BaseReward: A Strong Baseline for Multimodal Reward Model
-
ArXiv URL: http://arxiv.org/abs/2509.16127v1
-
作者: Haotian Wang; Chaoyou Fu; Xu Wang; Bo Cui; Kai Wu; Haochen Tian; Yang Shi; Zezhou Chen; Liang Wang; Haihua Yang; 等13人
-
发布机构: ByteDance; CASIA; NJU; Peking University; Tsinghua University
TL;DR
本文通过一系列详尽的实验,系统性地探究了构建高性能多模态奖励模型的关键要素,总结出一套清晰的“配方”,并基于此提出了一款名为 BaseReward 的强大基线模型,在多个主流基准测试中达到了新的SOTA水平。
关键定义
本文主要沿用并对比了奖励模型领域的三种主流范式,对理解本文的实验设计至关重要:
- 朴素奖励模型 (Naive-RM):最直接的方法,在预训练的多模态大语言模型 (MLLM) 顶部接一个线性奖励头,直接输出一个标量奖励分数。这种方法训练和推理速度快,但可解释性差。
- 基于评论家的奖励模型 (Critic-based RM):分两步走,首先让模型生成对回答的文本评论或分析,然后由一个奖励头对生成的评论文本进行打分。这种方法在性能和效率之间取得了平衡,但其效果严重依赖于评论的质量。
- 生成式奖励模型 (Generative RM):将奖励建模重新定义为一个生成任务。模型直接生成一个特定的Token或短语,来指示两个回答中哪一个更优。这种方法可解释性强,但计算开销和训练效率较低。
相关工作
随着多模态大语言模型 (Multimodal Large Language Models, MLLMs) 的飞速发展,如何使其输出与人类偏好对齐变得至关重要。奖励模型 (Reward Models, RMs) 是实现这一目标的核心技术,尤其是在通过人类反馈强化学习 (Reinforcement Learning from Human Feedback, RLHF) 的流程中。
然而,当前领域内缺乏一个关于如何构建最先进的多模态奖励模型 (Multimodal Reward Models, MRMs) 的系统性、全面的指南。现有的SOTA MLLM大多采用各自独特的奖励建模策略,例如生成式奖励模型、双奖励模型(文本与多模态分离)或针对特定领域的奖励策略。这种方法论的多样性反映出研究领域的碎片化。
本文旨在解决的核心问题是:构建高性能MRM的最佳实践或“配方”是什么? 为此,本文系统性地回答了一系列关键问题,例如:哪种奖励模型架构性能最好?奖励头的最佳结构是什么?不同来源的数据(包括纯文本偏好数据)如何影响模型性能?基座模型和模型规模扮演什么角色?
本文方法
本文的核心贡献是提供了一套构建高性能MRM的“配方”,这套配方是通过对MRM开发流程中每个关键环节进行详尽的实验分析得出的。最终,基于这些发现,本文构建了BaseReward模型。
奖励建模方法对比
本文首先对三种主流的奖励模型范式进行了公平比较:Naive-RM、Critic-based RM 和 Generative RM (GRM)。
- 实验设置:所有模型均使用统一的默认数据集和训练策略。对于需要生成推理过程的GRM,使用GPT-4o来生成所需数据。
- 核心发现:
- GRM在安全和代码等依赖模型内置知识的任务上表现出优势。
- 在VQA、常识和幻觉等任务上,Naive-RM与GRM性能相当甚至更优。
- 考虑到Naive-RM在计算成本和实现简单性上的巨大优势,且其性能短板可通过补充特定训练数据来弥补,本文选择Naive-RM作为后续研究的重点。
奖励模型设计
本文发现,奖励头的设计对Naive-RM的性能有显著影响,并重点研究了其层数和激活函数。
- 奖励头层数 (Number of Layers):过多层数增加复杂性,过少则限制表达能力。
- 激活函数 (Activation Function):影响模型的非线性映射能力和梯度流。
核心发现:实验表明,采用2层MLP并使用SiLU作为激活函数的奖励头配置,能达到最佳性能。仅用1层线性头效果最差,而增加更多层数或使用其他激活函数(如ReLU, Tanh)均未带来明显增益。
训练正则化策略
本文研究了两种常见的正则化技术对奖励模型训练的影响。
- 零系数正则化 (Zero-coefficient Regularization):通过一个惩罚项,鼓励模型对“选择的”和“拒绝的”回答给出的奖励分数之和接近于零。
- 长度归一化 (Length Normalization):通过回答长度的对数来归一化奖励分数,以减轻模型对长回答的偏好。
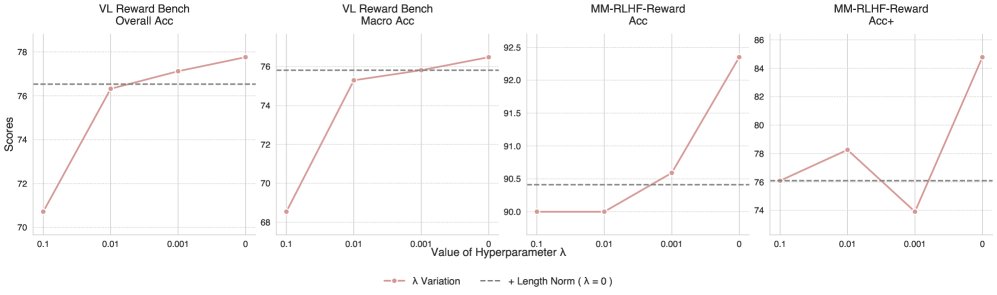
核心发现:如上图所示,随着零系数正则化权重 \($\lambda\)$ 的增加,模型性能普遍下降。单独使用长度归一化也未能带来任何性能提升。因此,在最终的训练配置中,不采用任何正则化损失。
训练数据集分析
数据是决定模型能力的关键。本文收集了十余个公开的多模态和纯文本偏好数据集,并分别在每个数据集上独立训练奖励模型,以评估其影响。
| 数据集名称 | 类型 | 大小 | 链接 |
|---|---|---|---|
| MMIF | 多模态 | 22k | Link |
| Omni-Align | 多模态 | 120k | Link |
| RLAIF-V | 多模态 | 83k | Link |
| MMPR v.12 | 多模态 | 2M | Link |
| R1-Reward | 多模态 | 200k | Link |
| Unltra-All | 纯文本 | 300k | Link |
| SHP | 纯文本 | 348k | Link |
| Tulu-3 | 纯文本 | 65k | Link |
| Olmo-2 | 纯文本 | 378k | Link |
| Unltra-Hard | 纯文本 | 63k | Link |
| Others | 纯文本 | 63k | WildChat, swe-arena, etc. |
核心发现:
- 数据筛选至关重要:部分数据集(如MMIF, SHP)对性能提升有限甚至有负面影响,说明高质量的数据筛选是必要步骤。
- 不同数据各有专长:例如,MMPR和RLAIF-V在提升模型对幻觉的辨别能力方面效果显著,而R1-Reward对推理任务更有效。
- 纯文本数据能显著增强多模态能力:令人意外的是,使用高质量的纯文本偏好数据(如Ultra-Hard, Olmo-2)训练模型,其在多模态基准上的表现不亚于多模态数据,尤其在安全和数学维度上提升显著。
- 保留文本能力需混合训练:为了让MRM同时具备强大的纯文本奖励判断能力,混合纯文本数据进行训练是必要的。
文本任务优化
既然文本数据能增强多模态能力,那么多模态数据能否反哺纯文本任务?
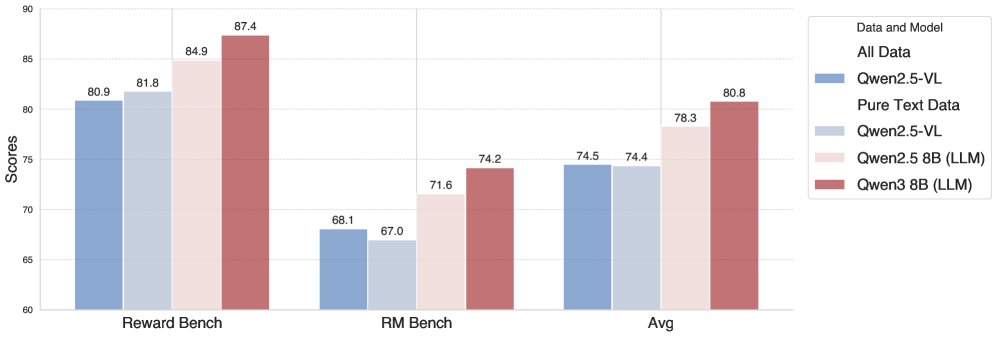
核心发现:实验表明,对于纯文本奖励建模任务,基于LLM架构的模型本质上比同等规模的MLLM架构更具优势。如下图所示,使用混合数据训练的MLLM在纯文本基准上并未比仅用文本数据训练的MLLM表现更好,且两者均不如在相同文本数据上训练的LLM。因此,当前最优策略是为纯文本任务训练一个专门的RM,并在RL阶段根据输入类型动态选择使用,而非强求一个模型通吃所有。
基座模型与规模的影响
本文比较了不同系列(Qwen-VL, Intern-VL)和不同规模的基座模型。
核心发现:
- 架构有偏好:Qwen-VL系列在多模态奖励基准上表现更优,而Intern-VL系列在纯文本基准上更有优势。
- 扩大规模收益有限:简单地扩大MLLM的参数规模(如从2B到8B)带来的性能提升并不显著。对于计算资源受限的场景,10B以下参数规模的模型是高效且具性价比的选择。
模型集成策略
鉴于不同数据和模型在不同能力维度上各有千秋,本文探索了模型集成策略。
核心发现:
- 集成效果显著:模型集成能在多模态和纯文本基准上带来稳定的性能提升。
- 简单平均法有效:与复杂的、需要验证集来确定权重的集成方法相比,简单的对多个模型输出的奖励分数进行平均,就能取得很好的效果,且无需额外数据和操作。
- 增加多样性持续提升:在集成模型中加入一个专门在纯文本数据上训练的LLM奖励模型,可以显著提升在纯文本基准上的性能,证明了增加集成内模型多样性的有效性。
BaseReward模型
综合以上所有实验结论,本文提出了BaseReward。
- 架构:以Qwen2.5-VL-7B为基座,配备一个2层MLP奖励头,中间使用SiLU激活函数。
- 训练策略:不使用任何正则化损失,学习率为\($3\mathrm{e}{-6}\)$,批次大小为128。
- 训练数据:使用了经过筛选的7个高质量数据集,混合了多模态和纯文本偏好数据,总计约280万对偏好数据。
实验结论
基准测试结果
BaseReward在多个主流MRM基准测试上取得了SOTA成绩,全面超越了此前的开源和闭源模型。
- 在 MM-RLHF-Reward Bench 上,BaseReward的准确率比之前的SOTA高出11.9%。在更严格的Acc+指标上,提升幅度达到23.32%。
- 在 VL-Reward Bench 的Overall Accuracy上,BaseReward比之前的最佳模型提升了14.2%。
- 值得注意的是,BaseReward作为一个Naive-RM,推理速度极快,而其他一些高性能模型(如R1-Reward, MM-RLHF-Reward)需要生成步骤,计算开销远大于BaseReward。
| Model | MM-RLHF-Reward Bench (Acc / Acc+) |
|---|---|
| MM-RLHF-Reward-7B | 79.52 / 62.00 |
| IXC-2.5-Reward | 81.65 / 62.26 |
| Claude 3.7 Sonnet | 81.80 / 62.26 |
| BaseReward (ours) | 93.57 / 85.58 |
| BaseReward (voting, ours) | 94.61 / 87.79 |
| Model | VL-Reward Bench (Overall Acc / Macro Avg) |
|---|---|
| MM-RLHF-Reward-7B | 73.10 / 72.80 |
| IXC-2.5-Reward | 75.30 / 75.20 |
| SliME-7B | 74.90 / 74.90 |
| BaseReward (ours) | 89.50 / 89.20 |
| BaseReward (voting, ours) | 90.30 / 90.00 |
在强化学习中的应用
为了验证BaseReward在实际应用中的效果,本文将其整合到一个RLHF流程中,使用GRPO算法对Qwen-2.5-VL 3B模型进行微调。
实验对比了三种奖励机制:
- 基于规则的奖励:输出与标准答案完全匹配则奖励为1,否则为0。
- 基于BaseReward的奖励:奖励分数直接由BaseReward模型给出。
- 混合奖励:优先使用规则判断,若不匹配,则使用BaseReward的分数(归一化到[0, 1])。
| Reward Mechanism | MMbench | MME-Lite | MMStar | Mathvista | V* | Llavawild | Wildvision | Average |
|---|---|---|---|---|---|---|---|---|
| SFT | 77.2 | 1656 | 54.9 | 43.1 | 68.3 | 82.2 | 68.1 | 77.4 |
| Rule-Based Only | 77.4 | 1645 | 55.4 | 45.6 | 68.9 | 82.3 | 68.3 | 78.4 |
| R1-Reward | 77.4 | 1640 | 55.3 | 43.8 | 69.1 | 82.6 | 68.6 | 78.1 |
| BaseReward | 77.8 | 1652 | 55.6 | 43.9 | 69.8 | 83.2 | 69.3 | 78.8 |
| Rule-Based + BaseReward | 78.1 | 1663 | 55.9 | 45.3 | 70.2 | 83.6 | 69.8 | 79.6 |
核心结论:
- BaseReward优于R1-Reward:在所有基准上,使用BaseReward作为奖励信号的模型性能均优于使用R1-Reward的模型,且BaseReward的计算效率远高于R1-Reward。
- 混合策略是最佳实践:结合了规则精度和模型语义理解能力的“Rule-Based + BaseReward”混合策略,在逻辑推理、感知和对话等各类任务中均取得了最稳定和显著的性能提升。这证明了BaseReward作为高质量奖励信号的实用价值。
总结
本文不仅提供了一个SOTA的MRM模型BaseReward,更重要的是,通过系统性的实验为社区提供了构建下一代MLLM的强大奖励模型的清晰、有数据支撑的“配方”。局限性在于,未探索72B以上更大规模模型的潜力,以及如何让MLLM在纯文本奖励任务上超越专用LLM仍是一个开放问题。