ConvergeWriter: Data-Driven Bottom-Up Article Construction
-
ArXiv URL: http://arxiv.org/abs/2509.12811v1
-
作者: Yifei Lu; Jiaqi Wang; Feiliang Ren; Yiyang Qi; Shichao Wang
-
发布机构: Northeastern University
TL;DR
本文提出了一种名为 ConvergeWriter 的“自下而上”长文生成框架,它通过“先检索知识,后聚类定结构”的策略,确保文章的规划和生成完全由可用的知识数据驱动,从而根本上解决了传统“自上而下”方法中规划与知识脱节导致的幻觉问题。
关键定义
- 自下而上 (Bottom-up) 数据驱动框架: 一种与传统方法相反的文章生成范式。它不先预设大纲,而是首先从知识库中检索全部相关文档,然后基于这些数据的内容和内在结构来生成文章大纲和最终内容。
- 先检索知识,后聚类定结构 (Retrieval-First for Knowledge, Clustering for Structure): ConvergeWriter 的核心策略。它强调在进行任何生成性规划之前,首先通过详尽的检索来确定可用知识的边界,然后通过无监督聚类将这些知识组织成有意义的结构。
- 知识聚类 (Knowledge Clusters): 通过对检索到的所有文档进行无监督聚类算法(如K-means)而形成的语义上内聚的文档分组。每个聚类代表了原始主题的一个特定方面,它们共同构成了文章结构的客观数据基础。
- 轮廓-知识簇联合驱动生成 (Outline-Knowledge Cluster Jointly Guided Generation): 在生成文章正文时采用的一种范式。每个章节的内容生成不仅依据大纲标题,还严格受其对应的知识聚类(即该章节的数据来源)的约束,确保了内容的溯源性和准确性。
相关工作
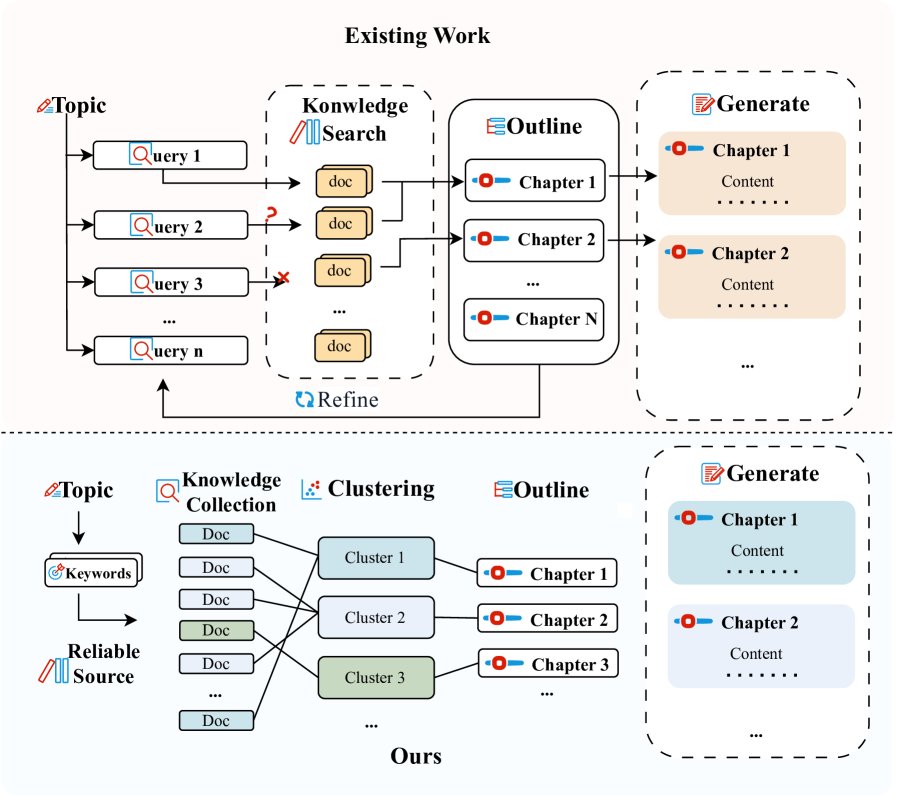
现有的大语言模型长文本生成方法,如 STORM 和 OmniThink,主要采用一种“自上而下 (Top-Down)”、假设驱动的策略。这些方法通常首先由模型构思文章主题,主动生成一个大纲或一系列探索性问题,然后再去知识库中检索“证据”来填充这个预设的框架。
这种方法的关键瓶颈在于:初始的规划阶段与知识库的实际内容可能存在脱节。模型预设的大纲可能高估或误判了实际可检索到的信息,这会导致检索效率低下、信息获取碎片化,甚至在知识稀疏的领域,模型为了填充大纲而“编造”内容,最终损害生成文章的深度、连贯性和事实准确性。
本文旨在解决这一核心问题,即如何确保生成的长篇文档严格忠实于给定的、有限的知识源,从根本上避免“大纲幻觉”和内容捏造,特别是在金融、科研等对信息准确性要求极高的“封闭知识库”场景中。
本文方法
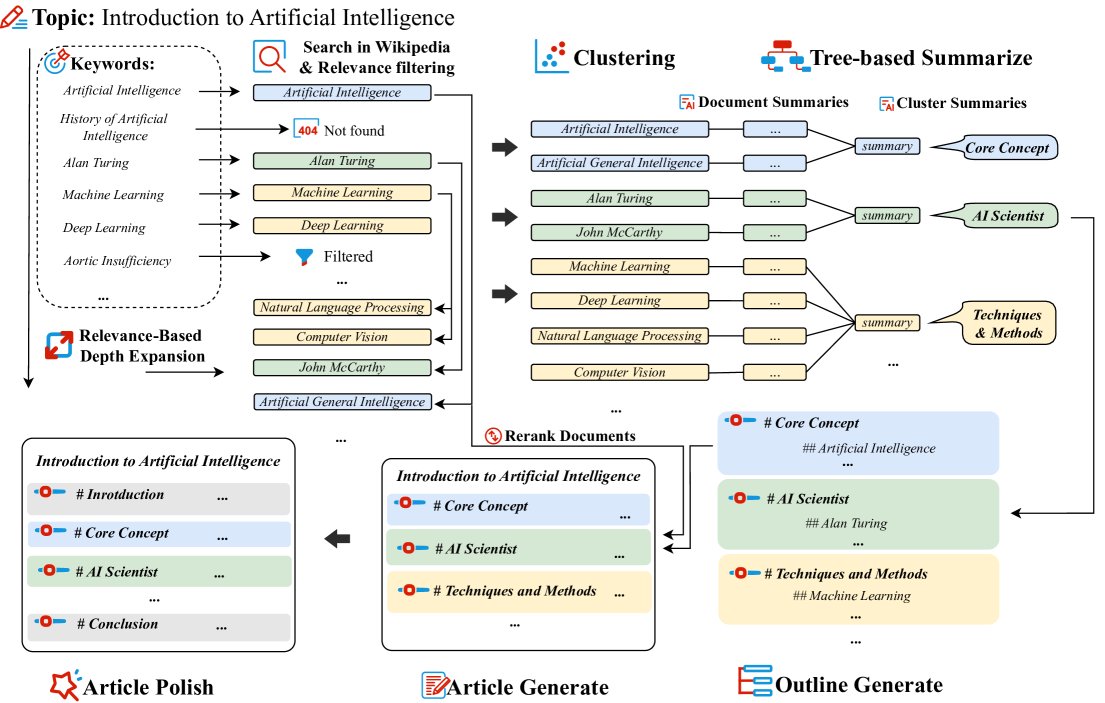 ConvergeWriter的工作流程: (1) 迭代式关联扩展知识检索与文档筛选;(2) 结合树状摘要的无监督聚类;(3) 基于大语言模型的提纲生成;(4) 召回增强的分章节内容生成、引言/结论补充与润色。
ConvergeWriter的工作流程: (1) 迭代式关联扩展知识检索与文档筛选;(2) 结合树状摘要的无监督聚类;(3) 基于大语言模型的提纲生成;(4) 召回增强的分章节内容生成、引言/结论补充与润色。
ConvergeWriter 的核心创新在于颠覆了传统的“规划-检索-生成”流程,采用一种“自下而上”的、由数据驱动的四阶段工作流。
1. 关联扩展的知识检索
为了构建一个全面且深入的知识基础,本方法首先围绕主题 $T$ 进行系统性的知识收集。
第一步,利用大语言模型 $\mathcal{M}$ 根据主题 $T$ 生成初始关键词集 $\mathcal{K}_{0}$,并从知识库(如维基百科)检索初步的文档集 $\mathcal{D}^{(0)}$。随后,通过 $\mathcal{M}$ 进行相关性筛选,保留与主题 $T$ 强相关的文档,形成 $\mathcal{D}^{(1)}$。
第二步,为了挖掘更深层次的信息,对 $\mathcal{D}^{(1)}$ 中的每篇文档 $d$ 再次使用 $\mathcal{M}$ 生成扩展关键词 $\mathcal{K}_{\text{ext}}$。这些关键词旨在探索与当前文档内容相关的更细分或纵深的知识点。利用 $\mathcal{K}_{\text{ext}}$ 进行二次检索和筛选。
最终,将两轮检索到的高质量文档合并,得到最终的知识文档集 $\mathcal{D}^*$。这一“检索先行”的策略确保了后续所有步骤都建立在实际可获得的知识边界之内。
2. 知识结构化:聚类与摘要
获得非结构化的文档集 $\mathcal{D}^*$ 后,本阶段旨在揭示其内在的主题分布,为生成逻辑连贯的大纲做准备。
首先,使用预训练的嵌入模型 $\mathcal{E}$ 将每篇文档 $d_i$ 映射为语义向量 $v_i$。接着,为了自动确定最佳聚类数量 $k$,本方法采用轮廓系数 (silhouette coefficient) 作为评估指标,在预设范围内迭代寻找使平均轮廓系数 $\bar{s}(k)$ 最大化的 $k^*$ 值:
\[k^* = \underset{k \in [k_{\min}, k_{\max}]}{\arg\max} \bar{s}(k)\]确定 $k^*$ 后,执行 K-means 聚类算法,将所有文档划分为 $k^*$ 个“知识聚类” ${C_1, C_2, \ldots, C_{k^*}}$。
由于每个聚类可能包含大量文档,直接处理会超出模型的上下文窗口限制。因此,本方法采用一种层级化树状摘要策略:
- 文档级摘要: 对聚类中的每篇文档 $d_i$ 单独生成一个简洁的摘要 $s_i$。
- 聚类级摘要: 将该聚类内所有的文档摘要 ${s_i}$ 拼接起来,再次输入给大语言模型,生成一个更高层次的、概括性的聚类摘要 $S_j$。
通过这一过程,原始的文档集合被转化为一组语义内聚、并附有精炼概括的知识结构。
3. 基于结构化知识映射的大纲生成
此阶段利用上一阶段生成的聚类摘要 ${S_j}_{j=1}^{k^*}$ 来构建文章大纲 $O$。
大语言模型 $\mathcal{M}$ 被指示基于这些摘要生成一个逻辑通顺、重点突出的大纲。为杜绝“大纲幻觉”,此过程受到严格约束:
- 内容约束: 大纲的章节标题和内容必须完全源自于输入的聚类摘要。
- 结构约束: 除了引言和结论,大纲中的每一个主体章节 $\text{Sec}_i$ 都必须明确且唯一地映射到一个知识聚类 $C_j$。
这种设计确保了文章的骨架完全由数据驱动,准确反映了知识库内容的内在结构,从源头上保证了文章的覆盖度和真实性。
4. 轮廓-知识簇联合驱动的逐节生成与整合
这是最终生成完整文章的阶段。 首先,将大纲 $O$ 解析为独立的章节单元。对于每个主体章节 $\text{Sec}_i$,从其唯一对应的知识聚类 $C_j$ 中检索相关文档,并通过一个重排序模型 (Ranker) 筛选出最相关的文档集 $\mathcal{D}_{\text{sec}_i}^*$。然后,模型使用章节标题 $\text{Sec}_i$ 和文档集 $\mathcal{D}_{\text{sec}_i}^*$ 联合驱动生成该章节的具体内容 $\text{Sec}_i^*$:
\[\text{Sec}_i^* = \mathcal{M}(\text{Sec}_i, \mathcal{D}_{\text{sec}_i}^*; \mathcal{I}_{\text{section\_gen}})\]在所有主体章节独立生成后,将它们拼接成文章主体草稿 $\mathcal{A}_{\text{draft}}$。接着,模型根据文章主题和主体草稿,分别生成“引言”和“结论”部分。
最后,对整合后的全文草稿 $\mathcal{A}_{\text{full_draft}}$ 进行一次全局性的润色,生成语法流畅、风格统一的最终文章 $\mathcal{A}_{\text{final}}$。
实验结论
实验在一个名为 WildSeek 的数据集上进行,该数据集源于真实用户的复杂信息查询场景。实验的核心任务是:给定一个主题和唯一的知识源(维基百科API),评估不同方法生成结构化、信息丰富文章的能力。
核心结果
实验结果(见下表)表明,ConvergeWriter 在多个关键指标上表现出显著优势。
| 方法 | 模型 | 长度 (Length) | 引用文档数 (Cite Docs) | Rubric Grading (平均分) | 覆盖率 (Coverage %) | 新颖性 (Novelty) |
|---|---|---|---|---|---|---|
| ConvergeWriter (本文) | Qwen1.5-14B | 2334 | 9.08 | 4.79 | 80.14% | 4.22 |
| OmniThink | Qwen1.5-14B | 2809 | 8.86 | 4.61 | 64.92% | 3.51 |
| Storm | Qwen1.5-14B | 2007 | 7.92 | 4.47 | 71.01% | 3.59 |
| Two-Stage RAG | Qwen1.5-14B | 4172 | 8.33 | 4.31 | 55.32% | 3.29 |
| Direct RAG | Qwen1.5-14B | 1582 | 6.81 | 4.09 | 67.89% | 2.59 |
| ConvergeWriter (本文) | Qwen1.5-32B-instruct | 2686 | 8.55 | 4.86 | 70.51% | 4.58 |
| OmniThink | Qwen1.5-32B-instruct | 2589 | 8.01 | 4.70 | 60.10% | 3.82 |
| Storm | Qwen1.5-32B-instruct | 2439 | 7.79 | 4.61 | 63.88% | 3.90 |
| Two-Stage RAG | Qwen1.5-32B-instruct | 3892 | 7.64 | 4.38 | 50.11% | 3.32 |
| Direct RAG | Qwen1.5-32B-instruct | 2011 | 7.02 | 4.41 | 64.12% | 2.92 |
- 高可信度与低幻觉: ConvergeWriter 在“文档覆盖率 (Coverage)”指标上遥遥领先(14B模型下为80.14%,32B模型下为70.51%),这意味着其生成的内容绝大部分都能在源知识库中找到依据。这直接验证了其“先检索后规划”策略能有效抑制内容幻觉,增强可信度。
- 更优的知识组织与新颖性: 与同样注重结构的 STORM 和 OmniThink 相比,ConvergeWriter 的文章结构由客观数据聚类决定,而非模型主观构想,因而能更真实地反映知识库的全貌。值得注意的是,其“新颖性 (Novelty)”得分也最高(4.22 和 4.58),表明通过聚类发现文档间的潜在联系,模型能生成更具洞察力的观点,而非简单的信息堆砌。
- 高效的信息利用: 在14B模型上,ConvergeWriter 引用了最多的文档(9.08篇),同时文章长度适中。这说明它能有效地利用大量信息源并进行浓缩,而不是像 Two-Stage RAG 那样生成冗长但覆盖率低、信息量稀疏的内容。
- 框架的普适性: 无论是在14B还是更强的32B模型上,ConvergeWriter 都保持了性能领先。这证明其优势来源于框架设计的先进性,而非依赖特定模型的强大能力,具有良好的泛化性和可移植性。
消融研究
为了验证聚类模块的核心作用,实验设计了一个“无聚类”版本(w/o Clustering),该版本简单地将检索到的文档按顺序均分为五份作为章节依据。
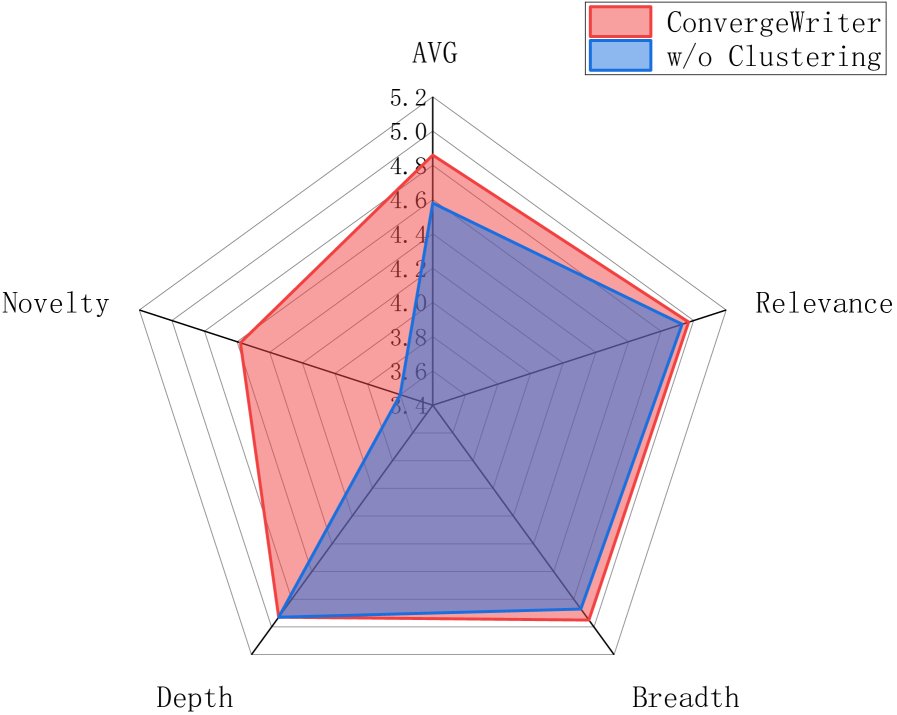 聚类消融实验:顺序切分破坏了知识组织,导致新颖性大幅下降(4.58→3.60)和输出不连贯。
聚类消融实验:顺序切分破坏了知识组织,导致新颖性大幅下降(4.58→3.60)和输出不连贯。
结果显示,移除聚类后,文章的整体质量显著下降,尤其“新颖性”得分从4.58骤降至3.60。这是因为机械的顺序切分破坏了文档间的内在语义联系,导致知识组织混乱,模型难以生成连贯且有深度的大纲和内容。该实验有力地证明了通过聚类预先构建一个能反映知识库内部结构的数据框架,是生成高质量结构化长文的基石。
最终结论
本文提出的 ConvergeWriter 框架通过一种创新的自下而上、数据驱动的范式,成功地解决了现有方法在利用外部知识时面临的内容可信度挑战。其实验证明,该方法在需要高保真度和结构连贯性的封闭知识场景下表现优异,为开发更稳健、更可靠的知识密集型大语言模型应用铺平了道路。