Capabilities of GPT-4 on Medical Challenge Problems
-
ArXiv URL: http://arxiv.org/abs/2303.13375v2
-
作者: S. McKinney; Harsha Nori; Nicholas King; E. Horvitz; Dean Carignan
-
发布机构: Microsoft; OpenAI
TL;DR
本文通过对美国行医执照考试(USMLE)等权威医学基准的全面评测,表明通用的GPT-4模型在未经任何领域专业化微调的情况下,其医学知识水平和推理能力已远超之前的通用模型(GPT-3.5)和医学专用模型(Med-PaLM),并以高分通过考试,同时展现出更优的概率校准能力和强大的交互式解释潜力。
关键定义
本文主要沿用现有概念,但其评估框架和分析中应用或提出了以下关键术语:
- 美国行医执照考试 (United States Medical Licensing Examination, USMLE): 在美国用于评估临床能力和授予行医执照的三步式标准化考试。本文将其作为衡量模型高级医学能力的核心基准,因其权威性和难度而具有重要意义。
- 零样本/少样本提示 (Zero-shot / Few-shot Prompting): 指在不提供或仅提供极少量示例的情况下,直接要求大语言模型完成任务的提示方法。本文特意采用这种最简单的提示策略,以评估GPT-4“开箱即用”的基线性能。
- 校准度 (Calibration): 衡量模型预测的概率(置信度)与其实际正确率之间一致性的指标。在医学等高风险领域,良好的校准度至关重要,因为它意味着模型的置信度是可靠的。
- MELD (Memorization Effects Levenshtein Detector): 本文作者设计的一种启发式算法,通过探测模型能否以高相似度复现数据样本,来判断基准数据是否可能被模型在训练阶段“记忆”而非“理解”。
相关工作
长期以来,人工智能在医学领域的探索历经了从概率方法、专家系统到监督学习和深度学习的演进。近年来,大语言模型(LLMs)因其强大的自然语言处理能力,开始在医学领域展现潜力。
在本文之前,SOTA(State-of-the-Art)模型如Google的Flan-PaLM 540B,以及在其基础上针对医学领域进行提示调优的Med-PaLM,在MultiMedQA等医学问答基准上取得了领先成绩。然而,这些模型的优异表现通常依赖于复杂的提示工程(如思维链)或领域特定的微调。同时,研究界普遍存在一个关键问题:最前沿的通用大模型(如GPT-4)的原始能力究竟达到了何种水平?它们是否仅凭其巨大的规模和通用的预训练,就足以在专业的医学领域达到甚至超越经过专门优化的模型?
本文旨在解决这一具体问题:通过一套严格、全面的评估,确定GPT-4在不依赖复杂提示技巧或任何医学专业微调的情况下,在解决高难度医学挑战问题上的基线能力,并与之前的通用模型和专用模型进行直接比较。
本文方法
本文的核心是一种针对GPT-4医学能力的综合评估框架,而非提出一个全新的模型架构。其方法论的创新体现在评估的广度、深度和严谨性上。
评估对象与基准
- 核心评估模型: GPT-4的纯文本版本(GPT-4 no vision)。
- 对比模型: 其前代模型GPT-3.5,以及文献中报告的Flan-PaLM 540B和Med-PaLM等模型的性能数据。
- 核心数据集:
- 官方USMLE材料: 直接从美国国家医学考试委员会(NBME)购买的USMLE样题和自我评估题,覆盖了从 preclinical knowledge 到临床实践的所有三个步骤(Step 1, 2, 3),确保了评估的权威性和真实性。
- 公共医学基准: 包含MedQA、PubMedQA、MedMCQA和MMLU医学部分在内的MultiMedQA基准套件。
评估策略:简洁性与公平性
为测量模型最原始的能力,本文刻意采用了最简洁的提示方法:
- 零样本与随机5样本提示: 采用了[SAT+22]研究中完全相同的提示模板,确保了与先前工作的公平比较。在零样本设置中不提供任何范例,在5样本设置中则随机抽取5个例子作为提示。
- 避免高级技巧: 在核心性能测试中,有意排除了思维链(Chain-of-Thought)、检索增强生成(Retrieval Augmented Generation)或集成策略(Ensembling)等能显著提升性能但流程复杂的技巧。
创新点
本文方法的本质创新在于其多维度的评估视角,旨在全面剖析模型的真实能力及其在实际应用中的潜力与风险。
-
对含视觉信息问题的评估: 论文专门分析了纯文本模型在处理包含图表、照片等视觉媒体(模型无法看到)的题目时的表现。这揭示了模型仅通过文本描述进行逻辑推理和排除的能力。
-
模型校准度分析: 评估了模型输出答案的置信度是否可靠。通过绘制校准图,直观对比了GPT-4和GPT-3.5在“自信”与“正确”之间的关系,这对高风险应用至关重要。
-
记忆效应探测: 设计并使用了MELD算法,系统地检测模型在回答问题时是依赖于背诵训练数据中的答案,还是真正进行推理。这一举措增强了结论的有效性。
-
对齐调优的影响: 通过对比公开发布的、经过RLHF(Reinforcement Learning from Human Feedback)对齐微调的GPT-4与未对齐的内部基础模型(GPT-4-base),探究了为提升安全性而进行的微调对模型原始性能的潜在影响。
-
超越正确答案的定性探索: 通过一个案例研究,展示了GPT-4在交互式场景中的能力,包括:
- 解释性: 详细解释诊断的医学逻辑。
- 元认知 (Metacognition): 推断学生可能出现的错误思路。
- 反事实推理: 根据要求修改病例,创造新的学习场景。
实验结论
实验结果有力地证明了GPT-4在医学能力上的巨大飞跃。
在USMLE上的表现
GPT-4的性能远超前代模型和人类及格线。在官方USMLE样题和自评估测试中,GPT-4的平均准确率超过了86%,比约60%的及格分数线高出20多分,而GPT-3.5的得分则在50%-60%之间徘徊。
| USMLE自评估(准确率 %) | GPT-4 (5-shot) | GPT-4 (zero-shot) | GPT-3.5 (5-shot) | GPT-3.5 (zero-shot) |
|---|---|---|---|---|
| Step 1 | 85.21 | 83.46 | 54.22 | 49.62 |
| Step 2 | 89.50 | 84.75 | 52.75 | 48.12 |
| Step 3 | 83.52 | 81.25 | 53.41 | 50.00 |
| 总平均 | 86.65 | 83.76 | 53.61 | 49.10 |
| USMLE样题(准确率 %) | GPT-4 (5-shot) | GPT-4 (zero-shot) | GPT-3.5 (5-shot) | GPT-3.5 (zero-shot) | ChatGPT† (zero-shot) | | :— | :—: | :—: | :—: | :—: | :—: | | Step 1 | 85.71 | 80.67 | 52.10 | 51.26 | 55.1 | | Step 2 | 83.33 | 81.67 | 58.33 | 60.83 | 59.1 | | Step 3 | 90.71 | 89.78 | 64.96 | 58.39 | 60.9 | | 总平均 | 86.70 | 84.31 | 58.78 | 56.91 | – | † ChatGPT-3.5 数据引自 [KCM+23],设置与本文最相似。
语言与视觉问题的处理
一个令人惊讶的发现是,尽管无法看到题目中的图片(如X光片、病理图),纯文本的GPT-4在这些题目上依然取得了70-80%的准确率。这表明模型能够利用题目中的文本线索、病患历史和实验室数据进行有效的逻辑推理和排除,从而选出正确答案。
案例分析: 当被问及如何在没有看到照片的情况下回答一个需要看内窥镜照片的问题时,GPT-4解释道,仅根据问题中描述的“10年烧心史、夜间和食辣后加重、抗酸药可暂时缓解”等临床病史,就足以将最可能的原因锁定为“一过性下食管括约肌过度松弛”(GERD最常见病因),而照片只是用于确认诊断和评估并发症,并非选择最可能病因的必要条件。
对齐与安全调优的影响
实验发现,与公开发布的、经过RLHF安全对齐的GPT-4相比,未对齐的基础模型(GPT-4-base)在所有测试集上的性能有3-5%的轻微提升。这表明,为了确保模型的安全性和遵循指令的能力而进行的对齐过程,可能会对模型的原始基准测试性能产生一定的“折损”,这为未来如何在保证安全和维持性能之间取得更优平衡指明了研究方向。
在通用医学基准上的表现
在MultiMedQA的多个基准测试中,GPT-4同样展现了SOTA性能。无论是零样本还是少样本,GPT-4的得分都显著高于GPT-3.5,也超过了先前由专用模型Med-PaLM(一种经过复杂提示工程优化的模型)创下的记录。
| 数据集 | GPT-4 (5-shot / 0-shot) | GPT-3.5 (5-shot / 0-shot) | Flan-PaLM 540B* (few-shot) | | :— | :— | :— | :— | | MedQA (US 4-option) | 81.38 / 78.87 | 53.57 / 50.82 | 60.3** | | PubMedQA | 74.40 / 75.20 | 60.20 / 71.60 | 79.0 | | MedMCQA | 72.36 / 69.52 | 51.02 / 50.08 | 56.5 | | MMLU (Professional Medicine) | 93.75 / 93.01 | 69.85 / 70.22 | 83.8 | * 数据来自 [SAT+22]。 ** [SAT+22] 报告称,使用复杂提示的Med-PaLM在此数据集上取得了67.2%的成绩,而GPT-4仅用零样本提示就达到了78.87%。
模型校准度分析
GPT-4的校准度相较于GPT-3.5有了显著改善。如下图所示,GPT-4的预测概率(x轴)与其实际正确率(y轴)非常接近理想的对角线。例如,当GPT-4认为答案正确的概率约为0.96时,它的实际正确率高达93%。相比之下,当GPT-3.5给出相似的置信度时,其实际正确率仅为55%。这种可靠的置信度评估对于在医疗等高风险决策中提供辅助至关重要。
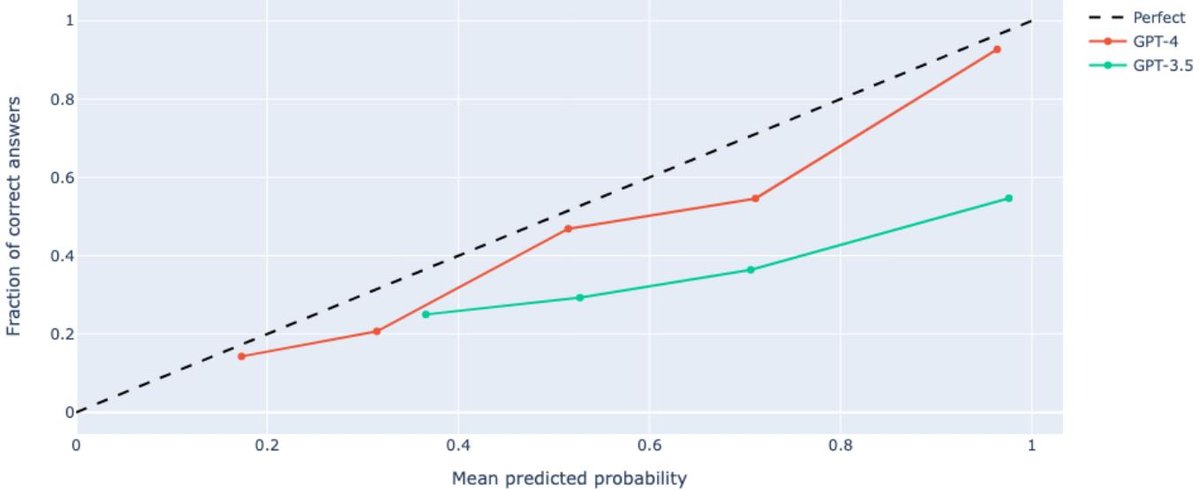 图:GPT-4(蓝色)的校准曲线比GPT-3.5(橙色)更接近理想的对角线,表明其置信度更可靠。
图:GPT-4(蓝色)的校准曲线比GPT-3.5(橙色)更接近理想的对角线,表明其置信度更可靠。
其他发现与局限性
- 记忆效应: 使用MELD算法进行检测,未在官方USMLE数据集中发现明显的记忆痕迹,表明GPT-4的优异表现更可能源于其泛化的推理能力而非死记硬背。
- 提示工程: 初步实验表明,简单的思维链提示或专家挑选的少样本范例对GPT-4的性能提升不明显。这可能意味着对于能力极强的模型,传统的提示技巧收益递减,需要探索新的交互模式。
- 局限性: 本文的评估主要集中在多项选择题,未涵盖USMLE Step 3中的交互式病例模拟(CCS)部分。此外,基准测试的性能不完全等同于在复杂、动态的真实世界临床环境中的表现。
总结
GPT-4在医学能力方面取得了突破性进展,其“开箱即用”的性能达到了专家级水平。这为模型在医学教育、知识检索和临床辅助方面展现了巨大潜力。尽管如此,本文同样强调,从基准测试的成功到安全、可靠的真实世界应用,仍有大量工作要做,必须始终保持谨慎,并以人类专家的监督为核心。