Beyond Turn Limits: Training Deep Search Agents with Dynamic Context Window
-
ArXiv URL: http://arxiv.org/abs/2510.08276v1
-
作者: Qiaoyu Tang; Yaojie Lu; Xianpei Han; Zhenru Zhang; Le Yu; Shixuan Liu; Hao Xiang; Hongyu Lin; Bowen Yu; Pengbo Wang; 等13人
-
发布机构: Alibaba Group; Chinese Academy of Sciences; University of Chinese Academy of Sciences
TL;DR
本文提出了DeepMiner框架,通过构造高难度训练任务和设计动态上下文窗口策略,显著提升了大型语言模型在多轮长程交互中作为深度搜索智能体的推理与执行能力。
关键定义
- DeepMiner: 本文提出的一个新颖训练框架,旨在通过(1)生成高难度的训练任务和(2)引入动态上下文窗口管理机制,来激发和训练多轮长程交互智能体的深度推理能力。
- 逆向构建方法 (Reverse Construction Method): 本文设计的一种用于生成复杂但可验证的问答(QA)对的方法。该方法从真实的网页信息源出发,通过实体驱动的信息收集、跨多源信息的问题生成以及严格的多阶段过滤,确保训练数据的挑战性和可靠性。
- 动态上下文管理 / 滑动窗口策略 (Dynamic Context Management / Sliding Window Strategy): 一种为解决长程交互中上下文长度限制而设计的策略。它通过一个滑动窗口,选择性地将旧的工具调用(tool call)输出替换为占位符,同时完整保留智能体自身的思考链(assistant reasoning traces),从而在有限的上下文中支持更长的交互轮次。
相关工作
当前,通过可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)在单轮推理任务(如数学、编程)中已取得显著成功,使模型展现出自我检验、回溯等复杂认知行为。然而,将这种能力扩展到需要几十甚至上百轮交互的多轮长程任务(如深度研究)时,现有开源方法遇到了两大瓶颈:
- 训练数据难度不足:现有的问答数据集(如HotpotQA)大多基于结构化的维基百科,任务模式相对简单,模型可以通过浅层信息检索轻易完成,无法激发其进行深度探索、验证和策略规划等高级认知能力。
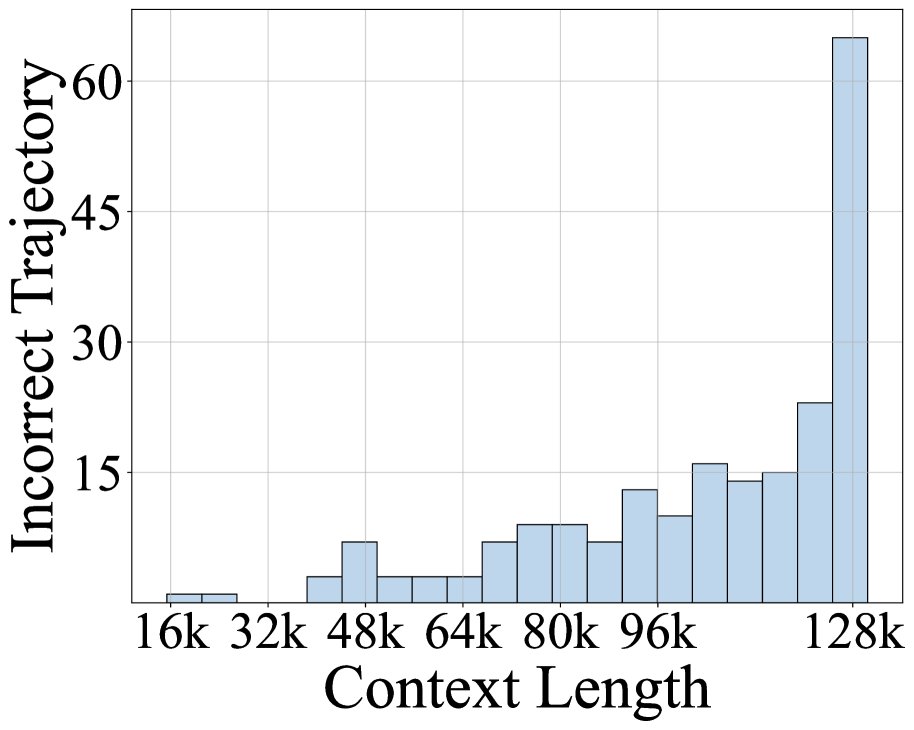
- 上下文长度限制:在多轮交互中,工具返回的大量文本会迅速占满模型的上下文窗口(例如32k的上下文仅能支持约10-15轮交互)。当前主流的解决方案是依赖外部模型对工具输出进行摘要,但这不仅会丢失关键的细粒度信息,还增加了系统复杂性,且无法被端到端的强化学习过程优化。
本文旨在解决上述两个问题,即如何通过构建真正具有挑战性的训练数据和设计高效的上下文管理策略,来训练能够在长程交互中执行深度推理的搜索智能体。
本文方法
本文提出了DeepMiner框架,其核心由两部分构成:复杂问题的逆向构建方法和带动态上下文窗口的强化学习策略。
复杂问题构建
为了生成能激发模型深度推理能力的训练任务,本文设计了一个三阶段的逆向构建流程:
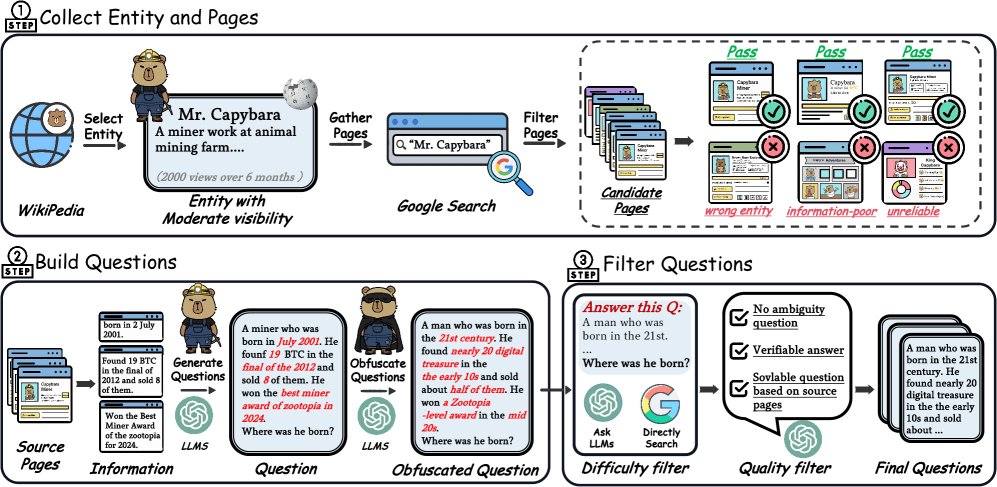
- 实体驱动的信息收集:首先从维基百科中选择中等知名度的实体,以确保信息足够丰富但又未被模型固化为参数知识。然后通过搜索引擎收集与该实体相关的网页,并进行三轮筛选:验证网页与实体的对应关系、评估信息是否具有互补性、过滤掉不可靠信源。
- 问题生成:利用大语言模型,基于筛选后的多个真实网页(至少4个,且刻意排除维基百科)生成问题。这一过程强制模型必须综合多个分散的信息源才能回答。为了进一步增加难度,生成的问题还会经过二次“模糊化”处理,例如将具体细节替换为更概括性的描述,迫使智能体在解决问题时需要进行更复杂的推理和信息整合。
- 多阶段过滤:对生成的QA对进行严格的难度和质量过滤。难度过滤确保问题无法通过简单的搜索引擎查询或对模型的零样本提问直接解决。质量过滤则排除那些存在表述歧义、答案模棱两可或答案无法从给定证据中逻辑推导的问题,保证了训练信号的可靠性。
带动态上下文窗口的强化学习
动态上下文管理策略
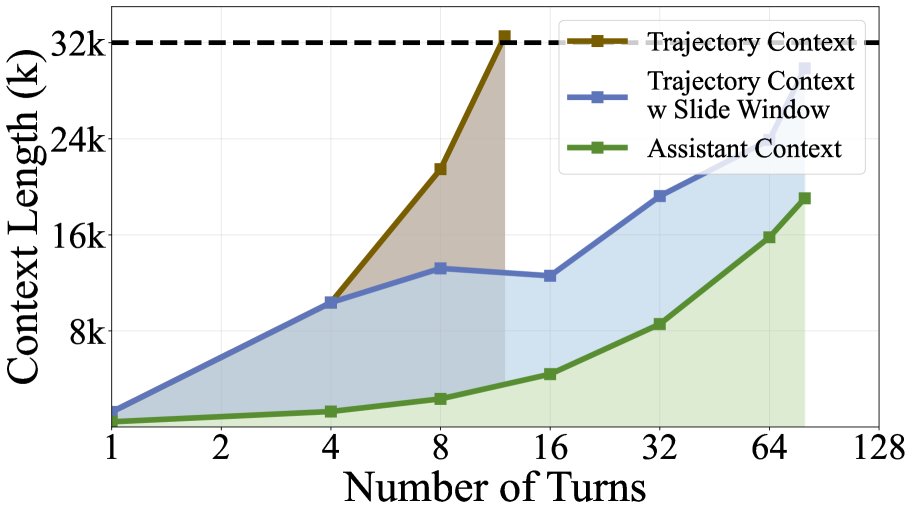
对现有模型在复杂任务上的失败案例分析表明,上下文耗尽是导致交互提前终止的主要原因。通常,工具返回的内容长度远超智能体的思考过程,导致上下文被迅速填满。
基于此,本文设计了一种动态上下文管理策略,其核心是滑动窗口机制 (Sliding Window Mechanism):
- 创新点:该机制的核心思想是“丢工具、保思考”。在一个交互轨迹 $\tau={q, a_1, t_1, \ldots, a_T}$ 中($a_i$ 为智能体思考, $t_i$ 为工具输出),当工具输出的数量达到窗口大小 $\mathcal{W}$ 时,系统会将最早的几个工具输出 $t_i$ 替换为一个占位符(如 \([Previous tool output skipped. Re-run tool if needed.]\)),但完整保留所有的智能体思考过程 $a_i$。
- 优点:这种设计既保留了指导策略规划的完整思考链,又通过压缩旧的、对当前决策影响较小的工具输出来大幅节省上下文空间,使得模型在32k的上下文中也能支持近100轮的交互。同时,它避免了外部摘要模型带来的信息损失和优化盲点。
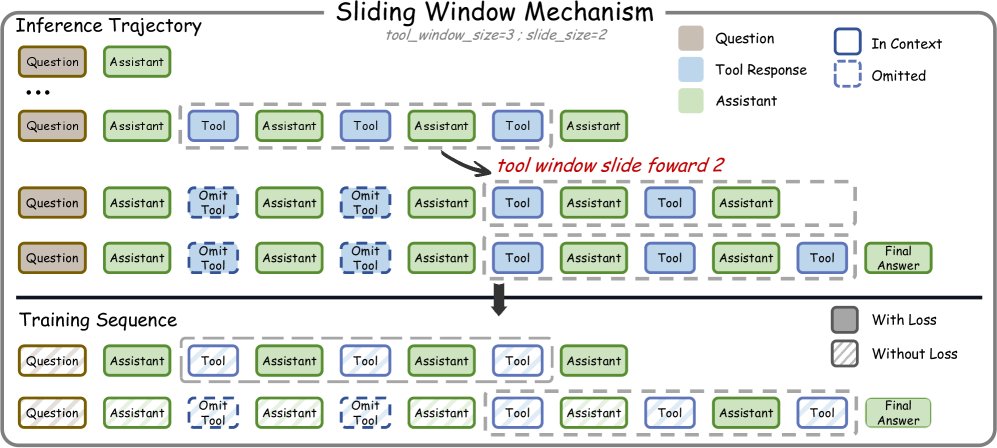
训练-测试一致性
为了让模型适应推理时动态变化的上下文,本文在训练时对每个长轨迹进行分解。一个包含 $T$ 次工具调用的轨迹会被分解成多个训练序列。每个序列模拟了滑动窗口在不同阶段的状态,即部分早期的工具输出被替换为占位符。通过掩码(masking)机制确保每个智能体的思考输出在所有序列中只被训练一次,从而实现训练与测试行为的一致性。
\[\mathcal{M}^{(k)}_{i}=\begin{cases}0&\text{if }i<\mathcal{W}+(k-2)\cdot\mathcal{S}+2\\ 1&\text{otherwise}\end{cases}\]训练流程
- 冷启动 (Cold Start):首先通过监督微调(SFT)进行冷启动。利用强大的语言模型生成高质量的工具调用轨迹(同样应用滑动窗口机制以支持长程生成),并筛选出其中的成功案例,用于初步训练模型,使其具备基础的工具使用和长程推理能力。
-
强化学习训练 (Reinforcement Learning Training):采用GRPO(Group Relative Policy Optimization)算法进行强化学习。在训练时,对每个问题生成 $G$ 个完整的交互轨迹。奖励是二元的(答案正确为1,错误为0)。轨迹级别的优势(advantage)计算如下:
\[\hat{A}_i = \frac{1}{ \mid \mathcal{G} \mid } \sum_{j \in \mathcal{G}} (\mathbb{I}[r_i > r_j] - \mathbb{I}[r_i < r_j])\]本文的核心改动在于优势传播:计算出的轨迹级别优势 $\hat{A}_i$ 会被传播到由该轨迹分解出的所有训练序列上。这保证了即使在动态变化的上下文序列中进行训练,策略学习的信号仍然是一致和有效的。
实验结论
主要结果
本文基于Qwen3-32B模型训练了DeepMiner-32B,并在多个深度研究基准上进行了评测。
| 模型 | BrowseComp-en | BrowseComp-zh | XBench-DeepSearch | GAIA |
|---|---|---|---|---|
| 开源智能体 | ||||
| Webshaper-34B | 13.9 | 15.6 | 17.5 | 18.0 |
| ASearcher-7B | 12.1 | 14.2 | 16.5 | 16.8 |
| WebDancer-8B | 12.8 | - | 19.3 | - |
| WebSailor-7B | 11.2 | - | 16.2 | 14.1 |
| 通用模型 | ||||
| DeepSeek-V3.1-671B | 31.7 | - | 34.0 | - |
| 本文模型 | ||||
| DeepMiner-32B (SFT) | 21.2 | 23.3 | 29.5 | 27.6 |
| DeepMiner-32B (RL) | 33.5 | 35.4 | 38.5 | 31.9 |
- 性能大幅提升:DeepMiner-32B在所有基准上均显著超越了此前的开源智能体。特别是在最具挑战性的BrowseComp-en上,其33.5%的准确率比之前的最佳开源方法高出近20个百分点,甚至超过了体量大20倍的DeepSeek-V3.1-671B。
- RL阶段效果显著:从SFT到RL的训练阶段,模型性能在所有基准上都获得了巨大提升(例如在BrowseComp-en上提升了12.3个百分点),证明了本文的强化学习框架能有效增强模型的深度推理和策略规划能力。
效率与分析
上下文管理效率 比较了三种上下文管理策略的效率。本文的滑动窗口方法在仅使用32k上下文的情况下,性能(33.3%)就超过了其他方法使用128k上下文时的表现,同时支持的交互轮次接近100轮,远超其他方法。
| 策略 | 上下文效率 | 附加模型 | 信息损失 | 端到端优化 | 最大轮次 (32k) | 性能 (BrowseComp) |
|---|---|---|---|---|---|---|
| Vanilla | 低 | 否 | 无 | 是 | ~15 | 29.2% (128k) |
| 外部摘要 | 中 | 是 | 高 | 否 | ~30 | 31.7% (128k) |
| DeepMiner (滑动窗口) | 高 | 否 | 低 | 是 | ~100 | 33.3% (32k) |
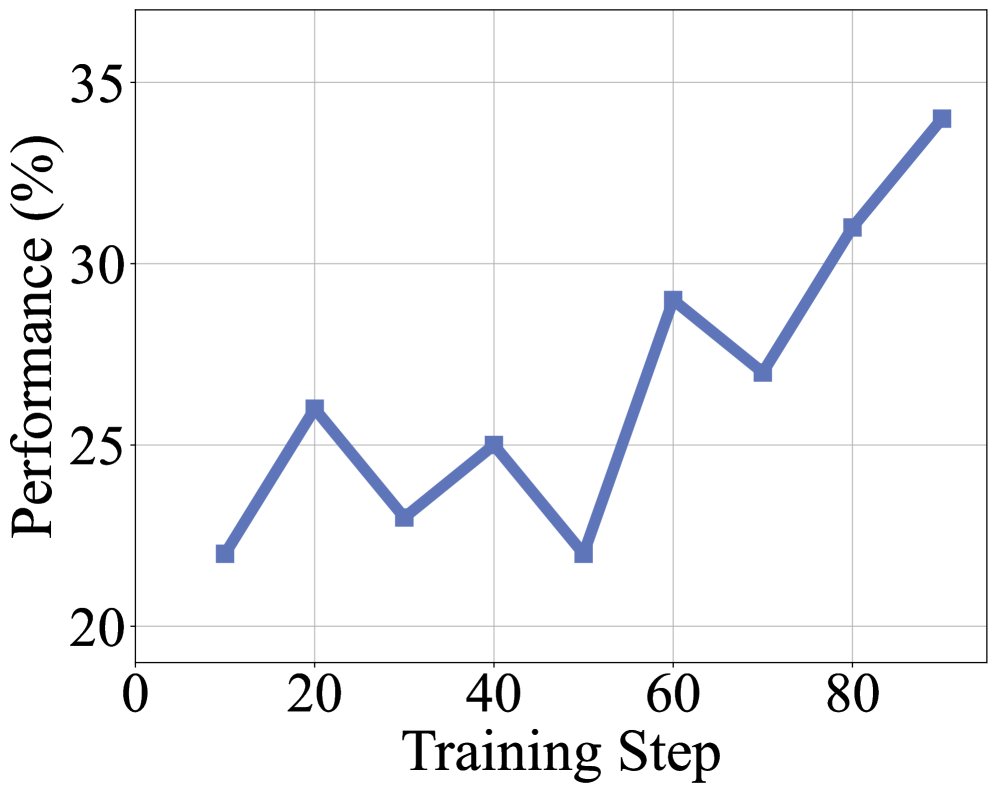
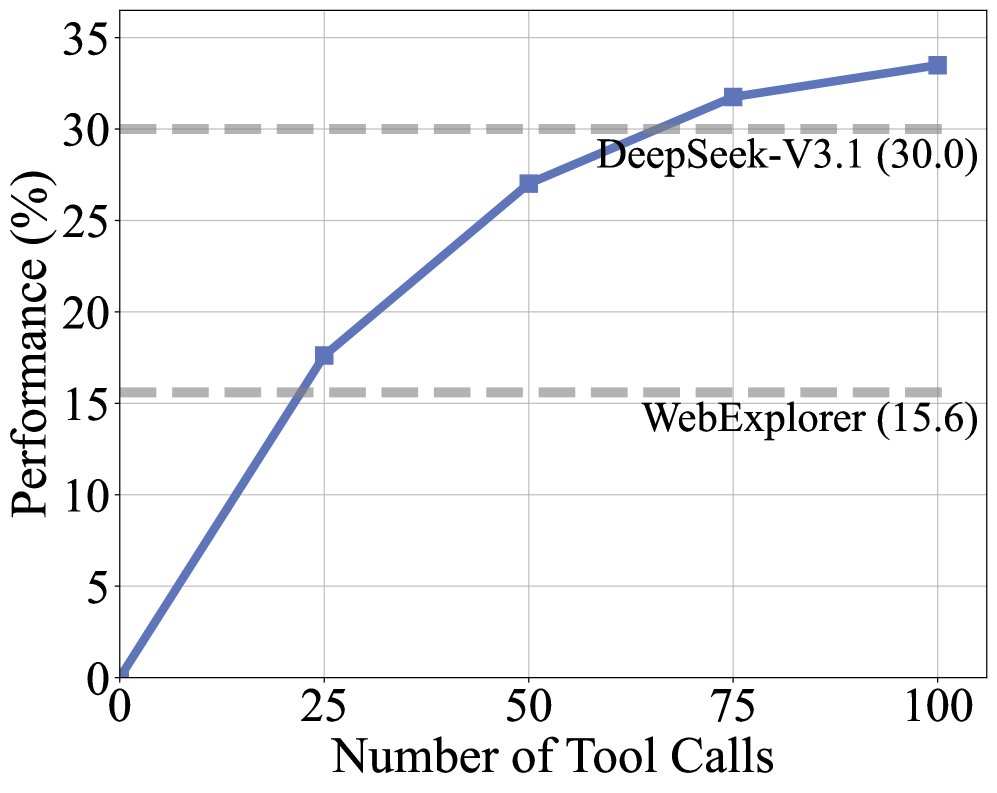
训练动态与上下文扩展 训练过程中的奖励和轨迹长度稳步增长,表明模型在持续学习解决本文构造的复杂任务。性能随着工具调用预算的增加而提升,在60次调用后即超越了强大的基线模型。此外,即使在32k的有限上下文中,DeepMiner也能取得接近饱和的性能,展示了其上下文管理策略的高效性。
数据效率 为了验证本文数据构建方法的有效性,实验比较了使用本文数据和常用数据集HotpotQA进行SFT训练的效果。
| 训练数据 | BrowseComp 性能 |
|---|---|
| HotpotQA-SFT | 15.6% |
| DeepMiner-SFT | 21.2% |
结果显示,使用DeepMiner数据训练的模型性能远超使用HotpotQA训练的模型,证明了本文构造的高难度数据对于激发复杂网页智能体认知能力是必要且有效的。
最终结论:本文证明了通过高质量、高难度的训练数据与高效的动态上下文管理策略相结合,可以有效解锁大型语言模型在多轮长程交互中的深度推理潜力,是开发下一代深度研究智能体的关键路径。