CODA: Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent with Decoupled Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2508.20096v1
-
作者: Jiaqi Wang; Qiushi Sun; Dahua Lin; Ziyu Liu; Yuhang Cao; Zeyi Sun; Zhixiong Zhang; Xiaoyi Dong; Yuhang Zang; Kai Chen
-
发布机构: Shanghai AI Laboratory; Shanghai Jiao Tong University; The Chinese University of Hong Kong; The University of Hong Kong
TL;DR
本文提出了一种名为 CODA 的可训练组合式智能体框架,它模仿人脑的大脑与小脑功能分离机制,通过解耦的强化学习和两阶段训练流程,协同一个通用规划器(大脑)和一个专用执行器(小脑),以有效解决科学计算等专业领域中长时序规划与精确GUI操作的挑战。
关键定义
- CODA框架: 一个受人脑双脑结构启发的、可训练的组合式智能体框架,全称为“为双脑计算机使用智能体协同大脑与小脑”(Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent)。它将智能体的能力解耦为规划和执行两个模块。
- 规划器 (Planner / Cerebrum): 框架中的“大脑”,由一个大型视觉语言模型(如 Qwen2.5-VL)充当。它负责高层次的战略思考,根据历史交互和当前屏幕截图生成指导下一步行动的“想法”(thought)。
- 执行器 (Executor / Cerebellum): 框架中的“小脑”,由一个擅长GUI操作的模型(如 UI-TARS-1.5)充当。它负责将规划器生成的抽象想法转化为精确、可执行的底层GUI动作(如 \(pyautogui\) 命令)。
- 解耦强化学习 (Decoupled Reinforcement Learning): 一种新颖的训练策略,在训练过程中,保持执行器模型固定不变,仅通过与环境交互产生的奖励信号来更新和优化规划器模型。这种方法能更高效地提升智能体的规划能力,而无需重新训练已经很强大的执行模块。
相关工作
当前用于图形用户界面(Graphical User Interfaces, GUIs)的自主智能体在处理科学计算等专业领域任务时面临一个核心困境。一方面,通用型智能体(Generalist agents)虽然具备强大的长时序规划能力,但在需要精确定位的GUI操作上表现不佳。另一方面,专用型智能体(Specialized agents)精于精确执行,但其复杂规划能力有限。
为了解决这一矛盾,研究界开始探索组合式框架,将“规划器”与“执行器”解耦。然而,这些早期的框架大多是静态且不可训练的,通常依赖于强大的闭源模型作为规划核心。这种设计的缺陷是显而易见的:它不仅降低了研究的透明度和可复现性,更关键的是,它使得智能体无法从经验中学习和适应,这在缺乏高质量标注数据的专业软件领域是一个致命的限制。
本文旨在解决上述问题,即如何构建一个可训练的、能够从与环境的交互中学习并适应新软件的组合式智能体框架。
本文方法
本文提出了CODA框架,该框架受人脑功能分区启发,构建了一个“规划器-执行器”双脑结构,并通过一个创新的两阶段训练流程进行优化。
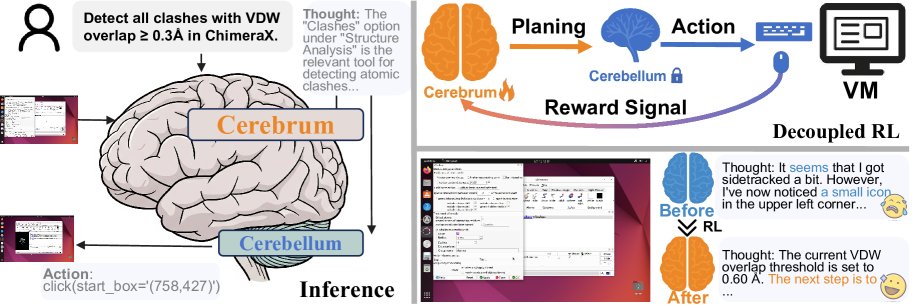 图1: 所提出的可学习的“规划器-执行器”框架的整体架构。类似于人脑中大脑和小脑的关系,规划器(大脑)根据历史和屏幕截图生成高层想法,而执行器(小脑)则相应地执行具体的GUI操作。
图1: 所提出的可学习的“规划器-执行器”框架的整体架构。类似于人脑中大脑和小脑的关系,规划器(大脑)根据历史和屏幕截图生成高层想法,而执行器(小脑)则相应地执行具体的GUI操作。
核心架构
该框架将智能体的决策过程解耦为两个协同工作的模块:
-
规划器 (Planner): 使用 Qwen2.5-VL 模型,负责战略规划。在每个时间步 \(t\),它接收交互历史 \(m_{t-1}\)、当前及上一帧的视觉观察 \(o_t\) 和 \(o_{t-1}\),输出一个结构化的想法 \(p_t\),该想法明确了当前步骤的目标和要交互的UI元素。
\[p_t = \text{Planner}(m_{t-1}, o_{t-1}, o_t)\] -
执行器 (Executor): 使用 UI-TARS-1.5 模型,负责将规划器的抽象想法转化为具体行动。它接收与规划器相同的上下文信息,并额外接收规划器生成的想法 \(p_t\),最终输出一个如 \(click(x, y)\) 的底层 \(pyautogui\) 命令 \(a_t\)。
\[a_t = \text{Executor}(m_{t-1}, o_{t-1}, o_t, p_t)\]
两阶段训练流程
本文设计了一个从“专用化”到“泛化”的两阶段训练课程。
 图2: 所提出的“规划器-执行器”框架的整体训练过程。规划器根据历史和截图生成高层想法,而执行器则相应地执行具体的GUI操作。在训练期间,奖励根据动作 \(a^{(i)}\) 计算,并应用于想法 \(p^{(i)}\) 以计算损失。
图2: 所提出的“规划器-执行器”框架的整体训练过程。规划器根据历史和截图生成高层想法,而执行器则相应地执行具体的GUI操作。在训练期间,奖励根据动作 \(a^{(i)}\) 计算,并应用于想法 \(p^{(i)}\) 以计算损失。
阶段一:通过解耦强化学习实现专用化
此阶段的目标是为每个独立的软件应用训练一个专门的、高性能的规划器。 创新点:
- 解耦训练: 实验发现,执行器本身已具备很强的泛化能力,而规划器是性能瓶颈。因此,本文采取解耦强化学习策略,只对规划器进行优化,而执行器保持固定。这极大地提升了数据效率和训练稳定性。
- GRPO算法应用: 考虑到初始规划器较弱,成功轨迹稀少,本文采用了组相对策略优化 (Group Relative Policy Optimization, GRPO) 算法。该算法通过比较一组 \(G\) 个候选计划的相对好坏来产生有效的学习信号,即使在大多数尝试都失败的情况下也能进行学习。
-
复合奖励函数: 为了提供细粒度的奖励信号,本文设计了一个复合奖励函数 \(r\),它结合了动作类型的正确性(二元奖励)和动作参数的精确度(如坐标的L1距离或边界框的IoU),如下所示:
\[r^{(i)} = r(a^{(i)}, a_T) = \mathbb{I}(\text{type}(a^{(i)}) = \text{type}(a_T)) + r_{\text{dist}}(a^{(i)}, a_T)\]其中 \(a^{(i)}\) 是生成的动作,\(a_T\) 是正确的动作。
-
GRPO损失函数: 根据奖励计算每个计划的相对优势 \(A^{(i)}\),并应用到GRPO损失函数 \(L_{\text{GRPO}}\) 中来更新规划器策略 \(\pi_\theta\)。
\[A^{(i)} = \frac{r^{(i)} - \text{mean}(\{r^{(j)}\}_{j=1}^{G})}{\text{std}(\{r^{(j)}\}_{j=1}^{G})}, \quad i=1,\cdots,G.\] \[\begin{aligned} \mathcal{L}_{\text{GRPO}}(\pi_\theta) = -\mathbb{E}_{(s,I)\sim\mathcal{D},\{a^{(i)}\}_{i=1}^{G}\sim\pi_{\text{ref}}(\cdot\mid s,I)} \Bigg{[} \frac{1}{G}\sum_{i=1}^{G}\frac{1}{ \mid p^{(i)} \mid } \sum_{t=1}^{ \mid p^{(i)} \mid } \Big{\{} \min\Big{(} r_t^{(i)}(\theta)A^{(i)}, \\ \text{clip}(r_t^{(i)}(\theta), 1-\epsilon, 1+\epsilon)A^{(i)} \Big{)} - \beta\,D_{\text{KL}}^{(i,t)}(\pi_\theta\ \mid \pi_{\text{ref}}) \Big{\}} \Bigg{]} \end{aligned}\]这个优势被施加到计划 \(p^{(i)}\) 中所有的推理 token 上,以鼓励模型生成更鲁棒、更自由的规划内容。
阶段二:通过聚合式监督微调实现泛化
此阶段遵循“从专家到通才”的范式,旨在训练一个通用的、跨软件的规划器。 流程:
- 教师模型: 利用第一阶段为四种不同软件训练出的四个“专家规划器”作为教师。
- 数据生成: 每个专家规划器在其对应的软件上生成大量成功的交互轨迹。
- 聚合与微调: 将所有专家生成的、高质量的成功轨迹聚合起来,形成一个丰富的数据集。
- SFT训练: 在这个聚合的数据集上,对一个新的通用规划器(同样从Qwen2.5-VL初始化)进行监督微调 (Supervised Fine-Tuning, SFT)。
最终得到的通用规划器不仅在各项任务上超越了单个专家教师,还表现出更强的跨软件领域知识和规划能力。
自动化探索流程
为了支持上述训练流程,本文建立了一个高效的自动化数据收集与标注流程。
- 自动化任务生成: 使用强大的 Qwen2.5-72B 模型,基于少量人工示例自动生成大量新的高级任务。
- 自动化评判系统: 构建了一个评判系统,能够自动评估智能体执行任务的轨迹是否成功,并标注出其中正确的动作,为强化学习提供奖励信号,为SFT提供高质量数据。
- 分布式虚拟机系统: 建立了一个基于HTTP的“主-从”架构的分布式系统,允许在数百个虚拟机中并行执行任务和收集数据,极大地加速了训练数据的准备过程。
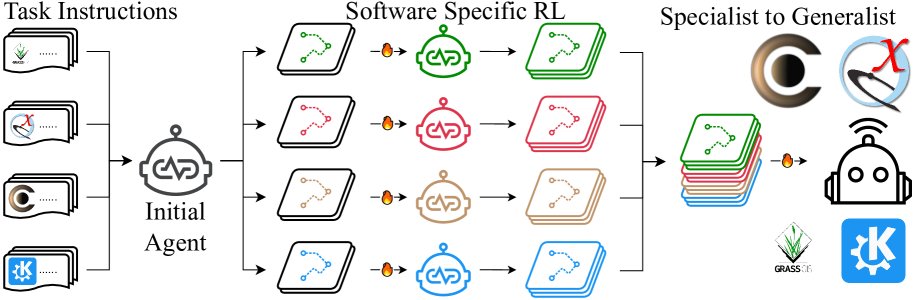 (a) 从专家到通才策略
(a) 从专家到通才策略
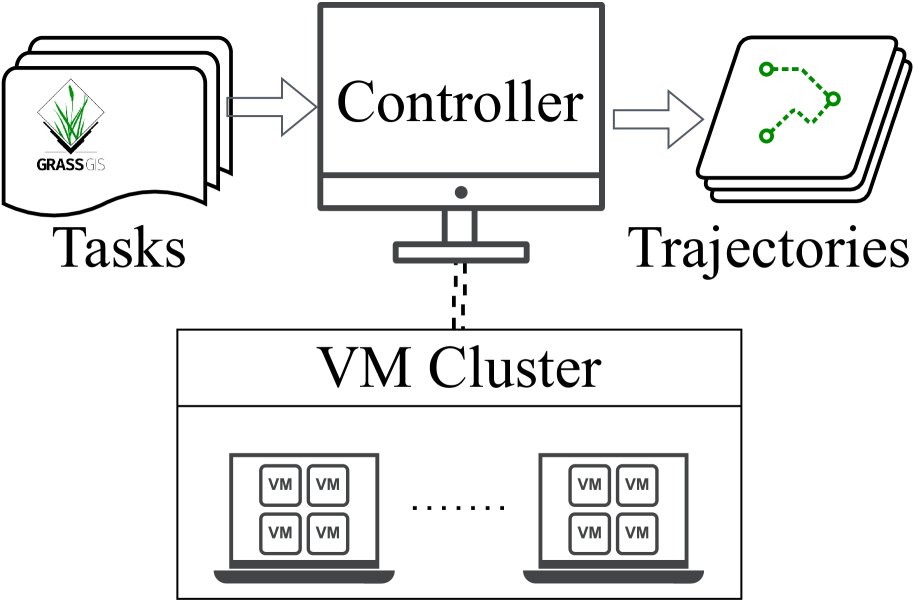 (b) 分布式虚拟机系统
(b) 分布式虚拟机系统
图3: 用于支持训练的探索流程。
实验结论
本文在 ScienceBoard 基准测试中的四个具有挑战性的科学软件应用上验证了 CODA 框架的有效性。
关键实验结果:
-
大幅性能提升: 如表1所示,与基线模型(规划器:Qwen2.5-VL-32B,执行器:UI-TARS-1.5-7B)相比,CODA 取得了显著的性能提升。基线模型的总体 Pass@8 成功率为 19.49%,而 CODA Stage-1(专家模型集成)和 Stage-2(通用模型)分别达到了 32.12% 和 39.96%。
-
新的开源SOTA: CODA Stage-2 模型在整体性能上不仅超越了所有基线模型和专家模型,还超过了同期其他开源方法,甚至与一些强大的闭源模型(如 Claude-3.7-Sonnet)的表现相当或更优,从而在 ScienceBoard 基准上建立了新的开源SOTA(State-of-the-Art)。
-
专用化到泛化的有效性: CODA Stage-2 的通用模型性能(21.04% Average@1)全面超越了 Stage-1 的专家模型集成(14.39% Average@1),证明了“从专家到通才”的训练策略能够有效整合多个领域的知识,产生一个能力更强、更通用的规划器。
-
精确的评判系统: 如表2所示,通过引入投票、多分辨率输入和模型集成等策略,评判系统的精确度在 ScienceBoard 数据集上从41.5%提升至69.5%,这为强化学习提供了高质量的奖励信号,是训练成功的关键保障。
表1: 各模型在 ScienceBoard 上的成功率。专有模型和基于开源模型的方法分别用紫色和绿色背景高亮。*表示分别在各软件上训练的专家智能体的集成结果。
| 指标 | 模型 | Algebra | Biochem | GIS | Astron | 总体 |
|---|---|---|---|---|---|---|
| 成功率 ($\uparrow$) | ||||||
| Average@1 | GPT-4o (OpenAI, 2023) | 3.23% | 0.00% | 0.00% | 0.00% | 0.81% |
| Claude-3.7-Sonnet (Anthropic, 2025) | 9.67% | 37.93% | 2.94% | 6.06% | 14.15% | |
| Gemini-2.0-Flash (Team et al., 2023) | 6.45% | 3.45% | 2.94% | 6.06% | 4.73% | |
| GPT4o$\xrightarrow{}$UGround-V1-7B (Gou et al., 2024) | 0.00% | 3.45% | 0.00% | 3.03% | 1.62% | |
| GPT4o$\xrightarrow{}$OS-Atlas-Pro-7B (Wu et al., 2024b) | 6.25% | 10.34% | 0.0% | 3.03% | 4.92% | |
| GPT4o$\xrightarrow{}$UI-TARS-72B (Qin et al., 2025) | 3.23% | 10.34% | 5.88% | 6.06% | 6.38% | |
| Qwen2.5-VL-72B (Bai et al., 2025) | 22.58% | 27.59% | 5.88% | 9.09% | 12.94% | |
| InternVL3-78B (Zhu et al., 2025) | 6.45% | 3.45% | 0.00% | 0.00% | 2.69% | |
| UI-TARS-1.5-7B (Qin et al., 2025) | 12.90% | 13.79% | 0.00% | 6.06% | 8.19% | |
| Average@8 | Qwen2.5-VL-32B (Bai et al., 2025) | 10.48% | 13.79% | 1.47% | 4.55% | 7.57% |
| UI-TARS-1.5-7B (Qin et al., 2025) | 6.49% | 10.24% | 0.80% | 3.03% | 5.14% | |
| CODA (Stage-1)* | 13.71% | 26.29% | 7.72% | 9.85% | 14.39% | |
| CODA (Stage-2) | 20.16% | 32.23% | 14.71% | 17.05% | 21.04% | |
| Pass@8 | Qwen2.5-VL-32B (Bai et al., 2025) | 29.03% | 31.03% | 8.82% | 9.09% | 19.49% |
| UI-TARS-1.5-7B (Qin et al., 2025) | 19.35% | 24.14% | 5.88% | 12.12% | 15.36% | |
| CODA (Stage-1)* | 41.94% | 44.83% | 23.53% | 18.18% | 32.12% | |
| CODA (Stage-2) | 48.39% | 51.72% | 29.41% | 30.30% | 39.96% |
表2: 不同评判方法在 AgentRewardBench 和 ScienceBoard 上的评估。
| 方法 | AgentRewardBench | ScienceBoard | ||
|---|---|---|---|---|
| 精确率 | 召回率 | 精确率 | 召回率 | |
| Qwen2.5-VL-72B-single | 64.5 | 83.4 | 41.5 | 80.1 |
| 72B-GUI-Judge | 73.5 | 79.0 | 43.7 | 80.1 |
| 72B-voting@4 | 76.1 | 79.5 | 58.6 | 75.3 |
| 72B-voting@4 w/ multi-res | 78.9 | 77.4 | 65.7 | 77.9 |
| 72B-voting@4 Ensemble | 81.2 | 76.8 | 69.5 | 74.2 |
最终结论:本文提出的受大脑启发的、可训练的“规划器-执行器”解耦框架是成功的。通过将稳定的执行模块与可自适应的规划模块相结合,并辅以高效的、基于强化学习的探索和数据生成流程,该方法有效解决了在复杂GUI环境中进行长时序规划的难题,为开发更强大、更具适应性的GUI智能体开辟了新的道路。