CALM Before the STORM: Unlocking Native Reasoning for Optimization Modeling
-
ArXiv URL: http://arxiv.org/abs/2510.04204v1
-
作者: Hongyuan Zha; Zihan Ye; Guanhua Chen; Zizhuo Wang; Chengpeng Li; Ming Yan; Chenyu Huang; Xuhan Huang; Dayiheng Liu; Sihang Li; 等12人
-
发布机构: Alibaba Inc.; Shanghai University of Finance and Economics; Shenzhen Loop Area Institute; Southern University of Science and Technology; The Chinese University of Hong Kong, Shenzhen
TL;DR
本文提出 CALM 框架,通过专家智能体注入轻量级提示来修正大型推理模型 (LRM) 的原生推理缺陷,从而生成高质量数据,并通过监督微调和强化学习两阶段训练,打造出在优化建模任务上达到业界顶尖水平且参数高效的模型 STORM。
关键定义
- 原生推理模式 (Native Reasoning Mode):指现代大型推理模型 (LRM) 固有的、无需额外训练即可执行多轮迭代式自我修正与推理的能力。本文旨在保护并增强此能力,而非简单地用直接生成模式覆盖它。
- CALM (Correcting Adaptation with Lightweight Modification):一个创新的数据策划框架。在该框架中,一个“干预者 (Intervener)”(专家模型)识别“推理者 (Reasoner)”(待训练模型)在其推理过程中出现的缺陷,并提供简短的修正提示,引导其生成高质量的专家级推理轨迹。
- STORM (Soft-Tuned Optimization Reasoning Model):基于 CALM 框架训练得到的最终模型。它首先通过 CALM 生成的数据进行监督微调(软适应),然后通过强化学习进行能力强化,最终实现自主掌握。
- 计算驱动推理缺陷 (Computation-Driven Reasoning Deficiencies):一类推理缺陷,指 LRM 未能有效利用外部计算工具(如代码解释器和求解器),例如尝试手动计算复杂问题或编写碎片化的代码。
- 领域知识缺陷 (Domain-Specific Knowledge Deficiencies):另一类推理缺陷,指 LRM 在建模和逻辑上出现根本性错误,例如数学公式错误、遗漏约束条件或代码实现错误。
相关工作
目前,自动化优化建模领域的主流方法是利用大型语言模型 (LLM) 将自然语言问题描述直接转换为数学模型和求解器代码。这些方法,如 ORLM 和 LLMOPT,通常在预先收集的、不包含中间推理步骤的静态“问题-解决方案”数据集上对模型进行微调。我们将这种方法称为“直接生成 (direct generation)”范式。
然而,随着具备复杂多步推理能力的大型推理模型 (LRM) 的出现,上述范式暴露了其局限性。直接在非反思性数据集上微调 LRM,会强制模型放弃其强大的原生推理模式,转而采用一种僵化的、非反思的生成风格。这导致模型在简单任务上略有提升,但在复杂任务上的性能却显著下降,未能充分发挥 LRM 的潜力。
本文旨在解决的核心问题是:如何有效地调整 LRM,以在不破坏其原生推理能力的前提下,充分利用其解决复杂的优化建模任务? 本文的目标是设计一种新的适应方法,能够保留并增强 LRM 的迭代推理能力,从而实现更高水平的性能。
本文方法
方法本质创新与优点
本文方法的核心是 CALM (Correcting Adaptation with Lightweight Modification) 框架,它通过一种“专家-学生”式的协作模式,动态地生成高质量的推理数据。与以往直接微调问题-答案对的方法不同,CALM 的创新之处在于:
- 保留并对齐原生推理:它不强制 LRM 学习一种全新的、非反思的生成模式,而是识别并修正其原生推理流程中的缺陷,使其与优化建模任务的需求对齐。
- 轻量级、靶向干预:通过专家“干预者”注入非常简短的提示 (hint),只修改了不到 2.6% 的 tokens,就能有效纠正推理轨迹。这种微创方法最大限度地保留了模型的原生思维链。
- 利用执行反馈:允许 LRM 访问代码求解器并获得即时执行反馈,这加强了其在单次推理中进行反思和修正的能力,模拟了人类专家的试错过程。
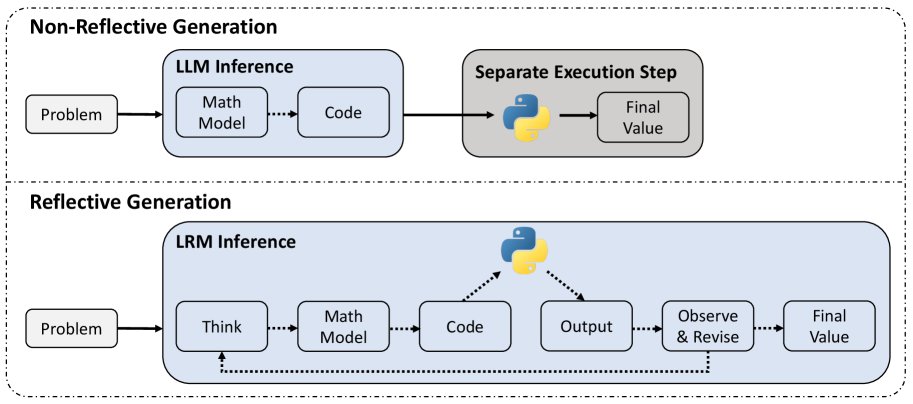 优化建模中的推理范式对比。上方为传统 LLM 的直接生成范式,下方为 LRM 在本文中采用的、整合了求解器反馈的反思性生成范式。
优化建模中的推理范式对比。上方为传统 LLM 的直接生成范式,下方为 LRM 在本文中采用的、整合了求解器反馈的反思性生成范式。
推理缺陷的分类体系
为了系统性地改进 LRM,本文首先对其在优化建模任务中未经引导的“原生”推理进行了缺陷分析。通过专家分析,识别出七种常见的缺陷类型,并将其归纳为两大概念类别:
- 计算驱动推理缺陷 (Computation-Driven Reasoning Deficiencies):指模型未能有效利用外部求解器工具,例如尝试手动计算或编写无法执行的代码片段。
- 领域知识缺陷 (Domain-Specific Knowledge Deficiencies):指模型在数学建模和逻辑上存在根本性错误,例如公式错误、遗漏约束条件等。
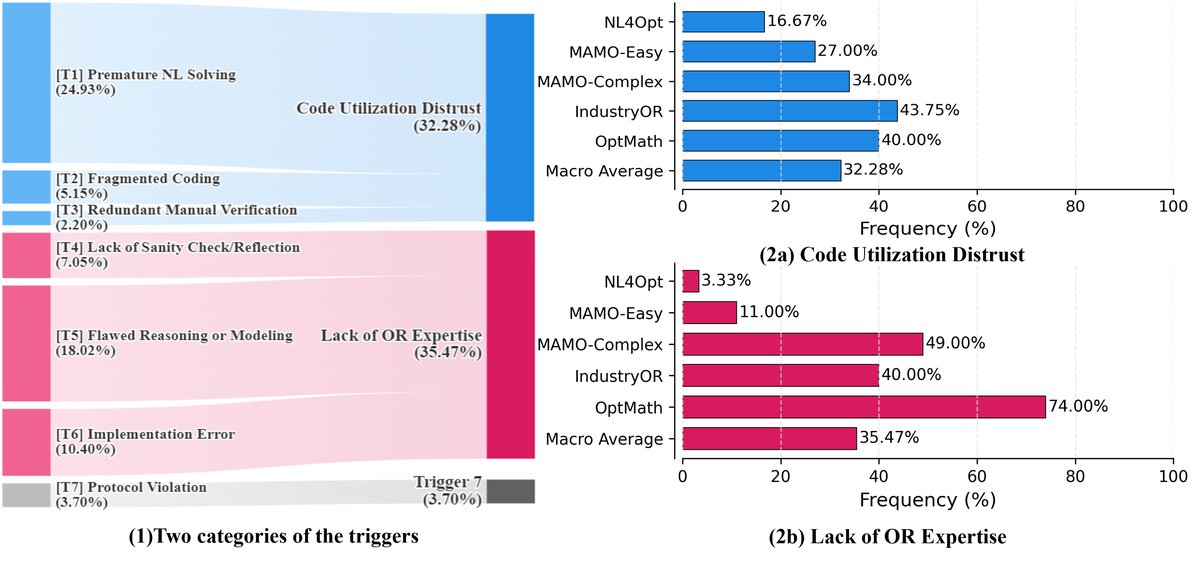 缺陷的分类与分布。左图显示了六种主要缺陷的宏平均频率。右图显示了两大类缺陷在不同难度基准测试上的分布情况。分析表明,在简单任务上,计算驱动缺陷是主要瓶颈;而在复杂任务上,领域知识缺陷成为主要障碍。
缺陷的分类与分布。左图显示了六种主要缺陷的宏平均频率。右图显示了两大类缺陷在不同难度基准测试上的分布情况。分析表明,在简单任务上,计算驱动缺陷是主要瓶颈;而在复杂任务上,领域知识缺陷成为主要障碍。
CALM 框架:通过轻量级修正进行数据策划
CALM 框架的核心是一个动态的、人机协作的修正循环,旨在将有缺陷的推理轨迹转化为专家级的解决方案。该过程形式化如下:
给定一个问题 $P$ ,推理者(即 LRM 策略 $\pi_{\theta}$)生成一个迭代的推理流 $\tau^{(T)}=(s_{0},a_{0},o_{0},\dots,s_{T},a_{T},o_{T})$,其中 $s_t$ 是推理文本, $a_t$ 是代码, $o_t$ 是代码执行结果。
CALM 框架的运行流程如下:
- 生成:推理者根据问题 $P$ 生成一个初始推理轨迹 $\tau^{(0)}$。
- 诊断与干预:干预者(一个更强大的专家模型)检查轨迹 $\tau^{(i)}$。若发现缺陷,例如在第 $t$ 步,干预者会生成一个针对性的、简短的提示 $h_i$。
- 修正与再生成:将提示 $h_i$ 追加到第 $t$ 步的上下文中,形成新的状态。推理者从这个修正后的状态继续生成,得到新的轨迹 $\tau^{(i+1)}$。
- 迭代:重复步骤2和3,直到干预者认为轨迹完美无缺,或达到最大干预次数。
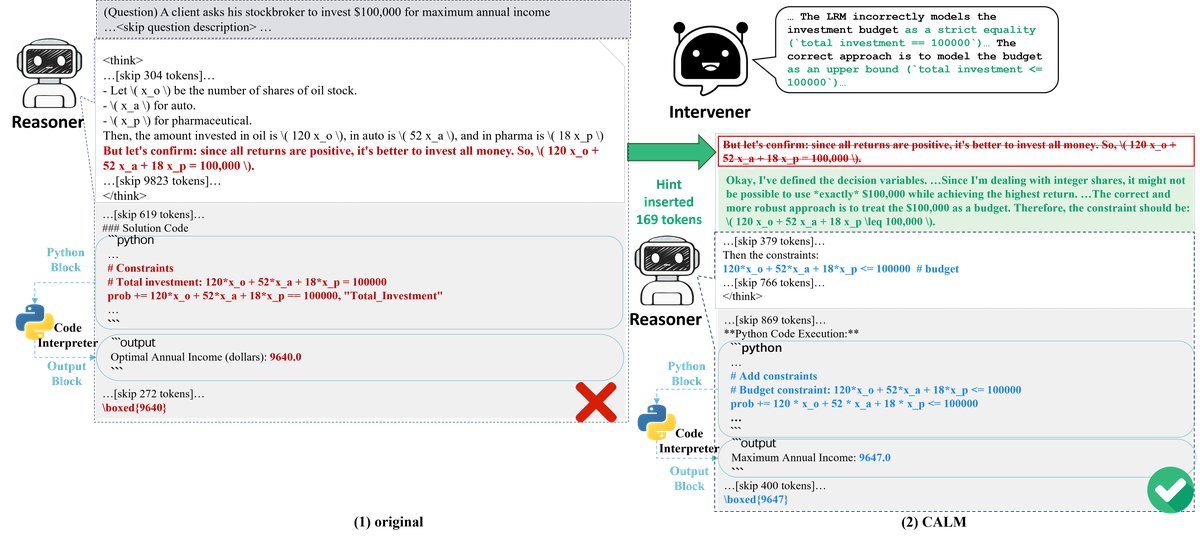 CALM 修正案例对比。(1) 模型的原生推理导致了错误的公式和答案。(2) 经过 CALM 的提示引导后,模型修正了公式,并找到了正确解。
CALM 修正案例对比。(1) 模型的原生推理导致了错误的公式和答案。(2) 经过 CALM 的提示引导后,模型修正了公式,并找到了正确解。
最后,只有那些最终答案正确且被干预者评为“无懈可击”的推理轨迹,才会被筛选出来,形成高质量的监督微调数据集 $\mathcal{D}_{CALM}$。
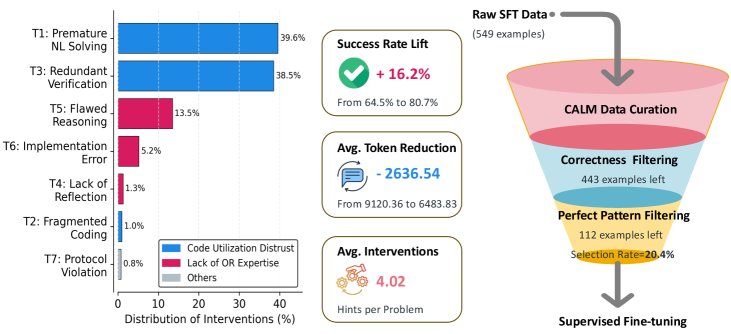 CALM 数据策划流程:(1) 对模型的原生推理进行缺陷诊断;(2) 通过提示进行迭代式修正,显著提升正确率;(3) 经过严格筛选,最终保留高质量的“黄金”轨迹用于训练。
CALM 数据策划流程:(1) 对模型的原生推理进行缺陷诊断;(2) 通过提示进行迭代式修正,显著提升正确率;(3) 经过严格筛选,最终保留高质量的“黄金”轨迹用于训练。
两阶段训练流程:从软适应到自主掌握
利用 CALM 策划的数据,本文设计了一个两阶段的训练流程来打造最终模型 STORM:
-
监督微调 (SFT) 进行软适应: 在 $\mathcal{D}_{CALM}$ 数据集上对基础 LRM 进行微调。此阶段的目标不是最大化最终得分,而是对模型的行为进行“软适应”,引导其养成良好的推理习惯,同时避免破坏其原生的反思性推理模式。
-
强化学习 (RL) 实现自主掌握: 在 SFT 之后,使用强化学习算法(GRPO)进一步优化模型。模型与代码解释器环境交互,目标是最大化获得正确答案的期望奖励 $J(\theta)$。奖励函数 $R(\tau)$ 是一个简单的二元信号:
\[R(\tau)=\begin{cases}1&\text{if }\left \mid \frac{Ans(\tau)-Ans^{*}}{Ans^{*}}\right \mid \leq\epsilon,\\ 0&\text{otherwise}.\end{cases}\]其中 $Ans(\tau)$ 是模型从轨迹中得到的答案,$Ans^{*}$ 是标准答案。这一阶段旨在让模型学会自主探索并实现性能的最大化。
实验结论
主要结果
本文将最终模型 STORM (4B 参数) 与一系列基线模型在五个优化建模基准上进行了比较。
| 模型 | GSM8K-OR | Streaming-OR | Math-OR | OR-Bench | NL4Opt | 宏平均 |
|---|---|---|---|---|---|---|
| 基础模型 (Qwen3-4B-Thinking) | 67.9 | 80.0 | 44.5 | 45.4 | 47.7 | 57.1 |
| STORM (本文方法, 4B) | 70.3 (+2.4) | 85.9 (+5.9) | 68.3 (+23.8) | 63.5 (+18.1) | 56.3 (+8.6) | 68.9 (+11.8) |
| Qwen3-235B-Thinking | 44.7 | 64.1 | 59.5 | 67.9 | 49.3 | 57.1 |
| DeepSeek-R1-0528 (671B) | 68.3 | 82.8 | 65.6 | 63.8 | 57.1 | 67.5 |
实验结果表明:
- 显著性能提升:与基础模型相比,STORM 在所有基准上均取得显著提升,宏平均准确率从 57.1% 提升至 68.9%(绝对提升 11.8 点),尤其在 \(Math-OR\) 等复杂任务上提升超过 23 点。
- 高参数效率:STORM 作为一个 4B 参数的模型,其性能不仅超越了其 235B 的同系列大型模型,还与一个 671B 的顶尖 LRM (DeepSeek-R1) 表现相当,证明了本文方法在参数效率上的巨大优势。
- 新的 SOTA:STORM 在学习型方法中取得了新的业界顶尖(SOTA)性能,推动了复杂优化建模领域的技术前沿。
消融与行为分析
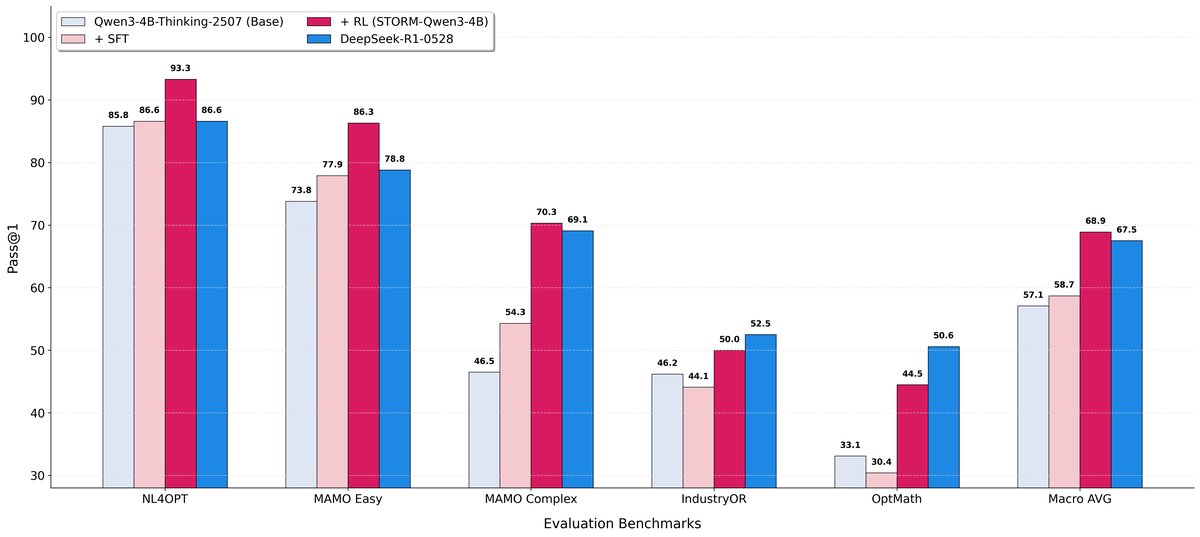 两阶段训练框架的消融研究。SFT 阶段提供了温和的性能校准,而 RL 阶段则实现了性能的巨大飞跃,使 4B 模型达到与 671B 模型相媲美的水平。
两阶段训练框架的消融研究。SFT 阶段提供了温和的性能校准,而 RL 阶段则实现了性能的巨大飞跃,使 4B 模型达到与 671B 模型相媲美的水平。
- 两阶段训练的贡献:消融研究证实了两阶段训练的必要性。SFT 阶段(使用 CALM 数据)起到了“行为校准器”的作用,温和地提升了性能并为后续训练打下稳定基础。随后的 RL 阶段则像一场“风暴”,带来了决定性的性能飞跃,将模型的宏平均准确率从 58.7% 大幅提升至 68.9%。
- CALM-SFT 对 RL 的催化作用:通过对比实验发现,在 CALM 生成的“黄金”轨迹上进行 SFT 后,模型在 RL 阶段的学习速度更快,性能上限也更高。这证明了高质量的初始引导(SFT)对于后续强化学习的样本效率和最终效果至关重要。
- 行为演化:经过完整训练后,STORM 的行为模式发生了显著变化。它倾向于使用更多的代码块来执行计算,同时减少了回答的总 token 数量。这表明模型从冗长的自然语言推理转向了更高效、更可靠的“计算驱动”专家行为模式。
- 缺陷修复机制:分析显示,SFT 阶段主要减少了“计算驱动推理缺陷”,而 RL 阶段则更有效地减少了“领域知识缺陷”。两个阶段协同作用,系统性地修复了模型的各项能力短板。
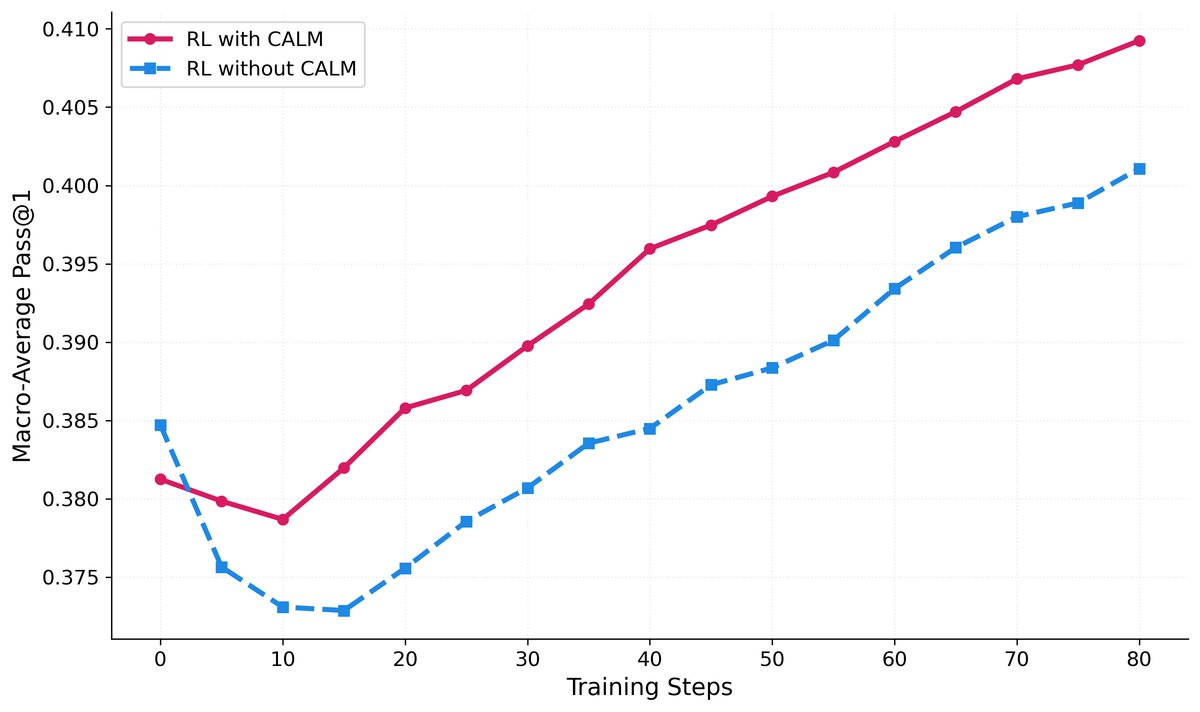 (左) RL 在复杂测试集上的性能。 (中) 平均代码块数量。 (右) 平均响应长度 (Tokens)。
(左) RL 在复杂测试集上的性能。 (中) 平均代码块数量。 (右) 平均响应长度 (Tokens)。
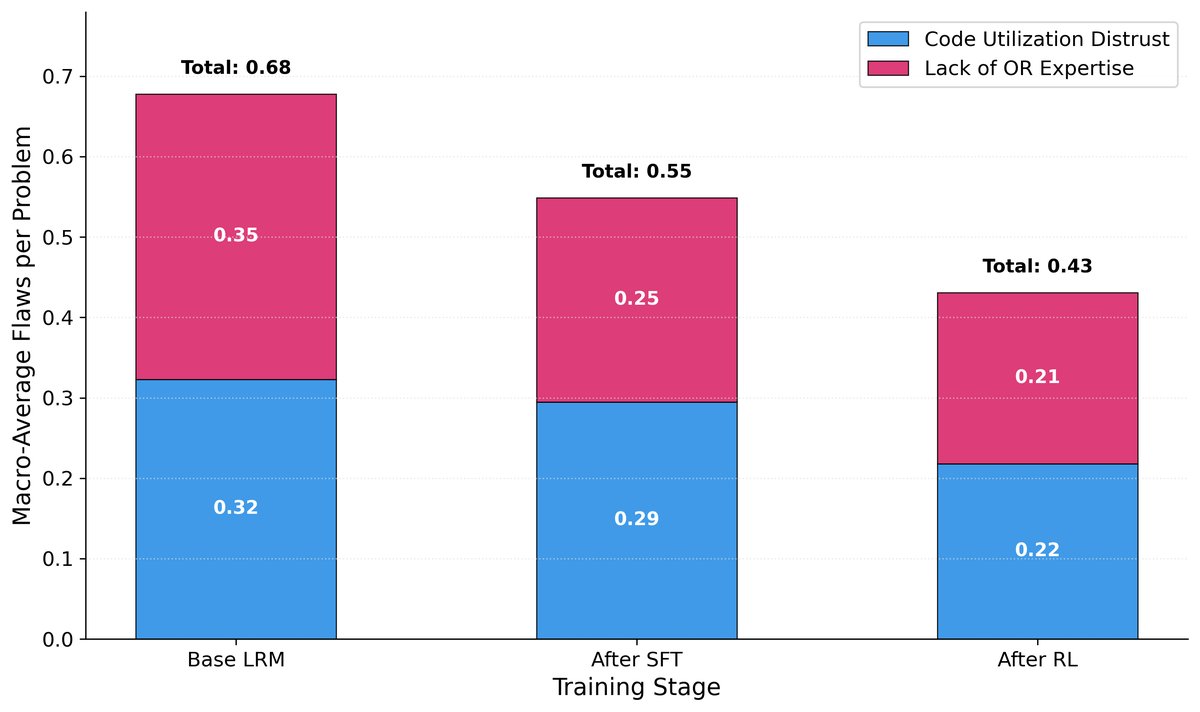 缺陷类型的演化。SFT 和 RL 阶段协同修复了不同类型的缺陷。
缺陷类型的演化。SFT 和 RL 阶段协同修复了不同类型的缺陷。
总结
本文证明,通过 CALM 框架进行轻量级、有针对性的干预,可以有效保留并增强 LRM 的原生推理能力,从而高效地将其适配到复杂的专业领域。最终的模型 STORM 以较小的参数量取得了顶尖的性能,为未来如何高效地将通用大模型特化为领域专家提供了 一条有效且可扩展的路径。