BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
-
ArXiv URL: http://arxiv.org/abs/2402.03216v4
-
作者: Zheng Liu; Shitao Xiao; Kun Luo; Jianlv Chen; Defu Lian; Peitian Zhang
-
发布机构: BAAI; University of Science and Technology of China
TL;DR
本文提出了一种名为 M3-Embedding 的通用文本嵌入模型,它通过新颖的自知识蒸馏(Self-Knowledge Distillation)训练框架,在单一模型中同时实现了多语言(Multi-Lingual)、多功能(Multi-Functionality)和多粒度(Multi-Granularity)的卓越能力。
关键定义
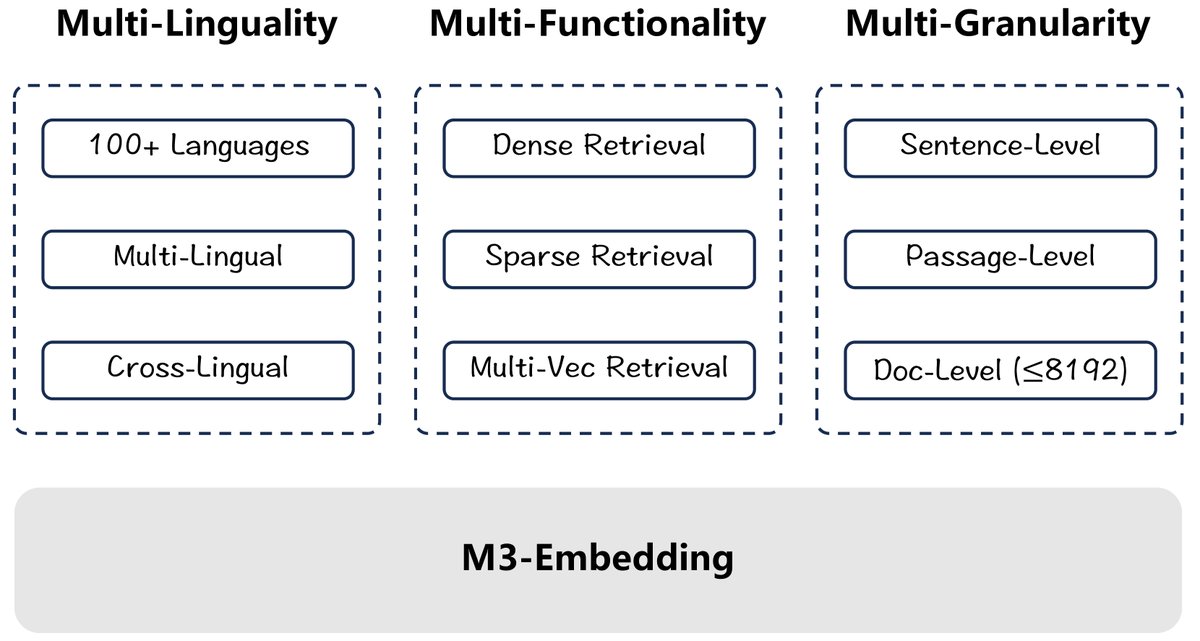
本文的核心是围绕一个统一的嵌入模型 M3-Embedding 展开的,该模型具备以下关键特性:
- 多功能性 (Multi-Functionality):模型能够同时支持三种主流的检索范式:
- 密集检索 (Dense Retrieval):使用 \([CLS]\) token的归一化嵌入向量来表示整个文本,通过向量内积计算相似度。
- 词汇检索 (Lexical Retrieval / Sparse Retrieval):通过一个可学习的映射矩阵,为文本中的每个token(词项)学习一个权重,并基于共享词项的权重乘积之和来计算相关性得分,类似于传统的稀疏检索。
- 多向量检索 (Multi-Vector Retrieval):将文本中的所有token嵌入向量作为一个集合来表示文本,通过计算两个文本嵌入集合之间的“词-词”最大相似度的均值(Late-Interaction)来得到最终相关性得分。
-
自知识蒸馏 (Self-Knowledge Distillation):本文提出的核心训练技术。它将来自上述三种不同检索功能(密集、词汇、多向量)的相关性得分进行集成(加权求和),形成一个更强大的“教师”信号。然后,这个集成后的教师信号被用来指导(通过KL散度损失)各个独立检索功能的学习过程,从而使不同功能之间相互促进、协同优化,解决了多任务学习中的潜在冲突。
- 多粒度 (Multi-Granularity):模型能够处理从短句到长达8192个token的长文档,这得益于高效的批处理策略和专门针对长文档的训练数据。
相关工作
当前的文本嵌入模型虽然取得了巨大进展,但普遍存在以下局限性:
- 语言单一:大多数高质量的嵌入模型主要针对英语设计,缺乏对其他语言的有效支持。
- 功能单一:现有模型通常只为一种特定的检索功能(如密集检索)进行优化,而一个完整的IR系统往往需要多种检索方法的协同工作。
- 粒度受限:由于训练成本和模型架构的限制,绝大多数嵌入模型仅能处理较短的文本输入(如512个token),在长文档检索场景下表现不佳。
本文旨在解决这些问题,提出一个具备前所未有的通用性的嵌入模型,能够在一个统一的框架内同时支持超过100种语言、三种核心检索功能以及从短句到8192 token的长文本处理。
本文方法
M3-Embedding 的实现依赖于精细的数据管理、创新的训练框架和高效的训练策略。
数据管理
高质量的训练数据是模型通用性的基石。本文从三个方面构建了一个大规模、多样化的多语言数据集:
- 无监督数据:从维基百科、S2ORC、mC4等海量多语言语料库中,提取具有强语义关系的文本对,如“标题-正文”、“标题-摘要”、“指令-输出”等。同时,引入NLLB和CCMatrix等翻译数据集中的平行句对,以构建跨语言的统一语义空间。总计包含194种语言的12亿个文本对。
- 有监督数据:整合了来自英语和汉语的多个高质量标注数据集(如HotpotQA, MS MARCO, DuReader等),以及来自Mr. Tydi和MIRACL的多语言训练数据,用于模型微调。
- 合成数据:为解决长文档检索和多语言微调数据稀缺的问题,利用GPT-3.5为从维基百科、悟道、mC4等语料中抽取的长文章生成对应的问题,构建了名为MultiLongDoc的合成数据集。
混合检索架构
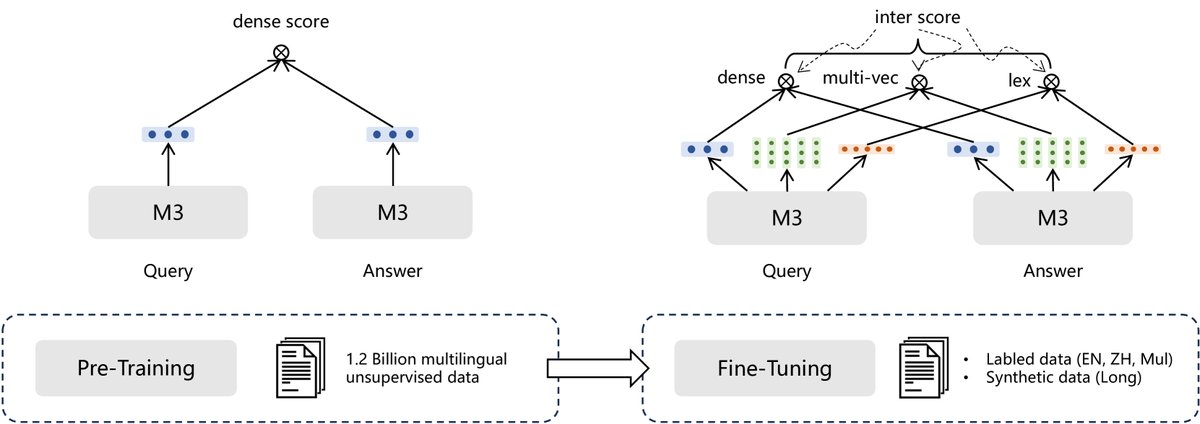
M3-Embedding通过其编码器的输出,巧妙地统一了三种检索功能:
- 密集检索:使用 \([CLS]\) token的隐藏状态 \(H[0]\) 作为文本的全局表示,其相关性得分为:$s_{dense} \leftarrow \langle norm(\mathbf{H}_{p}[0]), norm(\mathbf{H}_{q}[0]) \rangle$。
- 词汇检索:对于每个token \(t\) 的隐藏状态 \(H[i]\),通过一个线性层 \(W_lex\) 和ReLU激活函数计算其权重 $w_{t} \leftarrow \mathsf{Relu}(\mathbf{W}_{lex}^{T}\mathbf{H}[i]))$。两个文本的相关性得分由它们交集词项的权重乘积之和计算:$s_{lex} \leftarrow \sum_{t\in q\cap p}(w_{q_{t}} \cdot w_{p_{t}})$。
- 多向量检索:使用一个投影矩阵 \(W_mul\) 转换所有token的隐藏状态,并采用类似ColBERT的后期交互(late-interaction)方式计算得分:$s_{mul} \leftarrow\frac{1}{N}\sum_{i=1}^{N}\max_{j=1}^{M}E_{q}[i]\cdot E_{p}^{T}[j]$。
这三种方法可以独立使用,也可以通过加权求和的方式进行混合(Hybrid)检索,以实现更好的重排序效果:
\[s_{rank} \leftarrow w_{1}\cdot s_{dense}+w_{2}\cdot s_{lex}+w_{3}\cdot s_{mul}\]自知识蒸馏与多阶段训练
这是本文最核心的训练创新。为了解决多种检索目标可能相互冲突的问题,本文设计了一个自知识蒸馏框架。
-
教师信号的构建:将三种检索方法看作一个集成系统,它们的得分加权组合成一个更精确的集成得分(教师信号):
\[s_{inter} \leftarrow w_{1}\cdot s_{dense}+w_{2}\cdot s_{lex}+w_{3}\cdot s_{mul}\] -
知识蒸馏:将集成得分 \(s_inter\) 作为教师模型的软标签,指导各个学生模型(即每种单一的检索方法)的学习。标准的InfoNCE损失函数被修改为基于KL散度的蒸馏损失,例如对于密集检索:
\[\mathcal{L}^{\prime}_{dense} \leftarrow -p(s_{inter}) \cdot \log p(s_{dense})\]其中,$p(\cdot)$ 是Softmax函数。
-
最终损失:总损失由两部分组成:一部分是每个检索方法以及集成得分自身的InfoNCE损失之和 \(L\),另一部分是蒸馏损失之和 \(L'\)。最终损失为 $\mathcal{L}_{final} \leftarrow (\mathcal{L}+\mathcal{L}^{\prime})/2$。
训练流程分为多个阶段:
- 阶段一(预训练):使用大规模无监督数据,通过基本的对比学习训练密集检索功能。模型骨干是基于RetroMAE改进的XLM-RoBERTa。
- 阶段二(微调):在有监督和合成数据上,应用自知识蒸馏框架,联合训练密集、词汇和多向量三种检索功能。
高效批处理
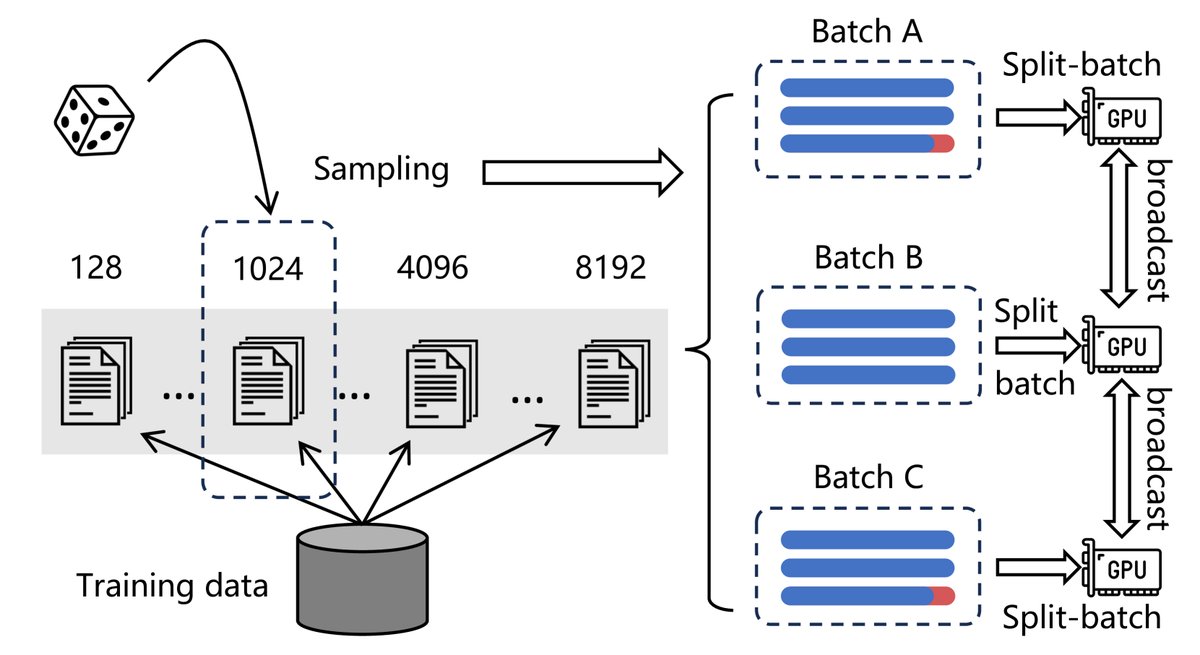
为了在处理长序列(最高8192 token)的同时保持大批量(large batch size)和高吞吐量,本文采用了多项优化策略:
- 按长度分组:将训练数据按序列长度分组,在同一批次内采样长度相近的样本,大幅减少了填充(padding)开销。
- 梯度检查点 (Gradient Checkpointing):在处理长序列时,通过将一个mini-batch拆分为多个sub-batch并迭代编码,显著降低了显存占用,从而允许更大的有效批量。
- 跨GPU广播:在分布式训练中,将所有GPU上的嵌入向量广播给每个设备,极大地扩展了批内负样本(in-batch negatives)的数量,增强了模型的判别能力。
此外,本文还提出了一个简单的推理时策略MCLS (Multi-CLS),即在长文档中插入多个CLS token,并取其嵌入向量的平均值作为最终表示,这在没有资源进行长文档微调时也能有效提升性能。
实验结论
实验结果全面验证了M3-Embedding在多语言、多功能和多粒度上的优越性。
- 多语言检索 (MIRACL):M3-Embedding仅用密集检索就在18种语言上超越了mE5-large、E5-mistral-7b等强大的基线模型。其稀疏检索功能也优于BM25。多种功能的混合使用(Dense+Sparse, All)带来了进一步的性能提升,取得了SOTA结果。
| 模型 | 平均 | ar | bn | en | es | fa | fi | fr | hi | id | ja | ko | ru | sw | te | th | zh | de | yo |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 基线 (先前工作) | |||||||||||||||||||
| mE5 large | 66.6 | 76.0 | 75.9 | 52.9 | 52.9 | 59.0 | 77.8 | 54.5 | 62.0 | 52.9 | 70.6 | 66.5 | 67.4 | 74.9 | 84.6 | 80.2 | 56.0 | 56.4 | 78.3 |
| E5 mistral-7b$ | 63.4 | 73.3 | 70.3 | 57.3 | 52.2 | 52.1 | 74.7 | 55.2 | 52.1 | 52.7 | 66.8 | 61.8 | 67.7 | 68.4 | 73.9 | 74.0 | 54.0 | 54.1 | 79.7 |
| OpenAI-3 | 54.9 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| M3-Embedding (本文工作) | |||||||||||||||||||
| Dense | 69.2 | 78.4 | 80.0 | 56.9 | 56.1 | 60.9 | 78.6 | 58.3 | 59.5 | 56.1 | 72.8 | 69.9 | 70.1 | 78.7 | 86.2 | 82.6 | 62.7 | 56.7 | 81.8 |
| Sparse | 53.9 | 67.1 | 68.9 | 43.8 | 38.6 | 45.1 | 65.4 | 35.3 | 48.2 | 48.9 | 56.1 | 61.5 | 44.5 | 57.9 | 79.1 | 70.9 | 36.1 | 32.5 | 70.0 |
| Multi-vec | 70.5 | 79.6 | 81.0 | 59.3 | 57.8 | 62.0 | 80.1 | 59.4 | 61.5 | 58.3 | 74.5 | 71.2 | 71.2 | 79.1 | 87.9 | 83.0 | 63.7 | 58.0 | 82.4 |
| Dense+Sparse | 70.4 | 79.6 | 80.7 | 58.8 | 58.1 | 62.3 | 79.7 | 58.0 | 62.9 | 58.3 | 73.9 | 71.2 | 69.8 | 78.5 | 87.2 | 83.1 | 63.5 | 57.7 | 83.3 |
| All | 71.5 | 80.2 | 81.5 | 59.6 | 59.7 | 63.4 | 80.4 | 61.2 | 63.3 | 59.0 | 75.2 | 72.1 | 71.7 | 79.6 | 88.1 | 83.7 | 64.9 | 59.8 | 83.5 |
-
跨语言检索 (MKQA):在用25种非英语查询检索英语文档的任务上,M3-Embedding同样展现了SOTA性能,尤其在低资源语言上优势明显,表现出更好的鲁棒性。
-
长文档检索 (MLDR & NarrativeQA):在长文档场景下,M3-Embedding的稀疏检索和多向量检索功能表现尤为出色,大幅超越了密集检索和其他基线模型。混合所有功能后,取得了65.0 (MLDR) 和 61.7 (NarrativeQA) 的nDCG@10得分,远超之前的SOTA方法。
| 模型 | MLDR nDCG@10 (Avg) | NarrativeQA nDCG@10 |
|---|---|---|
| E5${}_{\mathrm{\text{mistral-7b}}}$ | 42.6 | 49.9 |
| text-embedding-3-large | - | 51.6 |
| M3-Embedding Dense | 52.5 | 48.7 |
| M3-Embedding Sparse | 62.2 | 57.5 |
| M3-Embedding All | 65.0 | 61.7 |
- 消融实验:
- 移除自知识蒸馏(skd)后,模型所有功能的性能均出现下降,尤其是稀疏检索性能大幅降低(MIRACL上从53.9降至36.7),证明了skd在协调多任务学习、缓解冲突方面的关键作用。
- 逐步引入RetroMAE预训练和无监督数据预训练,模型性能持续提升,验证了多阶段训练策略的有效性。
最终结论:本文成功地通过自知识蒸馏和高效训练策略,打造了一款高度通用的M3-Embedding模型。该模型在多语言、多功能和多粒度方面均展现出当前最先进的水平,为各种复杂的实际检索应用提供了强大而统一的解决方案。