Beyond Pipelines: A Survey of the Paradigm Shift toward Model-Native Agentic AI
-
ArXiv URL: http://arxiv.org/abs/2510.16720v1
-
作者: Jitao Sang; Jinlin Xiao; Yuhang Wang; Jilin Chen; Xiaoyi Chen; Shuyu Wei
-
发布机构: Beijing Jiaotong University
引言
近年来,AI领域的发展由生成式AI主导,但其本质上仍是被动响应。为了超越被动生成,实现自主行动,研究焦点正转向智能体AI (Agentic AI),它强调自指导行为、复杂推理和环境交互。智能体AI被广泛视为AI系统演化的下一阶段。
学术界和工业界普遍认为,智能体AI包含三个核心能力:
- 规划 (Planning):将高层目标分解为连贯的多步策略。
- 工具使用 (Tool use):调用和协调API、数据库等外部资源。
- 记忆 (Memory):在长时间跨度内保留、检索和管理信息。
智能体AI的发展与这些核心能力的实现方式演进紧密相关,这一过程正在经历深刻的范式转变。
范式分类体系
本文的核心分类体系将智能体AI的构建方法划分为两大范式:基于流水线的范式和模型原生范式。
基于流水线的范式 (Pipeline-based Paradigm)
早期的智能体构建可被归纳为“流水线”范式,其核心能力由外部逻辑和工作流(workflow)架构驱动:
- 规划:早期依赖外部符号规划器(如PDDL),后来发展为通过提示工程(如思维链 CoT, 思维树 ToT)引导模型逐步阐述其思考过程。
- 工具使用:最初是单轮函数调用,后发展为ReAct等框架,通过外部的“思考-行动-观察”循环提示模型交替进行推理和动作调用。
- 记忆:短期记忆通过对话摘要实现,长期记忆则依赖检索增强生成 (Retrieval-Augmented Generation, RAG)。
在这种范式下,智能体的能力并非模型内生,而是通过外部精心设计的流水线工程化实现的。其局限性在于系统僵化、脆弱,难以适应动态变化的环境,且将大语言模型(LLM)视为被动工具而非主动决策者。
模型原生范式 (Model-native Paradigm)
为克服流水线范式的局限,智能体AI正转向以“模型原生”为核心的范式。其理念是从构建复杂的外部智能体系统,转向训练一个本身就是系统的强大智能体模型。规划、工具使用和记忆不再是外部脚本,而是通过端到端训练内化为模型的内在行为:
- 规划:OpenAI的推理模型和DeepSeek的\(DeepSeek-R1\)模型通过大规模强化学习证明,LLM可以学会自主“思考”和规划,特别是基于结果的奖励被证明足以训练出推理行为。
- 工具使用:OpenAI的模型和月之暗面的\(Kimi\)模型展示了将工具使用集成到推理过程中,通过多阶段强化学习过程增强了智能体的工具使用和多步决策能力。
- 记忆:短期记忆方面,\(Qwen-2.5-1M\)通过扩展原生上下文窗口解决信息记忆问题;\(MemAct\)则将上下文管理视为一种模型学会调用的工具。长期记忆方面,\(MemoryLLM\)等工作开创性地将记忆直接参数化,通过模型前向传播持续更新,实现知识的自动内化。
模型原生范式将LLM视为自主决策者,使其能够生成计划、调用工具和管理记忆,这些都是其内在习得的行为。
应用演进
核心能力的范式转变也重塑了智能体应用的发展路径。目前,智能体应用主要沿着两条主线演进:作为“大脑”的深度研究智能体 (Deep Research Agent) 和作为“眼手”的图形界面智能体 (GUI Agent)。
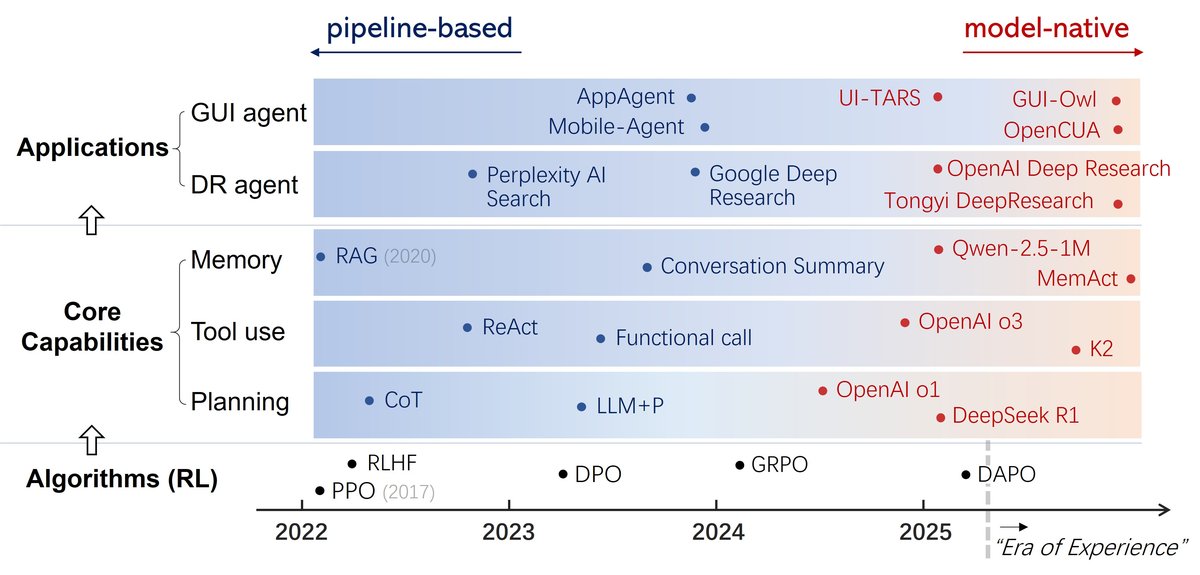
深度研究智能体
早期形式如Perplexity的AI搜索,其构建了一个包含查询扩展、信息检索和答案生成的智能体流水线。Google则将单轮搜索升级为多轮迭代的“深度研究”过程,但早期版本仍依赖精心设计的流水线。
范式转变的标志是OpenAI推出的首个模型原生深度研究智能体,它基于其智能体基础模型进行微调,通过模型的内部策略来规划整个研究过程,显著提升了长时程一致性和信息发现深度。后续,通义实验室的WebAgent系列,特别是\(WebSailor\)和\(Tongyi DeepResearch\)模型,推动了开源模型原生深度研究智能体的发展。
与流水线系统相比,模型原生智能体展现出更强的长时程一致性、更深的探索能力和对多样化信息环境的适应性。但仍面临两大挑战:
- 开放网络中的信息噪音可能导致强化学习放大“幻觉”问题。
- 开放式研究任务的奖励模型难以定义,如何量化洞察力、批判性分析等主观质量标准仍是前沿问题。
图形界面智能体 (GUI Agent)
早期的GUI智能体多采用流水线方法,如\(AppAgent\)通过XML视图层次信息来编排LLM,\(Mobile-Agent\)则调用专门的感知工具(如OCR)来从截图中定位UI元素。这些系统通常将通用模型与专用工具配对,依赖外部工作流指导行为。
近期的趋势是开发模型原生的解决方案,将感知、规划、定位和执行内化为统一的策略。\(UI-TARS\)是早期的代表,通过在监督轨迹数据集上进行端到端训练来预测底层操作。\(GUI-Owl\)和\(OpenCUA\)则更进一步,通过强化学习完全内化GUI的规划与执行,使其超越模仿,获得更强的鲁棒性和适应性。
与流水线系统相比,模型原生范式使GUI智能体能够处理更复杂、灵活的任务。但其也面临独特挑战:
- 输入和输出是细粒度的底层操作(像素、控件、点击、滑动),微小的感知或定位错误都可能导致任务失败。
- GUI环境的动态性和非平稳性(如布局变化、弹窗)使得并行探索和强化学习变得困难,一次收集的轨迹可能很快失效。
算法驱动力
从流水线范式向模型原生范式转变的核心驱动力,是在LLM训练中应用大规模强化学习 (Reinforcement Learning, RL)。\(DeepSeek-R1\)的技术报告表明,通过端到端的RL,模型可以在没有昂贵、逐步监督的情况下,通过探索来获得核心智能体能力。
从SFT到RL
在RL成为焦点之前,监督微调 (Supervised Fine-Tuning, SFT) 是主要方法,即训练模型模仿一个真实的轨迹数据集。然而,对于认知和执行层面的智能体任务(如撰写研究报告),构建完整的轨迹数据成本极高。
RL通过将学习问题从“模仿如何做”转变为“探索哪些行为能成功”,优雅地绕过了对明确程序化监督的需求。模型通过与环境交互,根据奖励信号来学习一个能最大化累积期望奖励的策略 \($\pi\_{\theta}\)$。这使模型能发现人类标注数据中可能不存在的新颖、更优的策略,从被动模仿者转变为主动探索者。
面向LLM的强化学习
早期的RL方法(如PPO、DPO)主要用于RLHF,优化单轮、对齐人类偏好的行为。但这些方法依赖密集的步级监督,不适用于长时程、稀疏奖励的智能体任务。
为解决这些问题,一系列面向结果驱动的RL算法被提出。例如,组相对策略优化 (GRPO) 引入轻量级评估范式,提高了训练稳定性;解耦裁剪和动态采样策略优化 (DAPO) 则通过改进裁剪机制和采样策略,提升了在多轮交互中的性能。这些算法的进步最终形成了一个统一的训练方案:\($LLM+RL+Task\)$,即基础模型在特定任务环境中通过RL算法得到增强。
算法:面向LLM的强化学习
必要性:程序化数据的短缺
一个基础的LLM策略 \($\pi\_{\theta}(a \mid q)\)$ 直接将指令 \(q\) 映射到答案 \(a\),并未建模中间的程序化步骤。基于流水线的方法通过外部脚手架来引导模型生成程序化行为,但这种方式存在根本缺陷,凸显了使用RL将智能体能力内化的必要性。
流水线作为外部脚手架
以思维链(CoT)为例,它通过在提示中加入少量示例 \(E\) 来引导模型 \($\pi\_{\theta}\)$。当模型处理拼接后的提示 \($[E;q]\) 时,其生成后续推理链 \(R\) 和答案 \(a\) 的概率如下:
\[P(R,a \mid [E;q])=\prod_{t=1}^{T}P_{\theta}(r_{t} \mid [E;q],r_{<t})\cdot P_{\theta}(a \mid [E;q],r_{1:T})\]示例 \(E\) 的存在创造了一种强大的模式,使得模型倾向于模仿示例的结构生成推理链。因此,这个推理链不是模型内化的行为,而是被诱导产生的。
分布外 (Out-of-Distribution) 差距
这种对上下文模式匹配的依赖正是流水线范式脆弱的原因。模型并未学会推理步骤的逻辑有效性,只学会了它们在文本上是合理的。用于预训练的大规模自然语料库很少包含这种结构化的程序化数据。因此,由CoT提示所调用的条件分布 \($P\_{\theta}(R,a \mid [E;q])\)$ 对于模型来说通常是分布外 (Out-of-Distribution, OOD) 的。当测试查询与示例相似时,模型可能成功;但当面对OOD情况时,泛化能力很差,可能产生不连贯的推理和无根据的答案。
RL的必要性
为了弥合OOD差距并创造内化的能力,必须显式地优化模型参数 \($\theta\)$。从概率角度看,一个具备原生规划能力的模型应该首先推理,然后回答。这可以看作是在所有可能的推理轨迹 \(R\) 空间上对最终答案概率进行边缘化:
\[P(a \mid q)=\int_{R}P(R \mid q)P(a \mid R,q)dR\]要内化这个过程,模型必须学会对推理轨迹的策略 \($P(R \mid q)\)$ 和给定推理轨迹的答案生成 \($P(a \mid R,q)\)$ 进行建模。SFT是一种方法,但高质量的 \($(q,R,a)\)$ 三元组数据成本高昂。
RL通过允许策略 \($\pi\_{\theta}\)$ 在环境中探索完整的轨迹 \($\tau\)$,并基于结果驱动的奖励 \($\mathcal{R}(\tau)\)$ 更新参数,而无需完整的程序化监督。其优化目标为:
\[\theta^{*}=\arg\max_{\theta}\;\mathbb{E}_{\tau\sim\pi_{\theta}}\big[\mathcal{R}(\tau)\big]\]RL将学习从静态数据灌输转变为动态样本生成,从绝对真值拟合转变为相对价值学习,从而将模型从被动模仿者转变为主动探索者,为智能体能力的模型原生内化提供了根本机制。
可行性:经典RL vs. 面向LLM的RL
大规模预训练赋予LLM丰富的世界知识和结构化先验,这从根本上重塑了RL的应用方式。这些先验知识不仅提高了探索效率,还为不同任务提供了一个通用的接口。
探索效率:从随机搜索到先验引导的探索
经典RL中,智能体从一个随机策略开始,通过反复试错学习,这个过程样本效率极低。
相比之下,预训练的LLM已编码了大量事实和程序化知识,这构成了对状态和行为空间的强大先验。RL不再是从零开始,而是在一个由预训练权重中的世界知识 \($\mathcal{K}\)$ 锚定的结构化先验 \($\pi\_{\text{prior}}(a \mid s,\mathcal{K})\)$ 基础上进行探索。RL的目标变为:
\[\theta^{*}=\arg\max_{\theta}\;\mathbb{E}_{\tau\sim\pi_{\theta}(\tau\mid\mathcal{K})}\big[\mathcal{R}(\tau)\big]\]这可以看作是对知识条件下的策略进行微调,使其更好地对齐任务特定的奖励信号。这种先验引导的探索显著提升了样本效率,使模型能够在训练早期就发现有意义的轨迹。
跨任务泛化:通用的环境、行动和奖励接口
经典RL通常在狭隘、特定的环境中运行,策略与环境紧密耦合,难以泛化。
而面向LLM的RL则在一个开放的、以语言为媒介的环境中运行,RL元组的所有元素(状态、行动、奖励)都通过文本或符号Token表示:
- 状态 \(s_t\):不断演化的文本或多模态上下文。
- 行动 \(a_t\):生成的文本、工具调用或GUI操作,构成了一个通用的控制接口。
- 奖励 \(\mathcal{R}(\tau)\):可以灵活地以语义方式定义,如推理的成功、事实的正确性、用户偏好对齐等。
这种基于语言的表示,将原本针对特定领域的RL问题,转化为一个统一的、在语言空间中的序列建模任务。LLM充当了一个通用的世界模型和策略网络,允许单个模型通过RL在推理、编码、网页浏览等多种任务上进行学习和优化。这使得RL不再是为特定任务训练专门智能体的方法,而成为一种为通用LLM内化广泛智能体能力的通用机制。