BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data
-
ArXiv URL: http://arxiv.org/abs/2510.10159v1
-
作者: Ziyin Zhang; Yurii Paniv; Negar Foroutan; Nikitas Theodoropoulos; Pouya Sadeghi; Leshem Choshen; Akari Haga; Linyang He; Faiz Ghifari Haznitrama; Bastian Bunzeck; 等20人
-
发布机构: Aix Marseille University; Bielefeld University; City University of Hong Kong; Columbia University; EPFL; Independent Researcher; KAIST; MIT; MIT-IBM Watson AI Lab; Nara Institute of Science and Technology; Shanghai Jiao Tong University; SomosNLP; Ukrainian Catholic University; University of California San Diego; University of Cambridge; University of Cape Town; University of Colorado Boulder; University of Groningen; University of Tehran; University of Texas at Austin; University of the Basque Country
TL;DR
本文提出了 BabyBabelLM,一个包含45种语言、模拟人类语言习得环境的多语言基准,旨在推动语言模型在数据效率和认知合理性方面的跨语言研究。
关键定义
本文提出或沿用了以下几个关键概念:
- BabyBabelLM: 本文提出的核心贡献,是一个多语言的基准,包含:(1) 在45种语言中精心策划的、符合发育合理性的训练数据集;(2) 一套覆盖形式能力和功能能力的评测套件;(3) 在这些数据上训练的单语、双语和多语基线模型。
- 发育合理性 (Developmental Plausibility): 构建数据集的核心指导原则,指预训练数据应尽可能模拟儿童在语言习得过程中实际接触到的语言输入。这包括优先选择儿童导向语音(CDS)、教育材料、儿童读物等,并特意排除了合成数据。
- 语言分层 (Language Tiers): 为了在不同语言数据资源不均衡的情况下进行公平比较,本文将45种语言根据数据集大小(经过跨语言校准的Token数量)分为三个等级:Tier 1(约1亿等效英语词)、Tier 2(1000万)和 Tier 3(100万)。
- 形式能力 (Formal Competence) 与 功能能力 (Functional Competence): 评测套件的两个维度。形式能力指对语言规则和模式的掌握(如语法);功能能力指在真实世界情境中理解和使用语言的能力(如推理、常识)。
相关工作
当前语言模型研究的主流趋势是追求规模扩张,这导致了两个关键问题:一是忽视了数据效率,使得模型训练成本高昂;二是模型学习方式与人类语言习得过程的差距越来越大,人类用不到1亿词汇就能掌握母语,而大模型则需要数万亿词汇。
作为应对,BabyLM Challenge 等研究开始关注数据效率和认知合理性,但这些工作绝大多数局限于英语。虽然有一些针对法语、德语、日语等语言的零散研究,但它们缺乏统一、可比的标准和数据集。
本文旨在解决的核心问题是:当前缺乏一个标准化的、跨越多语言的、符合发育合理性的训练与评测框架。通过构建 BabyBabelLM,本文为研究数据高效的、更接近人类学习方式的语言模型如何在不同类型语言中习得语言提供了关键基础设施。
本文方法
本文的核心贡献是创建了 BabyBabelLM 基准,其构建过程和组成部分如下。
数据集构建
创新点
本文方法的创新之处在于其系统性、原则性和可扩展性地构建了一个多语言、符合发育合理性的数据集。与以往零散的研究不同,它:
- 坚持发育合理性原则:严格筛选数据来源,优先选择儿童导向语音(CDS)、教育材料和儿童读物,并明确排除了可能扭曲语言分布的合成数据(如 TinyStories),以更真实地模拟儿童的语言环境。
- 实现跨语言可比性:通过引入“语言分层”(Language Tiers)和语言调整的字节估计方法,解决了不同语言数据资源量和文本编码效率差异的问题,使得跨语言的模型性能比较更加公平。
- 采用社区驱动模式:为每个语言指定熟悉该语言的研究者作为负责人,并建立了开源贡献流程,将 BabyBabelLM 设计成一个“活的资源”,能够持续吸收新的数据和语言,保证了其长期价值和质量。
数据集构成
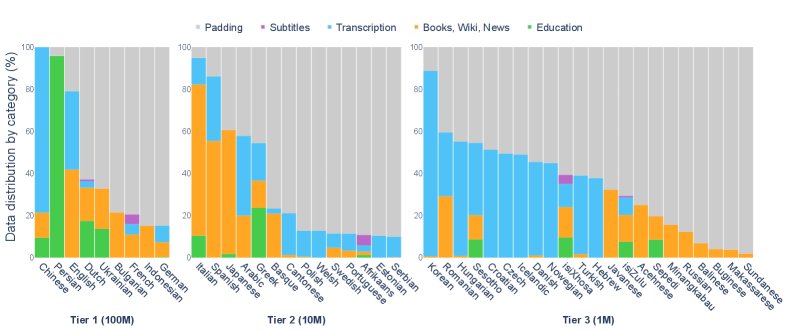
- 数据类别 (Data Categories):为模拟儿童接收到的多样化语言输入,数据集包含以下几类:
- 转录文本 (Transcription):主要来自 CHILDES 数据库的儿童导向语音(CDS),其特点是句子简短、结构简单、重复性高。同时包含部分成人间的对话。
- 教育 (Education):来自教科书和考试的材料,提供更直接的指导性内容。
- 书籍、维基、新闻 (Books, Wiki, News):儿童读物、儿童维基百科等,提供更长、更复杂的句子和更丰富的词汇。
- 字幕 (Subtitles):来自适合儿童观看的影视剧字幕,作为自然口语的近似。
- 填充数据 (Padding):为使各语言数据量达到所在层级的标准,使用经过筛选的 OpenSubtitles 等语料库进行填充。
- 语言覆盖与分层 (Language Tiers and Coverage):
- 覆盖45种语言,横跨印欧语系、闪米特语系、班图语系等多个语系,确保了语言的多样性。
- 根据数据量分为三个层级(Tier 1/2/3),分别对应约1亿/1000万/100万等效英语词汇量,以便进行公平的跨语言比较。
- 数据预处理 (Data Preprocessing):包括语言特定的初步处理和一套统一的标准化流程(如Unicode统一、空格、标点符号规范化),并使用 GlotLID v3 进行语言和脚本验证,以保证数据质量。
评测套件
本文构建了一个多语言评测套件,旨在评估模型的形式能力和功能能力。
- 形式能力评测:使用高质量的最小对(minimal pair)基准(如 MultiBLiMP、CLAMS),测试模型对主谓一致等语法规则的掌握程度。
- 功能能力评测:使用多项选择、问答等任务,评估模型的事实知识(如 Global-MMLU)、常识推理(如 HellaSwag, XCOPA)和阅读理解(如 Belebele)。
- 评测方式:对于最小对任务采用零样本(zero-shot)提示进行评测;对于分类和问答任务,由于基线模型规模较小,采用微调(fine-tuning)后进行评测。
基线模型
为了给后续研究提供一个起点,本文训练了一系列基线模型:
- 单语模型:为45种语言分别训练了一个17.1M参数的GPT-2架构模型。
- 双语模型:为Tier 1语言的数据集加入英语数据进行训练。
- 多语模型:一个111M参数的模型,在所有45种语言的数据上进行训练。
实验结论
本文对训练的基线模型进行了评估,主要结论如下:
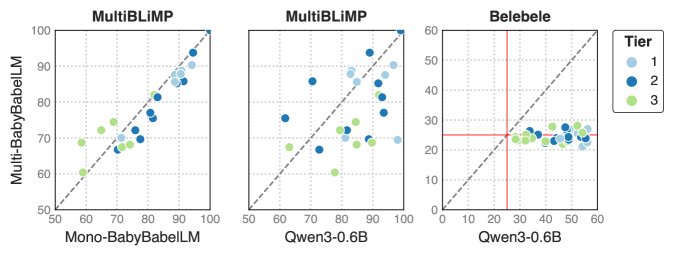
- 模型在形式能力上表现良好:单语模型在语言学基准(如 MultiBLiMP)上取得了不错的成绩,尤其是在数据量充足的 Tier 1 语言上,准确率通常超过80%。这证明即使是小型模型,在接触符合发育合理性的数据后也能掌握核心的语法知识。性能与数据量强相关,Tier 2 和 Tier 3 语言的模型表现相对较差。
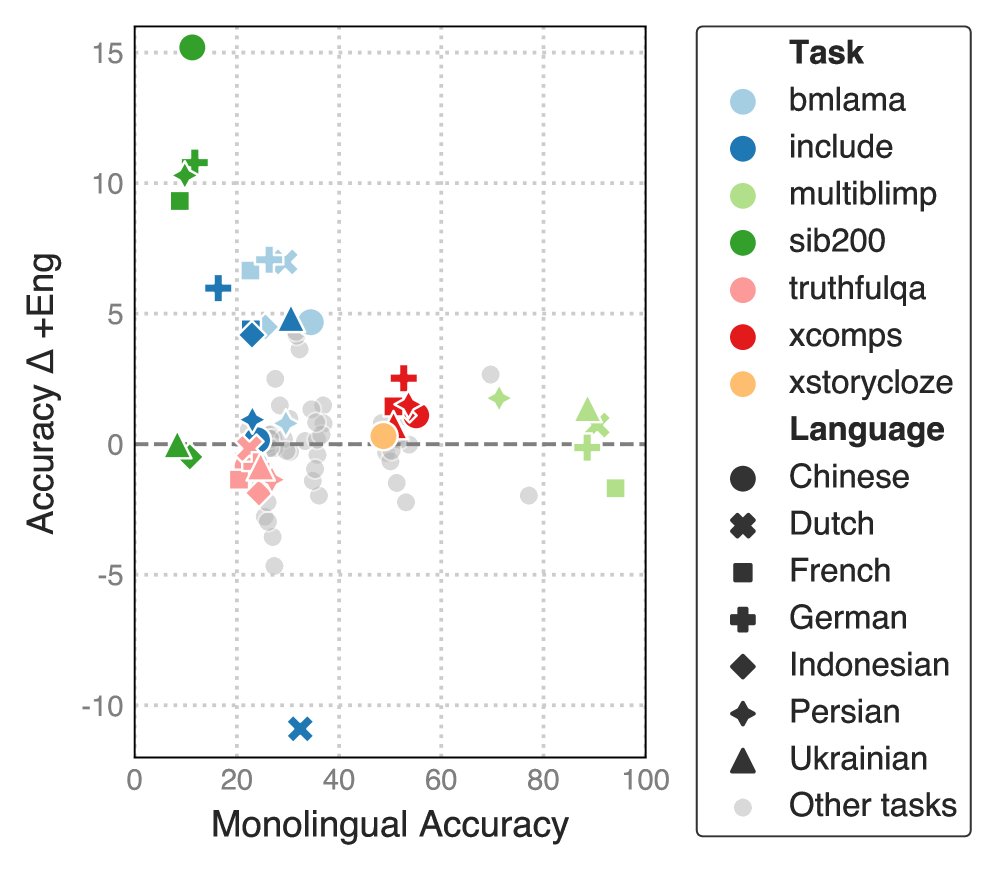
- 模型在功能能力上表现有限:在需要复杂推理和世界知识的功能性任务(如 XCOPA、ARC)上,模型的表现接近随机猜测。这表明,仅靠有限的发育合理性数据,这些小型模型难以获得高级的推理能力。
-
单语模型优于多语模型:在形式能力任务(MultiBLiMP)上,专门训练的单语模型通常优于在所有语言上训练的多语模型,这可能是因为多语训练分散了模型在单一语言上的学习深度。
-
双语训练效果不一:在单语数据中加入英语数据进行双语训练,对模型性能的影响是混合的。在某些任务和语言上有所提升,但在另一些上则有损害。
- 基线模型作为起点:实验结果表明,本文构建的基线模型本身性能有限(尤其与更大规模的模型如Qwen3-0.6B相比),但它们成功验证了基准的有效性,并为未来在 BabyBabelLM 上进行数据高效、认知启发式的模型研究提供了坚实的起点和比较基准。
下表展示了单语模型在各项任务上的平均准确率。
| 形式能力 | 功能能力 (微调后) | 功能能力 (零样本) | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tier | 语言 Language | Multi BLiMP | Linguistic-Probes | Belebele | XNLI | MMLU | SIB-200 | ARC-c | XCOPA | TQA | XStory Cloze | Hella Swag | Wino grande | XCOMPS | |||
| … | Random | 50.0 | 50.0 | 25.0 | 33.3 | 25.0 | 25.0 | 25.0 | 50.0 | 50.0 | 50.0 | 25.0 | 50.0 | 50.0 | |||
| 1 | Bulgarian | ||||||||||||||||
| 1 | Chinese | ||||||||||||||||
| 1 | Dutch | ||||||||||||||||
| 1 | English | ||||||||||||||||
| 1 | French | ||||||||||||||||
| 1 | German | ||||||||||||||||
| 1 | Indonesian | ||||||||||||||||
| 1 | Persian | ||||||||||||||||
| 1 | Ukrainian | ||||||||||||||||
| 2 | Afrikaans | ||||||||||||||||
| 2 | Arabic | ||||||||||||||||
| 2 | Basque | ||||||||||||||||
| 2 | Estonian | ||||||||||||||||
| 2 | Greek | ||||||||||||||||
| 2 | Hebrew | ||||||||||||||||
| 2 | Italian | ||||||||||||||||
| 2 | Japanese | ||||||||||||||||
| 2 | Polish | ||||||||||||||||
| 2 | Portuguese | ||||||||||||||||
| 2 | Serbian | ||||||||||||||||
| 2 | Spanish | ||||||||||||||||
| 2 | Swedish | ||||||||||||||||
| 2 | Welsh | ||||||||||||||||
| 2 | Yue Chinese | ||||||||||||||||
| 3 | Achinese | ||||||||||||||||
| 3 | Balinese | ||||||||||||||||
| 3 | Buginese | ||||||||||||||||
| 3 | Croatian | ||||||||||||||||
| 3 | Czech | ||||||||||||||||
| 3 | Danish | ||||||||||||||||
| 3 | Hungarian | ||||||||||||||||
| 3 | Icelandic | ||||||||||||||||
| 3 | Javanese | ||||||||||||||||
| 3 | Korean | ||||||||||||||||
| 3 | Makasar | ||||||||||||||||
| 3 | Minangkabau | ||||||||||||||||
| 3 | Norwegian | ||||||||||||||||
| 3 | Sepedi | ||||||||||||||||
| 3 | Romanian | ||||||||||||||||
| 3 | Russian | ||||||||||||||||
| 3 | Sesotho | ||||||||||||||||
| 3 | Sundanese | ||||||||||||||||
| 3 | Turkish | ||||||||||||||||
| 3 | isiXhosa | ||||||||||||||||
| 3 | isiZulu |