CreativityPrism: A Holistic Benchmark for Large Language Model Creativity
-
ArXiv URL: http://arxiv.org/abs/2510.20091v1
-
作者: Snigdha Chaturvedi; Anneliese Brei; Bhiman Kumar Baghel; Faeze Brahman; Zhaoyi Joey Hou; Meng Jiang; Ximing Lu; Daniel Khashabi; Yining Lu; Haw-Shiuan Chang; 等11人
-
发布机构: Allen Institute for Artificial Intelligence; Johns Hopkins University; University of Massachusetts Amherst; University of North Carolina; University of Notre Dame; University of Pittsburgh; University of Washington
TL;DR
本文提出了一个名为 \(CreativityPrism\) 的整体性评估框架,通过跨越三个领域(发散性思维、创意写作、逻辑推理)的九个任务和二十个指标,从质量、新颖性和多样性三个维度系统地评估大型语言模型的创造力。
关键定义
本文的核心是围绕其提出的 \(CreativityPrism\) 框架展开的,其中对创造力的分解是理解本文的关键。
- CreativityPrism: 一个用于评估大型语言模型(LLM)创造力的整体性、可扩展的基准。它由三个领域(发散性思维、创意写作、逻辑推理)、九个具体任务和二十个评估指标构成,旨在全面衡量模型的创造力。
- 质量 (Quality): 创造力维度之一,评估生成内容是否满足任务的基本要求和功能性。例如,在代码生成中,质量指代码能否成功执行并完成任务;在故事写作中,指故事是否连贯、语法是否正确以及是否满足约束。
- 新颖性 (Novelty): 创造力维度之一,评估生成内容与现有或常见内容相比的原创性或罕见程度。例如,在数学问题中,新颖性指能否提出不同于参考答案的解法;在物品用途测试中,指能否想出非常规的用途。
- 多样性 (Diversity): 创造力维度之一,评估模型生成的多个输出之间的差异性。例如,在创意写作中,多样性衡量生成故事的词汇丰富度;在发散性联想任务中,指生成名词之间的语义差异。
相关工作
当前对大型语言模型(LLM)创造力的评估存在两大挑战。首先,现有评估方法是分散和碎片化的(fragmented),不同领域和任务对创造力的定义和测量方式差异巨大,导致评估结论不一致,难以进行横向比较。例如,一些任务侧重词汇多样性,一些侧重非常规想法,但都只捕捉了创造力的单一侧面。
其次,许多评估方法难以扩展(scalable),严重依赖昂贵且耗时的人工评估。随着模型迭代速度加快,急需一种可扩展、自动化的评估方式。
因此,本文旨在解决当前 LLM 创造力评估缺乏统一、全面框架的问题。作者的目标是创建一个整体性的、可扩展的评估基准,整合多个任务和维度,以统一的方式衡量和比较不同 LLM 的创造力。
本文方法
本文提出了 \(CreativityPrism\),一个用于评估机器创造力的整体性基准框架。其核心思想是,创造力并非单一概念,而是一个多面体,在不同领域(上下文)下会展现出不同的特质,就像光透过棱镜折射出不同颜色的光谱一样。
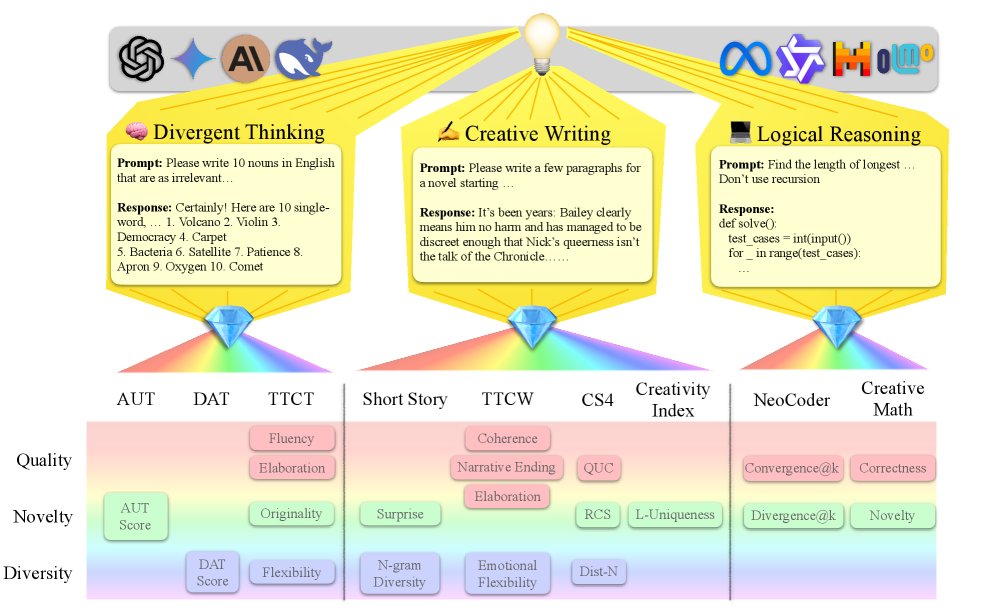
框架构成
\(CreativityPrism\) 框架包含三个主要部分:
- 三大任务领域: 框架涵盖了三个考验不同创造力方面的领域:
- 发散性思维 (Divergent Thinking): 包含源自心理学的经典测试任务,旨在评估模型生成多样化、非传统答案的能力。
- 创意写作 (Creative Writing): 包含要求模型创作短文的任务,通过直接指令或施加特定规则约束来激发非常规的思维。
- 逻辑推理 (Logical Reasoning): 包含编码和数学任务,用于评估模型在严格、明确的逻辑约束下生成创造性解决方案的能力。
- 九项具体任务: 框架从以上三个领域中选择了九个已有研究中的任务(数据集),这些任务均具备可扩展的自动化评估指标,并与人类判断有较好的一致性。
| 领域 | 任务 | 示例输入与说明 |
|---|---|---|
| 🧠 发散性思维 | Alternative Use Task (AUT) | 输入:日常物品。任务:为其想出尽可能多的创新用途。 |
| 🧠 发散性思维 | Divergent Association Task (DAT) | 输入:10 个名词。任务:找到一个与这10个词语义距离尽可能远的词。 |
| 🧠 发散性思维 | Torrance Test of Creative Thinking (TTCT) | 输入:一个不完整的图形。任务:完成这幅画并为其命名。 |
| ✍️ 创意写作 | Creative Short Story (CSS) | 输入:故事的开头。任务:续写一个有创意转折的短篇故事。 |
| ✍️ 创意写作 | Creative Story with 4 constraints (CS4) | 输入:4个约束(如特定词汇、句式)。任务:写一个满足所有约束的连贯故事。 |
| ✍️ 创意写作 | Creativity Index (CI) | 输入:维基百科段落。任务:在保留核心信息的同时,用创新的方式重写它。 |
| ✍️ 创意写作 | Torrance Test of Creative Writing (TTCW) | 输入:一个奇特的视觉场景。任务:围绕这个场景写一个故事。 |
| 🧬 逻辑推理 | NeoCoder | 输入:一个编程问题。任务:生成一个与标准答案不同的、但能正确解决问题的代码。 |
| 🧬 逻辑推理 | Creative Math | 输入:一个数学问题。任务:生成一个与参考解法不同的、但能正确解决问题的解法。 |
- 三大评估维度: \(CreativityPrism\) 的核心创新在于将所有任务的共二十个具体指标归纳为三个统一的维度,从而实现结构化分析:
- 质量 (Quality): 衡量产出是否合规、有效。例如代码是否能运行通过(\(convergent@0\)),故事是否连贯。
- 新颖性 (Novelty): 衡量产出是否原创、罕见。例如代码解法是否不同于参考答案(\(divergent@0\)),重写文本与训练语料的n-gram重叠度是否低。
- 多样性 (Diversity): 衡量产出内部的变化和丰富性。例如生成故事的词汇多样性,或多次生成答案之间的语义差异。
创新点
本文方法最本质的创新在于提出了一个分解式、结构化的评估体系。它没有试图用单一指标定义创造力,而是将这个模糊的概念分解为质量、新颖性、多样性这三个可衡量、可比较的维度。通过将不同领域的任务和指标统一纳入该框架,\(CreativityPrism\) 首次实现对 LLM 创造力的全面(holistic)和跨领域(cross-domain)的系统性评估。
优点
- 整体性: 通过覆盖多个领域,避免了单一任务评估带来的片面性,能更全面地反映模型的创造力画像。
- 结构化: 质量-新颖性-多样性的三维分解为分析模型能力提供了清晰的视角,可以揭示模型在不同创造力侧面上的优势与短板。
- 可扩展性: 框架主要依赖自动化评估指标(包括经过可靠性验证的 LLM-as-a-Judge),使其比传统的人工评估更高效、更易于扩展,适应了模型快速迭代的需求。
实验结论
本文对17个先进的闭源和开源 LLM 进行了评估,揭示了它们在创造力方面的表现。
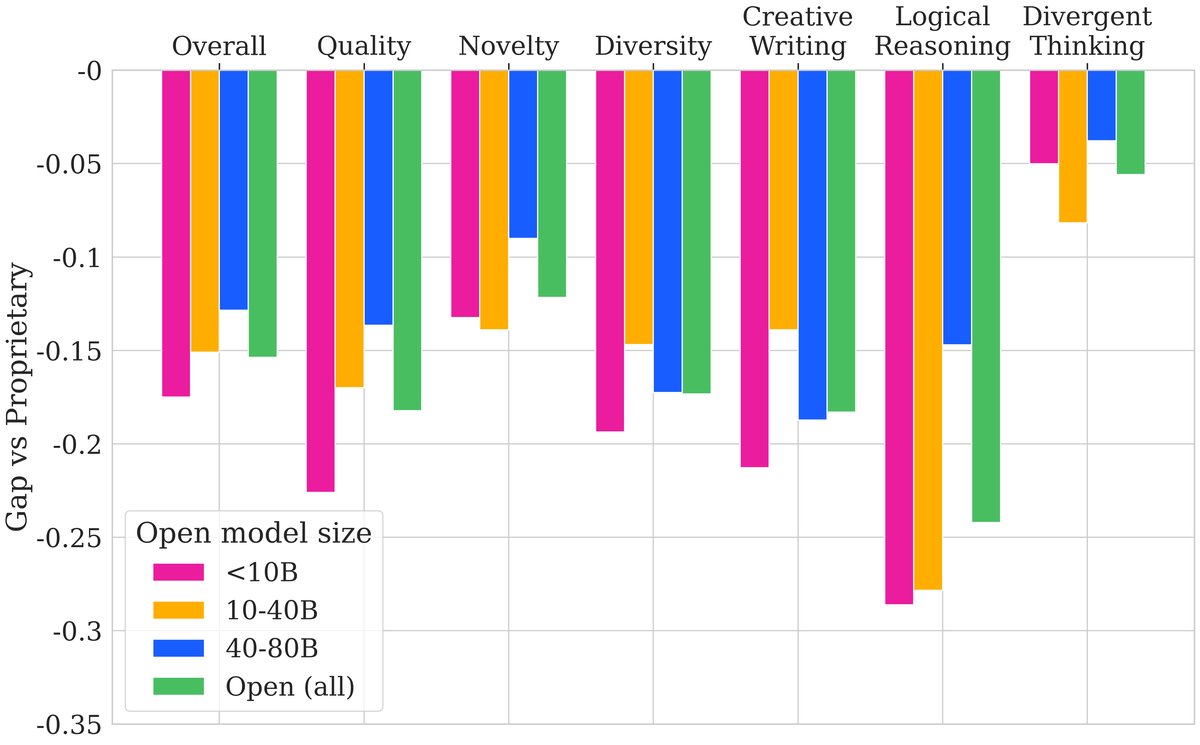
关键实验结果
- 闭源与开源模型存在显著差距: 如总览表所示,最顶尖的闭源模型(如 GPT-4o、Claude-3-Opus)在总体创造力得分上显著优于最好的开源模型(如 Qwen2.5-72B, DeepSeek-V3)。这一差距在逻辑推理和创意写作领域尤为明显,而在发散性思维领域则相对较小。同样,在质量和多样性维度上差距较大,但在新颖性维度上差距较小。
| Model Family | Model | 🧠 Div. Think. | ✍️ Crea. Writ. | 🧬 Log. Reas. | ✅ Quality | ✨ Novelty | 🎨 Diversity | 🏆 Overall |
|---|---|---|---|---|---|---|---|---|
| (Avg.) | 0.54 | 0.57 | 0.51 | 0.55 | 0.62 | 0.49 | 0.55 | |
| Proprietary | GPT-4o | 0.82 | 0.81 | 0.86 | 0.88 | 0.73 | 0.83 | 0.81 |
| Claude-3-Opus | 0.82 | 0.82 | 0.80 | 0.85 | 0.76 | 0.83 | 0.81 | |
| Gemini-1.5-Pro | 0.77 | 0.76 | 0.78 | 0.81 | 0.74 | 0.73 | 0.76 | |
| DeepSeek-V2 | 0.72 | 0.72 | 0.69 | 0.75 | 0.70 | 0.69 | 0.71 | |
| GPT-4-Turbo | 0.72 | 0.74 | 0.70 | 0.76 | 0.70 | 0.69 | 0.72 | |
| … | … | … | … | … | … | … | … | |
| Open-Source | Qwen2.5-72B | 0.77 | 0.73 | 0.58 | 0.71 | 0.72 | 0.64 | 0.69 |
| DeepSeek-Coder-V2 | 0.59 | 0.58 | 0.78 | 0.73 | 0.60 | 0.60 | 0.64 | |
| Llama-3-70B | 0.68 | 0.65 | 0.38 | 0.54 | 0.65 | 0.59 | 0.59 | |
| Qwen2-57B | 0.71 | 0.67 | 0.40 | 0.59 | 0.69 | 0.50 | 0.59 | |
| … | … | … | … | … | … | … | … |
- 性能相关性分析揭示创造力的多面性:
- 维度内相关性: 质量和多样性两个维度内的各项指标之间表现出强相关性。这意味着在一个任务上质量高(或多样性好)的模型,在其他任务上也倾向于表现出高质量(或高多样性)。
- 新颖性的独特性: 新颖性维度的各项指标之间相关性很弱,甚至为负。这表明不同任务对“新颖性”的定义和要求截然不同(例如,代码的新颖性与故事的新颖性是两种不同的能力),一个模型在一个领域展现的新颖性无法泛化到另一领域。
- 跨维度与跨领域相关性: 不同维度之间(如质量 vs. 新颖性)和不同领域之间(如创意写作 vs. 逻辑推理)的性能相关性普遍较低。
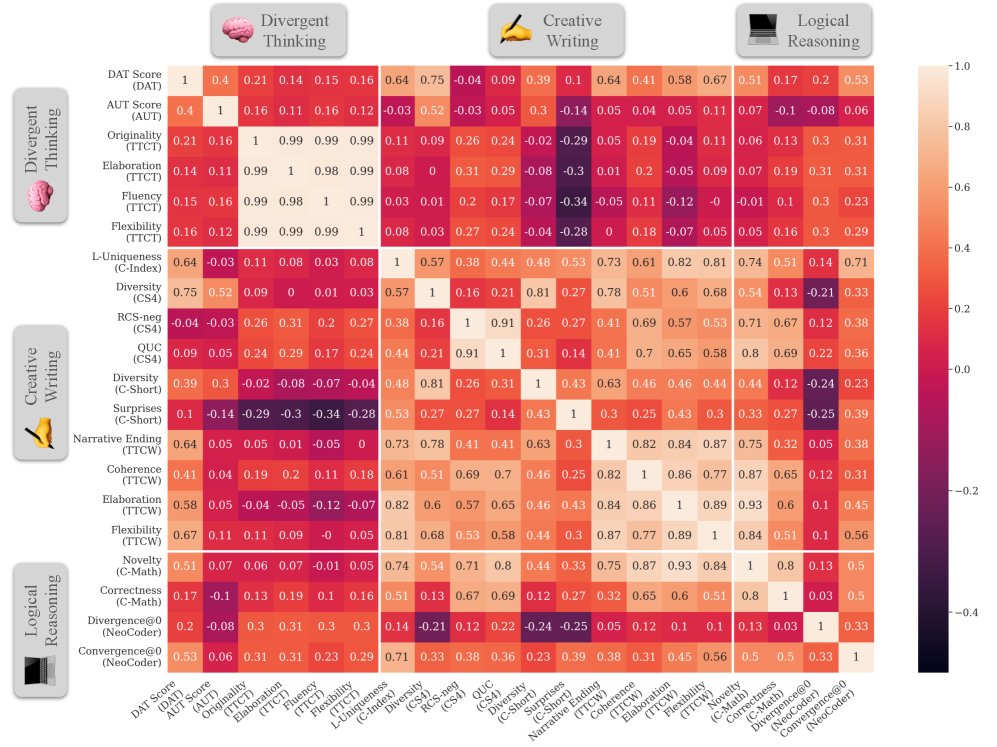
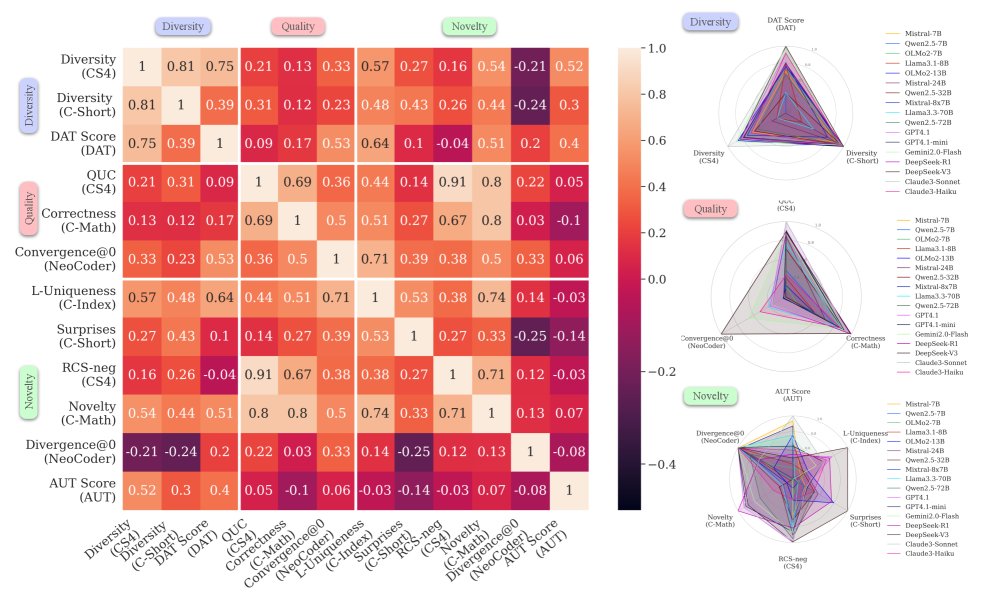
结论
实验结果有力地验证了本文的核心假设:创造力并非单一能力,在一个创造力任务或维度上的优异表现不一定能泛化到其他方面。这凸显了 \(CreativityPrism\) 这样一个整体性、多维度评估框架的必要性。
最终,本文提出的 \(CreativityPrism\) 为系统性地衡量和理解 LLM 的创造力提供了一个坚实的基础,能够帮助研究者和开发者识别模型的创造力短板,并为开发更具创造力的人工智能指明优化方向。同时,本文也承认了基准的局限性,如仅限英语、评估中可能存在的LLM偏见、仅限文本模态等。