BloombergGPT: A Large Language Model for Finance
-
ArXiv URL: http://arxiv.org/abs/2303.17564v3
-
作者: Steven Lu; Sebastian Gehrmann; Vadim Dabravolski; Ozan Irsoy; Shijie Wu; Mark Dredze; D. Rosenberg; Gideon Mann; P. Kambadur
-
发布机构: Bloomberg; Johns Hopkins University
TL;DR
本文提出了一种为金融领域专门打造的500亿参数大型语言模型——BloombergGPT,它通过在一个包含大量高质量金融数据和通用数据的混合数据集上进行训练,在金融领域的任务上取得了远超现有模型的性能,同时在通用LLM基准测试中保持了强大的竞争力。
关键定义
- BloombergGPT: 一个拥有500亿参数的、仅解码器 (decoder-only) 的因果语言模型。它的独特之处在于其训练数据同时包含了大规模的金融领域专属数据和通用的公开数据集,旨在同时优化领域特异性和通用能力。
- FinPile: 本文构建的一个大规模、领域专属的金融文本数据集,包含3630亿个Token。该数据集来源于彭博社四十年来积累的金融数据档案,包括公司财报、金融新闻、新闻稿、网络金融文件和社交媒体等,是迄今为止最大的领域专属数据集之一。
- 混合数据训练 (Mixed Data Training): 本文采用的核心训练策略。与完全依赖通用数据或完全依赖领域数据的模型不同,该方法将大约一半的训练数据(FinPile)用于金融领域,另一半(如The Pile, C4)用于通用领域。这种策略旨在使模型既能掌握金融领域的专业知识和术语,又不会丧失处理通用任务的泛化能力。
相关工作
当前的大型语言模型(LLMs)主要分为两类。一类是像GPT-3、PaLM这样在通用、广泛的主题上训练的超大规模模型,它们展现了强大的泛化能力和涌现能力(如少样本学习),但对特定领域的理解不够深入。另一类是专注于特定领域(如科学、医疗)的模型,它们在领域内任务上表现优于通用模型,但通常规模较小,且完全使用领域数据训练,可能牺牲了通用性。
金融科技(FinTech)领域存在大量复杂的自然语言处理任务,如情绪分析、命名实体识别和问答,其专业术语和上下文复杂性对模型提出了很高要求。然而,在本文提出之前,尚没有专门为金融领域设计和优化的LLM。
本文旨在解决的问题是:如何构建一个既能在复杂的金融任务上达到顶尖水平,又能保持在通用LLM基准上具有竞争力的模型,以满足金融行业对高精度、专业化和多功能性的双重需求。
本文方法
核心思想:混合数据训练
BloombergGPT的核心创新在于其训练策略。作者没有采取在通用模型上进行微调,或者完全从零开始训练一个纯金融模型的路线,而是开创性地采用了一种混合数据训练方法。他们构建了一个超过7000亿Token的庞大训练语料库,其中约51%是高质量、精心策划的金融领域数据(FinPile),约49%是通用的公开数据集。这种设计背后的假设是,领域数据可以赋予模型深度专业知识,而通用数据则确保其广泛的语言理解和推理能力,从而实现“专才”与“通才”的结合。
训练数据:FinPile与公共数据集
训练数据的构建是本文的关键贡献之一。整个数据集包含超过7000亿个Token,在去重后用于训练。
| 数据集 | 文件数 (1e4) | 平均字符数/文件 (1e4) | 字符数 (1e8) | 平均字符数/Token | Token数 (1e8) | Token占比 |
|---|---|---|---|---|---|---|
| FinPile | 175,886 | 1,017 | 17,883 | 4.92 | 3,635 | 51.27% |
| Web | 158,250 | 933 | 14,768 | 4.96 | 2,978 | 42.01% |
| News | 10,040 | 1,665 | 1,672 | 4.44 | 376 | 5.31% |
| Filings | 3,335 | 2,340 | 780 | 5.39 | 145 | 2.04% |
| Press | 1,265 | 3,443 | 435 | 5.06 | 86 | 1.21% |
| Bloomberg | 2,996 | 758 | 227 | 4.60 | 49 | 0.70% |
| PUBLIC | 50,744 | 3,314 | 16,818 | 4.87 | 3,454 | 48.73% |
| C4 | 34,832 | 2,206 | 7,683 | 5.56 | 1,381 | 19.48% |
| Pile-CC | 5,255 | 4,401 | 2,312 | 5.42 | 427 | 6.02% |
| GitHub | 1,428 | 5,364 | 766 | 3.38 | 227 | 3.20% |
| … | … | … | … | … | … | … |
| TOTAL | 226,631 | 1,531 | 34,701 | 4.89 | 7,089 | 100.00% |
表1:BloombergGPT完整训练集构成概览。(表格中省略了部分公共数据集的细项)
金融数据集 (FinPile, 3630亿 Tokens)
FinPile是本文构建的金融专属数据集,其数据源自彭博过去四十年积累的文档,时间跨度为2007年至2022年。
- Web (2980亿 Tokens):来自彭博爬取的包含金融相关信息的高质量网站内容。
- News (380亿 Tokens):来自数百个除彭博自产新闻外的信誉良好的金融新闻源。
- Filings (140亿 Tokens):主要来自美国证券交易委员会(SEC)的EDGAR数据库的公司财报(如10-K、10-Q),这些文件信息密集,格式特殊。
- Press (90亿 Tokens):公司发布的与财务相关的官方新闻稿。
- Bloomberg (50亿 Tokens):彭博社自己撰写的深度分析和实时新闻等。
| 日期 | Bloomberg | Filings | News | Press | Web | 总计 |
|---|---|---|---|---|---|---|
| 2007 [03-] | 276 | 73 | 892 | 523 | 2,667 | 4,431 |
| 2008 | 351 | 91 | 1,621 | 628 | 9,003 | 11,695 |
| … | … | … | … | … | … | … |
| 2022 [-07] | 140 | 882 | 2,206 | 531 | 16,872 | 20,631 |
| 总计 | 4,939 | 14,486 | 37,647 | 8,602 | 297,807 | 363,482 |
表2:FinPile数据集按年份和类型的Token数量(百万)分布。
公共数据集 (3450亿 Tokens)
为了保证模型的通用能力,训练数据还包括了三个广泛使用的公共数据集:
- The Pile (1840亿 Tokens): 一个多样化的开源数据集,涵盖学术、代码(GitHub)、法律(FreeLaw)等多个领域,有助于提高模型的泛化能力。
- C4 (1380亿 Tokens): 一个经过大量清洗的通用网络爬取语料库。
- Wikipedia (240亿 Tokens): 包含2022年7月的英文维基百科快照,为模型提供更新的、事实性的知识。
Tokenization
本文没有采用常见的BPE等算法,而是选择了Unigram Tokenizer。这种分词器基于概率模型,允许在推理时进行更智能、更灵活的Tokenization。为了处理海量的The Pile数据集,作者采用了分而治之的并行训练策略:将数据集的各部分分割成数千个小块,在每个小块上训练一个独立的Unigram模型,然后层级式地将这些模型合并,最终得到一个拥有约13万($2^{17}$)词汇量的Tokenizer。这个较大的词汇表有助于提高信息密度,减少序列长度。
| BLOOM | /ours | NeoX | /ours | OPT | /ours | BloombergGPT | |
|---|---|---|---|---|---|---|---|
| FinPile (旧版) | 451 | 110% | 460 | 112% | 456 | 111% | 412 |
| C4 | 166 | 121% | 170 | 123% | 170 | 123% | 138 |
| The Pile | 203 | 110% | 214 | 116% | 239 | 130% | 184 |
| Wikipedia | 21 | 88% | 23 | 99% | 24 | 103% | 24 |
| 总计 | 390 | 113% | 408 | 118% | 434 | 126% | 345 |
表3: 使用不同分词器对各训练数据集进行分词后的Token数量(十亿)对比。BloombergGPT的分词器在多数情况下更高效(Token数更少)。
模型架构与规模
架构
BloombergGPT是一个基于BLOOM架构的仅解码器(decoder-only)因果语言模型。其核心结构为70层的Transformer解码器模块。
\[\bar{h}_{\ell} =h_{\ell-1}+\mathop{\mathrm{SA}}\nolimits(\mathop{\mathrm{LN}}\nolimits(h_{\ell-1}))\] \[h_{\ell} =\bar{h}_{\ell}+\mathop{\mathrm{FFN}}\nolimits(\mathop{\mathrm{LN}}\nolimits(\bar{h}_{\ell}))\]关键特性包括:
- ALiBi 位置编码:通过在自注意力模块中添加偏置来实现位置编码,使其能外推到比训练序列更长的文本。
- 额外层归一化 (Layer Normalization):在词嵌入层之后增加了一个额外的LN层,以增强训练稳定性。
- 参数共享:输入词嵌入与最终输出前的线性映射层共享权重。
模型规模
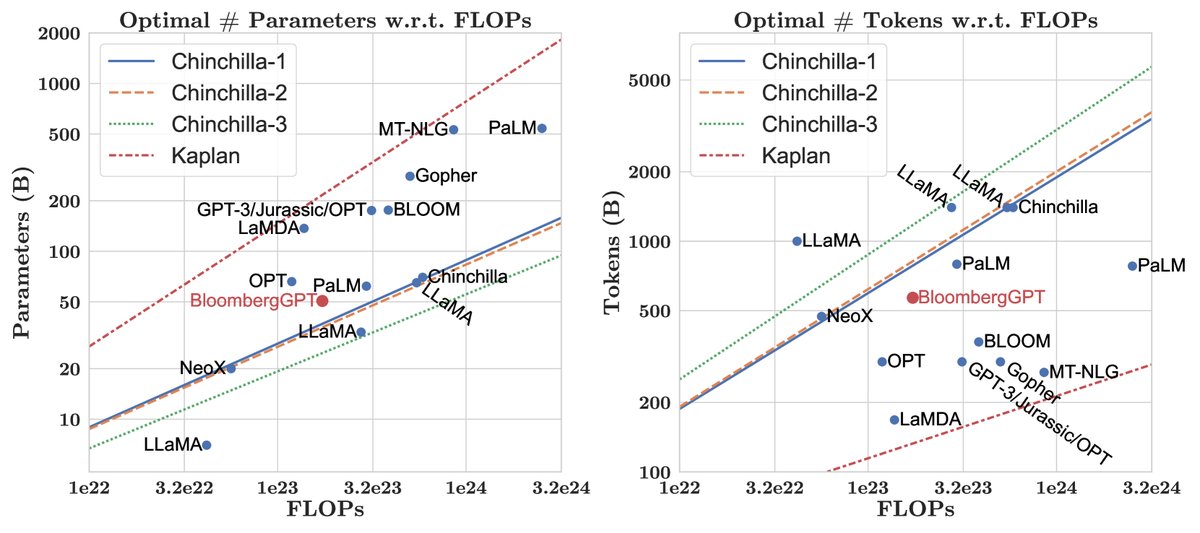
图1:与现有大型语言模型相比,BloombergGPT在模型参数和数据规模上的定位,参考了Chinchilla缩放定律。
模型的500亿参数量是根据Chinchilla缩放定律和可用的计算预算(约130万A100 GPU小时)精心选择的。考虑到金融领域数据(FinPile)的量是有限的(约3630亿Token),并且作者不希望其占比低于总数据的一半,因此无法无限增加数据量来匹配“Chinchilla最优”的更小模型尺寸。最终,选择500亿参数是在数据量受限的情况下,对计算资源的最优利用。
模型形态
模型的具体“形状”(层数、隐藏层维度等)也经过了优化。根据 \(Levine et al. (2020)\) 的研究,对于给定的层数 \(L\),最优的隐藏层维度 \(D\) 可以通过公式 $D = \exp(5.039)\exp(0.0555 \cdot L)$ 估算。通过在多个 \((L, D)\) 组合中寻找最接近500亿参数的配置,并考虑Tensor Core硬件加速对维度(需为8的倍数)的要求,最终确定了以下配置:
- 层数: 70
- 注意力头数: 40
- 隐藏层维度: 7680
- 总参数量: 506亿
| 形态 (Shape) | |
| 层数 | 70 |
| 注意力头数 | 40 |
| 词汇表大小 | 131,072 |
| 隐藏层维度 | 7,680 |
| 总参数量 | 50.6B |
| 超参数 (Hyperparameters) | |
| 最大学习率 | 6e-5 |
| 最终学习率 | 6e-6 |
| 学习率调度 | 余弦衰减 |
| 梯度裁剪 | 0.3 |
| 训练 (Training) | |
| Tokens | 569B |
| 硬件 | $64\times 8$ A100 40GB |
| 吞吐量 | 32.5 秒/步 |
| 平均TFLOPs | 102 |
| 总FLOPs | 2.36e23 |
表4:BloombergGPT的模型超参数和训练配置总结。
训练过程
训练在AWS SageMaker平台上进行,使用了512个40GB A100 GPU,历时约53天。 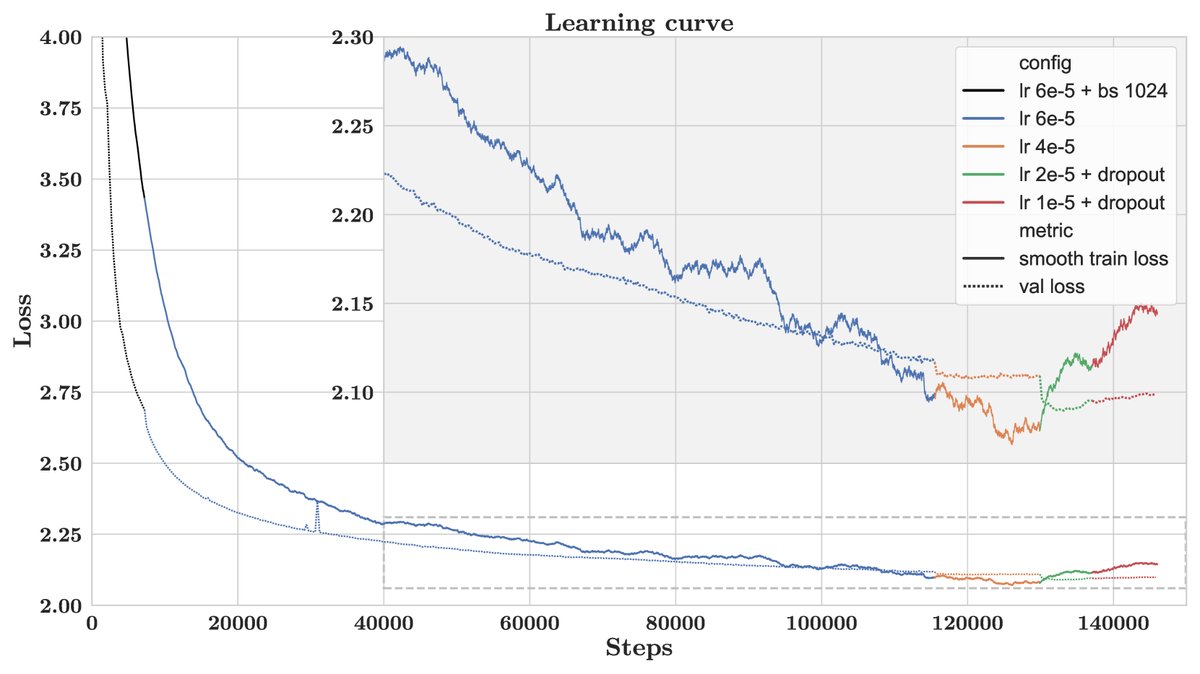
图2:训练和验证损失曲线。不同颜色代表不同的超参数配置。
为了在有限的GPU内存中训练大模型,本文采用了一系列并行和优化技术:
- ZeRO优化 (Stage 3): 将模型参数、梯度和优化器状态分片到128个GPU上。
- 激活检查点 (Activation Checkpointing): 以重计算为代价减少内存占用。
- 混合精度训练: 使用BF16进行前向和后向传播,FP32存储和更新参数。
- 融合核 (Fused Kernels): 将多个GPU操作合并,提高速度并避免内存溢出。
训练过程中,当验证损失出现停滞或上升时,团队采取了干预措施,如逐步降低学习率和引入Dropout,最终在验证损失不再显著改善时停止训练,并选择了表现最佳的检查点作为最终模型。
实验结论
本文对BloombergGPT在两大类任务上进行了全面评估:金融专属任务和通用任务。
- 评估对象:与三个公开可用的、规模和架构具有可比性的模型进行比较:GPT-NeoX (20B),OPT (66B),和BLOOM (176B)。
- 评估方法:为了公平比较,所有任务均采用标准的零样本或少样本提示(few-shot prompting),不进行特定于模型的提示工程或思维链(Chain-of-Thought)等高级技巧。
| 评估套件 | 任务数 | 衡量什么? |
|---|---|---|
| 公开金融任务 | 5 | 金融领域的公开数据集表现 |
| 彭博金融任务 | 12 | NER和情感分析等内部核心任务 |
| Big-bench Hard | 23 | 推理和通用NLP任务 |
| 知识评估 | 5 | 模型的闭卷信息回忆能力 |
| 阅读理解 | 5 | 模型的开卷任务表现 |
| 语言学任务 | 9 | 非直接面向用户的NLP任务 |
表5:评估基准的分类。
核心发现: 根据论文摘要和引言的描述(原文的评估结果图表部分缺失),BloombergGPT取得了以下关键成果:
- 在金融任务上表现卓越:在公开的金融NLP基准测试以及反映彭博内部实际应用场景的专有任务(如情感分析、命名实体识别)上,BloombergGPT的表现显著优于所有可比较的同类模型。这直接验证了混合训练中大量高质量金融数据的价值。
- 在通用任务上保持强大竞争力:尽管训练数据中有一半是金融专业数据,BloombergGPT在通用的LLM基准测试(如BIG-bench Hard、常规知识问答)上,其性能与同等规模甚至更大规模的通用模型持平或更好。这表明,领域特化并未以牺牲通用能力为代价。
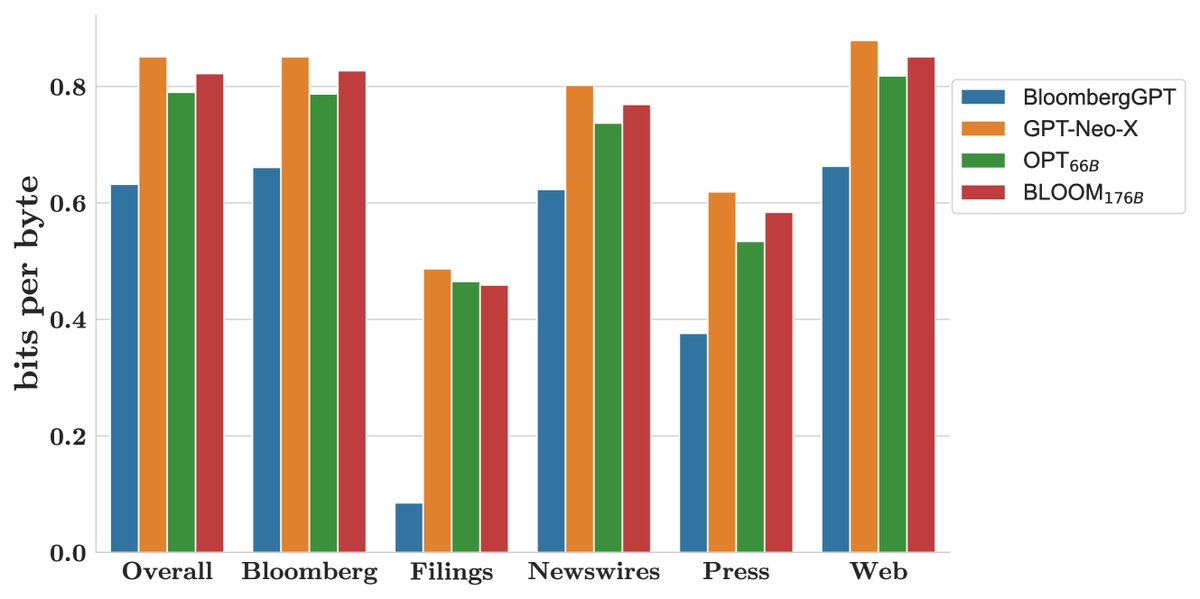
图3:在多个留出测试集上的每字节比特数表现,数值越低越好。
最终结论: 本文的实验结果有力地证明了其提出的混合数据训练策略的成功。BloombergGPT的成功表明,通过将大规模、高质量的领域专属数据与通用数据相结合,可以训练出既是“领域专家”又是“通才”的大型语言模型。这种方法为未来其他专业领域(如法律、医疗、科学)构建高性能LLM提供了一个极具价值的范例和实践蓝图。