BridgeData V2: A Dataset for Robot Learning at Scale
-
ArXiv URL: http://arxiv.org/abs/2308.12952v3
-
作者: Manish P Bhatt; I. Evtimov; Xiaoqing Tan; Jonas Gehring; Tal Remez; J. Rapin; Gabriel Synnaeve; F. Azhar; Itai Gat; Louis Martin; 等15人
-
发布机构: CMU; Google DeepMind; Stanford; University of California, Berkeley
TL;DR
本文介绍了 BridgeData V2,一个大规模、多样化的机器人操作行为数据集,旨在推动可扩展机器人学习的研究。该数据集包含在24个环境中、使用一个公开可用的低成本机器人收集的超过6万条轨迹,并证明了其能够支持多种主流学习算法训练出可泛化到新任务、新环境甚至新机构的策略。
关键定义
本文沿用了机器人学习领域的一些术语,并对其用法进行了明确界定,以清晰地描述数据集的构成:
- 技能 (Skill):指代表现出相似运动模式的轨迹组。例如,“抓取并放置”、“清扫”、“折叠”或“开门”等,这些技能可以应用于不同的物体或物体布局。
- 任务 (Task):指代对应于相似自然语言指令的轨迹组。在实践中,这意味着使用相似运动(同一技能)但操作不同物体(例如,拿起叉子 vs. 拿起碗)对应的是不同的任务。
相关工作
- 研究现状:现有的机器人学习数据集大多存在局限性。一些数据集(如MIME, RoboTurk)虽然包含多任务,但通常局限于单个环境,导致在其上训练的策略难以泛化到新的场景。另一些大规模数据集(如RT-1, BC-Z)则依赖于昂贵的、非公开的专有机器人,限制了学术界研究的可及性。此外,许多数据集只适用于单一类型的学习方法(例如,仅限行为克隆)。
- 本文要解决的问题:目前缺少一个同时满足以下条件的机器人操作数据集:1) 大规模且多样化,覆盖多种技能和环境;2) 在低成本、公开可用的机器人平台上收集,便于不同研究机构复现和使用;3) 足够通用,能够支持包括目标条件、语言条件、模仿学习 (Imitation Learning) 和离线强化学习 (Offline Reinforcement Learning) 在内的多种前沿算法。
本文方法
本文的核心贡献是 BridgeData V2 数据集本身。其设计理念和构成旨在成为一个能够促进可扩展、通用机器人学习研究的基础资源。
系统设置与数据收集
-
硬件平台:数据收集使用了一个总成本约4000美元、易于采购的机器人系统,主要包括一个 WidowX 250 机械臂和多个摄像头(一个肩视固定RGBD摄像头,两个姿态随机化的RGB摄像头,以及一个腕部RGB摄像头)。
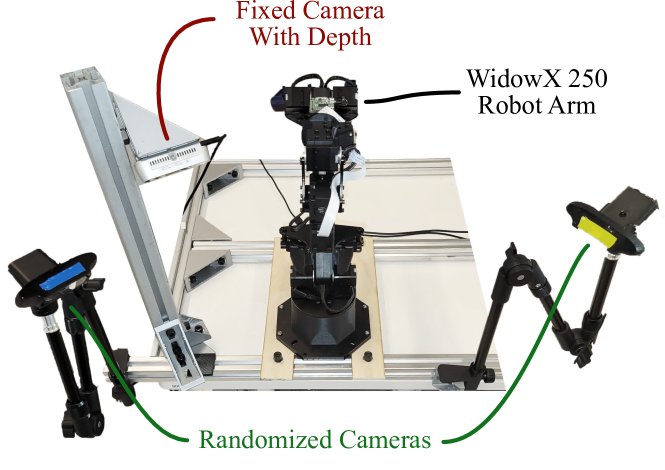
-
数据收集协议:
- 支持多任务学习:在一个场景中设置多种可能的任务(例如,厨房场景里有抽屉、水槽和多种餐具)。数据收集者可以连续执行任何可行的任务(如开抽屉或把餐具放入水槽),而无需在每次操作后重置环境。这种设计强迫模型必须理解任务指令(目标图像或语言),而不是简单地从初始观察中推断任务。
- 增强泛化性:为了提升策略的泛化能力,数据收集中会定期(约每50条轨迹)随机化相机位姿、更换场景中的物体,并改变工作空间相对于机器人的位置。
- 混合数据来源:数据集不仅包含人类专家通过VR手柄遥操作收集的演示数据,还包含一部分由一个高度随机化的脚本策略自主收集的“抓取-放置”数据。这些自主收集的数据虽然成功率不高,但为离线强化学习等需要探索性数据的算法提供了宝贵的次优数据。
- 事后标注:收集到的轨迹没有实时任务标签,而是通过众包平台进行事后自然语言标注,描述机器人执行的任务。
数据集构成与特点
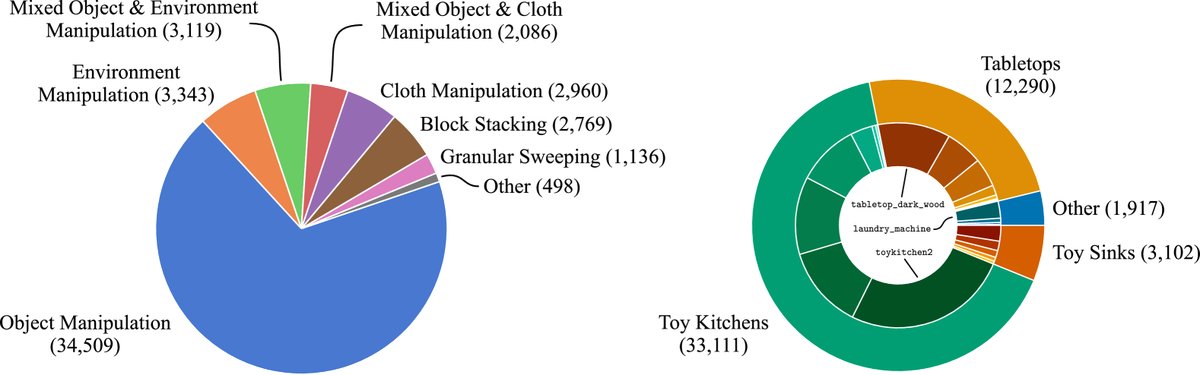
BridgeData V2 是一个规模巨大且高度多样化的数据集,远超其第一版。
-
规模与构成:共包含 60,096 条轨迹,其中 50,365 条是专家演示,9,731 条来自脚本策略。数据集涵盖 13 种核心技能和 24 个不同的环境(如厨房、水槽、桌面等),涉及超过100种物体。
-
技能多样性:技能范围广泛,从基础的物体操作(抓取-放置、推动、重定向)到更复杂的任务,如开关门窗/抽屉、擦拭表面、折叠布料、堆叠积木、使用工具清扫颗粒物等。

-
创新与优点:
- 通用性与兼容性:数据集的设计支持多种学习范式,包括基于目标图像的模仿学习(GCBC, D-GCBC, ACT)、离线强化学习(CRL)以及基于自然语言的模仿学习(LCBC, RT-1),使其成为一个通用的算法测试平台。
- 可及性:使用低成本、公开可用的硬件,使得其他研究者能够轻松地在自己的实验室中复现并扩展研究。
- 为泛化而设计:广泛的任务、物体和环境变化,以及独特的“多任务共存”数据收集策略,使其成为研究机器人泛化能力的理想资源。
- 正向迁移的潜力:包含大量不同但相关的技能数据,为研究技能间的正向迁移提供了可能。
| 数据集 | # 轨迹 | # 技能 | # 环境 | 语言 | 公开数据 | 公开机器人 | 收集方式 |
|---|---|---|---|---|---|---|---|
| MIME [3] | 8.30k | 12 | 1 | ✗ | ✓ | ✓ | 人类 |
| RoboTurk [4] | 2.10k | 2 | 1 | ✗ | ✓ | ✓ | 人类 |
| RoboNet [23] | 162k | n/a | 10 | ✗ | ✓ | ✓ | 脚本 |
| MT-Opt [30] | 800k | 1 | 1 | ✗ | ✗ | ✓ | 脚本 & 学习 |
| BridgeData [6] | 7.20k | 4 | 12 | ✓ | ✓ | ✓ | 人类 |
| BC-Z [5] | 26.0k | 3 | 1 | ✓ | ✓ | ✗ | 人类 |
| RT-1 [7] | 130k | 2 | 3 | ✓ | ✗ | ✗ | 人类 |
| RH20T [49] | 13.0k | 41 | 50 | ✓ | ✓ | ✓ | 人类 |
| RoboSet [32] | 98.5k | 6 | 11 | ✓ | ✓ | ✓ | 29% 人类, 71% 脚本 |
| BridgeData V2 | 60.1k | 13 | 24 | ✓ | ✓ | ✓ | 84% 人类, 16% 脚本 |
实验结论
实验旨在验证 BridgeData V2 作为多任务离线学习研究平台的有效性,评估了6种主流方法(GCBC、D-GCBC、ACT、CRL、LCBC、RT-1)在数据集上的表现。
技能学习与泛化能力
- 场景内泛化:在训练数据“见过”的任务上(物体位置、光照等有变化),所有方法都能学习到一定程度的技能。RT-1在语言条件任务上表现显著优于基线LCBC,而各种目标条件方法的性能则大致相当。
- 场景外泛化:在需要泛化到新物体和新环境的任务上,所有方法都表现出非零的成功率,证明了数据集支持广泛的泛化。例如,即使米和刷子都是未见过的,策略也能成功执行扫米的任务。语言条件方法在处理名称未出现在训练集中的新物体时挑战更大。
| 任务 (见过) | GCBC | D-GCBC | ACT | CRL | LCBC | RT-1 |
|---|---|---|---|---|---|---|
| 打开抽屉 | 0.4 | 0.6 | 0.5 | 0.4 | 0.5 | 1.0 |
| 用杆把豆子扫成一堆 | 0.9 | 0.9 | 0.9 | 0.7 | 0.4 | 0.6 |
| 将蓝色薄布折叠在物体上 | 0.4 | 0.7 | 0.7 | 0.5 | 0.5 | 0.9 |
| 平均 | 0.49 | 0.49 | 0.41 | 0.42 | 0.23 | 0.49 |
| 任务 (未见过) | GCBC | D-GCBC | ACT | CRL | LCBC | RT-1 |
|---|---|---|---|---|---|---|
| 用刷子()把米()扫成堆 | 0.6 | 0.0 | 0.3 | 0.3 | 0.0 | 0.1 |
| 把记号笔(*)放进碗里(†) | 0.6 | 0.6 | 0.2 | 0.7 | 0.0 | 0.0 |
| 用布(‡)擦桌子(‡) | 0.6 | 0.5 | 0.4 | 0.6 | 0.4 | 0.9 |
| 平均 | 0.60 | 0.55 | 0.28 | 0.52 | 0.08 | 0.50 |
跨机构泛化能力
- 为了验证数据集的通用性,另一个机构(Lab 2)搭建了相同的机器人平台,并直接部署在原始实验室(Lab 1)训练好的策略(零样本迁移)。尽管存在机器人设置、光照、相机位置等领域的差异,所有方法都在Lab 2取得了非零的成功率,其中RT-1的性能下降最小。这证明了 BridgeData V2 能够支持跨机构的研究与合作。
| 任务 (Lab 1 → Lab 2) | GCBC | D-GCBC | ACT | CRL | LCBC | RT-1 |
|---|---|---|---|---|---|---|
| 平均成功率 | 0.30 → 0.13 | 0.23 → 0.13 | 0.03 → 0.10 | 0.13 → 0.20 | 0.13 → 0.03 | 0.47 → 0.40 |
规模化效应分析
- 模型规模:使用更大容量的模型(如更大的ResNet编码器)可以获得更好的性能。
- 数据规模:随着训练数据集规模的增加,策略在已见和未见任务上的性能都得到提升。
- 数据多样性:这是一个关键发现。在保持数据总量大致相同的情况下,使用包含13种技能的数据集训练的策略,其在未见任务上的泛化性能显著优于仅使用3种技能数据集训练的策略。这表明不同技能之间存在正向迁移,训练更多样化的技能有助于提升单一技能的鲁棒性和泛化能力。
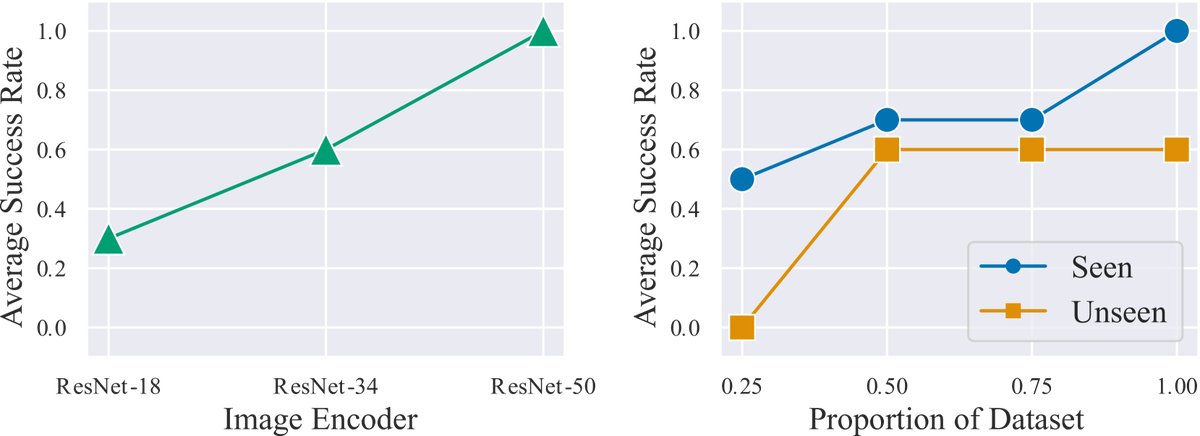
- 最终结论:实验结果有力地证明了 BridgeData V2 是一个高质量、实用且有效的研究平台。它不仅能支持多种学习算法训练出具备泛化能力的策略,而且实验揭示了“规模效应”——增加模型容量、数据量和数据多样性是通往更强机器人能力的有前景的路径。