Continual Learning via Sparse Memory Finetuning
-
ArXiv URL: http://arxiv.org/abs/2510.15103v1
-
作者: Gargi Ghosh; Jessy Lin; Luke Zettlemoyer; Barlas Oğuz; Vincent-Pierre Berges
-
发布机构: Meta; University of California, Berkeley
TL;DR
本文提出了一种名为稀疏内存微调(sparse memory finetuning)的方法,通过仅更新与新知识高度相关的、利用TF-IDF筛选出的极少数内存槽位,使大型语言模型在学习新知识的同时,显著减少了灾难性遗忘。
关键定义
本文方法建立在现有内存层模型的基础上,并提出了新的微调策略。
- 内存层 (Memory Layers):一种神经网络模块,它用一个可查询的、包含大量可训练参数(键 \(K\) 和值 \(V\))的内存池,来替换或增强标准 Transformer 中的前馈网络(FFN)。在前向传播时,模型会根据输入查询 \(q(x)\),通过注意力机制从内存池中检索最高相关的Top-k个键值对,从而生成输出。这可以被看作是一种拥有大量微小专家(每个内存槽位都是一个专家)的混合专家模型(MoE)。
- 稀疏内存微调 (Sparse Memory Finetuning):本文提出的核心方法。它并非简单地微调内存层,而是一种更具选择性的更新策略。具体而言,在每个训练批次上,该方法首先计算所有被访问内存槽位的 TF-IDF 分数,然后仅对分数最高的 \(t\) 个内存槽位进行梯度更新。这一过程确保了只有对当前新知识“特异性”最强的参数被修改。
- TF-IDF 排名 (TF-IDF Ranking):用于筛选待更新内存槽位的核心机制。它通过一个分数来衡量一个内存索引 \(i\) 对于当前批次(batch)的重要性。该分数由两部分组成:\(TF\)(词频)代表索引 \(i\) 在当前批次中被访问的频率;\(IDF\)(逆文档频率)代表索引 \(i\) 在一个固定的“背景语料库”(如预训练数据)中被访问的普遍程度。高 TF-IDF 分数意味着该索引在当前批次中频繁出现,但在通用数据中却很罕见,因此被认为是“特异性”强的。
相关工作
当前人工智能领域的一个长期目标是实现持续学习(continual learning)或终身学习,即模型能够随着时间不断积累新知识和技能。然而,一个巨大的障碍是灾难性遗忘(catastrophic forgetting):当模型在新的数据流上更新时,它往往会丢失之前获得的能力。
现有的解决方案主要有:
- 正则化方法:如弹性权重巩固(EWC),通过惩罚项来限制对“重要”参数的修改。但本文方法通过完全稀疏化的更新来实现,而非施加正则化惩罚。
- 扩展性方法:如 Adapter、LoRA 或为每个任务添加新的MoE专家。这些方法虽然能减少遗忘,但通常学习能力也较弱,且增加的参数容量有限。本文方法则利用了内存层巨大的总容量,通过稀疏访问实现了容量和遗忘之间的平衡。
- 重放方法:在训练新任务时,混合旧任务或预训练数据进行“排练”。这种方法数据效率低下,且随着模型经验的增加,维护和重放的数据量会变得难以管理。
本文旨在解决的问题是:如何在不依赖数据重放、不过度限制模型容量的前提下,让语言模型持续吸收新知识,同时最大限度地保留其原有的通用能力。本文的核心思路是利用稀疏性,即每次更新只修改与新知识最直接相关的极小一部分参数。
本文方法
本文提出的稀疏内存微调 (Sparse Memory Finetuning) 是一种针对内存增强型语言模型的持续学习策略。其核心设计思想是通过极度稀疏的参数更新来隔离新旧知识,从而避免相互干扰。
背景:内存层
本文方法建立在内存层(Memory Layers)架构之上。内存层使用一个大型的、可训练的键值对内存池(\(K\) 和 \(V\))来替代 Transformer 中的部分前馈网络(FFN)。对于每个输入 Token,模型会生成一个查询向量,并用它从内存池中检索 \(k\) 个最相似的键,然后将对应的 \(k\) 个值加权求和,作为该层的输出。
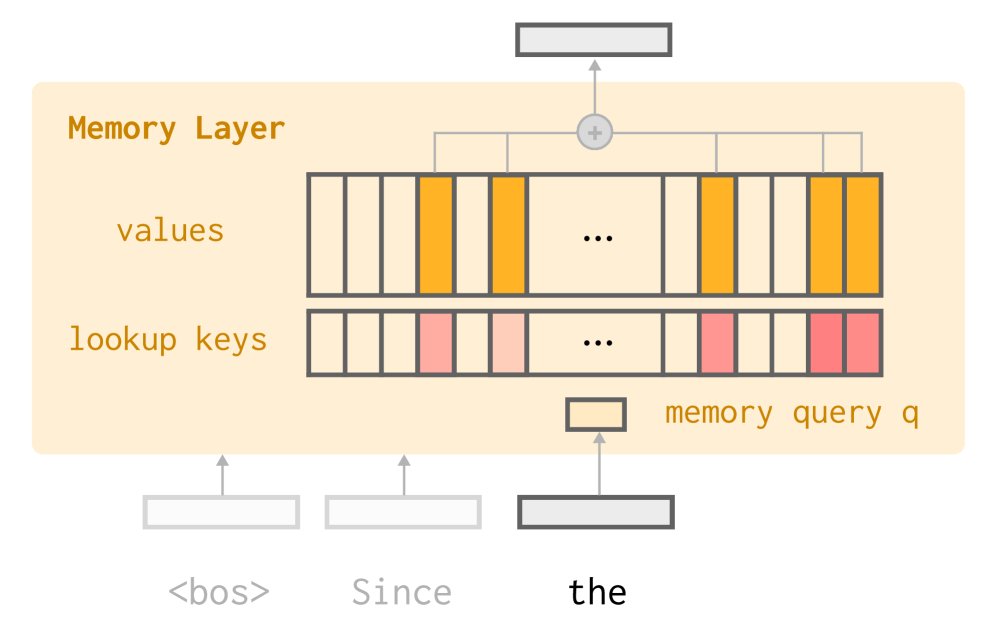
与标准注意力机制不同,内存层的 \(K\) 和 \(V\) 是可训练的参数,而非由输入动态生成的激活值。这使得内存层成为存储知识的理想场所。同时,由于每次前向传播只访问 \(k\) 个内存槽(例如,\(k=32\),而总内存槽数可达百万级),这种架构天然地具有稀疏访问的特性。
创新点:基于 TF-IDF 的稀疏更新
虽然内存层访问是稀疏的,但研究发现,如果简单地微调所有被访问到的内存槽位,模型仍然会发生灾难性遗忘。这是因为许多被访问的槽位可能存储的是通用知识(如语法结构),而非特定于新信息的知识。
本文的核心创新在于提出了一种更智能的更新策略:只更新对当前新知识最“特异”的内存槽。
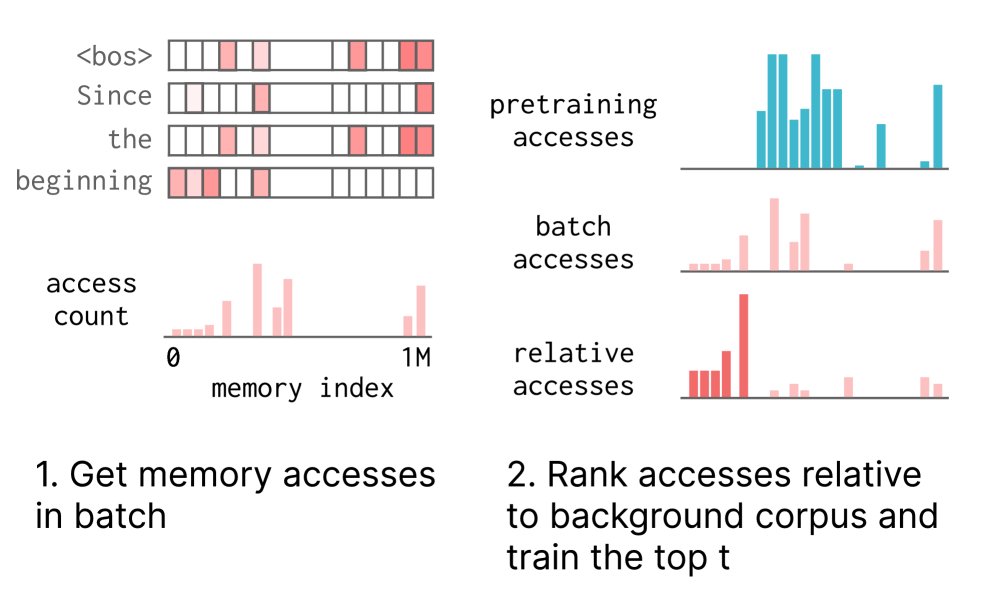
实现这一点的机制是 TF-IDF 排名。对于一个给定的训练批次,该方法按以下步骤操作:
- 统计访问频率 (TF):记录当前批次中每个内存索引被访问的次数 \(c(i)\)。
-
计算特异性分数 (TF-IDF):对于每个被访问的内存索引 \(i\),计算其 TF-IDF 分数。
\[\text{TF-IDF}(i) = \frac{c(i)}{\sum_{j \in M}c(j)} \cdot \log\frac{ \mid B \mid +1}{\sum_{b \in B}\mathbf{1}_{c_b(i)>0}+1}\]其中,\(TF\) 部分是索引 \(i\) 在当前批次的访问频率,\(IDF\) 部分的 \(B\) 是一个固定的“背景语料库”(如从预训练数据中随机抽取的批次集合),\(c_b(i)\) 是索引 \(i\) 在背景批次 \(b\) 中的访问次数。这个分数衡量了索引 \(i\) 在当前输入中的重要性相对于其在通用数据中的普遍性。
- 选择性梯度更新:根据 TF-IDF 分数从高到低排序,只选择分数最高的 \(t\) 个内存槽位。在反向传播过程中,梯度只会被传递到这 \(t\) 个槽位的值(\(V\))上,而所有其他参数(包括其他被访问的内存槽)则被冻结。
优点
- 最小化干扰:通过仅更新与新知识高度绑定的“特异性”参数,该方法能有效避免对存储在其他内存槽中的通用知识或旧知识的“覆写”,从而显著减轻遗忘。
- 动静分离:它在动态学习新知识(更新少数内存槽)和保持模型稳定性(冻结绝大多数参数)之间取得了出色的平衡。
- 高粒度控制:相比于更新整个LoRA模块或激活一个庞大的MoE专家,该方法提供了对参数更新的极高粒度控制,每次更新的参数量可以非常小(如 \(t=500\)),但整体内存容量又很大。
实验结论
本文通过在事实学习和文档问答两个持续学习场景下进行的实验,将稀疏内存微调与全参数微调(Full finetuning)和 LoRA 进行了对比。
主要实验结果
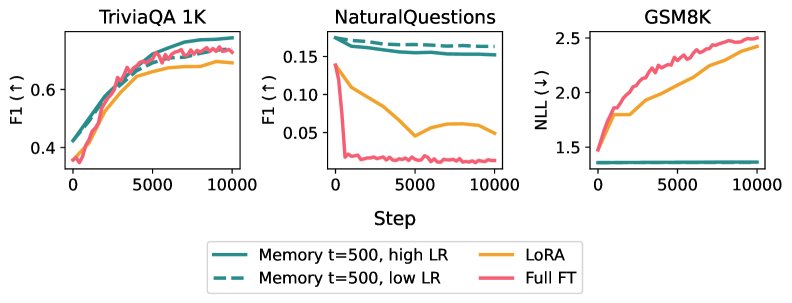
- 事实学习任务:模型需要学习一系列孤立的事实。实验结果表明,在达到相同新知识学习水平的情况下:
- 全参数微调导致模型在 NaturalQuestions (NQ) 数据集上的 F1 分数下降了 89%。
- LoRA 导致 NQ F1 分数下降了 71%。
- 稀疏内存微调仅导致 NQ F1 分数下降 11%,展现出极强的抗遗忘能力。
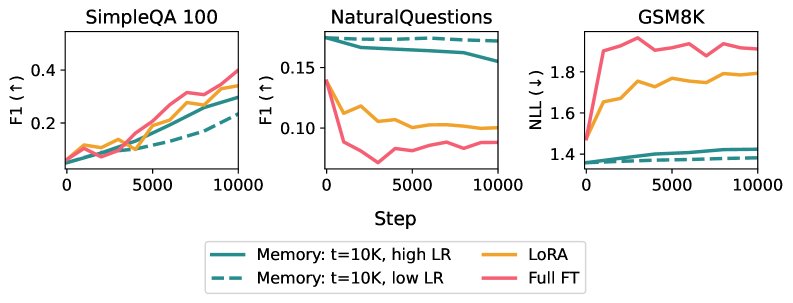
- 文档问答任务:模型需要从连续的文档流中学习。
- 虽然全参数微调和LoRA在该任务中表现更好(因为数据更丰富多样),但仍然存在明显的遗忘问题。
- 稀疏内存微调同样可以在达到与基线相同的目标任务性能的同时,将遗忘程度降到最低。
学习与遗忘的权衡
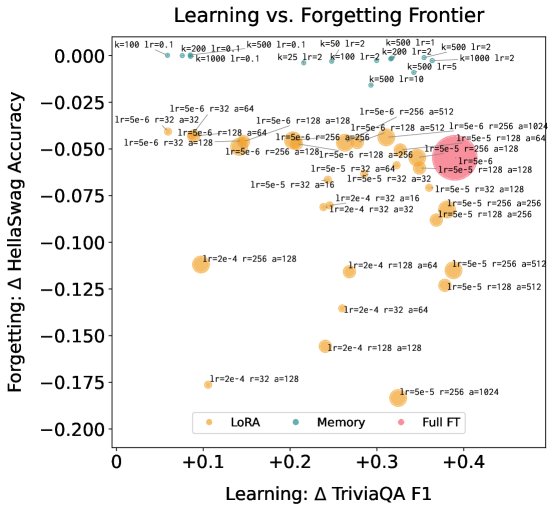
通过对不同方法的超参数(如学习率、LoRA的rank、稀疏微调的 \(t\) 值)进行扫描,本文绘制了学习效果与遗忘程度的帕累托前沿(Pareto Frontier)。
- 结果清晰地显示,稀疏内存微调在学习-遗忘权衡上帕累托支配(Pareto dominates)了全参数微etuning和LoRA,即在任何给定的遗忘水平上,它能学到更多知识;或在任何给定的学习水平上,它的遗忘更少。
分析与洞察
- TF-IDF 的必要性:消融实验表明,与简单地微调所有被访问的内存槽或仅根据访问频率(TF-only)选择 Top-t 相比,使用 TF-IDF 排名能显著减少遗忘,证明了识别“特异性”参数的重要性。
- 内存访问机制理解:定性分析发现,TF-IDF 选出的可训练索引与代表事实核心语义的“核心集(core set)”高度重合,并且这些索引的访问通常与文本中的实体边界对齐,这表明该方法确实定位到了存储关键信息的参数位置。
总结
实验结果有力地证明,稀疏内存微调是一种高效的持续学习方法。它通过利用内存层的稀疏设计和基于TF-IDF的选择性更新策略,成功地在学习新知识和保留旧能力之间取得了卓越的平衡,其表现在抗灾难性遗忘方面远超全参数微调和LoRA。这表明,参数更新的稀疏性可能是实现大模型持续学习的关键原则。