BrowseConf: Confidence-Guided Test-Time Scaling for Web Agents
-
ArXiv URL: http://arxiv.org/abs/2510.23458v2
-
作者: Yong Jiang; Pengjun Xie; Xixi Wu; Litu Ou; Rui Ye; Huifeng Yin; Jingren Zhou; Kuan Li; Zhongwang Zhang; Zile Qiao; 等11人
-
发布机构: Alibaba Group; Tongyi Lab
TL;DR
本文提出了一种名为 BrowseConf 的测试时扩展 (Test-Time Scaling, TTS) 方法,它通过利用大语言模型智能体对其回答的“口头表述置信度” (Verbalized Confidence),来动态决定是否需要进行额外的计算尝试,从而在保证任务性能的同时,显著提升了网络信息获取任务的计算效率。
关键定义
本文的核心方法建立在以下几个关键概念之上:
- 口头表述置信度 (Verbalized Confidence):一种模型无关的置信度评估方法。通过在提示中加入特定指令,让模型在生成最终答案的同时,输出一个自我评估的置信度分数(本文中为 0-100 分)。
- BrowseConf:本文提出的核心方法。这是一种基于置信度的测试时扩展策略,它根据智能体报告的口头表述置信度动态分配计算资源。只有当置信度低于预设阈值时,才会启动新一轮的解答尝试。
- 置信度阈值 (Confidence Threshold, $\tau$):一个预先设定的决策边界。如果智能体当前尝试的置信度分数 $C_i < \tau$,则认为结果不可靠,需要再次尝试;反之,则接受当前答案并终止流程。该阈值通过在一个验证集上进行校准来确定。
- BrowseConf 变体:
- BrowseConf-Zero:最基础的变体。当需要再次尝试时,完全从零开始,不保留任何先前尝试的信息。
- BrowseConf-Summary:一种知识传递策略。在启动新尝试前,让模型对上一次低置信度的尝试过程进行总结,并将该摘要作为额外信息输入到下一次尝试中,以指导新的探索。
- BrowseConf-Neg:一种负向约束策略。将之前所有低置信度尝试产生的错误答案提供给模型,并明确指示它生成一个与这些答案都不同的新答案。
相关工作
当前,即使是最先进的大语言模型(LLM)也依然存在产生幻觉和过度自信的错误。虽然学术界已经探索了多种置信度评估方法,如口头表述分数、Token 概率和自我反思,但这些研究大多集中于单步、非交互式的任务。
对于需要与外部环境(如网络)进行多轮交互的复杂智能体任务,置信度评估的研究尚不充分。在这类长时程任务中,智能体容易忘记之前获取的信息,或难以从早期错误中恢复,导致最终的置信度评估并不可靠。
同时,现有的测试时扩展(TTS)技术,如自洽性(Self-Consistency),通常对所有问题都采用固定的多次采样(rollouts)策略,这在智能体已经能够轻松解决某些问题时,会造成大量的计算资源浪费。
本文旨在解决的问题是:如何在复杂的网络信息获取智能体任务中,更高效地利用计算资源,避免对简单问题进行不必要的重复计算,同时提升对困难问题的解决能力。
本文方法
本文首先通过实验证明,在复杂的网络浏览任务中,智能体的口头表述置信度与其任务准确率之间存在强烈的正相关关系。如下图所示,尽管模型普遍存在过度自信(报告的置信度远高于实际准确率),但高置信度分数确实对应着更高的准确率。
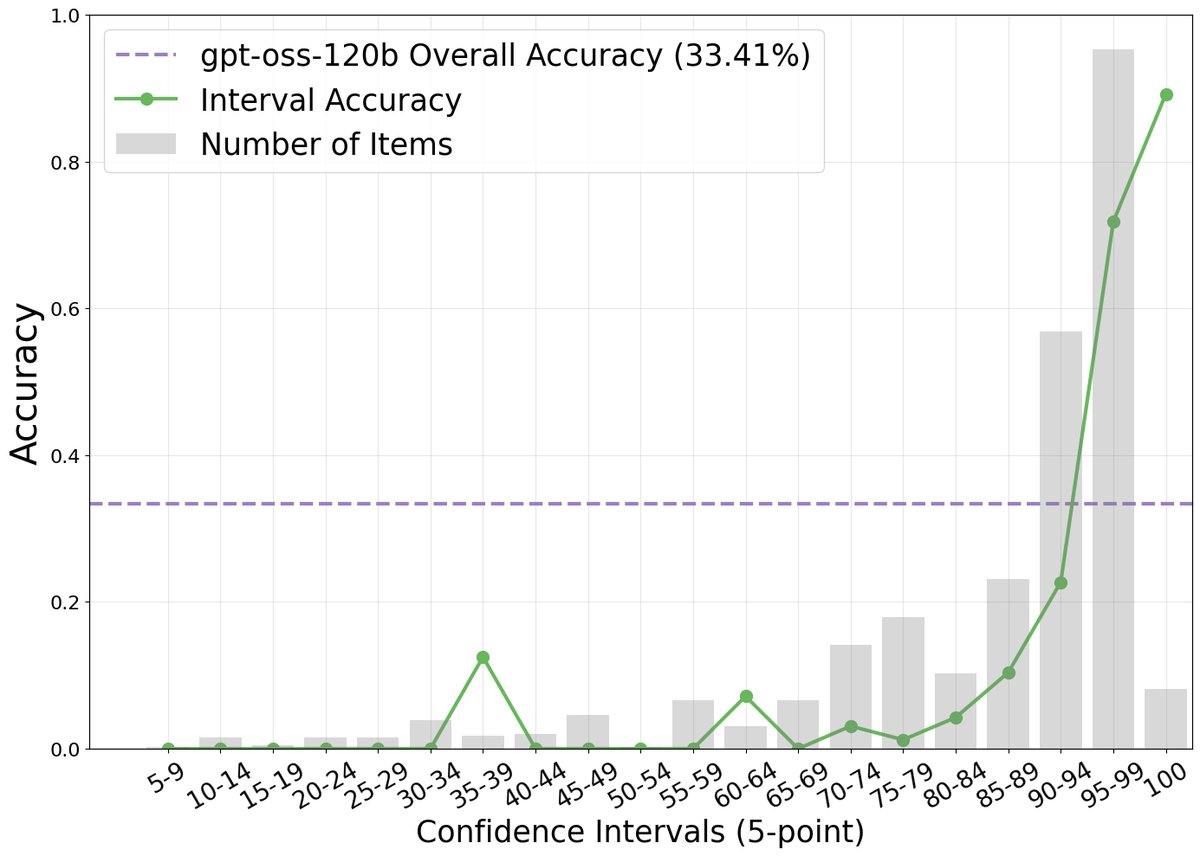
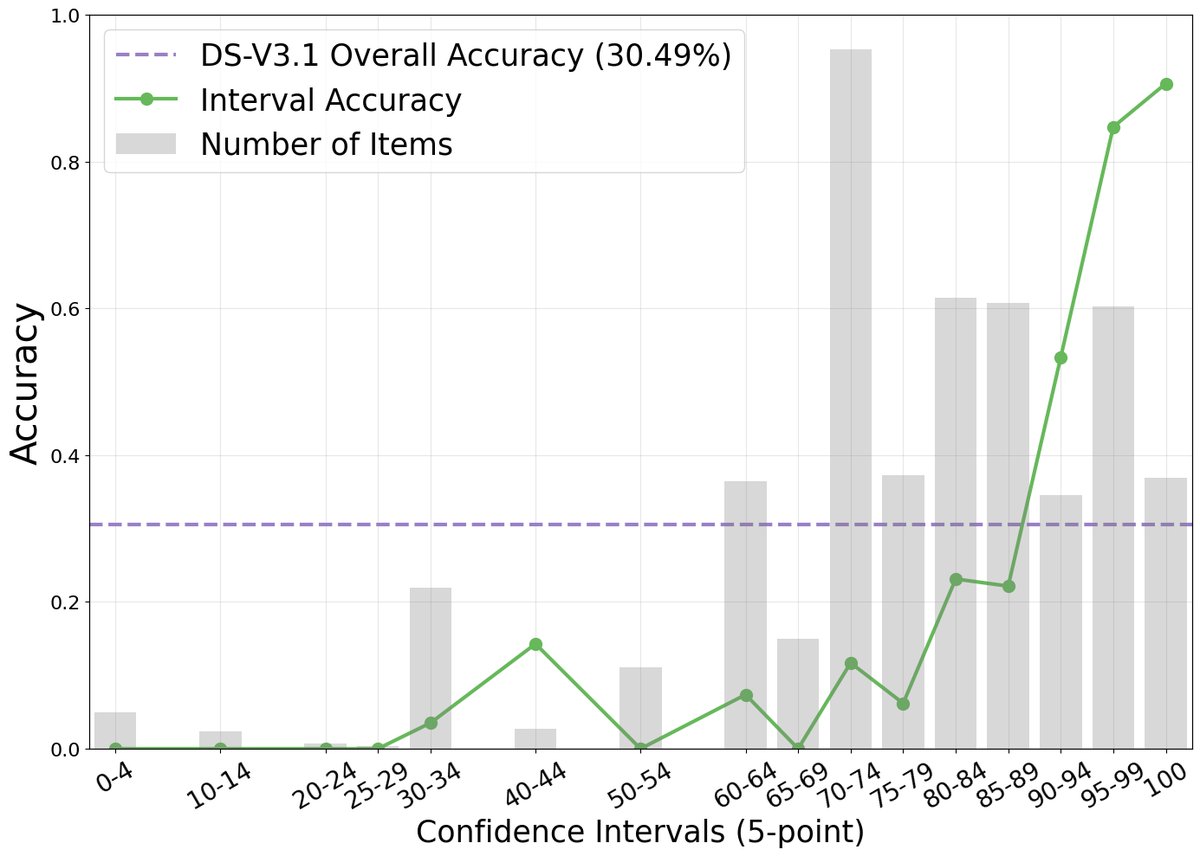
创新点
基于这一发现,本文提出了 BrowseConf,一种根据置信度动态分配计算预算的测试时扩展方法。其核心创新在于用智能体自身的置信度判断来动态触发计算,而非采用固定的、统一的计算开销。
核心算法
对于给定的查询 $q$,算法流程如下:
- 智能体进行第 $i$ 次尝试,生成答案 $A_i$ 和置信度分数 $C_i$。
- 判断 $C_i$ 是否大于或等于预设的置信度阈值 $\tau$。
- 如果 $C_i \geq \tau$,则认为答案可靠,终止流程并返回 $A_i$。
- 如果 $C_i < \tau$,且总尝试次数未达到上限 $N$,则启动下一次尝试。
- 如果所有 $N$ 次尝试都未能达到置信度阈值,则返回所有尝试中置信度最高的那个答案 $A_{best}$。
阈值校准
为了避免测试集泄漏,置信度阈值 $\tau$ 在一个独立的验证集(本文使用 SailorFog-QA 的子集)上进行校准。阈值 $\tau^*$ 的选择标准是:找到一个最小的置信度分数,使得在该分数以上的样本子集,其准确率相比于整个验证集的总体准确率,至少有 $k\%$ 的相对提升。其计算公式为:
\[\tau^{*}=\min\bigg\{\tau\in[0,100]\mid\frac{\text{Acc}(\{x\in D_{val}\mid C\geq\tau\})-\text{Acc}(D_{val})}{\text{Acc}(D_{val})}\geq\frac{k}{100}\bigg\}\]优点
BrowseConf 的核心优点是计算效率。它能有效避免在智能体已经高度自信的问题上进行冗余的计算尝试,将算力“好钢用在刀刃上”,仅对智能体不确定的难题进行多次探索,从而在达到甚至超越固定预算方法性能的同时,大幅降低平均计算成本。
方法变体
为了进一步优化多次尝试之间的效率,本文还提出了两种改进策略,旨在利用先前尝试失败所产生的信息:
- BrowseConf-Summary (摘要指导):该变体让模型对低置信度的尝试过程进行总结,提炼出关键实体、矛盾点和未完成的推理步骤。这个摘要会作为附加信息,用于指导下一次尝试,避免重复探索。
- BrowseConf-Neg (负向约束):该变体将之前所有尝试中产生的低置信度答案集合提供给模型,并明确指示它生成一个与这些答案都不同的新答案,从而约束搜索空间,避免陷入已知的错误路径。
实验结论
实验在 gpt-oss-120b 和 DeepSeek-V3.1 模型上,以及在 BrowseComp 和 BrowseComp-zh 这两个高难度的信息寻求基准上进行。
主要结果
如下表所示,BrowseConf 系列方法在性能上与强大的基准方法(如 Self-Consistency 和 CISC)相当,甚至在某些情况下更优。
| 模型 | 方法 | BrowseComp (英文) | BrowseComp-zh (中文) |
|---|---|---|---|
| gpt-oss-120b | |||
| Pass@1 | 33.8 / 1 | 38.0 / 1 | |
| Pass@10 | 70.3 / 10 | 74.7 / 10 | |
| Self-Consistency (10) | 47.5 / 10 | 50.5 / 10 | |
| CISC (10) | 52.2 / 10 | 53.3 / 10 | |
| BrowseConf-Zero | 52.1 / 3.76 | 51.6 / 2.32 | |
| BrowseConf-Summary | 48.7 / 2.06 | 49.2 / 2.09 | |
| BrowseConf-Neg | 52.5 / 3.87 | 54.5 / 2.43 | |
| DeepSeek-V3.1 | |||
| Pass@1 | 29.5 / 1 | 51.1 / 1 | |
| Pass@10 | 68.6 / 10 | 82.0 / 10 | |
| Self-Consistency (10) | 36.7 / 10 | 61.1 / 10 | |
| CISC (10) | 38.7 / 10 | 59.8 / 10 | |
| BrowseConf-Zero | 41.3 / 5.67 | 59.2 / 3.42 | |
| BrowseConf-Summary | 40.1 / 5.14 | 53.4 / 3.74 | |
| BrowseConf-Neg | 41.7 / 5.72 | 54.3 / 3.68 |
表格说明:每个单元格的格式为“准确率 (%) / 平均尝试次数”。
- 性能与效率:BrowseConf 方法在准确率上极具竞争力,同时显著降低了计算成本。例如,在 gpt-oss-120b 上,BrowseConf-Neg 取得了最高的准确率,而平均尝试次数仅为 2.43-3.87 次,远低于基准方法固定的 10 次。
- 变体对比:在三种变体中,BrowseConf-Neg(负向约束)通常能取得最高的任务准确率。BrowseConf-Summary(摘要指导)则在计算效率上表现最佳,需要的平均尝试次数最少。BrowseConf-Zero(从零开始)在性能和效率之间提供了一个平衡。
消融研究与分析
-
置信度阈值的影响:实验表明,一个更严格的置信度阈值(即更大的 $k\%$)可以带来更高的最终准确率,但代价是需要更多的平均尝试次数。这揭示了准确率与计算成本之间的权衡关系。
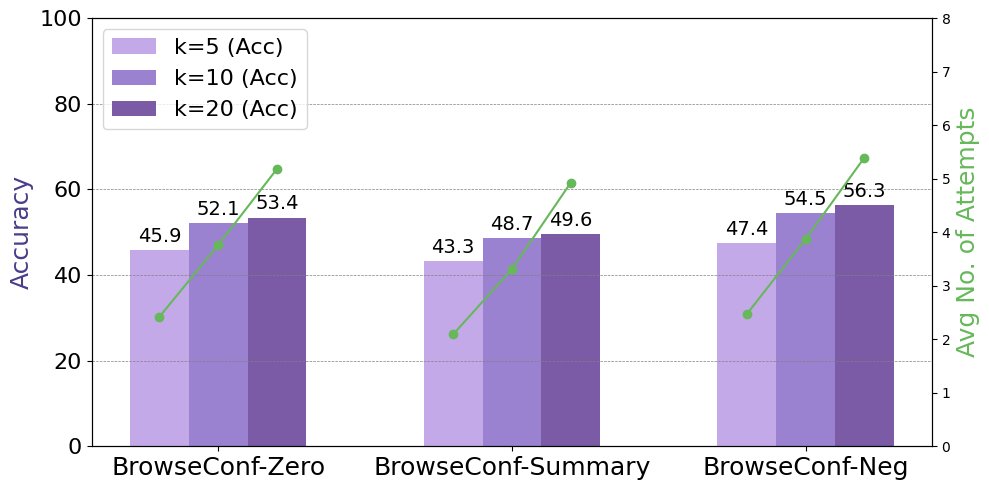
-
连续尝试间的交互变化:分析显示,携带了历史信息的 BrowseConf-Summary 和 BrowseConf-Neg 方法,在后续尝试中所需的交互步骤(thought-action-observation 循环)显著减少。这证明了利用先前尝试的信息能让智能体更高效地解决问题。
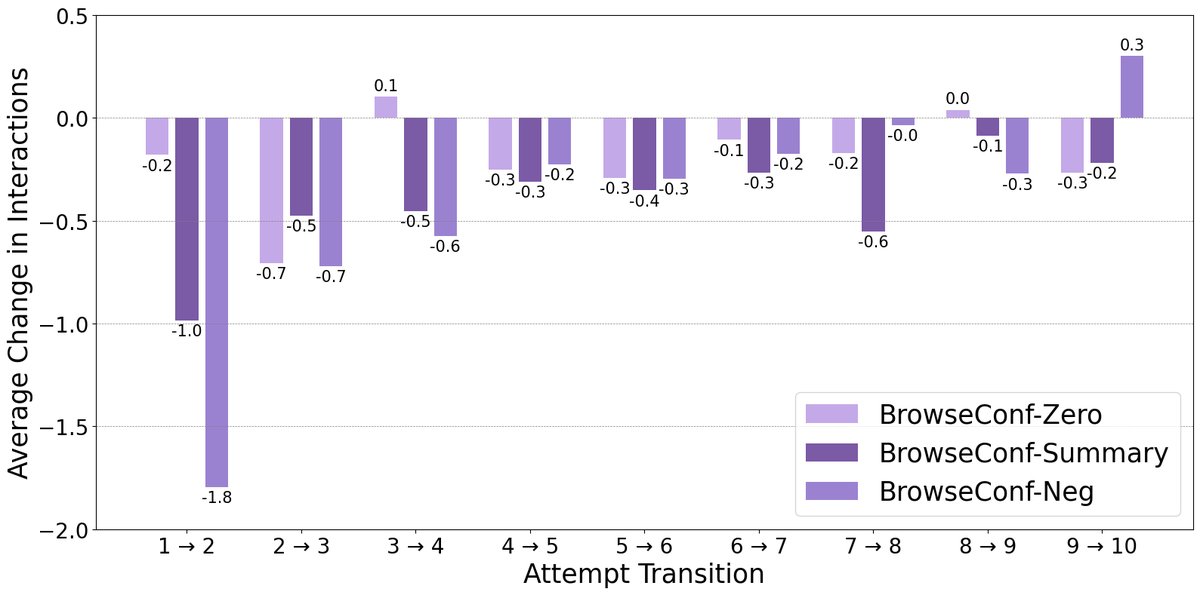
总结
本文证实了口头表述置信度是评估智能体在复杂任务中表现的一个可靠信号。基于此,提出的 BrowseConf 方法通过动态分配计算资源,在保证高任务准确率的同时,显著优于固定预算的传统 TTS 方法的计算效率,为构建更高效、更智能的 AI 智能体提供了新的思路。