟器、数据分析包等软件,还能通过编程接口操控实验室自动化设备等硬件。
- 记忆机制:作为持续研究和累积学习的基础,它能归档所有成功和失败的尝试,从中学习并优化策略,避免重复错误。
自主科学发现的信息论框架
本文提出了一个新颖的框架,通过信息论的视角来分析从人类主导到自主发现的转变。
核心信息属性
- 信息熵 (Information Entropy):源自信息论的数学度量,用于量化问题的不确定性或假设空间的大小。科学发现的核心任务之一就是熵减 (Entropy Reduction),即通过与物理世界的信息交换(如实验)来系统性地减少问题的不确定性。这个过程必须在开放系统中进行。
- 可验证性 (Verifiability):指信息能够被客观标准(形式、逻辑或经验)检验的属性。科学发现的目标就是将低可验证性的想法转变为高可验证性的经验事实。
- 耗散 (Dissipation):在探索问题空间时,因探索错误路径而产生的不可避免的计算成本和资源消耗。根据兰道尔原理 (Landauer’s Principle),任何不可逆的信息操作(如从众多不确定方案中确定唯一解)都必然伴随着能量耗散,其大小与必须探索并丢弃的非解决方案路径数量成正比。
信息分类体系
在自主科学发现中,信息经历一个层级式的转变过程,从高熵的人类意图转变为低熵、可验证的物理信息。这个过程涉及四种信息类型的转换:
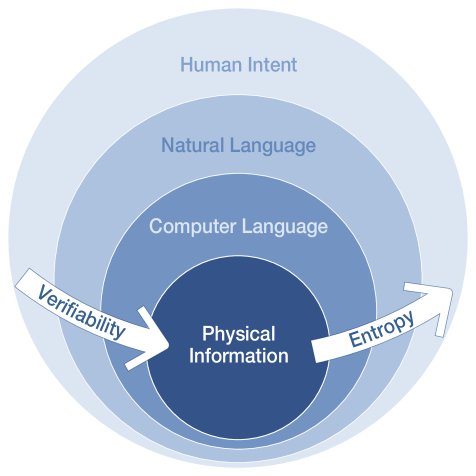
- 人类意图 (Human Intent):科学过程的起点,存在于巨大、非结构化的概念空间中。它拥有最高的信息熵和几乎为零的可验证性。
- 自然语言 (Natural Language):将高熵意图结构化的主要媒介。其熵值取决于上下文(创造性阶段高,命令阶段低)。其可验证性基于逻辑一致性。
- 计算机语言 (Computer Language):主要指代码,是形式化、无歧义的表示。将自然语言转为代码是一个显著的熵减过程。代码具有很高的可验证性,可以通过形式化规范进行测试。
- 物理信息 (Physical Information):从物理世界直接采集的原始经验数据(如测量值、信号)。尽管产生数据的物理过程可能熵很高,但记录的数据本身是事实。因此,物理信息拥有最高的可验证性,是评估原始假设的最终证据。
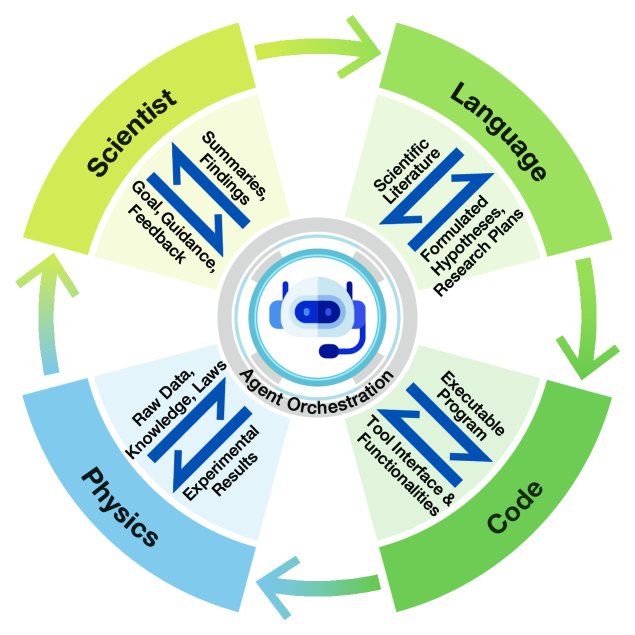
上图展示了LLM智能体作为协调者,编排科学家(人类意图)、语言(自然语言)、代码(计算机语言)和物理(物理信息)四个组件的闭环工作流。
各阶段的信息分析
运用信息论框架,本文评估了科学发现各阶段中不同信息类型的熵,并将其与自动化难度(耗散)联系起来。
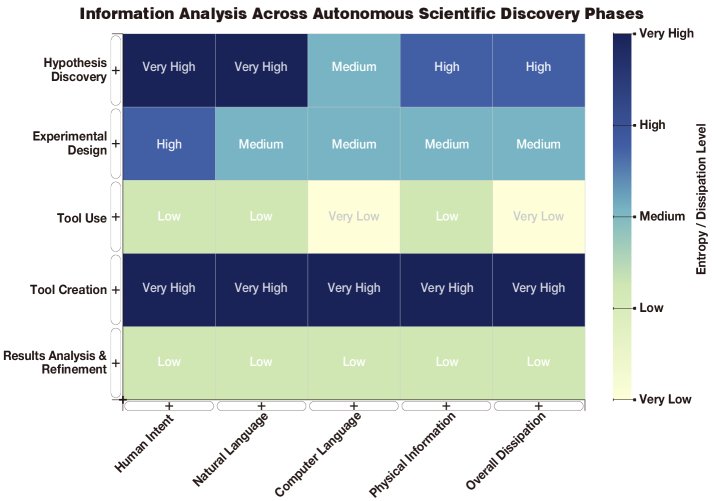
| 阶段 | 信息熵 | 耗散 | 自动化难度 | 核心挑战 |
|---|---|---|---|---|
| 假设发现 | 极高 | 高 | 困难 | 从海量可能性中发现单一有价值的洞见,高度创造性。 |
| 实验设计 | 中到高 | 中 | 中等 | 将抽象想法构建为具体计划,需在大型但受限的空间中搜索。 |
| 工具使用 | 低/极低 | 极低 | 容易 | 流程可预测,信息无歧义,是确定性的API调用。 |
| 工具创造 | 极高 | 极高 | 极困难 | 需要巨大的创造力来设计和实现全新的复杂算法。 |
| 分析与提炼 | 低 | 低 | 容易 | 任务是在有界的数据上下文中进行推断,而非无约束的探索。 |
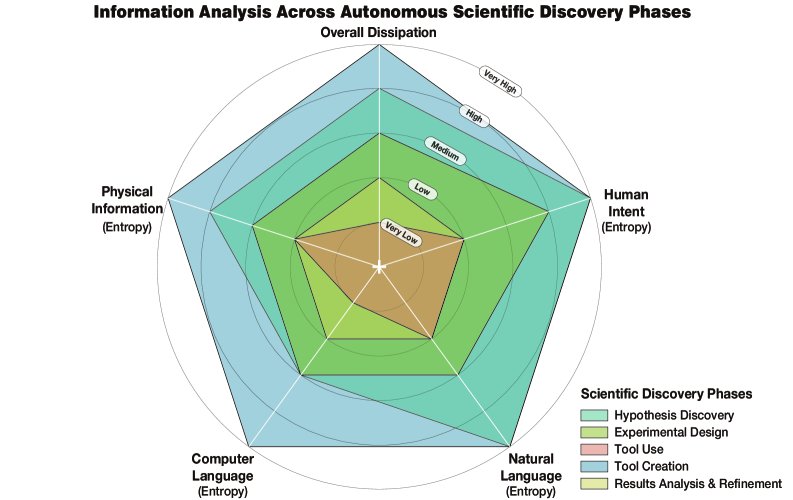
分析表明,工具创造是自动化最困难的阶段,因为它在所有信息类别上都表现出极高的熵和耗散。相反,工具使用和分析与提炼因其低熵和低耗散而最容易实现自动化。
面向科学发现的自主智能体分级
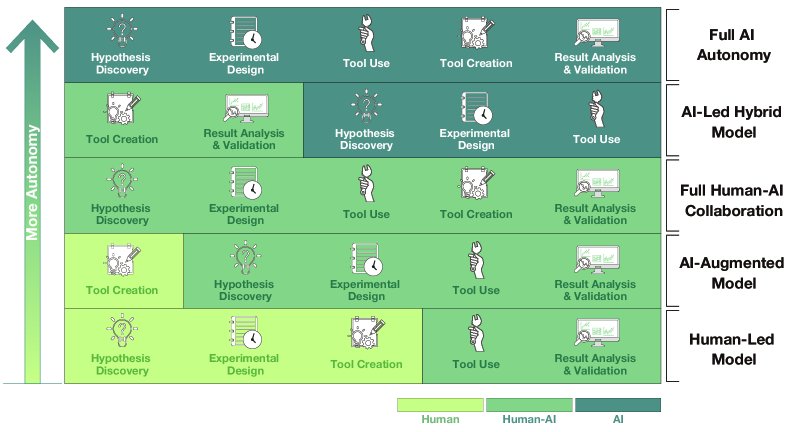
本文提出了一个五级自主能力框架,该框架比现有模型(如Zheng et al., 2025; Gao et al., 2024)更具粒度,因为它将自主性的进展与智能体处理信息(熵减、耗散、可验证性)的核心能力挂钩。
-
Level 1: 辅助执行 (Assisted Execution) 智能体仅作为工具,执行最低熵、最低耗散的任务(如工具使用)。人类承担所有创造性和规划的认知负荷。
-
Level 2: 协作支持 (Collaborative Support) 智能体开始在较高熵的领域(如假设发现、实验设计)中提供辅助,但仍依赖人类引导来收敛方向。
-
Level 3: 全方位协作 (Comprehensive Collaboration) 智能体成为全面的合作伙伴,与人类共同处理从创意构思到数据分析的所有任务。它是一个“力量倍增器”,但尚不能独立主导流程。
-
Level 4: 自主驱动,人类监督 (Autonomous Operation with Human Supervision) 智能体跨过一个关键阈值,能够独立主导核心科学任务(假设发现、实验设计、工具使用)。人类的参与聚焦于最高熵的任务(工具创造)和最终的分析与提炼,以确保结果的最终可验证性。
-
Level 5: 完全自主科学发现 (Fully Autonomous Scientific Discovery) 自主科学的顶峰。智能体能完全独立地管理从抽象目标到产出高可验证性科学事实的全过程,包括从零开始创造新工具这一最高耗散的任务。此时,智能体如同一个真正的自主科学家。