Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
-
ArXiv URL: http://arxiv.org/abs/2403.04132v1
-
作者: Joseph Gonzalez; Ying Sheng; Banghua Zhu; Michael Jordan; Wei-Lin Chiang; Anastasios Nikolas Angelopoulos; Tianle Li; Lianmin Zheng; Dacheng Li; Ion Stoica; 等1人
-
发布机构: Stanford; University of California, Berkeley; University of California, San Diego
TL;DR
本文介绍并验证了一个名为 Chatbot Arena 的开放平台,该平台通过众包用户的成对比较和偏好投票,来评估和排名大型语言模型(LLM),并为此设计了一套高效、可靠的统计方法论。
关键定义
本文沿用了现有统计学模型,并基于其评估框架提出了一些关键概念:
- Chatbot Arena: 一个开放的、通过众包方式评估 LLM 的基准测试平台。其核心机制是让用户与两个匿名的 LLM 进行对话“对战”(Battle),然后投票选出更优的回答。这种方式可以收集到反映真实世界使用场景的、鲜活多样的用户提示和人类偏好数据。
-
Bradley-Terry (BT) 模型: 一种用于成对比较数据分析的经典统计模型。本文使用它来估计每个 LLM 的潜在“实力”分数(即 BT 系数,\(ξ\))。模型假设,模型 \(m\) 战胜模型 \(m'\) 的概率可以通过它们实力分数的差异来建模:
\[\mathbb{P}(H_{t}=1)=\frac{1}{1+e^{\xi_{m'}-\xi_{m}}}\]其中 \(H_t=1\) 表示模型 \(m\) 在该次对战中获胜。通过最大似然估计法可以求解出所有模型的 \(ξ\) 值,从而得到排名。
-
近似排名 (Approximate Ranking): 考虑到评估数据中的统计不确定性,本文不直接给出单一的排名数值,而是计算每个模型实力分数的置信区间。一个模型的“近似排名”定义为:其实力分数置信区间的下限(infimum)低于其他模型置信区间上限(supremum)的模型的数量加一。这种方法可以更稳健地判断模型间的性能差异。
\[R_{m}=1+\sum_{m^{\prime}\in[M]}\mathds{1}\left\{\inf\mathcal{C}_{m^{\prime}}> \sup\mathcal{C}_{m}\right\}\] - 主动采样 (Active Sampling): 为了提高数据收集效率,平台采用的一种非随机的模型配对策略。该策略会优先选择那些对缩小排名置信区间最有效的模型对进行“对战”,从而用更少的投票数据更快地获得稳定的排名结果。
相关工作
当前 LLM 的评估基准主要分为四类,由问题来源(静态数据集 vs. 实时来源)和评估指标(基于标准答案 vs. 基于人类偏好)两个维度决定。
 图1:LLM基准测试分类:我们沿两个维度进行分类:问题是来自静态数据集还是实时的、新鲜的来源;评估指标是依赖于标准答案还是(近似的)人类偏好。MMLU、HellaSwag、GSM-8K、MT-Bench 和 AlpacaEval 是静态基准的常见例子。Chatbot Arena 是本文介绍的平台。
图1:LLM基准测试分类:我们沿两个维度进行分类:问题是来自静态数据集还是实时的、新鲜的来源;评估指标是依赖于标准答案还是(近似的)人类偏好。MMLU、HellaSwag、GSM-8K、MT-Bench 和 AlpacaEval 是静态基准的常见例子。Chatbot Arena 是本文介绍的平台。
目前最主流的评估方法是基于静态数据集和标准答案的基准测试(如 MMLU, GSM-8K),因为它们成本低且可复现。然而,这类基准存在明显瓶颈:
- 问题非开放性:无法捕捉真实世界中灵活、交互式的使用场景。
- 数据集静态:测试集可能会随着时间推移被“污染”(模型在训练数据中见过),导致评估结果不可靠。
- 缺乏标准答案:对于许多复杂的、创造性的任务,很难甚至不可能定义唯一的“标准答案”。
- 无法对齐人类偏好:评估结果无法直接反映模型是否符合用户的真实偏好。
因此,业界迫切需要一个开放的、实时的、基于人类偏好的评估平台。本文提出的 Chatbot Arena 正是为了解决以上问题,旨在创建一个能更准确反映真实世界使用情况和用户偏好的 LLM 评估生态系统。
本文方法
平台设计与数据收集
Chatbot Arena 的核心是一个众包评估网站。
- 界面与流程:用户进入网站后,可以输入任意提示词。系统会随机抽取两个匿名模型(例如模型A和模型B)同时生成回答。用户在并排比较两个回答后,投票选出更喜欢的一个,也可以选择“平局”或“两者都很差”。只有在投票之后,模型的真实身份才会被揭晓。
- 数据统计:自2023年4月运行以来,截至2024年1月,平台已收集了来自约9万名用户的超过24万次投票,涵盖了50多个主流的闭源和开源模型。数据覆盖超过100种语言,其中英语占77%,中文占5%。
| 数据集 | 对话数 | 模型数 | 用户数 | 语言数 | 平均轮次 | 平均每样本Token数 | 平均每提示Token数 | 平均每响应Token数 |
|---|---|---|---|---|---|---|---|---|
| Anthropic HH | 338,704 | - | 143 | 1 | 2.3 | 18.9 | 78.9 | |
| OpenAssistant | 66,497 | - | 13,500 | 35 | - | 36.9 | 214.2 | |
| Chatbot Arena | 243,329 | 50 | 90,051 | 149 | 1.3 | 94.9 | 269.0 |
表1:人类偏好数据集统计
排名系统
从成对比较到排名
收集到的数据是成对的胜负关系,为了得到全局排名,本文采用了 Bradley-Terry (BT) 模型。该模型为每个模型 \(m\) 估计一个潜在的实力分数 \(ξ_m\)。通过对所有投票数据进行最大似然估计,可以求解出所有模型的 BT 系数,这些系数即作为模型的最终得分,得分越高,排名越靠前。该方法的一个重要优点是,即使模型的参数假设不完全成立,只要使用所谓的“三明治”协方差矩阵(”sandwich” covariance matrix),估计结果在渐近意义上仍然是有效的。
高效近似排名
为确保排名的统计可靠性并提高效率,本文设计了以下算法:
- BT 分数估计与置信区间:通过对收集到的数据进行加权最大似然估计来计算 BT 分数。同时,为了量化不确定性,本文计算了每个模型分数的置信区间。
- 近似排名:基于置信区间,本文提出了“近似排名”的概念。只有当一个模型的置信区间完全高于另一个模型时,才能确定性地认为前者优于后者。这避免了因数据波动而导致的排名频繁变动。
-
主动采样规则:为了加速排名收敛,平台不采用完全随机的模型配对。它会根据一个主动采样公式,优先选择那些对缩小当前排名不确定性最有帮助的模型对进行对战。公式如下:
\[P_{t}(a)\propto\sqrt{\frac{\hat{\Sigma}_{t,a,a}}{ \mid \{t:A_{t}=a\} \mid }}-\sqrt{\frac{\hat{\Sigma}_{t,a,a}}{ \mid \{t:A_{t}=a\} \mid +1}}\]该规则旨在最大化每次投票带来的信息增益。
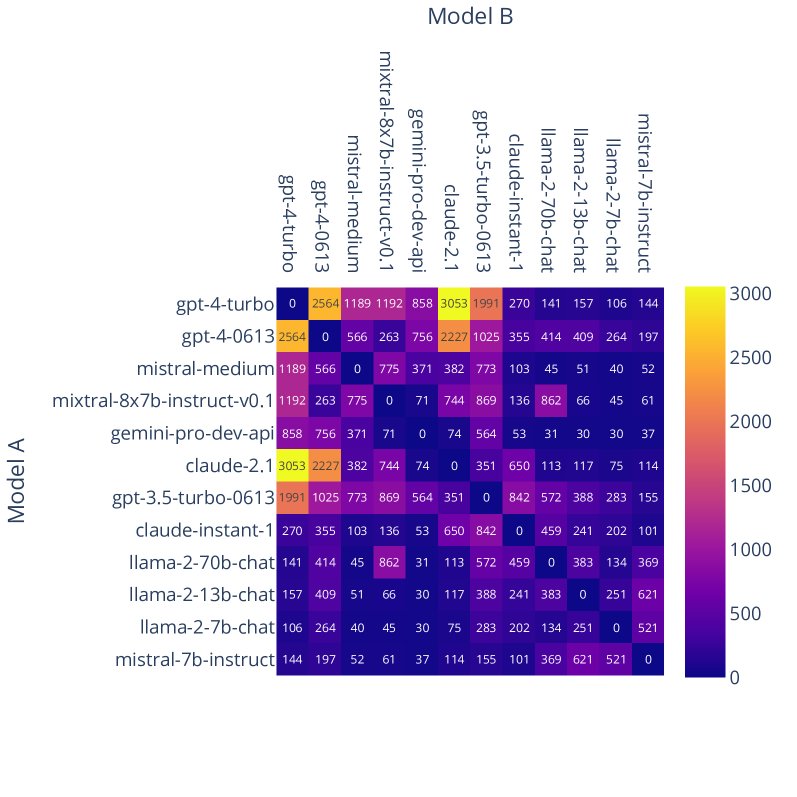 图2:Chatbot Arena 中部分模型的胜率(左)和对战次数(右)。右图显示了非均匀采样,系统会集中在表现相似的模型对上进行更多对战。
图2:Chatbot Arena 中部分模型的胜率(左)和对战次数(右)。右图显示了非均匀采样,系统会集中在表现相似的模型对上进行更多对战。
异常用户检测
为了保证数据质量,本文还提出了一种检测异常用户(如机器人或恶意用户)的方法。该方法通过比较单个用户投票行为与历史数据分布的差异来计算 p-value,并使用 Fisher’s 组合检验来判断用户行为是否异常。
实验结论
数据质量分析
- 提示多样性:通过对用户提示进行主题建模,发现了超过600个不同的主题聚类,最大的聚类仅占总数的1%,表明用户提示覆盖了极其广泛和长尾的真实世界应用场景。
- 提示区分度:Arena 的提示能够有效区分不同模型的强项。例如,在“Python游戏编程”、“C++多线程”等编码和推理任务上,GPT-4 的胜率远高于 Llama-2-70b-chat(高达97%);而在“电影推荐”、“旅行规划”等开放性任务上,两者差距则显著缩小。
- 构建 Arena Bench:利用 Arena 的高质量提示,本文构建了一个新的、更具挑战性的基准 Arena Bench。与 MT-Bench 相比,Arena Bench 能更显著地揭示顶级闭源模型与最强开源模型之间的性能差距。
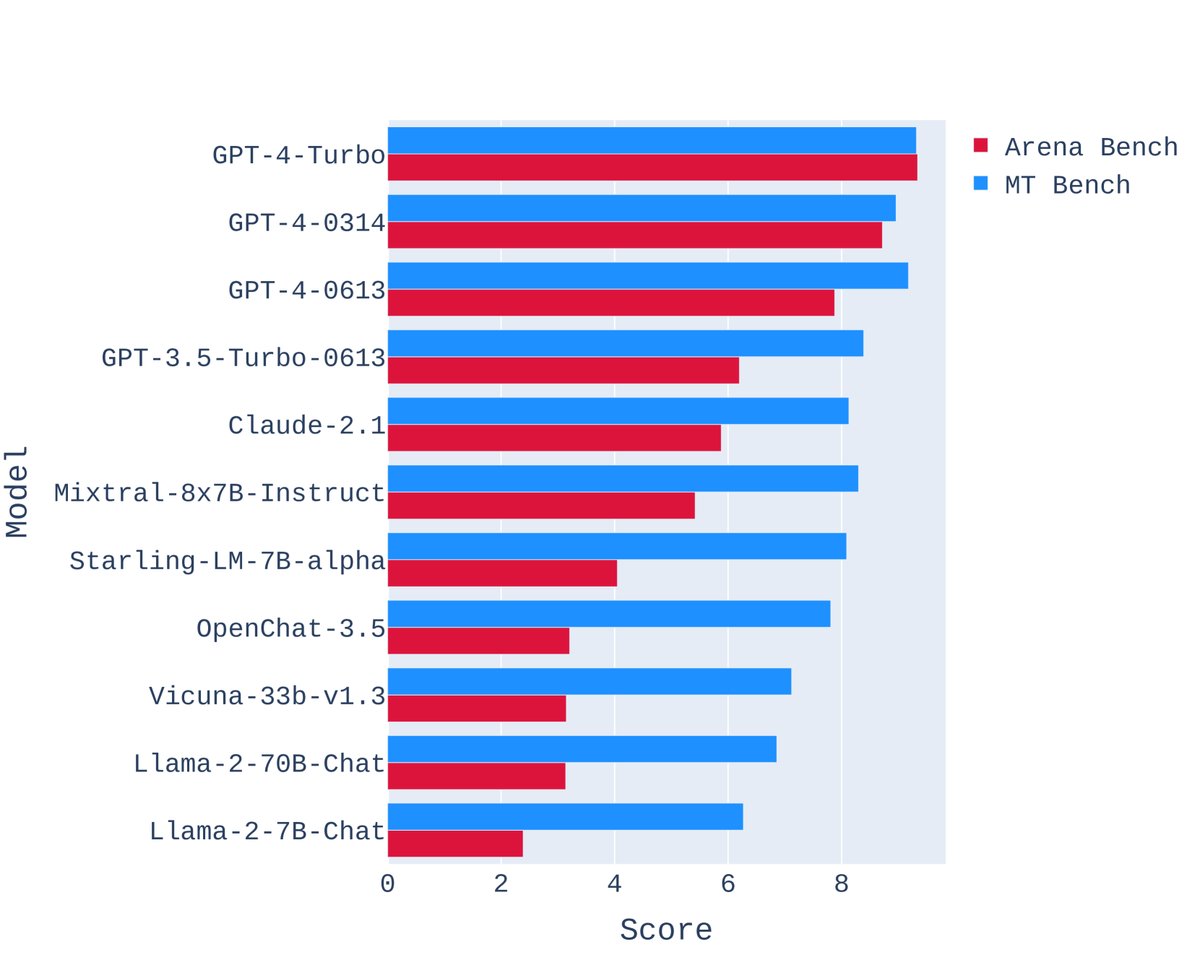 图4:模型在 Arena Bench 和 MT-Bench 上的表现,显示开源模型和闭源模型之间的差距增大。
图4:模型在 Arena Bench 和 MT-Bench 上的表现,显示开源模型和闭源模型之间的差距增大。 - 投票质量验证:将部分众包投票数据与专家标注进行对比,发现众包用户与专家的一致性高达72%-83%。这一比例与专家之间的一致性(约80%-90%)相近,有力地证明了众包投票的可靠性。
| (GPT-4-Turbo vs. Llama-2-13b) | 专家 1 | 专家 2 | GPT-4 |
|---|---|---|---|
| 众包用户 | 72.8% | 77.8% | 75.6% |
| 专家 1 | - | 89.8% | 81.0% |
表3(部分):众包用户、GPT-4评委和专家在成对对战中的一致率
排名系统评估
- 排名系统有效性:在超过21万次真实投票数据上运行排名算法,成功计算出各模型的 BT 分数及置信区间,生成了稳定的排行榜。模拟实验也验证了置信区间的覆盖率符合预期。
- 主动采样的优越性:模拟实验表明,主动采样规则比随机采样更具样本效率。例如,在估计胜率矩阵时,为达到相同的精度,随机采样需要6800个样本,而主动采样仅需4400个,节省了约54%的数据。
- 异常用户检测有效性:在手动标记的测试集上,异常用户检测方法表现良好,例如在 α=0.3 时,真阳性率达到90%,假阳性率较低。
总结
本文成功构建并验证了 Chatbot Arena 这一创新的 LLM 评估平台。研究表明,通过众包、成对比较和先进的统计方法,可以有效、高效地收集高质量的人类偏好数据,并生成比传统静态基准更能反映真实世界性能的 LLM 排行榜。该平台已成为 LLM 领域一个被广泛引用的重要基准。