Balanced Actor Initialization: Stable RLHF Training of Distillation-Based Reasoning Models
-
ArXiv URL: http://arxiv.org/abs/2509.00309v1
-
作者: Siyuan Qiao; Xin Liu; Yuxin Song; Liang Xiang; Yuan Yang; Xun Zhou; Deyi Liu; Cheng Ren; Yonghui Wu; Chen Zheng; 等14人
-
发布机构: ByteDance
TL;DR
本文提出了一种名为“平衡智能体初始化 (Balanced Actor Initialization, BAI)”的两阶段加权模型合并方法,旨在解决当对经过蒸馏训练的推理模型应用强化学习(RLHF)时出现的训练不稳定问题,从而稳定地结合蒸馏的效率和人类反馈对齐的优势。
关键定义
- 范式三 (Paradigm 3):一种结合了两种主流大模型训练方法的混合范式,即在经过“基于蒸馏的推理能力微调(范式二)”的模型之上,再应用“从人类反馈中强化学习(RLHF)进行对齐(范式一)”。
- 序列长度坍塌 (Sequence Length Collapse):在范式三的早期RLHF训练阶段,模型生成的回复序列长度急剧缩短的一种现象。这削弱了模型进行详细推理的能力。
- 奖励曲棍球棒曲线 (Reward Hockey Stick Curve):在范式三的早期RLHF训练中,奖励模型评分出现先急剧下降、后缓慢回升的现象,其曲线形状类似于曲棍球棒。
- 平衡智能体初始化 (Balanced Actor Initialization, BAI):本文提出的核心方法。这是一种两阶段的加权模型合并策略,用于为RLHF的智能体(Actor)模型创建一个鲁棒的初始状态。第一阶段合并指令遵循模型和推理微调模型,第二阶段将合并后的模型与预训练基础模型再次合并。
相关工作
目前,提升大语言模型的对齐和推理能力主要有两种成熟的范式:
- 范式一:指令微调和RLHF对齐范式,通过监督微调(SFT)和RLHF使模型行为与人类偏好对齐。
- 范式二:基于蒸馏的推理微调范式,通过在由更强大模型生成的高质量推理数据上进行训练,使小模型获得复杂的推理能力。
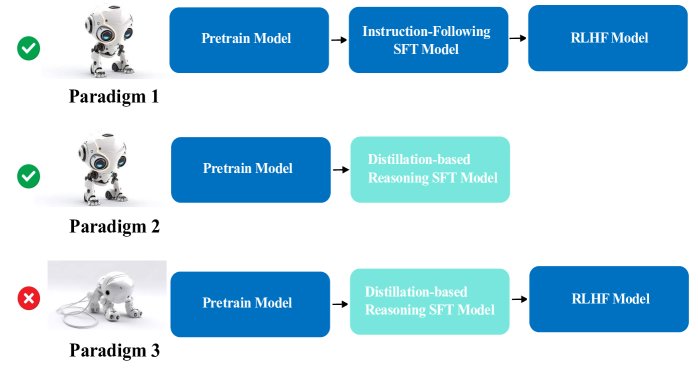
这两种范式各自都取得了成功。一个自然而然的思路是结合两者,即范式三:对经过蒸馏推理训练的模型再进行RLHF。然而,实践表明这种结合会导致严重的训练不稳定问题。
本文旨在解决范式三中出现的两个关键问题:
- 序列长度坍塌:模型在RLHF训练初期突然无法生成长推理链。
- 奖励曲棍球棒曲线:奖励分数在训练初期急剧下降,破坏了学习过程。
这些问题源于蒸馏 SFT 阶段学到的专门推理模式与 RL 优化目标之间的不匹配,阻碍了更强大推理模型的开发。
本文方法
为了解决上述训练不稳定性,本文提出了平衡智能体初始化 (Balanced Actor Initialization, BAI),一种在RLHF训练开始前通过模型合并来创建鲁棒智能体初始状态的方法。
创新点
BAI的核心创新在于使用一种确定性、可控的模型合并方法来替代依赖不明确数据配比的“冷启动”方案,从而为RLHF训练提供一个更理想的起点。它通过两阶段合并,巧妙地平衡了模型的专业能力与基础知识。
3.1.1 第一阶段:多SFT模型合并
此阶段旨在整合不同SFT模型的专业能力。将多个($N$个)经过SFT训练的模型(例如,一个用于指令遵循,一个用于蒸馏推理)的参数进行加权线性组合。
\[\mathbf{M}_{\text{merge}}^{\text{sft}}=\sum_{i=1}^{N}w_{i}\mathbf{M}_{i}^{\text{sft}}\]其中,\($\mathbf{M}\_{i}^{\text{sft}}\)$ 是第 \(i\) 个SFT模型的参数,\($w\_i\)$ 是其权重,且 \($\sum w\_i = 1\)$。本文中,作者等权重地(\($w\_1=w\_2=0.5\)$)合并了指令遵循SFT模型和蒸馏推理SFT模型。
3.1.2 第二阶段:为RL智能体进行平衡合并
第一阶段合并出的模型虽然专业能力强,但可能遗忘了预训练模型中的广泛知识(灾难性遗忘)。直接将其用作RL智能体会导致性能下降。因此,第二阶段将第一阶段的产物 \($\mathbf{M}\_{\text{merge}}^{\text{sft}}\)$ 与原始的预训练基础模型 \($\mathbf{M}^{\text{base}}\)$ 进行合并,以保留基础知识。
\[\mathbf{M}^{\text{BAI}}=\alpha\cdot\mathbf{M}^{\text{base}}+\beta\cdot\mathbf{M}_{\text{merge}}^{\text{sft}}\]其中,\($\alpha\)$ 和 \($\beta\)$(\($\beta=1-\alpha\)$)是合并系数,用于控制预训练知识和微调能力之间的平衡。最终得到的 \($\mathbf{M}^{\text{BAI}}\)$ 作为RLHF训练的初始智能体模型。
优点
- 整合互补能力:第一阶段有效集成了不同微调阶段的专业技能,如推理和指令遵循。
- 防止灾难性遗忘:第二阶段通过引入预训练模型,保留了其丰富的世界知识和语言能力,增强了模型的鲁棒性。
- 可解释与可控:通过调整合并系数 \($\alpha\)$ 和 \($\beta\)$,可以精确地控制知识保留和行为适应之间的权衡,具有很强的可解释性和可操作性。
实验结论
性能对比
实验结果表明,BAI方法在多个基准测试中表现出色。
| 方法 | MMLU Pro | MMLU | SuperGPQA | LiveBench | MixEval-Hard | ArenaHard | AIME 2024 | MATH | MBPP+ | 总体 |
|---|---|---|---|---|---|---|---|---|---|---|
| 范式 1 | 67.8 | 80.8 | 38.1 | 44.4 | 48.5 | 15.4 | 18.7 | 80.9 | 67.5 | 51.3 |
| 范式 2 | 69.7 | 82.0 | 40.7 | 42.3 | 50.0 | 34.6 | 17.3 | 77.6 | 67.5 | 53.6 |
| 范式 3 | 69.2 | 80.8 | 40.5 | 43.0 | 51.5 | 16.0 | 17.7 | 77.5 | 67.2 | 51.5 |
| BAI | 70.2 | 82.7 | 40.6 | 44.9 | 50.8 | 35.9 | 21.3 | 81.0 | 69.3 | 55.2 |
- 全面超越:如表1所示,BAI在总体得分上(55.2)显著优于所有三个独立的范式。特别是在数学推理(AIME, MATH)和对话能力(ArenaHard)等任务上提升明显。
- 解决不稳定性:
- 奖励曲棍球棒曲线:如图2所示,未使用BAI的范式三(粉色曲线)在训练初期奖励分数急剧下降,而使用BAI后(蓝色曲线)奖励分数从一开始就保持稳定增长,有效缓解了此问题。
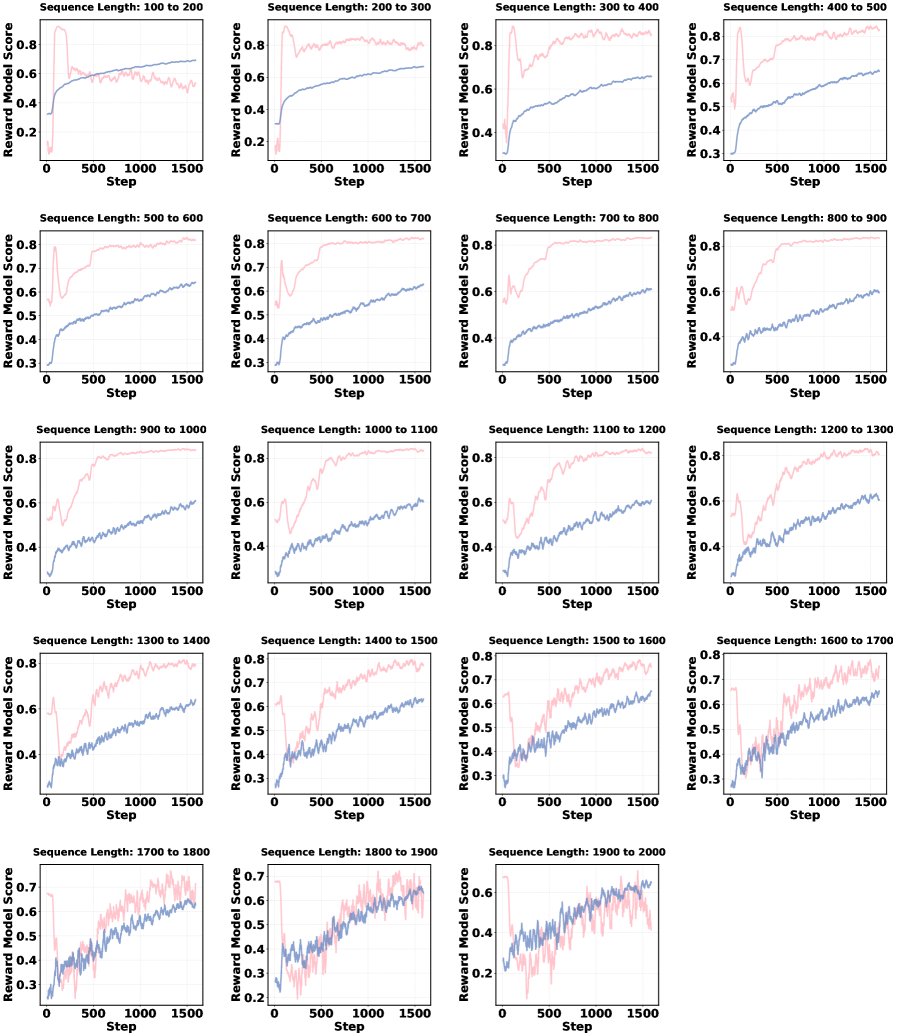
图2: 不同生成序列长度下的奖励曲线。粉色为未使用BAI的范式三,蓝色为使用BAI的范式三。 - 序列长度坍塌:如图3所示,未使用BAI的模型在训练初期序列长度急剧下降且无法恢复。而使用BAI(以 \($\alpha=0.6, \beta=0.4\)$ 为例)的模型不仅没有出现坍塌,其序列长度在整个训练过程中还持续增长,显示出健康的学习动态。
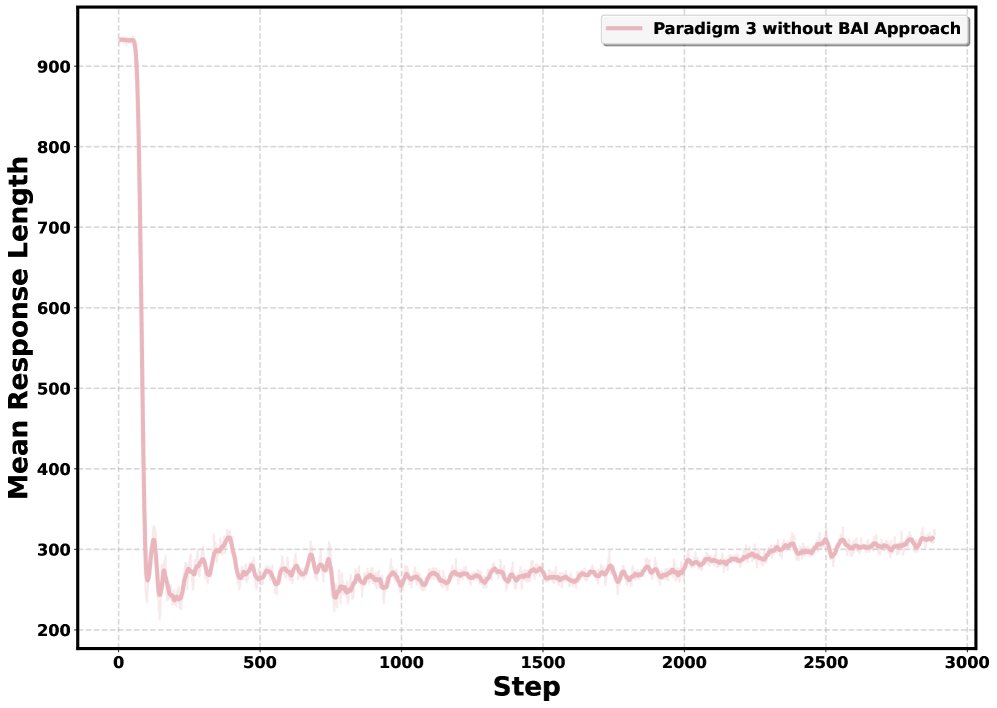
图3: 3000步训练中,(a)不使用BAI 和 (b)使用BAI 的平均序列长度对比。
合并比例分析
对不同合并比例(\($\alpha\)$)的分析表明:
| $\alpha\cdot\mathbf{M}^{\text{base}}+\beta\cdot\mathbf{M}_{\text{merge}}^{\text{sft}}$ | $\alpha=0.1, \beta=0.9$ | $\alpha=0.2, \beta=0.8$ | $\alpha=0.5, \beta=0.5$ | $\alpha=0.7, \beta=0.3$ | $\alpha=0.9, \beta=0.1$ |
|---|---|---|---|---|---|
| MMLU Pro | 70.2 | 69.7 | 70.7 | 68.6 | 68.1 |
| MMLU | 82.7 | 81.3 | 80.9 | 81.8 | 81.3 |
| ArenaHard | 35.9 | 33.3 | 25.2 | 16.0 | 11.5 |
- SFT-heavy表现优异:倾向于SFT模型的配置(如\($\alpha=0.1, \beta=0.9\)$)在大多数基准上表现最佳,尤其是在需要结构化推理的MMLU Pro和ArenaHard上,这表明保留微调阶段学到的专业推理模式至关重要。
- 平衡配置更稳定:中等或平衡的合并比例(如\($\alpha=0.5, \beta=0.5\)$)不仅能有效防止序列长度坍塌,还能在训练中实现序列长度的持续增长,显示出最健康的训练动态。KL散度分析也证实了平衡配置能在策略适应和训练稳定之间取得最佳平衡。
总结
本文成功识别并解决了在蒸馏推理模型上应用RLHF时出现的两大核心不稳定问题。提出的BAI方法通过简单有效的两阶段模型合并,创建了一个鲁棒的初始智能体,不仅解决了序列长度坍塌和奖励分数不稳定的问题,还在多个基准测试上取得了最优性能。这为结合蒸馏学习和RLHF的范式三提供了一条稳定且高效的实践路径。